Masked Autoencoders Are Scalable Vision Learners
MAE proposes a self supervised training method, which can effectively and train the model and improve the performance of the model. This project realizes the self-monitoring training part and visualizes the training process.
network structure
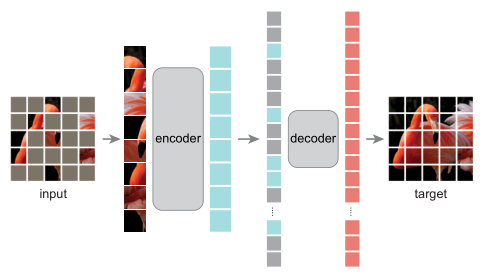
The structure of MAE is relatively simple. It is composed of encoder and decoder. Here, both encoder and decoder adopt Transformer structure. After the input pictures are divided into patches, a certain proportion of patches are masked (75% in the paper). unmasked patches are sent to the encoder to obtain encoded patches. The combination of masked tokens and encoded patches is introduced to send them to the decoder. The output target of the decoder is the original image, and the loss is only calculated on the masked patches.
Details to note:
1. Masking: after the image is divided into non overlapping patches, the masked patches are selected to obey uniform distribution;
2. Encoder: encoder only works on unmasked patches. embedding patches need to be added with position embeddings;
3. Decoder: the input of decoder is composed of encoded patches and mask tokens. mask token is a learnable parameter shared by parameters. At the same time, position embeddings is added to mask tokens to represent location information;
4. Reconstruction target: the decoder outputs each pixel value of the target picture (input the original picture), and the loss is only calculated in masked patches;
5. Implementation:
(1) Generate a token for each patch;
(2) shuffle all tokens, and then remove some tokens according to the masking ratio;
(3) After obtaining encoded tokens, merge mask tokens and encoded tokens. Note that there is no need to unsuffle here, and simply concat;
Contents of the project
This project is trained in the verification machine of ImageNet 1K, 4W of 5W pictures are used as training data, and the remaining 1W is reserved for verification. Because the training is relatively slow, only MAE is pre trained here. The masking ratio is 0.5, and only 200 epochs are trained. Due to less data and small epochs, the effect is not very good, but the output change process of MAE can be seen, and there is no fine tuning process.
Output change
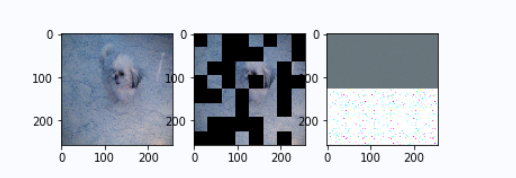
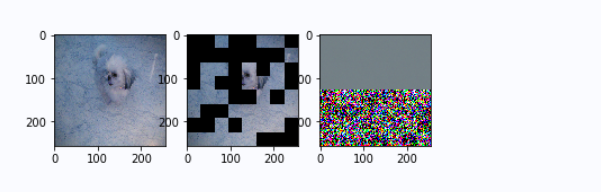
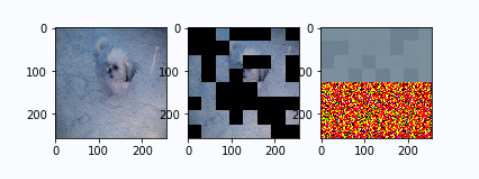
On the left is the original image, in the middle is the masked image, and on the right is the prediction result of mae.
epoch 1:
epoch 10:
epoch 200:
other
reference resources: vit-pytorch
Thank you very much for teacher Zhu Er's course (teacher Zhu is awesome): Learning visual Transformer from scratch
Aistudio homepage: https://aistudio.baidu.com/aistudio/personalcenter/thirdview/312316
Passing masters, please like it and give me some fighting power.
# Processing data sets
%cd ~/data/data89857/
!tar -xf ILSVRC2012mini.tar
%cd ~/
# There is a problem with the txt file of the dataset. Fix the train_list content, run it once
import os
train_file_path = '/home/aistudio/data/data89857/ILSVRC2012mini/train_list.txt'
data = []
with open(train_file_path, 'r') as f:
lines = f.readlines()
for line in lines:
_, info = line.split('/')
data.append(info)
with open(train_file_path, 'w') as f:
f.writelines(data)
ViT
The implementation of ViT will not be explained too much. Note: since the reconstruction target of MAE is the pixel value of the original image, do not use convolution for patch embedding. First divide the original image into patches, and then use linear embedding.
# VIT
import paddle
from paddle import nn
class PreNorm(nn.Layer):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x):
return self.fn(self.norm(x))
class Mlp(nn.Layer):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout),
)
def forward(self, x):
x = self.mlp(x)
return x
class Identity(nn.Layer):
def __init__(self):
super().__init__()
def forward(self, x):
return x
class Attention(nn.Layer):
def __init__(self, dim, heads=8, dim_head=64, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** (-0.5)
self.attend = nn.Softmax(axis = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias_attr=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout),
) if project_out else Identity()
def forward(self, x):
B, N, _ = x.shape
qkv = self.to_qkv(x).chunk(3, axis=-1)
q, k, v = map(lambda t: t.reshape([B, N, self.heads, -1]).transpose([0, 2, 1, 3]), qkv)
dots = paddle.matmul(q, k.transpose([0, 1, 3, 2])) * self.scale
attn = self.attend(dots)
out = attn.matmul(v)
out = out.transpose([0, 2, 1, 3]).flatten(2)
out = self.to_out(out)
return out
class Transformer(nn.Layer):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout=0.):
super().__init__()
self.layers = nn.LayerList()
for _ in range(depth):
self.layers.append(
nn.LayerList(
[
PreNorm(dim, Attention(dim, heads=heads, dim_head=dim_head, dropout=dropout)),
PreNorm(dim, Mlp(dim, mlp_dim, dropout=dropout)),
]
)
)
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
class PatchEmbedding(nn.Layer):
def __init__(self, image_size, patch_size, embed_dim=768, in_channels=3):
super().__init__()
image_height, image_width = image_size if isinstance(image_size, tuple) else (image_size, image_size)
self.patch_height, self.patch_width = patch_size if isinstance(patch_size, tuple) else (patch_size, patch_size)
assert image_height % self.patch_height == 0 and image_width % self.patch_width == 0, "Image dimensions must be divisible by the patch size."
self.p1, self.p2 = (image_height // self.patch_height), (image_width // self.patch_width)
self.num_patches = (image_height // self.patch_height) * (image_width // self.patch_width)
self.patch_embed = nn.Linear(in_channels * self.patch_height * self.patch_width, embed_dim)
def forward(self, x):
N, C, H, W = x.shape
patches = x.reshape([N, C, self.p1, self.patch_height, self.p2, self.patch_width]).transpose([0, 2, 4, 1, 3, 5]).reshape([N, self.num_patches, -1])
x = self.patch_embed(patches)
x = x.flatten(2)
return x, patches
class ViT(nn.Layer):
def __init__(
self,
image_size,
patch_size,
num_classes,
depth,
heads,
mlp_dim,
embed_dim=768,
pool='cls',
channels=3,
dim_head=64,
dropout=0,
embed_dropout=0.,
):
super().__init__()
assert pool in {'cls', 'mean'}, 'pool type nums be either cls(cls token) or mean (mean pooling).'
self.embed_dim = embed_dim
self.patch_embedding = PatchEmbedding(image_size, patch_size, embed_dim=embed_dim, in_channels=channels)
self.num_patches = self.patch_embedding.num_patches
self.pos_embedding = self.create_parameter(shape=[1, self.num_patches + 1, embed_dim], default_initializer=nn.initializer.KaimingNormal(0.02))
self.cls_token = self.create_parameter(shape=[1, 1, embed_dim])
self.dropout = nn.Dropout(embed_dropout)
self.transformer = Transformer(embed_dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(embed_dim),
nn.Linear(embed_dim, num_classes),
)
def forward(self, x):
x, patches = self.patch_embedding(x)
B, N, _ = x.shape
cls_tokens = paddle.tile(self.cls_token, [B, 1, 1])
x = paddle.concat([cls_tokens, x], axis=1)
x += self.pos_embedding[:, :(N + 1)]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(axis=1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
x = self.mlp_head(x)
return x
# if __name__ == '__main__':
# model = ViT(image_size=(256,256),
# patch_size=(32,32),
# num_classes=1000,
# embed_dim=1024,
# heads=8,
# depth=6,
# mlp_dim=2048, )
# x = paddle.randn([2, 3, 256, 256])
# y = model(x)
# print(x.shape, y.shape)
# paddle.summary(model, (4, 3, 256, 256))
MAE
The encoder of MAE is ViT, and the decoder is a transformer model.
import paddle
from paddle import nn
import paddle.nn.functional as F
class MAE(nn.Layer):
def __init__(self, encoder, decoder_dim, masking_ratio=0.75, decoder_depth=1, decoder_heads=8, decoder_dim_head=64):
super().__init__()
assert masking_ratio > 0 and masking_ratio < 1, 'masking ratio must in range (0, 1), but got {}.'.format(masking_ratio)
self.masking_ratio = masking_ratio
self.encoder = encoder
patch_dim = self.encoder.patch_embedding.patch_embed.weight.shape[0] # dim of each patch after division
self.enc_to_dec = nn.Linear(encoder.embed_dim, decoder_dim) if encoder.embed_dim != decoder_dim else Identity()
self.mask_token = self.create_parameter(shape=(1, 1, decoder_dim)) # mask_ Learnable parameters shared by token
self.decoder = Transformer(dim=decoder_dim, depth=decoder_depth, heads=decoder_heads, dim_head=decoder_dim_head, mlp_dim=decoder_dim*4) # decoder
self.decoder_pos_emb = nn.Embedding(encoder.num_patches, decoder_dim) # decoder position embedding
self.to_pixels = nn.Linear(decoder_dim, patch_dim)
def forward(self, x):
tokens, patches = self.encoder.patch_embedding(x) # Patches are the patches divided in the original diagram and used as the target
batch, num_patches, _ = tokens.shape # batch_size, num_patches, _
tokens = tokens + self.encoder.pos_embedding[:, 1:(num_patches + 1)]
# mask part of patches
num_masked = int(self.masking_ratio * num_patches)
rand_indices = paddle.rand(shape=[batch, num_patches]).argsort(axis=-1)
masked_indices, unmasked_indices = rand_indices[:, :num_masked], rand_indices[:, num_masked:]
# unmasked tokens to be encoded
batch_range = paddle.arange(batch)[:, None]
tokens = tokens[batch_range, unmasked_indices]
# masked_patches
masked_patches = patches[batch_range, masked_indices] # Losses are calculated only in masked patches
# transformer
encoded_tokens = self.encoder.transformer(tokens)
decoder_tokens = self.enc_to_dec(encoded_tokens)
# decoder embed
mask_tokens = paddle.tile(self.mask_token, [batch, num_masked, 1]) # decoder position embedding
mask_tokens = mask_tokens + self.decoder_pos_emb(masked_indices) # learned mask token
decoder_tokens = paddle.concat([mask_tokens, decoder_tokens], axis=1) # unshuffle is not required
decoded_tokens = self.decoder(decoder_tokens)
if self.training:
mask_tokens = decoded_tokens[:, :num_masked]
pred = self.to_pixels(mask_tokens) # N, num_unmasked, dim
loss = F.mse_loss(pred, masked_patches)
return loss
else:
image = patches.clone() # Graph after sampling
image.stop_gradient = True
image[batch_range, masked_indices] = 0 # mask sampling area
pred = self.to_pixels(decoded_tokens)
return pred, image
# if __name__ == '__main__':
# encoder = ViT(image_size=256,
# patch_size=32,
# num_classes=1000,
# embed_dim=1024,
# heads=8,
# depth=6,
# mlp_dim=2048)
# model = MAE(encoder, masking_ratio=0.75, decoder_dim=512, decoder_depth=6)
# x = paddle.randn([4, 3, 256, 256])
# y = model(x)
# print(x.shape, y.shape)
# paddle.summary(model, (4, 3, 256, 256))
dataset
# Build dataset
from paddle.io import Dataset, DataLoader
import paddle.vision.transforms as T
import cv2
import os
class ImageNetDataset(Dataset):
def __init__(self, data_dir, info_txt, mode='train', transforms=None):
self.data_dir = data_dir
self.image_paths, self.labels = self.get_info(info_txt)
self.mode = mode
self.transforms = transforms
def get_info(self, file_path):
paths = []
labels = []
with open(file_path, 'r') as f:
lines = f.readlines()
for line in lines:
image_name, label = line.strip().split(' ')
paths.append(os.path.join(self.data_dir, image_name))
labels.append(int(label))
return paths, labels
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
image_path = self.image_paths[idx]
label = self.labels[idx]
image = cv2.imread(image_path)
if self.transforms:
image = self.transforms(image)
if self.mode == 'train':
return image, label
else:
return image
# mae_train_trans = T.Compose(
# [
# T.Resize((256, 256)),
# T.RandomHorizontalFlip(),
# T.RandomVerticalFlip(),
# T.Transpose([2, 0, 1]),
# ]
# )
# if __name__ == '__main__':
# dataset = ImageNetDataset('/home/aistudio/data/data89857/ILSVRC2012mini/train', '/home/aistudio/data/data89857/ILSVRC2012mini/train_list.txt', mode='val', transforms=mae_train_trans)
# print(len(dataset))
# image = dataset[0]
# import matplotlib.pyplot as plt
# plt.imshow(image)
# plt.show()
Pre training MAE
# Auxiliary class
class AverageMeter:
def __init__(self):
self.val = 0.
self.count = 0.
def update(self, value, n=1):
self.val += value
self.count += n
def reset(self):
self.val = 0.
self.count = 0.
def __call__(self):
return self.val / self.count
# Set relevant parameters
import time
epoches = 2000
batch_size = 256
learning_rate = 0.00001
grad_clip_value = 10
# encoder param
patch_size = (32, 32)
image_size = (256, 256)
num_classes = 1000
encoder_embed_dim = 1024
encoder_heads = 8
encoder_depth = 6
encoder_mlp_dim = 2048
# decoder params
masking_ratio = 0.5
decoder_dim = 512
decoder_depth = 6
mae_train_trans = T.Compose(
[
T.Resize((256, 256)),
T.RandomHorizontalFlip(),
T.RandomVerticalFlip(),
T.Transpose([2, 0, 1]),
]
)
# mode = 'val', because label is not required for pre training, it can also be added
mae_dataset = ImageNetDataset('/home/aistudio/data/data89857/ILSVRC2012mini/train', '/home/aistudio/data/data89857/ILSVRC2012mini/train_list.txt', mode='val', transforms=mae_train_trans)
mae_dataloader = DataLoader(
mae_dataset,
batch_size=batch_size,
shuffle=True,
drop_last=True,
)
# MAE model
encoder = ViT(image_size=image_size,
patch_size=patch_size,
num_classes=num_classes,
embed_dim=encoder_embed_dim,
heads=encoder_heads,
depth=encoder_depth,
mlp_dim=encoder_mlp_dim)
model = MAE(encoder, masking_ratio=masking_ratio, decoder_dim=decoder_dim, decoder_depth=decoder_depth)
# paddle.summary(model, (4, 3, 256, 256))
clip = paddle.nn.ClipGradByValue(min=-grad_clip_value, max=grad_clip_value)
optimizer = paddle.optimizer.Momentum(learning_rate=learning_rate, parameters=model.parameters(), grad_clip=clip)
# Test the function and visualize the training process with a picture
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
def reconstruct(x, image_size, patch_size):
"""reconstrcunt [batch_size, num_patches, embedding] -> [batch_size, channels, h, w]"""
B, N, _ = x.shape # batch_size, num_patches, dim
p1, p2 = image_size[0] // patch_size[0], image_size[1] // patch_size[1]
x = x.reshape([B, p1, p2, -1, patch_size[0], patch_size[1]]).transpose([0, 3, 1, 4, 2, 5]).reshape([B, -1, image_size[0], image_size[1]])
return x
def test(model):
"""
Use the model to predict a picture and check the effect to see the change trend predicted in the model training process
"""
model.eval()
image_path = '/home/aistudio/data/data89857/ILSVRC2012mini/val/ILSVRC2012_val_00040043.JPEG'
source_image = cv2.imread(image_path)
trans = T.Compose(
[
T.Resize((256, 256)),
T.Transpose([2, 0, 1]),
]
)
source_image = trans(source_image)
image = paddle.to_tensor(source_image, dtype='float32').unsqueeze(0)
pred, masked_img = model(image)
pred_img = reconstruct(pred, image_size, patch_size)
masked_img = reconstruct(masked_img, image_size, patch_size)
masked_img = masked_img[0].numpy()
masked_img = np.clip(masked_img, 0, 255).astype('uint8')
masked_img = np.transpose(masked_img, [1, 2, 0])
pred_img = pred_img[0].numpy()
pred_img = np.clip(pred_img, 0, 255).astype('uint8')
pred_img = np.transpose(pred_img, [1, 2, 0])
plt.subplot(1, 3, 1)
plt.imshow(source_image.transpose([1, 2, 0]))
plt.subplot(1, 3, 2)
plt.imshow(masked_img)
plt.subplot(1, 3, 3)
plt.imshow(pred_img)
plt.show()
return pred_img
# train
model.train()
for epoch in range(1, epoches + 1):
losses = AverageMeter()
for batch_id, image in enumerate(mae_dataloader):
image = image.astype('float32')
loss = model(image)
losses.update(loss.numpy()[0])
loss.backward()
optimizer.step()
optimizer.clear_grad()
lr = optimizer.get_lr()
if batch_id % 50 == 0:
print(time.asctime( time.localtime(time.time()) ), "Epoch: {}/{}, Batch id: {}, lr: {}, loss: {}".format(epoch, epoches, batch_id, lr, losses()))
obj = {
'model': encoder.state_dict(),
'epoch': epoch,
}
paddle.save(obj, 'model.pdparams')
obj = {
'model': model.state_dict(),
'epoch': epoch,
}
paddle.save(obj, 'mae.pdparams')
test(model) # This will become eval mode
model.train() # Switch to train mode
Please click here View the basic usage of this environment
Please click here for more detailed instructions.