Articles Catalogue
- statement
- Data sample
- functional requirement
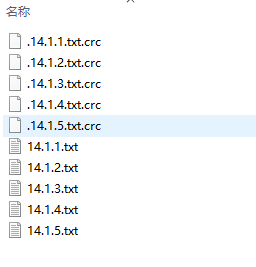
- 1. File data files by day, that is, one data file per day.
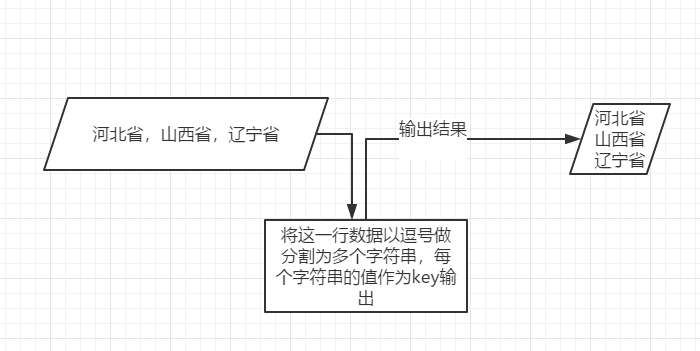
- 2. Re-export provincial documents and save them in one line of provinces after export.
- 3. Statistics of the total number of agricultural products markets in each province
- 4. What are the provinces without agricultural markets?
- 5. Statistical analysis of the proportion of clam Market in Shandong Province
- 6. Statistics of the total number of agricultural products in each province
- 7. Types of Agricultural Products Owned by the Top 3 Provinces
- 8. Calculate the price fluctuation trend of every agricultural product in Shanxi Province, that is, calculate the daily average price.
statement
This data comes from the network, and the case is only for reference. It has no practical significance.
Data sample

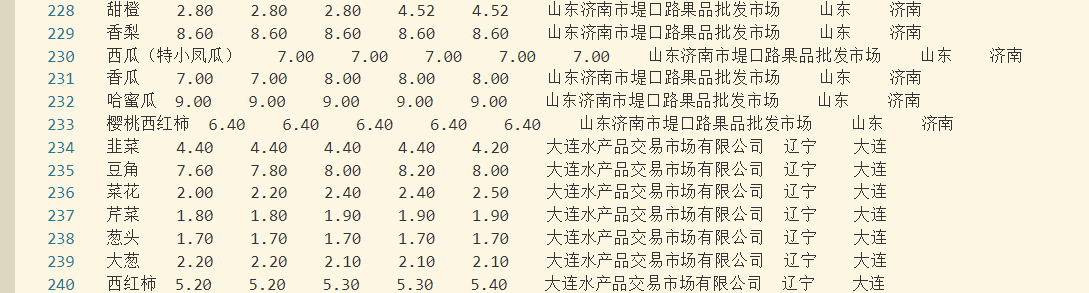
The above data sample provides the wholesale prices of agricultural products in some provinces and municipalities of China from January 1 to January 5, 2014. Segmentation of columns by "t".
The above data sample provides some provinces in China. Data is segmented by "."
functional requirement
1. File data files by day, that is, one data file per day.
requirement analysis
The idea of requirement completion is essentially a string segmentation, and then the unnecessary dates are listed and removed. Manual output is obviously unreasonable due to the need to archive by day, so you need to customize OutputFormat for data output.
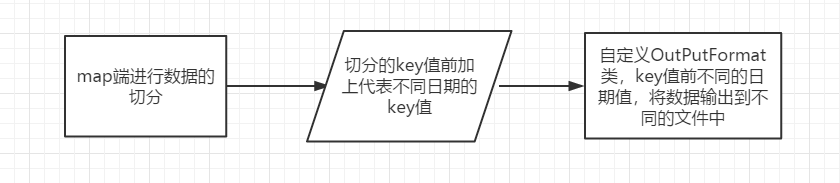
code implementation
Map-side code
public class EveryDayMapper extends Mapper<LongWritable,Text,Text, NullWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] line = value.toString().split("\t"); if (line[0].equals("Agricultural products")){ return; } if (line.length < 9){ return; } for (int i = 1; i<=5; i++){ //Automated segmentation is done in a loop, five days are written into the key, and the date value is added at the beginning of the key in the form of string splicing. context.write(new Text(i + line[0] + "\t" + line[i] + "\t" + line[6] + "\t" + line[7] + "\t" + line[8]),NullWritable.get()); } } }
Custom OutPutFormat Code
public class EveryDayOutPutFormat extends FileOutputFormat<Text, NullWritable>{ @Override public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException { // Create a RecordWriter return new EveryDayRecorderWriter(job); } }
Rewrite RecordWriter code
public class EveryDayRecorderWriter extends RecordWriter<Text,NullWritable> { private FSDataOutputStream day1; private FSDataOutputStream day2; private FSDataOutputStream day3; private FSDataOutputStream day4; private FSDataOutputStream day5; public EveryDayRecorderWriter() { super(); } public EveryDayRecorderWriter(TaskAttemptContext job) throws IOException { //1. Get the file system FileSystem fs; fs = FileSystem.get(job.getConfiguration()); //2. Create the output file path Path pathDay1 = new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\everyday\\14.1.1.txt"); Path pathDay2 = new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\everyday\\14.1.2.txt"); Path pathDay3 = new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\everyday\\14.1.3.txt"); Path pathDay4 = new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\everyday\\14.1.4.txt"); Path pathDay5 = new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\everyday\\14.1.5.txt"); //3. Create an output stream day1 = fs.create(pathDay1); day2 = fs.create(pathDay2); day3 = fs.create(pathDay3); day4 = fs.create(pathDay4); day5 = fs.create(pathDay5); } @Override public void write(Text key, NullWritable value) throws IOException, InterruptedException { String keyStr = key.toString() + "\r\n"; keyStr = keyStr.substring(1,keyStr.length()); //Export key values from map to different files on different dates at the beginning if (key.toString().startsWith("1")){ day1.write(keyStr.getBytes()); }else if (key.toString().startsWith("2")){ day2.write(keyStr.getBytes()); }else if (key.toString().startsWith("3")){ day3.write(keyStr.getBytes()); }else if (key.toString().startsWith("4")){ day4.write(keyStr.getBytes()); }else if (key.toString().startsWith("5")){ day5.write(keyStr.getBytes()); } } @Override public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException { IOUtils.closeStream(day1); IOUtils.closeStream(day2); IOUtils.closeStream(day3); IOUtils.closeStream(day4); IOUtils.closeStream(day5); } }
Driver code
public class EveryDayDrive { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(EveryDayDrive.class); job.setMapperClass(EveryDayMapper.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); job.setMapperClass(EveryDayMapper.class); job.setNumReduceTasks(0); //To set custom output format components into job job.setOutputFormatClass(EveryDayOutPutFormat.class); FileInputFormat.setInputPaths(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\FiveAllTable.txt")); FileOutputFormat.setOutputPath(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\EveryDOutput")); job.waitForCompletion(true); } }
Output results
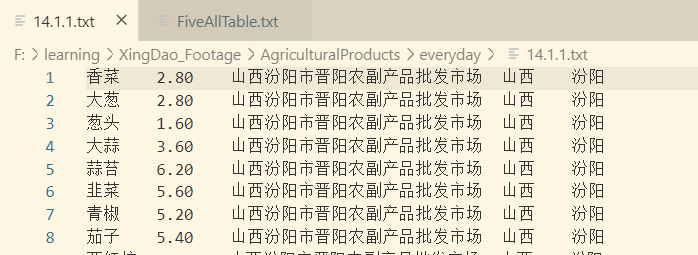
2. Re-export provincial documents and save them in one line of provinces after export.
requirement analysis
code implementation
public class provienceETL { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(provienceETL.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); job.setMapperClass(provienceETLMapper.class); //Set reduce number to 0 job.setNumReduceTasks(0); FileInputFormat.setInputPaths(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\china-province.txt")); FileOutputFormat.setOutputPath(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\ch_provience")); job.waitForCompletion(true); } } class provienceETLMapper extends Mapper<LongWritable, Text,Text, NullWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] line = value.toString().split(","); for (String str : line){ context.write(new Text(str),NullWritable.get()); } } }
Output results

3. Statistics of the total number of agricultural products markets in each province
requirement analysis
First, extract the keywords in the requirements:
- Each Province
- Total market for agricultural products
It can be seen from the demand that the corresponding relationship between the two keywords corresponds to multiple markets for a province. So you can make sure that province is the key value.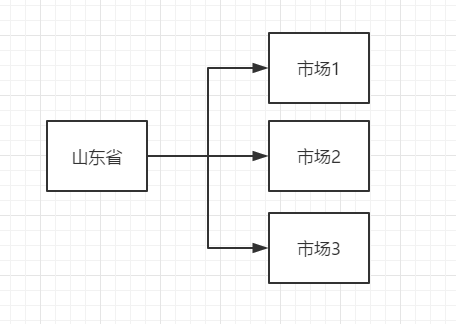
From the data, there will be multiple identical markets in the same identity province, so the market name will be transferred into reduce as value value value, then be de-duplicated and then count the number.

code implementation
map class code
class ProMarketMapper extends Mapper<LongWritable, Text,Text,Text>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] fields = line.split("\t"); String provience = fields[3]; String Market = fields[2]; context.write(new Text(provience),new Text(Market)); } }
reduce class code
class ProMarketReduce extends Reducer<Text,Text,Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = values.iterator(); HashSet<String> set = new HashSet<String>(); while (iterator.hasNext()){ set.add(iterator.next().toString()); } context.write(key,new IntWritable(set.size())); } }
driver class code
public class ProMarket { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(ProMarket.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(ProMarketMapper.class); job.setReducerClass(ProMarketReduce.class); FileInputFormat.setInputPaths(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\FiveDays\\14.1.1\\part-m-00000")); FileOutputFormat.setOutputPath(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\MarketNumber\\ProMarket")); job.waitForCompletion(true); } }
Output results
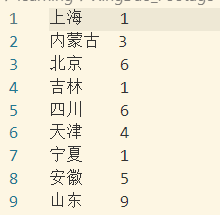
4. What are the provinces without agricultural markets?
requirement analysis
To fulfill the requirements, you can use the following known data
- All provinces
- Provinces with markets for agricultural products
This requirement can be done with reduce join.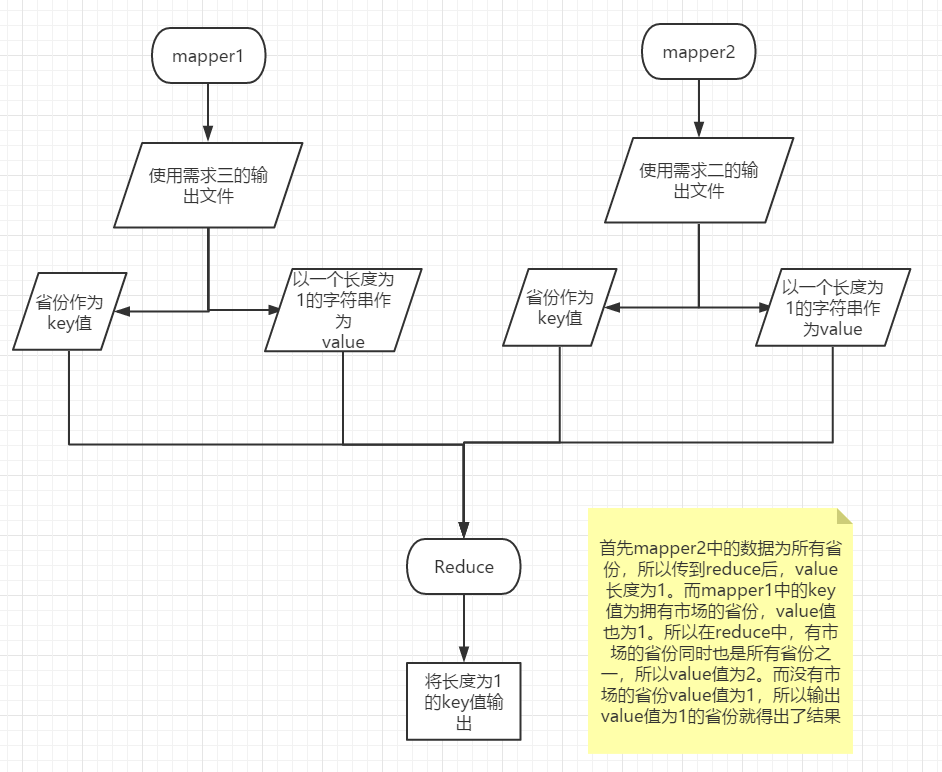
code implementation
mapper1
public class NMPMapper1 extends Mapper<LongWritable, Text, Text, Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] line = value.toString().split("\t"); context.write(new Text(line[0]),new Text(line[1])); } }
mapper2
public class NMPMapper2 extends Mapper<LongWritable, Text, Text, Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String str = ""; context.write(new Text(line),new Text(str)); } }
reduce
public class NMPReducer extends Reducer<Text,Text,Text, NullWritable> { @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = values.iterator(); ArrayList<String> list = new ArrayList<String>(); while (iterator.hasNext()){ String str = iterator.next().toString(); list.add(str); } if (list.size()<2){ context.write(key,NullWritable.get()); } } }
driver
public class NMPMain { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(NMPMain.class); MultipleInputs.addInputPath(job,new Path( "F:\\learning\\XingDao_Footage\\AgriculturalProducts\\MarketNumber\\ProMarket\\part-r-00000"), TextInputFormat.class, NMPMapper1.class ); MultipleInputs.addInputPath(job,new Path( "F:\\learning\\XingDao_Footage\\AgriculturalProducts\\ch_provience\\part-m-00000.txt"), TextInputFormat.class, NMPMapper2.class ); job.setReducerClass(NMPReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); FileOutputFormat.setOutputPath(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\MarketNumber\\NoMarketPro")); job.waitForCompletion(true); } }
Output results

5. Statistical analysis of the proportion of clam Market in Shandong Province
requirement analysis
According to the output documents of Demand Three, there are 9 agricultural products markets in Shandong Province. So as long as we count the number of agricultural products sold clams in the market, we can get the proportion.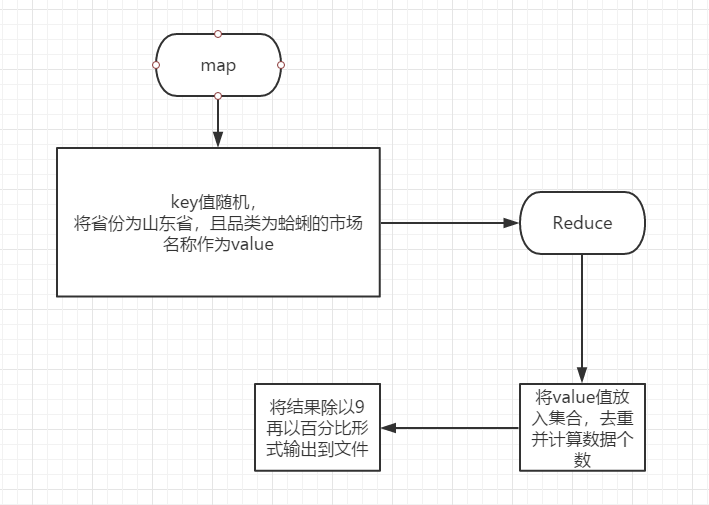
code implementation
mapper
public class GaLaMapper extends Mapper<LongWritable, Text,Text, Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] line = value.toString().split("\t"); String name = line[0]; String marketName = line[2]; String provience = line[3]; if (name.equals("Clams") && provience.equals("Shandong")){ context.write(new Text("Clam Market"),new Text(marketName)); } } }
reducer
public class GaLaReducer extends Reducer<Text, Text,Text,Text> { @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = values.iterator(); HashSet<String> set = new HashSet<String>(); while (iterator.hasNext()){ set.add(iterator.next().toString()); } DecimalFormat df = new DecimalFormat("%0.00"); double setSize = set.size(); double num = setSize/9; context.write(new Text("The proportion of the clam Market in Shandong province is as follows:"),new Text(df.format(num))); } }
driver
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(GaLaMain.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setMapperClass(GaLaMapper.class); job.setReducerClass(GaLaReducer.class); FileInputFormat.setInputPaths(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\FiveDays\\14.1.1\\part-m-00000")); FileOutputFormat.setOutputPath(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\MarketNumber\\GaLa")); job.waitForCompletion(true); } }
Output results

6. Statistics of the total number of agricultural products in each province
requirement analysis
Similar to the first step of the previous demand, the province is regarded as key, the product category is regarded as value, and the product is transferred to reduce, then the weight is removed, and the quantity can be obtained.
code implementation
mapper
class PTSMapper extends Mapper<LongWritable,Text,Text,Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] line = value.toString().split("\t"); String type = line[0]; String provience = line[3]; context.write(new Text(provience),new Text(type)); } }
reducer
class PTSReducer extends Reducer<Text,Text,Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = values.iterator(); HashSet<String> set = new HashSet<String>(); while (iterator.hasNext()){ set.add(iterator.next().toString()); } context.write(key,new IntWritable(set.size())); } }
driver
class PTSReducer extends Reducer<Text,Text,Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = values.iterator(); HashSet<String> set = new HashSet<String>(); while (iterator.hasNext()){ set.add(iterator.next().toString()); } context.write(key,new IntWritable(set.size())); } }
Output results
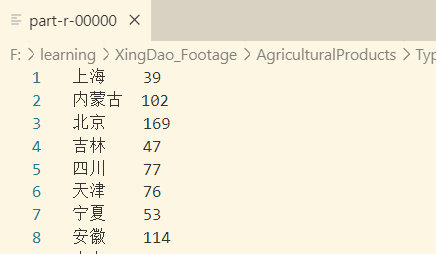
7. Types of Agricultural Products Owned by the Top 3 Provinces
requirement analysis
It takes three steps to complete the requirements
1. According to demand 6, the top three provinces can be obtained.
2. Export all types of agricultural products owned by the top three provinces (de-weighting)
For example:
Beijing Apple Beijing Orange Henan Yam
3. If the category in the second step result is regarded as key, the province as value, and the value is de-duplicated in reduce, then the value has three keys as the desired result.
code implementation
mapreduce1
public class ProTypeSum { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(ProTypeSum.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setMapperClass(PTSMapper.class); job.setReducerClass(PTSReducer.class); FileInputFormat.setInputPaths(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\FiveDays\\14.1.1\\part-m-00000")); FileOutputFormat.setOutputPath(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\TypeOfAgricultura\\ThreeType")); job.waitForCompletion(true); } } class PTSMapper extends Mapper<LongWritable,Text,Text,Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] line = value.toString().split("\t"); String type = line[0]; String provience = line[3]; //The first three results can be directly used as the key value criterion when the amount of data is small. If the amount of data is large, it is necessary. //Reducjoin method is used to distinguish key values. The method is detailed in Requirement 4. if (provience.equals("Shandong") || provience.equals("Beijing") || provience.equals("Jiangsu")){ context.write(new Text(provience),new Text(type)); } } } class PTSReducer extends Reducer<Text,Text,Text, Text>{ @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = values.iterator(); HashSet<String> set = new HashSet<String>(); while (iterator.hasNext()){ set.add(iterator.next().toString()); } String string; for (String str : set) { context.write(key,new Text(str)); } } }
mapreduce2
public class TopThreeType { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(ProTypeSum.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); job.setMapperClass(TTTMap.class); job.setReducerClass(TTTReduce.class); FileInputFormat.setInputPaths(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\TypeOfAgricultura\\ThreeType\\part-r-00000")); FileOutputFormat.setOutputPath(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\TypeOfAgricultura\\TopThreeSum1")); job.waitForCompletion(true); } } class TTTMap extends Mapper<LongWritable,Text,Text,Text>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] line = value.toString().split("\t"); String type = line[1]; String provience = line[0]; context.write(new Text(type),new Text(provience)); } } class TTTReduce extends Reducer<Text,Text,Text, NullWritable>{ @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = values.iterator(); HashSet<String> set = new HashSet<String>(); while (iterator.hasNext()){ set.add(iterator.next().toString()); } if (set.size() == 3){ context.write(new Text(key),NullWritable.get()); } } }
Output results
mapreduce1

mapreduce2

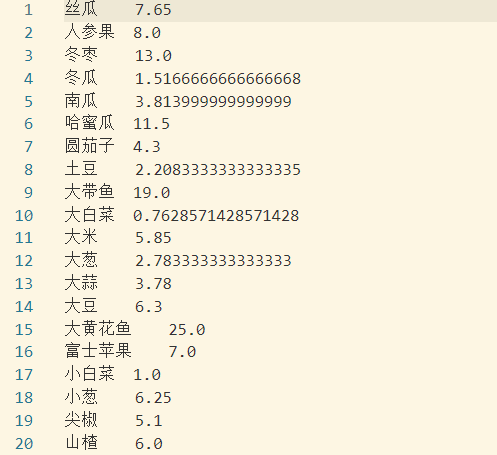
8. Calculate the price fluctuation trend of every agricultural product in Shanxi Province, that is, calculate the daily average price.
A formula for calculating the average price of a certain agricultural product: PAVG = PM1 + PM2 + (...) + PMn-max-min(P)/(N-2) where P denotes price and Mn denotes market, i.e. agricultural market. PM1 denotes the price of M1 agricultural product market, Max (P) denotes the maximum price and min (P) the minimum price.
requirement analysis
Simply put, in Shanxi Province, there will be many markets selling the same product in a day, and the prices are different. We need to get rid of one of the highest prices and one of the lowest prices to get the average.
It should be noted that when there are less than two kinds of pricing for a product, the average value can only be calculated by ordinary method, and the maximum value can not be removed.
According to the demand, it can be done in two steps.
The first step is to find out how many different prices of different varieties in Shanxi Province can be set in a day, and the specific value of these prices.
The second step is to decide how to average the price according to the quantity of the price.
code implementation
mapreduce1
public class PSETL { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(PSETL.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); job.setMapperClass(PSETLMapper.class); job.setReducerClass(PSETLReducer.class); FileInputFormat.setInputPaths(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\FiveDays\\14.1.1\\part-m-00000")); FileOutputFormat.setOutputPath(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\PriceStatistics\\PSETL")); job.waitForCompletion(true); } } class PSETLMapper extends Mapper<LongWritable,Text,Text,Text>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] lines = value.toString().split("\t"); String type = lines[0]; String provience = lines[3]; String marketName = lines[2]; String price = lines[1]; if (provience.equals("Shanxi")){ context.write(new Text(type),new Text(marketName + "," + price )); } } } class PSETLReducer extends Reducer<Text,Text,Text, Text>{ @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = values.iterator(); HashSet<String> set = new HashSet<String>(); while (iterator.hasNext()){ String it = iterator.next().toString(); set.add(it); } String price = ""; for (String str : set){ String[] prices = str.split(","); String prMid = prices[1]; price += prMid + ","; } price = price.substring(0,price.length() -1); context.write(key,new Text(String.valueOf(set.size()) + "\t" + price)); } }
mapreduce2
public class PSMain { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(PSMain.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); job.setMapperClass(PSMapper.class); //Set reduce number to 0 job.setNumReduceTasks(0); FileInputFormat.setInputPaths(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\PriceStatistics\\PSETL\\part-r-00000")); FileOutputFormat.setOutputPath(job,new Path("F:\\learning\\XingDao_Footage\\AgriculturalProducts\\PriceStatistics\\avg")); job.waitForCompletion(true); } } class PSMapper extends Mapper<LongWritable,Text,Text,DoubleWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //Input line String[] line = value.toString().split("\t"); //Split input behavior name num priceLine String name = line[0]; int num = Integer.parseInt(line[1]); String priceLine = line[2]; //priceLine Segmentation String[] priceArray = priceLine.split(","); //Declared average double avg = 0; if (num == 1){ avg = Double.parseDouble(priceArray[0]); context.write(new Text(name),new DoubleWritable(avg)); }else if (num == 2){ double x = Double.parseDouble(priceArray[0]); double y = Double.parseDouble(priceArray[1]); avg = (x+y)/2; context.write(new Text(name),new DoubleWritable(avg)); }else if (num > 2){ double sum = 0.00; double min = 99999999; double max = 0.00; for (String x : priceArray) { double y = Double.parseDouble(x); if (y > max){ max = y; } if (y < min){ min = y; } sum += y; } avg = (sum-max-min)/(num-2); context.write(new Text(name),new DoubleWritable(avg)); } } }
Output results
mapreduce1

mapreduce2