multiprocessing Multiprocess Crawling Knows the User
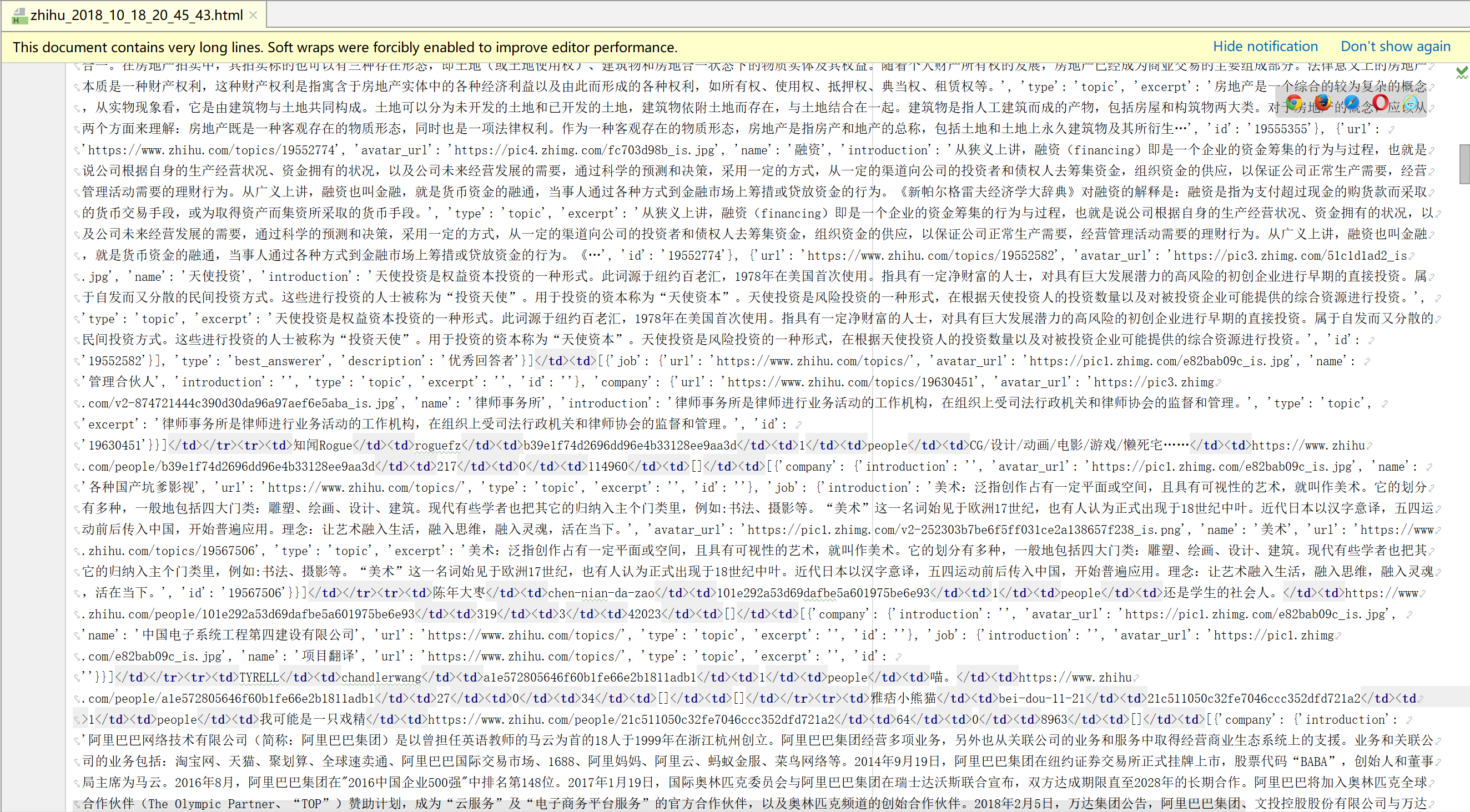
Crawl content screenshots

ControlNode Control Node Part
NodeManger - Control Scheduler
import time
from multiprocessing.managers import BaseManager
from multiprocessing import Process, Queue
from DataOutput import DataOutput
from MemberManager import MemberManager
class NodeManager(object):
def start_Manager(self,member_q,result_q):
BaseManager.register('get_task_queue',callable=lambda:member_q)
BaseManager.register('get_result_queue',callable=lambda:result_q)
manager = BaseManager(address=('', 8001), authkey='zhihuuser'.encode('utf-8'))
return manager
def member_manager_proc(self,member_q,con_q,root_member):
member_manager = MemberManager()
member_manager.add_new_member(root_member)
while True:
while(member_manager.has_new_member()):
new_member = member_manager.get_new_member()
member_q.put(new_member)
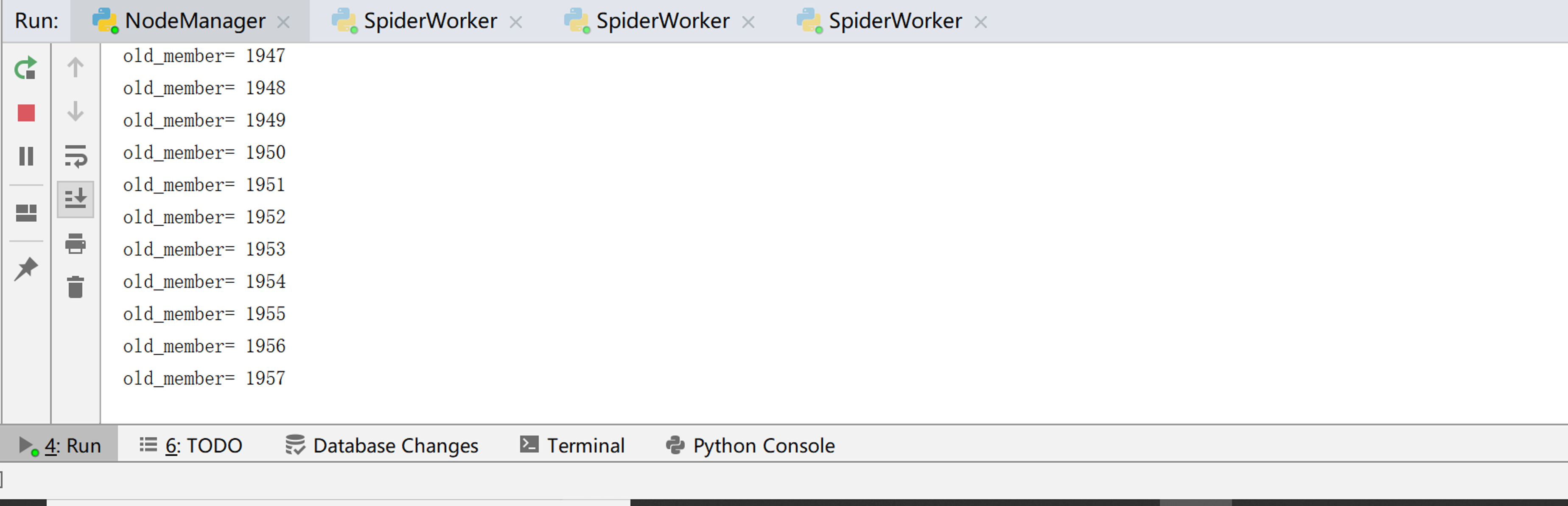
print('old_member=',member_manager.old_member_size())
if(member_manager.old_member_size()>2000):
member_q.put('end')
print('Control Node Initiates End Notification!')
member_manager.save_progress('new_members.txt',member_manager.new_members)
member_manager.save_progress('old_members.txt',member_manager.old_members)
return
try:
members = con_q.get()
member_manager.add_new_members(members)
except BaseException as e:
time.sleep(0.1)
def result_solve_proc(self,result_q,con_q,store_q):
while(True):
try:
if not result_q.empty():
content = result_q.get(True)
if content['new_members']=='end':
print('The result analysis process receives notification and then ends!')
store_q.put('end')
return
con_q.put(content['new_members'])
store_q.put(content['data'])
else:
time.sleep(0.1)
except BaseException as e:
time.sleep(0.1)
def store_proc(self,store_q):
output = DataOutput()
while True:
if not store_q.empty():
data = store_q.get()
if data=='end':
print('Storage process receives notification and ends!')
output.ouput_end(output.filepath)
return
output.store_data(data)
else:
time.sleep(0.1)
pass
if __name__=='__main__':
member_q = Queue()
result_q = Queue()
store_q = Queue()
con_q = Queue()
node = NodeManager()
manager = node.start_Manager(member_q,result_q)
member_manager_proc = Process(target=node.member_manager_proc, args=(member_q,con_q,'excited-vczh',))
result_solve_proc = Process(target=node.result_solve_proc, args=(result_q,con_q,store_q,))
store_proc = Process(target=node.store_proc, args=(store_q,))
member_manager_proc.start()
result_solve_proc.start()
store_proc.start()
manager.get_server().serve_forever()
MemberManger - Knowing User Manager
import pickle
import hashlib
class MemberManager(object):
def __init__(self):
self.new_members = self.load_progress('new_members.txt')
self.old_members = self.load_progress('old_members.txt')
def load_progress(self,path):
print('[+] Loading progress from files: %s' % path)
try:
with open(path, 'rb') as f:
tmp = pickle.load(f)
return tmp
except:
print('[!] No progress document, Establish: %s' % path)
return set()
def save_progress(self,path,data):
with open(path, 'wb') as f:
pickle.dump(data, f)
def has_new_member(self):
return self.new_member_size()!=0
def get_new_member(self):
new_member = self.new_members.pop()
m = hashlib.md5()
m.update(new_member.encode("utf-8"))
self.old_members.add(m.hexdigest()[8:-8])
return new_member
def add_new_member(self,member):
if member is None:
return
m = hashlib.md5()
m.update(member.encode('utf-8'))
member_md5 = m.hexdigest()[8:-8]
if member not in self.new_members and member_md5 not in self.old_members:
self.new_members.add(member)
def add_new_members(self,members):
if members is None or len(members)==0:
return
for member in members:
self.add_new_member(member)
def new_member_size(self):
return len(self.new_members)
def old_member_size(self):
return len(self.old_members)
Data Output - Data Storage
import codecs
import time
class DataOutput(object):
def __init__(self):
self.filepath='zhihu_%s.html'%(time.strftime("%Y_%m_%d_%H_%M_%S", time.localtime()) )
self.output_head(self.filepath)
self.datas=[]
def store_data(self,data):
if data is None:
return
self.datas.append(data)
if len(self.datas)>10:
self.output_html(self.filepath)
def output_head(self,path):
fout=codecs.open(path,'w',encoding='utf-8')
fout.write("<html>")
fout.write(r'''<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />''')
fout.write("<body>")
fout.write("<table>")
fout.close()
def output_html(self,path):
fout=codecs.open(path,'a',encoding='utf-8')
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>" % data['name'])
fout.write("<td>%s</td>" % data['member'])
fout.write("<td>%s</td>" % data['id'])
fout.write("<td>%s</td>" % data['gender'])
fout.write("<td>%s</td>" % data['type'])
fout.write("<td>%s</td>" % data['headline'])
fout.write("<td>%s</td>" % data['url'])
fout.write("<td>%s</td>" % data['answer_count'])
fout.write("<td>%s</td>" % data['articles_count'])
fout.write("<td>%s</td>" % data['follower_count'])
fout.write("<td>%s</td>" % data['badge'])
fout.write("<td>%s</td>" % data['employments'])
fout.write("</tr>")
self.datas=[]
fout.close()
def ouput_end(self,path):
fout=codecs.open(path,'a',encoding='utf-8')
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
fout.close()
SpiderNode crawler node section
SpiderWorker-Crawler Scheduler
from multiprocessing.managers import BaseManager
from Downloader import HtmlDownloader
from Parser import HtmlParser
class SpiderWork(object):
def __init__(self):
BaseManager.register('get_task_queue')
BaseManager.register('get_result_queue')
server_addr = '127.0.0.1'
print(('Connect to server %s...' % server_addr))
self.m = BaseManager(address=(server_addr, 8001), authkey='zhihuuser'.encode('utf-8'))
self.m.connect()
self.task = self.m.get_task_queue()
self.result = self.m.get_result_queue()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
print('init finish')
def crawl(self):
while(True):
try:
if not self.task.empty():
member = self.task.get()
if member =='end':
print('The control node notifies the crawler node to stop working...')
self.result.put({'new_members':'end','data':'end'})
return
print('The crawler node is parsing:%s'%member.encode('utf-8'))
f_html, m_html = self.downloader.download(member)
new_members,data = self.parser.parse(f_html, m_html)
self.result.put({"new_members":new_members,"data":data})
except EOFError as e:
print("Failure to connect working nodes")
return
except Exception as e:
print(e)
print('Crawl fail ')
if __name__=="__main__":
spider = SpiderWork()
spider.crawl()
Downloader - HTML Downloader
import requests
from requests.exceptions import ConnectionError
class HtmlDownloader(object):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
folowees_url = 'https://www.zhihu.com/api/v4/members/{member}/followees'
member_url = 'https://www.zhihu.com/api/v4/members/{member}'
follwees_query = {
'include': 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics',
'offset': None,
'limit': 20
}
member_query = {
'include': 'allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics'
}
def download(self,member):
if member is None:
return None
followees_html = self.download_followees(member)
member_html = self.download_member(member)
return followees_html,member_html
def download_followees(self,member):
r = requests.get(self.folowees_url.format(member=member), data=self.follwees_query, headers=self.headers)
if r.status_code==200:
r.encoding='utf-8'
followees_html = r.text
return followees_html
if r.status_code==403:
return self.download_followees(member)
def download_member(self,member):
offset = 0
self.follwees_query['offset'] = offset
offset += 20
r = requests.get(self.member_url.format(member=member), data=self.member_query,headers=self.headers)
if r.status_code==200:
r.encoding='utf-8'
followees_html = r.text
return followees_html
if r.status_code == 403:
return self.download_followees(member)
Parser - HTML parser
import urllib.parse
import json
import requests
class HtmlParser(object):
def parse(self, followees_html, member_html):
if followees_html is None or member_html is None:
return
new_members = self.parse_followees(followees_html)
new_data = self.parse_member(member_html)
return new_members,new_data
def parse_followees(self, html):
if html is None:
return
result = json.loads(html)
new_members = []
if 'data' in result.keys():
for data in result.get('data'):
print(data.get('url_token'))
new_member = data.get('url_token')
print(new_member)
new_members.append(new_member)
return new_members
def parse_member(self,html):
if html is None:
return
result = json.loads(html)
data={}
data['member']= result.get('url_token')
data['id']=result.get('id')
data['name']= result.get('name')
data['headline']= result.get('headline')
data['url']= result.get('url')
data['gender']=result.get('gender')
data['type']=result.get('type')
data['badge']=result.get('badge')
data['answer_count']=result.get('answer_count')
data['articles_count']=result.get('articles_count')
data['follower_count']=result.get('follower_count')
data['employments']=result.get('employments')
return data