preface
This learning note is the learning content of Alibaba cloud Tianchi Longzhu plan machine learning training camp. The learning links are:
https://tianchi.aliyun.com/specials/promotion/aicampml
Competition link: Come and explore happiness together!
Friendly reminder: I just started learning machine learning. Some places may not be mature. I refer to some forum notes. I can write it all by the selfless sharing of all leaders. I hope it will help you!
1, Game problem understanding
1.1 experimental environment
In the experimental environment of Alibaba cloud Tianchi, first import the dataset into DSW.
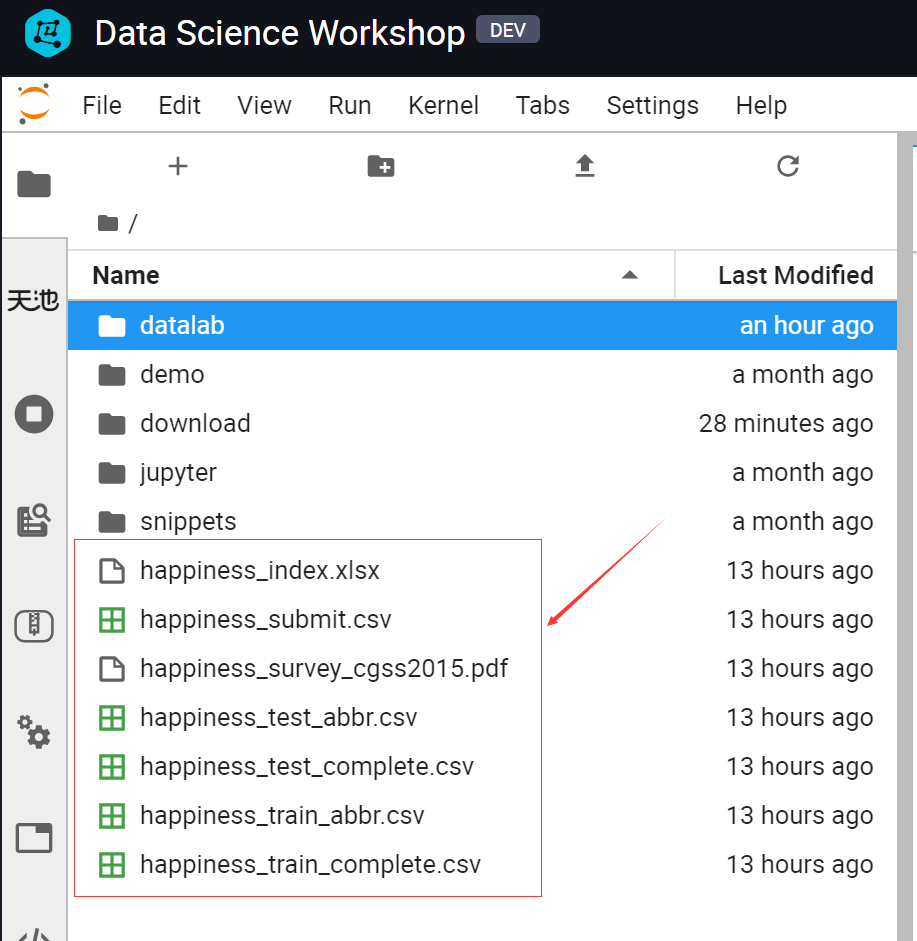
1.2 background introduction
The data of the competition is the data in the survey results of the official 2015 China Comprehensive Social Survey (CGSS) questionnaire (resident questionnaire), which contains 139 dimensions, including individual variables (gender, age, region, occupation, health, marriage and political outlook, etc.) and family variables (parents, spouses, children, family capital, etc.), social attitude (fairness, credit, public service), etc.
The competition requires the use of the given 139 dimensional characteristics and more than 8000 groups of data to predict personal well-being (the predicted values are 1, 2, 3, 4 and 5, of which 1 represents the lowest well-being and 5 represents the highest well-being).
1.3 data information
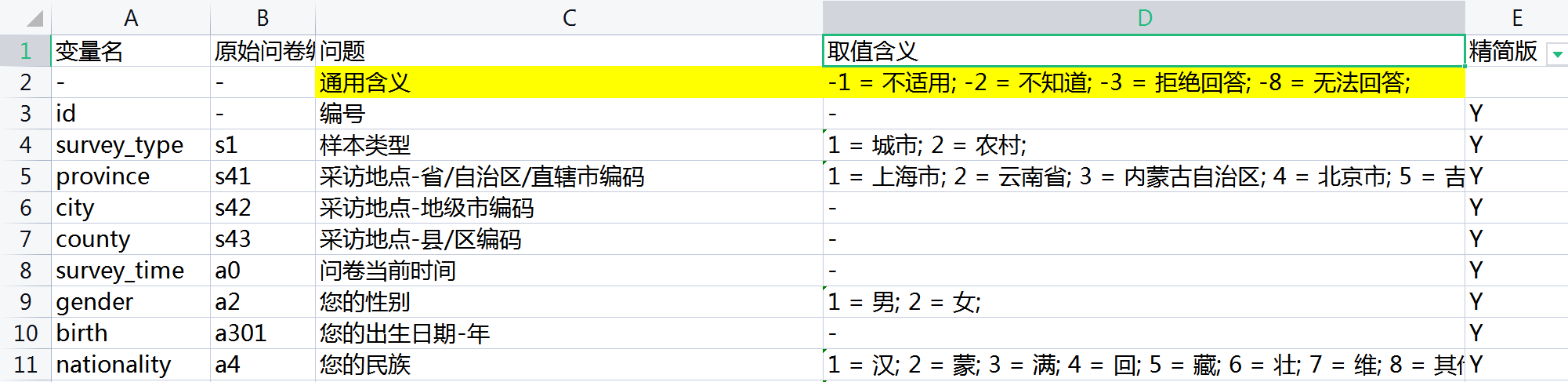
happiness_index.xlsx: 142 rows and 5 columns. The specific fields of this competition question are introduced, including the questionnaire question corresponding to each variable and the meaning of variable value. In fact, it is the 139 dimensional feature that can be used.
happiness_submit.csv: 2969 lines, 2 columns, and the platform submits the result sample file.
happiness_survey_cgss2015.pdf: 2015 annual questionnaire of China Comprehensive Social Survey (CGSS) (resident questionnaire)
happiness_test_abbr.csv: 2969 rows, 41 columns, reduced version data.
happiness_test_complete.csv: 2969 rows, 139 columns, full version data.
happiness_train_abbr.csv: 8001 rows, 42 columns, reduced version data.
happiness_train_complete.csv: 8001 rows, 140 columns, full version data.
Here, I use the full version of the data.
1.4 evaluation index
The final evaluation index is the mean square error MSE,

The smaller the submitted mean square error, the better the representative result.
2, Exploratory data analysis (EDA) & Feature Engineering
2.1 why exploratory data analysis
- Understanding data
– data type size (what configuration is needed, how expensive is the competition)
– whether the data is clean (obviously wrong data, such as height 5m...)
– what type of tag is it and whether format conversion is required?.. (DataFrame.info()) - Prepare for data modeling
– whether the construction of offline verification set may cross? (observe the data distribution)
– are there any strange phenomena? Prepare for Feature Engineering: for example, periodic change of time series
2.2 what data should exploratory data analysis look at
1. Data set size and field type: how big the data is and what type each field is
2. Missing value: whether the missing value is serious and whether the missing value has special meaning
3. Redundancy between features: for example, if the height is expressed in cm and m, there is redundancy
4. Whether there is time information: potential crossing problems
5. Label distribution: whether the category distribution is unbalanced, etc
6. Distribution of training set and test set: there are many fields in the test set, but there are no features in the training set
7. Univariate / multivariate distribution: be familiar with the distribution of features and the relationship with labels
2.3 data preprocessing
Import package
import os
import time
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
from datetime import datetime
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score, roc_curve, mean_squared_error,mean_absolute_error, f1_score
import lightgbm as lgb
import xgboost as xgb
from sklearn.ensemble import RandomForestRegressor as rfr
from sklearn.ensemble import ExtraTreesRegressor as etr
from sklearn.linear_model import BayesianRidge as br
from sklearn.ensemble import GradientBoostingRegressor as gbr
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.linear_model import LinearRegression as lr
from sklearn.linear_model import ElasticNet as en
from sklearn.kernel_ridge import KernelRidge as kr
from sklearn.model_selection import KFold, StratifiedKFold,GroupKFold, RepeatedKFold
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn import preprocessing
import logging
import warnings
warnings.filterwarnings('ignore') #Eliminate warning
#Import data
train = pd.read_csv("happiness_train_complete.csv", parse_dates=['survey_time'],encoding='latin-1')
test = pd.read_csv("happiness_test_complete.csv", parse_dates=['survey_time'],encoding='latin-1') #latin-1 is downward compatible with ASCII
#Observation data size train.shape

test.shape

#Simple view data train.head()
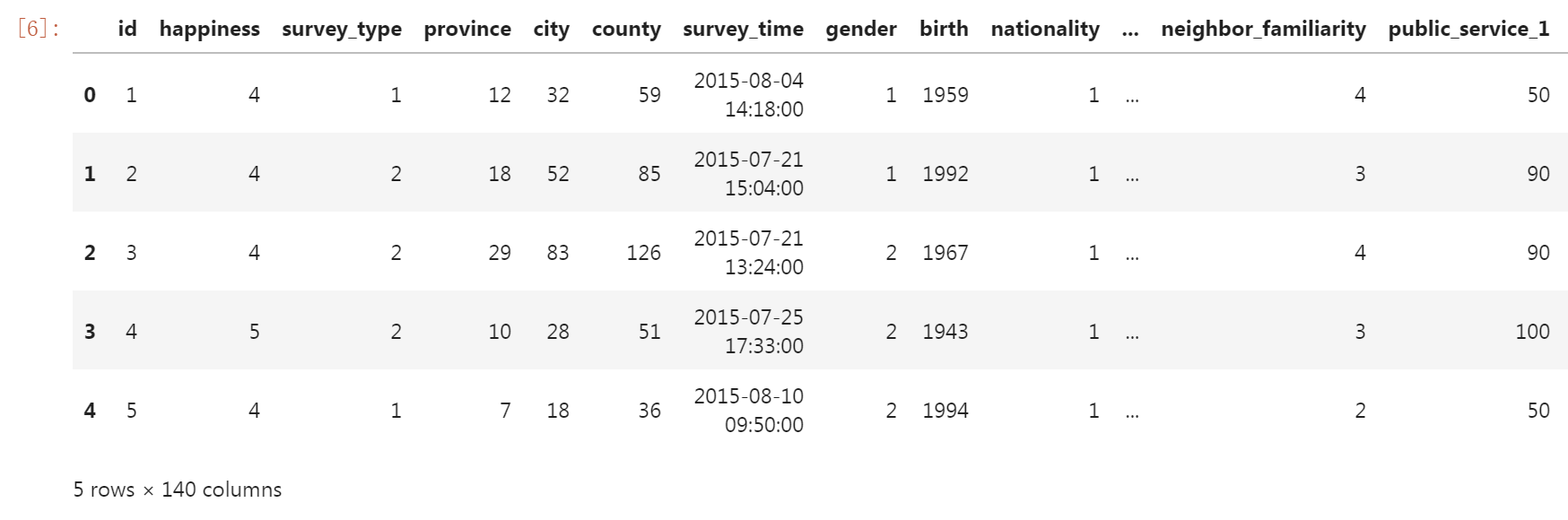
#Check whether the data is missing train.info(verbose=True,null_counts=True)
output:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 8000 entries, 0 to 7999 Data columns (total 140 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 id 8000 non-null int64 1 happiness 8000 non-null int64 2 survey_type 8000 non-null int64 3 province 8000 non-null int64 4 city 8000 non-null int64 5 county 8000 non-null int64 6 survey_time 8000 non-null datetime64[ns] 7 gender 8000 non-null int64 8 birth 8000 non-null int64 9 nationality 8000 non-null int64 10 religion 8000 non-null int64 11 religion_freq 8000 non-null int64 12 edu 8000 non-null int64 13 edu_other 3 non-null object 14 edu_status 6880 non-null float64 15 edu_yr 6028 non-null float64 16 income 8000 non-null int64 17 political 8000 non-null int64 18 join_party 824 non-null float64 19 floor_area 8000 non-null float64 20 property_0 8000 non-null int64 21 property_1 8000 non-null int64 22 property_2 8000 non-null int64 23 property_3 8000 non-null int64 24 property_4 8000 non-null int64 25 property_5 8000 non-null int64 26 property_6 8000 non-null int64 27 property_7 8000 non-null int64 28 property_8 8000 non-null int64 29 property_other 66 non-null object 30 height_cm 8000 non-null int64 31 weight_jin 8000 non-null int64 32 health 8000 non-null int64 33 health_problem 8000 non-null int64 34 depression 8000 non-null int64 35 hukou 8000 non-null int64 36 hukou_loc 7996 non-null float64 37 media_1 8000 non-null int64 38 media_2 8000 non-null int64 39 media_3 8000 non-null int64 40 media_4 8000 non-null int64 41 media_5 8000 non-null int64 42 media_6 8000 non-null int64 43 leisure_1 8000 non-null int64 44 leisure_2 8000 non-null int64 45 leisure_3 8000 non-null int64 46 leisure_4 8000 non-null int64 47 leisure_5 8000 non-null int64 48 leisure_6 8000 non-null int64 49 leisure_7 8000 non-null int64 50 leisure_8 8000 non-null int64 51 leisure_9 8000 non-null int64 52 leisure_10 8000 non-null int64 53 leisure_11 8000 non-null int64 54 leisure_12 8000 non-null int64 55 socialize 8000 non-null int64 56 relax 8000 non-null int64 57 learn 8000 non-null int64 58 social_neighbor 7204 non-null float64 59 social_friend 7204 non-null float64 60 socia_outing 8000 non-null int64 61 equity 8000 non-null int64 62 class 8000 non-null int64 63 class_10_before 8000 non-null int64 64 class_10_after 8000 non-null int64 65 class_14 8000 non-null int64 66 work_exper 8000 non-null int64 67 work_status 2951 non-null float64 68 work_yr 2951 non-null float64 69 work_type 2951 non-null float64 70 work_manage 2951 non-null float64 71 insur_1 8000 non-null int64 72 insur_2 8000 non-null int64 73 insur_3 8000 non-null int64 74 insur_4 8000 non-null int64 75 family_income 7999 non-null float64 76 family_m 8000 non-null int64 77 family_status 8000 non-null int64 78 house 8000 non-null int64 79 car 8000 non-null int64 80 invest_0 8000 non-null int64 81 invest_1 8000 non-null int64 82 invest_2 8000 non-null int64 83 invest_3 8000 non-null int64 84 invest_4 8000 non-null int64 85 invest_5 8000 non-null int64 86 invest_6 8000 non-null int64 87 invest_7 8000 non-null int64 88 invest_8 8000 non-null int64 89 invest_other 29 non-null object 90 son 8000 non-null int64 91 daughter 8000 non-null int64 92 minor_child 6934 non-null float64 93 marital 8000 non-null int64 94 marital_1st 7172 non-null float64 95 s_birth 6282 non-null float64 96 marital_now 6230 non-null float64 97 s_edu 6282 non-null float64 98 s_political 6282 non-null float64 99 s_hukou 6282 non-null float64 100 s_income 6282 non-null float64 101 s_work_exper 6282 non-null float64 102 s_work_status 2565 non-null float64 103 s_work_type 2565 non-null float64 104 f_birth 8000 non-null int64 105 f_edu 8000 non-null int64 106 f_political 8000 non-null int64 107 f_work_14 8000 non-null int64 108 m_birth 8000 non-null int64 109 m_edu 8000 non-null int64 110 m_political 8000 non-null int64 111 m_work_14 8000 non-null int64 112 status_peer 8000 non-null int64 113 status_3_before 8000 non-null int64 114 view 8000 non-null int64 115 inc_ability 8000 non-null int64 116 inc_exp 8000 non-null float64 117 trust_1 8000 non-null int64 118 trust_2 8000 non-null int64 119 trust_3 8000 non-null int64 120 trust_4 8000 non-null int64 121 trust_5 8000 non-null int64 122 trust_6 8000 non-null int64 123 trust_7 8000 non-null int64 124 trust_8 8000 non-null int64 125 trust_9 8000 non-null int64 126 trust_10 8000 non-null int64 127 trust_11 8000 non-null int64 128 trust_12 8000 non-null int64 129 trust_13 8000 non-null int64 130 neighbor_familiarity 8000 non-null int64 131 public_service_1 8000 non-null int64 132 public_service_2 8000 non-null int64 133 public_service_3 8000 non-null int64 134 public_service_4 8000 non-null int64 135 public_service_5 8000 non-null float64 136 public_service_6 8000 non-null int64 137 public_service_7 8000 non-null int64 138 public_service_8 8000 non-null int64 139 public_service_9 8000 non-null int64 dtypes: datetime64[ns](1), float64(25), int64(111), object(3) memory usage: 8.5+ MB
#View label distribution y_train_=train["happiness"] y_train_.value_counts()

#Replace - 8 with 3 y_train_=y_train_.map(lambda x:3 if x==-8 else x)
#Review label distribution y_train_.value_counts()

#Let the label start with 0 y_train_=y_train_.map(lambda x:x-1) #train and test are linked together data = pd.concat([train,test],axis=0,ignore_index=True) #Total data size data.shape

#Processing time characteristics
data['survey_time'] = pd.to_datetime(data['survey_time'],format='%Y-%m-%d %H:%M:%S')
data["weekday"]=data["survey_time"].dt.weekday
data["year"]=data["survey_time"].dt.year
data["quarter"]=data["survey_time"].dt.quarter
data["hour"]=data["survey_time"].dt.hour
data["month"]=data["survey_time"].dt.month
#Divide the time of the day
def hour_cut(x):
if 0<=x<6:
return 0
elif 6<=x<8:
return 1
elif 8<=x<12:
return 2
elif 12<=x<14:
return 3
elif 14<=x<18:
return 4
elif 18<=x<21:
return 5
elif 21<=x<24:
return 6
data["hour_cut"]=data["hour"].map(hour_cut)
#Age at the time of questionnaire
data["survey_age"]=data["year"]-data["birth"]
#Let the label start with 0
data["happiness"]=data["happiness"].map(lambda x:x-1)
#Remove the three missing values
data=data.drop(["edu_other"], axis=1)
data=data.drop(["happiness"], axis=1)
data=data.drop(["survey_time"], axis=1)
#Whether to join the party
data["join_party"]=data["join_party"].map(lambda x:0 if pd.isnull(x) else 1)
#Date of birth
def birth_split(x):
if 1920<=x<=1930:
return 0
elif 1930<x<=1940:
return 1
elif 1940<x<=1950:
return 2
elif 1950<x<=1960:
return 3
elif 1960<x<=1970:
return 4
elif 1970<x<=1980:
return 5
elif 1980<x<=1990:
return 6
elif 1990<x<=2000:
return 7
data["birth_s"]=data["birth"].map(birth_split)
#Revenue grouping
def income_cut(x):
if x<0:
return 0
elif 0<=x<1200:
return 1
elif 1200<x<=10000:
return 2
elif 10000<x<24000:
return 3
elif 24000<x<40000:
return 4
elif 40000<=x:
return 5
data["income_cut"]=data["income"].map(income_cut)
#Fill data
data["edu_status"]=data["edu_status"].fillna(5)
data["edu_yr"]=data["edu_yr"].fillna(-2)
data["property_other"]=data["property_other"].map(lambda x:0 if pd.isnull(x) else 1)
data["hukou_loc"]=data["hukou_loc"].fillna(1)
data["social_neighbor"]=data["social_neighbor"].fillna(8)
data["social_friend"]=data["social_friend"].fillna(8)
data["work_status"]=data["work_status"].fillna(0)
data["work_yr"]=data["work_yr"].fillna(0)
data["work_type"]=data["work_type"].fillna(0)
data["work_manage"]=data["work_manage"].fillna(0)
data["family_income"]=data["family_income"].fillna(-2)
data["invest_other"]=data["invest_other"].map(lambda x:0 if pd.isnull(x) else 1)
#Fill data
data["minor_child"]=data["minor_child"].fillna(0)
data["marital_1st"]=data["marital_1st"].fillna(0)
data["s_birth"]=data["s_birth"].fillna(0)
data["marital_now"]=data["marital_now"].fillna(0)
data["s_edu"]=data["s_edu"].fillna(0)
data["s_political"]=data["s_political"].fillna(0)
data["s_hukou"]=data["s_hukou"].fillna(0)
data["s_income"]=data["s_income"].fillna(0)
data["s_work_exper"]=data["s_work_exper"].fillna(0)
data["s_work_status"]=data["s_work_status"].fillna(0)
data["s_work_type"]=data["s_work_type"].fillna(0)
data=data.drop(["id"], axis=1)
X_train_ = data[:train.shape[0]]
X_test_ = data[train.shape[0]:]
X_train_.shape

X_test_.shape

target_column = 'happiness' feature_columns=list(X_test_.columns) feature_columns
output:
['survey_type', 'province', 'city', 'county', 'gender', 'birth', 'nationality', 'religion', 'religion_freq', 'edu', 'edu_status', 'edu_yr', 'income', 'political', 'join_party', 'floor_area', 'property_0', 'property_1', 'property_2', 'property_3', 'property_4', 'property_5', 'property_6', 'property_7', 'property_8', 'property_other', 'height_cm', 'weight_jin', 'health', 'health_problem', 'depression', 'hukou', 'hukou_loc', 'media_1', 'media_2', 'media_3', 'media_4', 'media_5', 'media_6', 'leisure_1', 'leisure_2', 'leisure_3', 'leisure_4', 'leisure_5', 'leisure_6', 'leisure_7', 'leisure_8', 'leisure_9', 'leisure_10', 'leisure_11', 'leisure_12', 'socialize', 'relax', 'learn', 'social_neighbor', 'social_friend', 'socia_outing', 'equity', 'class', 'class_10_before', 'class_10_after', 'class_14', 'work_exper', 'work_status', 'work_yr', 'work_type', 'work_manage', 'insur_1', 'insur_2', 'insur_3', 'insur_4', 'family_income', 'family_m', 'family_status', 'house', 'car', 'invest_0', 'invest_1', 'invest_2', 'invest_3', 'invest_4', 'invest_5', 'invest_6', 'invest_7', 'invest_8', 'invest_other', 'son', 'daughter', 'minor_child', 'marital', 'marital_1st', 's_birth', 'marital_now', 's_edu', 's_political', 's_hukou', 's_income', 's_work_exper', 's_work_status', 's_work_type', 'f_birth', 'f_edu', 'f_political', 'f_work_14', 'm_birth', 'm_edu', 'm_political', 'm_work_14', 'status_peer', 'status_3_before', 'view', 'inc_ability', 'inc_exp', 'trust_1', 'trust_2', 'trust_3', 'trust_4', 'trust_5', 'trust_6', 'trust_7', 'trust_8', 'trust_9', 'trust_10', 'trust_11', 'trust_12', 'trust_13', 'neighbor_familiarity', 'public_service_1', 'public_service_2', 'public_service_3', 'public_service_4', 'public_service_5', 'public_service_6', 'public_service_7', 'public_service_8', 'public_service_9', 'weekday', 'year', 'quarter', 'hour', 'month', 'hour_cut', 'survey_age', 'birth_s', 'income_cut']
X_train = np.array(X_train_) y_train = np.array(y_train_) X_test = np.array(X_test_)
X_train.shape

y_train.shape

X_test.shape

#User defined evaluation function
def myFeval(preds, xgbtrain):
label = xgbtrain.get_label()
score = mean_squared_error(label,preds)
return 'myFeval',score
3, Modeling parameter adjustment & model fusion
##### xgb
xgb_params = {"booster":'gbtree','eta': 0.005, 'max_depth': 5, 'subsample': 0.7,
'colsample_bytree': 0.8, 'objective': 'reg:linear', 'eval_metric': 'rmse', 'silent': True, 'nthread': 8}
folds = KFold(n_splits=5, shuffle=True, random_state=2018)
oof_xgb = np.zeros(len(train))
predictions_xgb = np.zeros(len(test))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):
print("fold n°{}".format(fold_+1))
trn_data = xgb.DMatrix(X_train[trn_idx], y_train[trn_idx])
val_data = xgb.DMatrix(X_train[val_idx], y_train[val_idx])
watchlist = [(trn_data, 'train'), (val_data, 'valid_data')]
clf = xgb.train(dtrain=trn_data, num_boost_round=20000, evals=watchlist, early_stopping_rounds=200, verbose_eval=100, params=xgb_params,feval = myFeval)
oof_xgb[val_idx] = clf.predict(xgb.DMatrix(X_train[val_idx]), ntree_limit=clf.best_ntree_limit)
predictions_xgb += clf.predict(xgb.DMatrix(X_test), ntree_limit=clf.best_ntree_limit) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_xgb, y_train_)))
fold n°1 [0] train-rmse:2.49563 valid_data-rmse:2.4813 train-myFeval:6.22818 valid_data-myFeval:6.15686 Multiple eval metrics have been passed: 'valid_data-myFeval' will be used for early stopping. Will train until valid_data-myFeval hasn't improved in 200 rounds. [100] train-rmse:1.6126 valid_data-rmse:1.60259 train-myFeval:2.60047 valid_data-myFeval:2.5683 [200] train-rmse:1.11478 valid_data-rmse:1.11408 train-myFeval:1.24274 valid_data-myFeval:1.24118 [300] train-rmse:0.851318 valid_data-rmse:0.865196 train-myFeval:0.724743 valid_data-myFeval:0.748564 [400] train-rmse:0.720533 valid_data-rmse:0.750967 train-myFeval:0.519168 valid_data-myFeval:0.563951 [500] train-rmse:0.656659 valid_data-rmse:0.702841 train-myFeval:0.431201 valid_data-myFeval:0.493985 [600] train-rmse:0.623453 valid_data-rmse:0.683129 train-myFeval:0.388694 valid_data-myFeval:0.466665 [700] train-rmse:0.603769 valid_data-rmse:0.675099 train-myFeval:0.364538 valid_data-myFeval:0.455759 [800] train-rmse:0.58938 valid_data-rmse:0.671326 train-myFeval:0.347369 valid_data-myFeval:0.450678 [900] train-rmse:0.577791 valid_data-rmse:0.669284 train-myFeval:0.333843 valid_data-myFeval:0.447941 [1000] train-rmse:0.567713 valid_data-rmse:0.668098 train-myFeval:0.322298 valid_data-myFeval:0.446355 [1100] train-rmse:0.558195 valid_data-rmse:0.667073 train-myFeval:0.311582 valid_data-myFeval:0.444986 [1200] train-rmse:0.549402 valid_data-rmse:0.666413 train-myFeval:0.301842 valid_data-myFeval:0.444107 [1300] train-rmse:0.541053 valid_data-rmse:0.665955 train-myFeval:0.292738 valid_data-myFeval:0.443496 [1400] train-rmse:0.533161 valid_data-rmse:0.665632 train-myFeval:0.28426 valid_data-myFeval:0.443066 [1500] train-rmse:0.525618 valid_data-rmse:0.665304 train-myFeval:0.276275 valid_data-myFeval:0.442629 [1600] train-rmse:0.518385 valid_data-rmse:0.665372 train-myFeval:0.268723 valid_data-myFeval:0.44272 [1700] train-rmse:0.511254 valid_data-rmse:0.665176 train-myFeval:0.26138 valid_data-myFeval:0.44246 [1800] train-rmse:0.504662 valid_data-rmse:0.664956 train-myFeval:0.254683 valid_data-myFeval:0.442167 [1900] train-rmse:0.498012 valid_data-rmse:0.664776 train-myFeval:0.248016 valid_data-myFeval:0.441928 [2000] train-rmse:0.49174 valid_data-rmse:0.664572 train-myFeval:0.241808 valid_data-myFeval:0.441656 [2100] train-rmse:0.485493 valid_data-rmse:0.664355 train-myFeval:0.235703 valid_data-myFeval:0.441368 [2200] train-rmse:0.479446 valid_data-rmse:0.664263 train-myFeval:0.229868 valid_data-myFeval:0.441245 [2300] train-rmse:0.473532 valid_data-rmse:0.664077 train-myFeval:0.224232 valid_data-myFeval:0.440998 [2400] train-rmse:0.46794 valid_data-rmse:0.663973 train-myFeval:0.218968 valid_data-myFeval:0.44086 [2500] train-rmse:0.462211 valid_data-rmse:0.663841 train-myFeval:0.213639 valid_data-myFeval:0.440685 [2600] train-rmse:0.45661 valid_data-rmse:0.663949 train-myFeval:0.208493 valid_data-myFeval:0.440828 Stopping. Best iteration: [2492] train-rmse:0.462626 valid_data-rmse:0.663821 train-myFeval:0.214022 valid_data-myFeval:0.440658 fold n°2 [0] train-rmse:2.49853 valid_data-rmse:2.46955 train-myFeval:6.24265 valid_data-myFeval:6.09866 Multiple eval metrics have been passed: 'valid_data-myFeval' will be used for early stopping. Will train until valid_data-myFeval hasn't improved in 200 rounds. [100] train-rmse:1.61339 valid_data-rmse:1.59864 train-myFeval:2.60302 valid_data-myFeval:2.55564 [200] train-rmse:1.11383 valid_data-rmse:1.11804 train-myFeval:1.24062 valid_data-myFeval:1.25001 [300] train-rmse:0.848462 valid_data-rmse:0.875119 train-myFeval:0.719888 valid_data-myFeval:0.765833 [400] train-rmse:0.716857 valid_data-rmse:0.764725 train-myFeval:0.513884 valid_data-myFeval:0.584804 [500] train-rmse:0.652761 valid_data-rmse:0.718626 train-myFeval:0.426097 valid_data-myFeval:0.516424 [600] train-rmse:0.619343 valid_data-rmse:0.699559 train-myFeval:0.383586 valid_data-myFeval:0.489383 [700] train-rmse:0.59878 valid_data-rmse:0.691164 train-myFeval:0.358538 valid_data-myFeval:0.477707 [800] train-rmse:0.584406 valid_data-rmse:0.687036 train-myFeval:0.34153 valid_data-myFeval:0.472018 [900] train-rmse:0.572886 valid_data-rmse:0.684788 train-myFeval:0.328199 valid_data-myFeval:0.468935 [1000] train-rmse:0.562962 valid_data-rmse:0.683213 train-myFeval:0.316926 valid_data-myFeval:0.46678 [1100] train-rmse:0.554569 valid_data-rmse:0.682218 train-myFeval:0.307547 valid_data-myFeval:0.465422 [1200] train-rmse:0.546599 valid_data-rmse:0.681102 train-myFeval:0.298771 valid_data-myFeval:0.4639 [1300] train-rmse:0.538384 valid_data-rmse:0.680288 train-myFeval:0.289857 valid_data-myFeval:0.462791 [1400] train-rmse:0.530827 valid_data-rmse:0.679778 train-myFeval:0.281777 valid_data-myFeval:0.462099 [1500] train-rmse:0.523566 valid_data-rmse:0.679006 train-myFeval:0.274121 valid_data-myFeval:0.46105 [1600] train-rmse:0.516822 valid_data-rmse:0.678669 train-myFeval:0.267105 valid_data-myFeval:0.460592 [1700] train-rmse:0.510059 valid_data-rmse:0.678479 train-myFeval:0.26016 valid_data-myFeval:0.460334 [1800] train-rmse:0.503851 valid_data-rmse:0.678285 train-myFeval:0.253866 valid_data-myFeval:0.46007 [1900] train-rmse:0.497297 valid_data-rmse:0.678069 train-myFeval:0.247305 valid_data-myFeval:0.459777 [2000] train-rmse:0.491299 valid_data-rmse:0.677739 train-myFeval:0.241375 valid_data-myFeval:0.45933 [2100] train-rmse:0.485227 valid_data-rmse:0.677723 train-myFeval:0.235445 valid_data-myFeval:0.459309 [2200] train-rmse:0.479466 valid_data-rmse:0.677622 train-myFeval:0.229888 valid_data-myFeval:0.459172 [2300] train-rmse:0.473802 valid_data-rmse:0.677815 train-myFeval:0.224488 valid_data-myFeval:0.459433 fold n°3 [0] train-rmse:2.48824 valid_data-rmse:2.51066 train-myFeval:6.19132 valid_data-myFeval:6.30342 Multiple eval metrics have been passed: 'valid_data-myFeval' will be used for early stopping. Will train until valid_data-myFeval hasn't improved in 200 rounds. [100] train-rmse:1.60686 valid_data-rmse:1.63402 train-myFeval:2.582 valid_data-myFeval:2.67001 [200] train-rmse:1.10953 valid_data-rmse:1.14734 train-myFeval:1.23105 valid_data-myFeval:1.31639 [300] train-rmse:0.845884 valid_data-rmse:0.897291 train-myFeval:0.71552 valid_data-myFeval:0.805131 [400] train-rmse:0.715194 valid_data-rmse:0.780631 train-myFeval:0.511503 valid_data-myFeval:0.609386 [500] train-rmse:0.651654 valid_data-rmse:0.729504 train-myFeval:0.424653 valid_data-myFeval:0.532176 [600] train-rmse:0.618452 valid_data-rmse:0.707078 train-myFeval:0.382482 valid_data-myFeval:0.499959 [700] train-rmse:0.598778 valid_data-rmse:0.696645 train-myFeval:0.358536 valid_data-myFeval:0.485314 [800] train-rmse:0.584995 valid_data-rmse:0.691768 train-myFeval:0.34222 valid_data-myFeval:0.478543 [900] train-rmse:0.573764 valid_data-rmse:0.688744 train-myFeval:0.329205 valid_data-myFeval:0.474368 [1000] train-rmse:0.564022 valid_data-rmse:0.68689 train-myFeval:0.31812 valid_data-myFeval:0.471817 [1100] train-rmse:0.554914 valid_data-rmse:0.685561 train-myFeval:0.30793 valid_data-myFeval:0.469994 [1200] train-rmse:0.546831 valid_data-rmse:0.684609 train-myFeval:0.299024 valid_data-myFeval:0.46869 [1300] train-rmse:0.538596 valid_data-rmse:0.683757 train-myFeval:0.290086 valid_data-myFeval:0.467524 [1400] train-rmse:0.531141 valid_data-rmse:0.682961 train-myFeval:0.28211 valid_data-myFeval:0.466436 [1500] train-rmse:0.523763 valid_data-rmse:0.682162 train-myFeval:0.274328 valid_data-myFeval:0.465345 [1600] train-rmse:0.517292 valid_data-rmse:0.681895 train-myFeval:0.267591 valid_data-myFeval:0.46498 [1700] train-rmse:0.510182 valid_data-rmse:0.681542 train-myFeval:0.260286 valid_data-myFeval:0.464499 [1800] train-rmse:0.503402 valid_data-rmse:0.681202 train-myFeval:0.253413 valid_data-myFeval:0.464036 [1900] train-rmse:0.496937 valid_data-rmse:0.681047 train-myFeval:0.246946 valid_data-myFeval:0.463825 [2000] train-rmse:0.490995 valid_data-rmse:0.681031 train-myFeval:0.241076 valid_data-myFeval:0.463803 [2100] train-rmse:0.484851 valid_data-rmse:0.680772 train-myFeval:0.23508 valid_data-myFeval:0.463451 [2200] train-rmse:0.47916 valid_data-rmse:0.680598 train-myFeval:0.229595 valid_data-myFeval:0.463214 [2300] train-rmse:0.473224 valid_data-rmse:0.680338 train-myFeval:0.223941 valid_data-myFeval:0.46286 [2400] train-rmse:0.46759 valid_data-rmse:0.680437 train-myFeval:0.218641 valid_data-myFeval:0.462995 [2500] train-rmse:0.461985 valid_data-rmse:0.680176 train-myFeval:0.213431 valid_data-myFeval:0.46264 [2600] train-rmse:0.456638 valid_data-rmse:0.679895 train-myFeval:0.208518 valid_data-myFeval:0.462257 [2700] train-rmse:0.451555 valid_data-rmse:0.679877 train-myFeval:0.203902 valid_data-myFeval:0.462233 [2800] train-rmse:0.446265 valid_data-rmse:0.679654 train-myFeval:0.199153 valid_data-myFeval:0.46193 [2900] train-rmse:0.440872 valid_data-rmse:0.679562 train-myFeval:0.194368 valid_data-myFeval:0.461804 [3000] train-rmse:0.435686 valid_data-rmse:0.679548 train-myFeval:0.189822 valid_data-myFeval:0.461786 [3100] train-rmse:0.430535 valid_data-rmse:0.679437 train-myFeval:0.18536 valid_data-myFeval:0.461635 [3200] train-rmse:0.425839 valid_data-rmse:0.679546 train-myFeval:0.181339 valid_data-myFeval:0.461783 [3300] train-rmse:0.421157 valid_data-rmse:0.679572 train-myFeval:0.177374 valid_data-myFeval:0.461818 Stopping. Best iteration: [3100] train-rmse:0.430535 valid_data-rmse:0.679437 train-myFeval:0.18536 valid_data-myFeval:0.461635 fold n°4 [0] train-rmse:2.49336 valid_data-rmse:2.49067 train-myFeval:6.21684 valid_data-myFeval:6.20343 Multiple eval metrics have been passed: 'valid_data-myFeval' will be used for early stopping. Will train until valid_data-myFeval hasn't improved in 200 rounds. [100] train-rmse:1.61098 valid_data-rmse:1.61922 train-myFeval:2.59525 valid_data-myFeval:2.62187 [200] train-rmse:1.11289 valid_data-rmse:1.13498 train-myFeval:1.23853 valid_data-myFeval:1.28817 [300] train-rmse:0.849092 valid_data-rmse:0.887377 train-myFeval:0.720957 valid_data-myFeval:0.787438 [400] train-rmse:0.717979 valid_data-rmse:0.771117 train-myFeval:0.515493 valid_data-myFeval:0.594622 [500] train-rmse:0.654382 valid_data-rmse:0.720297 train-myFeval:0.428216 valid_data-myFeval:0.518827 [600] train-rmse:0.621261 valid_data-rmse:0.698244 train-myFeval:0.385966 valid_data-myFeval:0.487545 [700] train-rmse:0.601387 valid_data-rmse:0.687932 train-myFeval:0.361667 valid_data-myFeval:0.473251 [800] train-rmse:0.587205 valid_data-rmse:0.68274 train-myFeval:0.344809 valid_data-myFeval:0.466134 [900] train-rmse:0.576164 valid_data-rmse:0.67993 train-myFeval:0.331965 valid_data-myFeval:0.462305 [1000] train-rmse:0.565982 valid_data-rmse:0.67764 train-myFeval:0.320336 valid_data-myFeval:0.459196 [1100] train-rmse:0.556975 valid_data-rmse:0.676599 train-myFeval:0.310221 valid_data-myFeval:0.457786 [1200] train-rmse:0.548716 valid_data-rmse:0.675994 train-myFeval:0.301089 valid_data-myFeval:0.456967 [1300] train-rmse:0.540704 valid_data-rmse:0.675275 train-myFeval:0.292361 valid_data-myFeval:0.455996 [1400] train-rmse:0.533031 valid_data-rmse:0.67509 train-myFeval:0.284122 valid_data-myFeval:0.455747 [1600] train-rmse:0.518829 valid_data-rmse:0.674387 train-myFeval:0.269184 valid_data-myFeval:0.454797 [1700] train-rmse:0.512472 valid_data-rmse:0.674234 train-myFeval:0.262628 valid_data-myFeval:0.454592 [1800] train-rmse:0.505854 valid_data-rmse:0.674212 train-myFeval:0.255889 valid_data-myFeval:0.454562 [1900] train-rmse:0.499552 valid_data-rmse:0.673864 train-myFeval:0.249552 valid_data-myFeval:0.454093 [2000] train-rmse:0.493428 valid_data-rmse:0.673896 train-myFeval:0.243471 valid_data-myFeval:0.454136 [2100] train-rmse:0.487465 valid_data-rmse:0.673945 train-myFeval:0.237622 valid_data-myFeval:0.454202 Stopping. Best iteration: [1982] train-rmse:0.49453 valid_data-rmse:0.673799 train-myFeval:0.24456 valid_data-myFeval:0.454005 fold n°5 [0] train-rmse:2.48807 valid_data-rmse:2.51175 train-myFeval:6.19053 valid_data-myFeval:6.30887 Multiple eval metrics have been passed: 'valid_data-myFeval' will be used for early stopping. Will train until valid_data-myFeval hasn't improved in 200 rounds. [200] train-rmse:1.11019 valid_data-rmse:1.14899 train-myFeval:1.23253 valid_data-myFeval:1.32018 [300] train-rmse:0.846003 valid_data-rmse:0.897965 train-myFeval:0.71572 valid_data-myFeval:0.806341 [400] train-rmse:0.714992 valid_data-rmse:0.780389 train-myFeval:0.511214 valid_data-myFeval:0.609008 [500] train-rmse:0.65098 valid_data-rmse:0.728968 train-myFeval:0.423775 valid_data-myFeval:0.531395 [600] train-rmse:0.617539 valid_data-rmse:0.706148 train-myFeval:0.381354 valid_data-myFeval:0.498644 [700] train-rmse:0.597487 valid_data-rmse:0.695606 train-myFeval:0.356991 valid_data-myFeval:0.483867 [800] train-rmse:0.583142 valid_data-rmse:0.689927 train-myFeval:0.340054 valid_data-myFeval:0.475999 [900] train-rmse:0.571824 valid_data-rmse:0.687029 train-myFeval:0.326983 valid_data-myFeval:0.472009 [1000] train-rmse:0.562088 valid_data-rmse:0.685097 train-myFeval:0.315943 valid_data-myFeval:0.469358 [1100] train-rmse:0.552812 valid_data-rmse:0.683917 train-myFeval:0.305601 valid_data-myFeval:0.467742 [1200] train-rmse:0.544331 valid_data-rmse:0.682804 train-myFeval:0.296296 valid_data-myFeval:0.466221 [1300] train-rmse:0.536364 valid_data-rmse:0.68213 train-myFeval:0.287687 valid_data-myFeval:0.465301 [1400] train-rmse:0.528567 valid_data-rmse:0.681425 train-myFeval:0.279383 valid_data-myFeval:0.46434 [1500] train-rmse:0.52093 valid_data-rmse:0.680725 train-myFeval:0.271368 valid_data-myFeval:0.463386 [1600] train-rmse:0.514128 valid_data-rmse:0.680122 train-myFeval:0.264328 valid_data-myFeval:0.462566 [1700] train-rmse:0.507027 valid_data-rmse:0.68001 train-myFeval:0.257076 valid_data-myFeval:0.462414 [1800] train-rmse:0.500298 valid_data-rmse:0.679592 train-myFeval:0.250298 valid_data-myFeval:0.461846 [1900] train-rmse:0.493881 valid_data-rmse:0.679473 train-myFeval:0.243919 valid_data-myFeval:0.461683 [2000] train-rmse:0.487692 valid_data-rmse:0.679272 train-myFeval:0.237844 valid_data-myFeval:0.46141 [2100] train-rmse:0.481702 valid_data-rmse:0.679074 train-myFeval:0.232036 valid_data-myFeval:0.461142 [2200] train-rmse:0.475845 valid_data-rmse:0.678811 train-myFeval:0.226429 valid_data-myFeval:0.460784 [2300] train-rmse:0.470158 valid_data-rmse:0.678583 train-myFeval:0.221049 valid_data-myFeval:0.460475 [2400] train-rmse:0.464276 valid_data-rmse:0.678738 train-myFeval:0.215553 valid_data-myFeval:0.460686 [2500] train-rmse:0.458573 valid_data-rmse:0.678521 train-myFeval:0.210289 valid_data-myFeval:0.460391 [2600] train-rmse:0.453289 valid_data-rmse:0.678433 train-myFeval:0.205471 valid_data-myFeval:0.460271 [2700] train-rmse:0.447749 valid_data-rmse:0.678131 train-myFeval:0.200479 valid_data-myFeval:0.459862 [2800] train-rmse:0.442273 valid_data-rmse:0.678136 train-myFeval:0.195606 valid_data-myFeval:0.459869 [2900] train-rmse:0.436974 valid_data-rmse:0.678275 train-myFeval:0.190947 valid_data-myFeval:0.460057 Stopping. Best iteration: [2711] train-rmse:0.447123 valid_data-rmse:0.678055 train-myFeval:0.199919 valid_data-myFeval:0.459758 CV score: 0.45503947
##### lgb
param = {'boosting_type': 'gbdt',
'num_leaves': 20,
'min_data_in_leaf': 20,
'objective':'regression',
'max_depth':6,
'learning_rate': 0.01,
"min_child_samples": 30,
"feature_fraction": 0.8,
"bagging_freq": 1,
"bagging_fraction": 0.8 ,
"bagging_seed": 11,
"metric": 'mse',
"lambda_l1": 0.1,
"verbosity": -1}
folds = KFold(n_splits=5, shuffle=True, random_state=2018)
oof_lgb = np.zeros(len(X_train_))
predictions_lgb = np.zeros(len(X_test_))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):
print("fold n°{}".format(fold_+1))
trn_data = lgb.Dataset(X_train[trn_idx], y_train[trn_idx])
val_data = lgb.Dataset(X_train[val_idx], y_train[val_idx])
num_round = 10000
clf = lgb.train(param, trn_data, num_round, valid_sets = [trn_data, val_data], verbose_eval=200, early_stopping_rounds = 100)
oof_lgb[val_idx] = clf.predict(X_train[val_idx], num_iteration=clf.best_iteration)
predictions_lgb += clf.predict(X_test, num_iteration=clf.best_iteration) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_lgb, y_train_)))
fold n°1 Training until validation scores don't improve for 100 rounds [200] training's l2: 0.437503 valid_1's l2: 0.469686 [400] training's l2: 0.372168 valid_1's l2: 0.44976 [600] training's l2: 0.33182 valid_1's l2: 0.443816 [800] training's l2: 0.300597 valid_1's l2: 0.4413 Early stopping, best iteration is: [852] training's l2: 0.293435 valid_1's l2: 0.440755 fold n°2 Training until validation scores don't improve for 100 rounds [200] training's l2: 0.431328 valid_1's l2: 0.494627 [400] training's l2: 0.366744 valid_1's l2: 0.46981 [600] training's l2: 0.327688 valid_1's l2: 0.463121 [800] training's l2: 0.297368 valid_1's l2: 0.459899 [1000] training's l2: 0.272359 valid_1's l2: 0.458902 [1200] training's l2: 0.251022 valid_1's l2: 0.457813 Early stopping, best iteration is: [1175] training's l2: 0.253627 valid_1's l2: 0.457521 fold n°3 Training until validation scores don't improve for 100 rounds [200] training's l2: 0.429379 valid_1's l2: 0.499227 [400] training's l2: 0.3656 valid_1's l2: 0.475046 [600] training's l2: 0.326419 valid_1's l2: 0.466977 [800] training's l2: 0.296541 valid_1's l2: 0.464133 [1000] training's l2: 0.271029 valid_1's l2: 0.462466 [1200] training's l2: 0.249656 valid_1's l2: 0.462441 Early stopping, best iteration is: [1108] training's l2: 0.259331 valid_1's l2: 0.461866 fold n°4 Training until validation scores don't improve for 100 rounds [200] training's l2: 0.433149 valid_1's l2: 0.490838 [400] training's l2: 0.368487 valid_1's l2: 0.461291 [600] training's l2: 0.3288 valid_1's l2: 0.452724 [800] training's l2: 0.298579 valid_1's l2: 0.450139 Early stopping, best iteration is: [745] training's l2: 0.306104 valid_1's l2: 0.449927 fold n°5 Training until validation scores don't improve for 100 rounds [200] training's l2: 0.431879 valid_1's l2: 0.488074 [400] training's l2: 0.366806 valid_1's l2: 0.469409 [600] training's l2: 0.326648 valid_1's l2: 0.464181 [800] training's l2: 0.295898 valid_1's l2: 0.461481 [1000] training's l2: 0.270621 valid_1's l2: 0.459628 Early stopping, best iteration is: [1033] training's l2: 0.266873 valid_1's l2: 0.459088 CV score: 0.45383135
#Install package for catboost !pip install -i https://pypi.tuna.tsinghua.edu.cn/simple catboost
from catboost import Pool, CatBoostRegressor
from sklearn.model_selection import train_test_split
kfolder = KFold(n_splits=5, shuffle=True, random_state=2019)
oof_cb = np.zeros(len(X_train_))
predictions_cb = np.zeros(len(X_test_))
kfold = kfolder.split(X_train_, y_train_)
fold_=0
#X_train_s, X_test_s, y_train_s, y_test_s = train_test_split(X_train, y_train, test_size=0.3, random_state=2019)
for train_index, vali_index in kfold:
print("fold n°{}".format(fold_))
fold_=fold_+1
k_x_train = X_train[train_index]
k_y_train = y_train[train_index]
k_x_vali = X_train[vali_index]
k_y_vali = y_train[vali_index]
cb_params = {
'n_estimators': 100000,
'loss_function': 'RMSE',
'eval_metric':'RMSE',
'learning_rate': 0.05,
'depth': 5,
'use_best_model': True,
'subsample': 0.6,
'bootstrap_type': 'Bernoulli',
'reg_lambda': 3
}
model_cb = CatBoostRegressor(**cb_params)
#train the model
model_cb.fit(k_x_train, k_y_train,eval_set=[(k_x_vali, k_y_vali)],verbose=100,early_stopping_rounds=50)
oof_cb[vali_index] = model_cb.predict(k_x_vali, ntree_end=model_cb.best_iteration_)
predictions_cb += model_cb.predict(X_test_, ntree_end=model_cb.best_iteration_) / kfolder.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_cb, y_train_)))
fold n°0 0: learn: 0.8175871 test: 0.7820939 best: 0.7820939 (0) total: 49.9ms remaining: 1h 23m 8s 100: learn: 0.6711041 test: 0.6749289 best: 0.6749289 (100) total: 372ms remaining: 6m 7s 200: learn: 0.6410910 test: 0.6688829 best: 0.6686703 (190) total: 674ms remaining: 5m 34s 300: learn: 0.6130819 test: 0.6669464 best: 0.6668201 (282) total: 988ms remaining: 5m 27s 400: learn: 0.5895197 test: 0.6666901 best: 0.6663658 (371) total: 1.3s remaining: 5m 23s 500: learn: 0.5684832 test: 0.6657841 best: 0.6654600 (478) total: 1.6s remaining: 5m 18s Stopped by overfitting detector (50 iterations wait) bestTest = 0.6654599993 bestIteration = 478 Shrink model to first 479 iterations. fold n°1 0: learn: 0.8107754 test: 0.8172376 best: 0.8172376 (0) total: 3.48ms remaining: 5m 48s 100: learn: 0.6715406 test: 0.6800052 best: 0.6800052 (100) total: 323ms remaining: 5m 19s 200: learn: 0.6428284 test: 0.6699391 best: 0.6699391 (200) total: 641ms remaining: 5m 18s 300: learn: 0.6144500 test: 0.6663790 best: 0.6662390 (298) total: 964ms remaining: 5m 19s 400: learn: 0.5905343 test: 0.6643743 best: 0.6641256 (388) total: 1.28s remaining: 5m 18s 500: learn: 0.5703917 test: 0.6632232 best: 0.6632137 (497) total: 1.6s remaining: 5m 17s 600: learn: 0.5523517 test: 0.6626011 best: 0.6620170 (579) total: 1.92s remaining: 5m 17s Stopped by overfitting detector (50 iterations wait) bestTest = 0.6620170222 bestIteration = 579 Shrink model to first 580 iterations. fold n°2 0: learn: 0.8046145 test: 0.8370989 best: 0.8370989 (0) total: 3.56ms remaining: 5m 56s 100: learn: 0.6652528 test: 0.7059731 best: 0.7059731 (100) total: 314ms remaining: 5m 10s 200: learn: 0.6356395 test: 0.6958527 best: 0.6958527 (200) total: 618ms remaining: 5m 7s 300: learn: 0.6079444 test: 0.6913800 best: 0.6913800 (300) total: 927ms remaining: 5m 6s 400: learn: 0.5848883 test: 0.6900293 best: 0.6900293 (400) total: 1.24s remaining: 5m 8s 500: learn: 0.5637398 test: 0.6896119 best: 0.6889243 (455) total: 1.56s remaining: 5m 10s Stopped by overfitting detector (50 iterations wait) bestTest = 0.6889243403 bestIteration = 455 Shrink model to first 456 iterations. fold n°3 0: learn: 0.8156897 test: 0.7928103 best: 0.7928103 (0) total: 3.89ms remaining: 6m 29s 100: learn: 0.6666901 test: 0.6886018 best: 0.6886018 (100) total: 325ms remaining: 5m 21s 200: learn: 0.6349422 test: 0.6834388 best: 0.6834388 (200) total: 643ms remaining: 5m 19s 300: learn: 0.6054434 test: 0.6814056 best: 0.6806466 (259) total: 954ms remaining: 5m 15s Stopped by overfitting detector (50 iterations wait) bestTest = 0.680646584 bestIteration = 259 Shrink model to first 260 iterations. fold n°4 0: learn: 0.8073054 test: 0.8273646 best: 0.8273646 (0) total: 3.34ms remaining: 5m 34s 100: learn: 0.6617636 test: 0.7072268 best: 0.7072268 (100) total: 312ms remaining: 5m 8s 200: learn: 0.6326520 test: 0.6986823 best: 0.6985780 (193) total: 614ms remaining: 5m 5s 300: learn: 0.6047984 test: 0.6949317 best: 0.6949112 (296) total: 914ms remaining: 5m 2s 400: learn: 0.5809457 test: 0.6927416 best: 0.6925554 (375) total: 1.22s remaining: 5m 2s Stopped by overfitting detector (50 iterations wait) bestTest = 0.6925554216 bestIteration = 375 Shrink model to first 376 iterations. CV score: 0.45983020
from sklearn import linear_model
# Stack the results of lgb, xgb and ctb
train_stack = np.vstack([oof_lgb,oof_xgb,oof_cb]).transpose()
test_stack = np.vstack([predictions_lgb, predictions_xgb,predictions_cb]).transpose()
folds_stack = RepeatedKFold(n_splits=5, n_repeats=2, random_state=2018)
oof_stack = np.zeros(train_stack.shape[0])
predictions = np.zeros(test_stack.shape[0])
for fold_, (trn_idx, val_idx) in enumerate(folds_stack.split(train_stack,y_train)):
print("fold {}".format(fold_))
trn_data, trn_y = train_stack[trn_idx], y_train[trn_idx]
val_data, val_y = train_stack[val_idx], y_train[val_idx]
clf_3 = linear_model.BayesianRidge()
#clf_3 =linear_model.Ridge()
clf_3.fit(trn_data, trn_y)
oof_stack[val_idx] = clf_3.predict(val_data)
predictions += clf_3.predict(test_stack) / 10
print("CV score: {:<8.8f}".format(mean_squared_error(oof_stack, y_train_)))

result=list(predictions)
result=list(map(lambda x: x + 1, result))
test_sub=pd.read_csv("happiness_submit.csv",encoding='ISO-8859-1')
test_sub["happiness"]=result
test_sub.to_csv("submit_20211122.csv", index=False)
#Check where the file is saved, download the file under the path, and submit
print(os.path.abspath('.'))

4, References
reference resources:
Integrated learning case (happiness prediction)
Happiness prediction - online 0.471 - ranking 18 - ideas sharing - including XGB LGB CTB
Come and explore happiness together! -- Alibaba cloud Tianchi project practice (with completed practice process + code)
Machine learning (IV) happiness data analysis + prediction