1, Introduction to libSVM
libSVM is a set of support vector machine library developed by Professor Chih Jen Lin of Taiwan in 2001. This library has fast operation speed and can easily classify or regress data. libSVM has become the most widely used SVM Library in China because of its small program, flexible application, few input parameters, open source and easy expansion.
Format of training text of libSVM
First, you must understand the libSVM data format, which is as follows:
Label 1:value 2:value ....
Label: it is the identification of the category. For example, 1 - 1 mentioned in train.model in the previous section can be set at will, such as - 10, 0, 15. Of course, if it is regression, this is the target value, so we should be realistic. Value: it is the data to be trained. From the perspective of classification, it is the characteristic value, and the data are separated by spaces. If the characteristic value is 0, the preceding characteristic colon (called sequence number for the moment) can be discontinuous. From the perspective of programming, this can reduce the use of memory and improve the operation speed of matrix inner product.
2, Download libSVM
https://www.csie.ntu.edu.tw/~cjlin/libsvm/
3, Making iris dataset using LibSVM
Open the svm-toy.exe program and manually build the iris data set

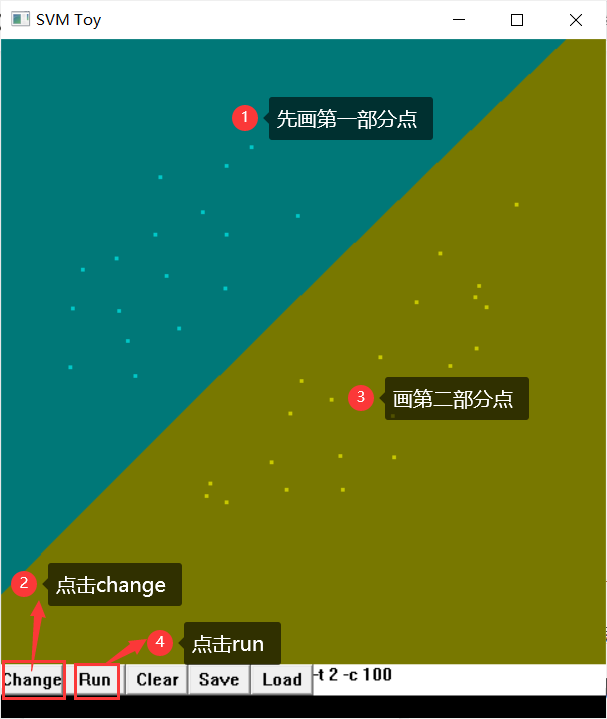
Then click Save to save as a TXT file, and then clear to draw a new one and save it.
The saved file format is as follows:
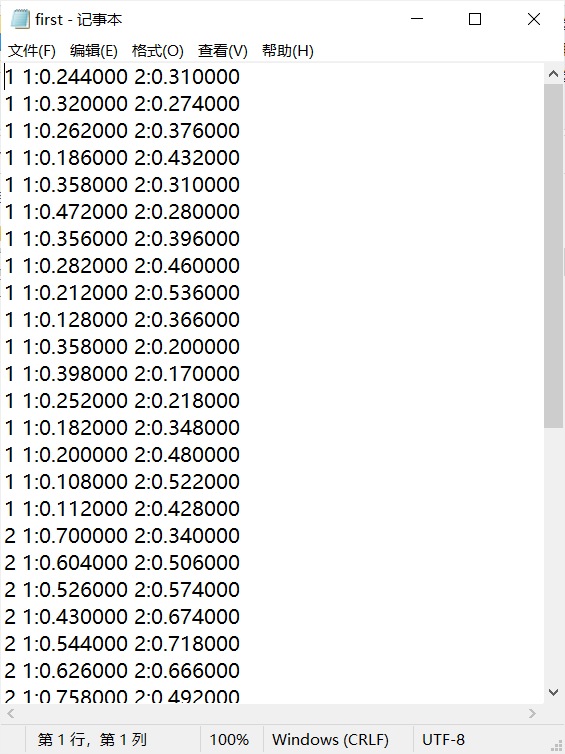
4, Write code for classification training
Create a new JAVA project using IDEA, create a new libsvm package under src, and copy the following files to the newly created libsvm package:
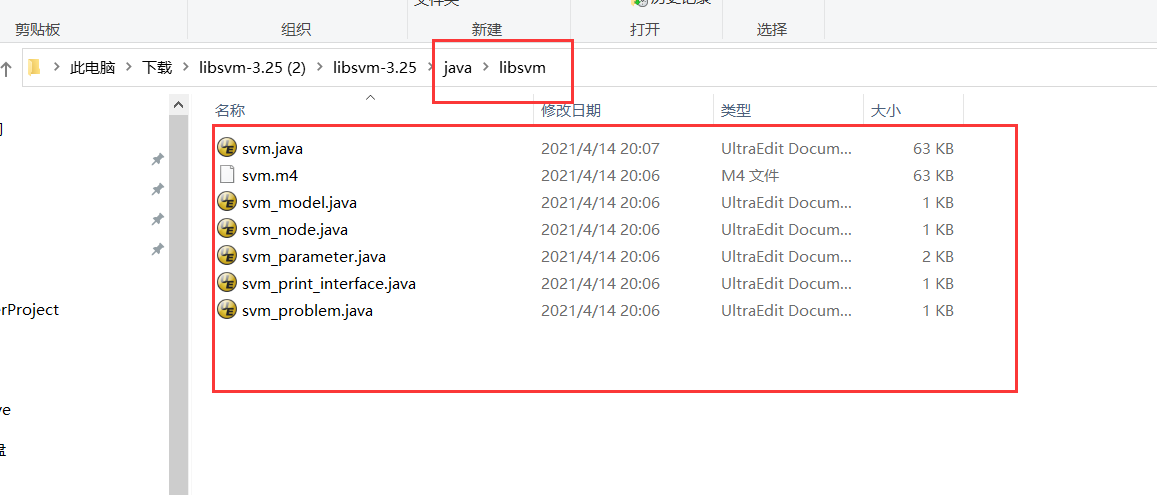
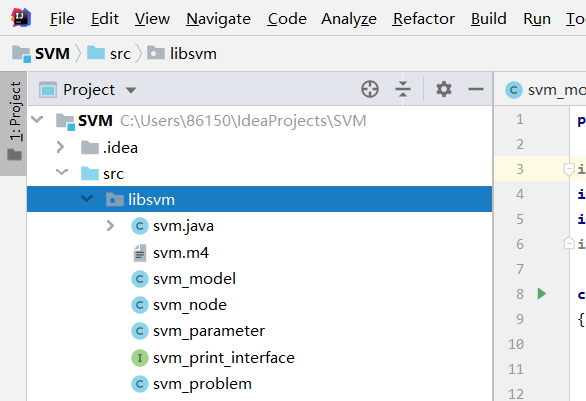
Create a new test package and copy the following files to the test package:

Create a new Test class.
The IDEA project structure is as follows:

Write the following code in the Test class:
package test;
import java.io.IOException;
public class Test {
public static void main(String args[]) throws IOException {
//Store data and save model file path
String filepath = "C:\\Users\\86150\\Downloads\\libsvm-3.25 (2)\\";
/*
* -s Set svm type: the default value is 0
* 0– C-SVC
* 1 – v-SVC
* 2 – one-class-SVM
* 3 –ε-SVR
* 4 – n - SVR
*
* -t Set the kernel function type. The default value is 2
* 0 --Linear kernel
* 1 --Polynomial kernel
* 2 -- RBF nucleus
* 3 -- sigmoid nucleus
*
* -d degree:Set the value of degree in the polynomial kernel. The default value is 3
*
* -c cost: Set C-SVC ε- SVR, N - penalty coefficient C in SVR, the default value is 1;
*/
String[] arg = {"-s","0","-c","10","-t","0",filepath+"first.txt",filepath+"line.txt"};
String[] arg1 = {filepath+"second.txt",filepath+"line.txt",filepath+"predict1.txt"};
System.out.println("----------------linear-----------------");
//Training function
svm_train.main(arg);
svm_predict.main(arg1);
arg[5]="1";
arg[7]=filepath+"poly.txt";//Output file path
arg1[1]=filepath+"poly.txt";
arg1[2]=filepath+"predict2.txt";
System.out.println("---------------polynomial-----------------");
svm_train.main(arg);
svm_predict.main(arg1);
arg[5]="2";
arg[7]=filepath+"RBF.txt";
arg1[1]=filepath+"RBF.txt";
arg1[2]=filepath+"predict3.txt";
System.out.println("---------------Gaussian kernel-----------------");
svm_train.main(arg);
svm_predict.main(arg1);
}
}
Build run:

optimization finished,#iter = 30 //30 indicates the number of iterations,
nu = 0.34890408019098784 / / parameters of kernel function
obj = -100.54604543265125, rho = -6.457424952803739
//obj is the optimal target value of the minimum value obtained by solving the quadratic programming transformed by SVM for the even problem, and Rho is the deviation term (also b,wx+b) in the decision function / / SGN (W ^ x rho).
nSV = 17, nBSV = 14 //nSV is the number of support vectors, and nBSV is the number of support vectors on the boundary
Total nSV = 17 / total number of support vectors
Accuracy = 97.01492537313433% (65/67) (classification) / / accuracy

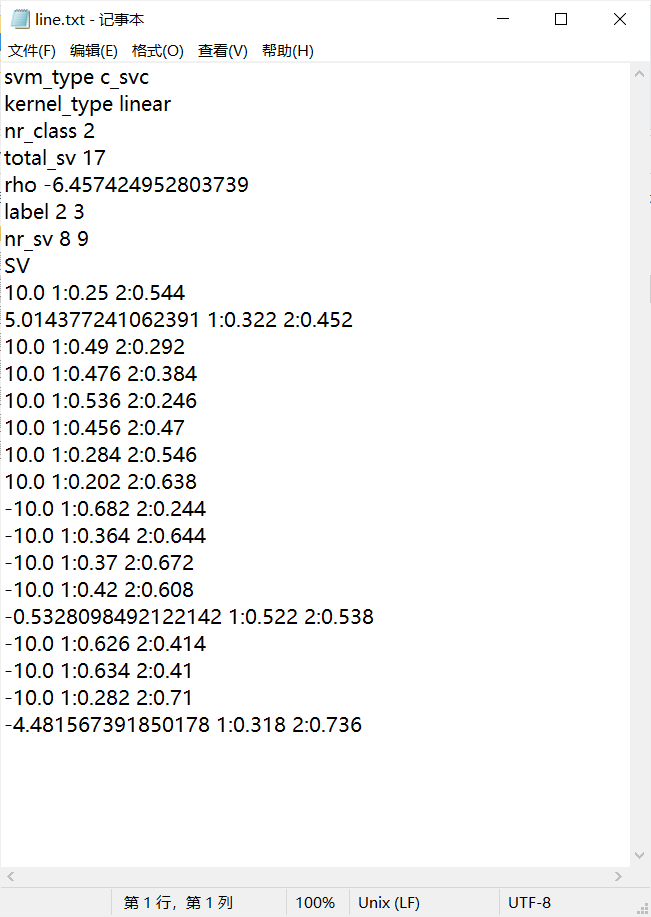
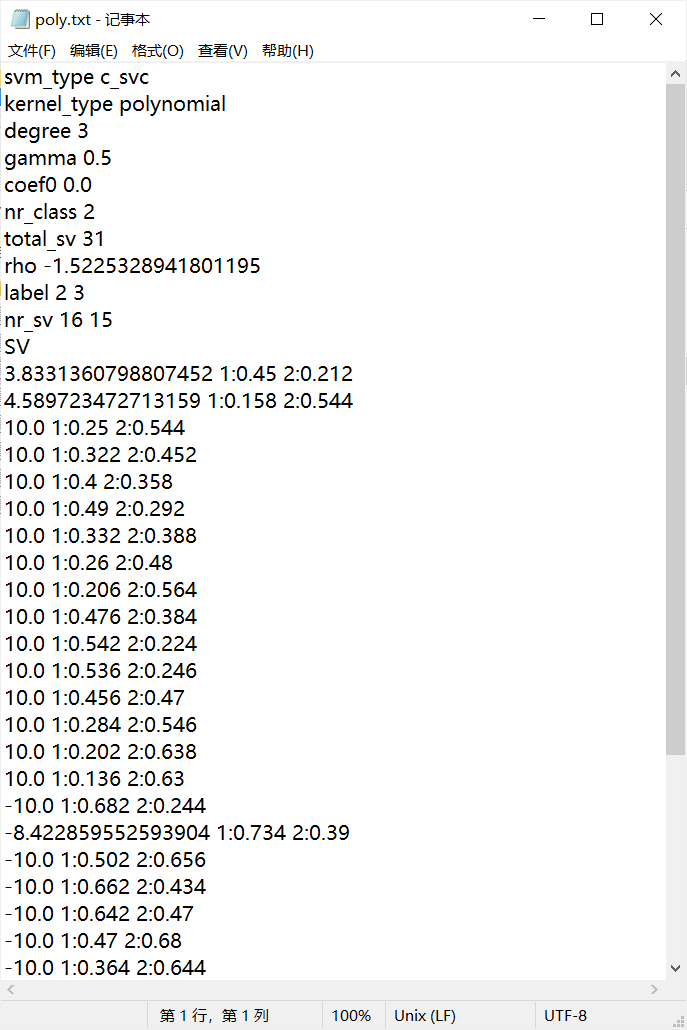
Data files obtained after linear, polynomial and Gaussian kernel classification training using LibSVM tool:
Linear kernel:
Polynomial:
Gaussian kernel:
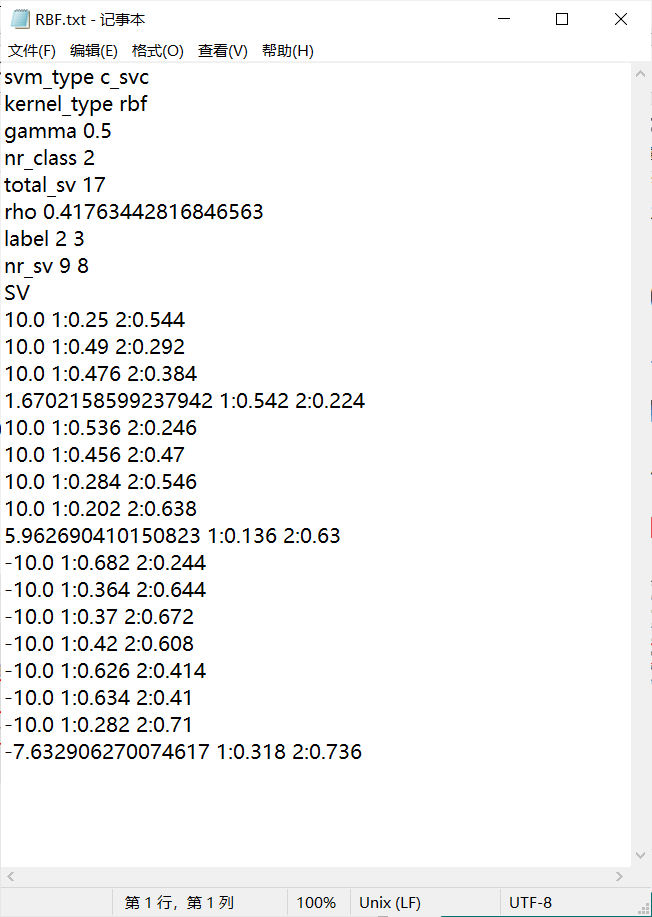
The results show that the model accuracy of polynomial and Gaussian kernel training is slightly higher than that of linear training.
Mathematical formula of decision tree:
f(x)=SV*x+rho
5, Summary
The decision tree is trained with LibSVM tool, and the data set is constructed by ourselves, which can be displayed intuitively in the graphical interface. It can also be used flexibly in the project by using the programming language codes such as python and java provided in the tool, and obtain the output of correlation coefficients and prediction results.
reference material
https://www.cnblogs.com/jiahuiyu/p/5415936.html
https://blog.csdn.net/qq_45659777/article/details/121320835?spm=1001.2014.3001.5501