Mangodb Baidu Encyclopedia
There are a lot of software that can't be installed without Mac version on Mac computer, but some software has Mac version and the way of installation is more complex than Windows platform. For example, now we want to install it on Mac computers. mangodb database First, we need to install the Mangodb server.
Next we'll come to Mongodb: mac Installation and Use of MongoDB . After installation according to the operation steps, the error was reported:
MacBook-Pro:~ guotianhui$ mongod
2019-08-01T13:32:13.194+0800 I CONTROL [main] Automatically disabling TLS 1.0, to force-enable TLS 1.0 specify --sslDisabledProtocols 'none'
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] MongoDB starting : pid=2855 port=27017 dbpath=/data/db 64-bit host=MacBook-Pro.local
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] db version v4.0.11
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] git version: 417d1a712e9f040d54beca8e4943edce218e9a8c
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] allocator: system
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] modules: none
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] build environment:
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] distarch: x86_64
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] target_arch: x86_64
2019-08-01T13:32:13.256+0800 I CONTROL [initandlisten] options: {}
2019-08-01T13:32:13.259+0800 I STORAGE [initandlisten] exception in initAndListen: IllegalOperation: Attempted to create a lock file on a read-only directory: /data/db, terminating
2019-08-01T13:32:13.259+0800 I NETWORK [initandlisten] shutdown: going to close listening sockets...
2019-08-01T13:32:13.260+0800 I NETWORK [initandlisten] removing socket file: /tmp/mongodb-27017.sock
2019-08-01T13:32:13.260+0800 I CONTROL [initandlisten] now exiting
2019-08-01T13:32:13.260+0800 I CONTROL [initandlisten] shutting down with code:100
Baidu below failed to create a database due to lack of authorization, through the following commands Create a Mangodb database for authorization:
sudo chmod 777 /data/db
Authorization needs to enter the mac administrator password, and then open the mongodb server to succeed.
Enter the following address in the browser: http://localhost:27017/. If the following interface is displayed, your Mongodb server has been installed successfully. Next you need to install Robomongo Client That is, the Mongo GUI interface, downloading Robomongo requires a link to an external address.
Next you need to install Robomongo Client That is, the Mongo GUI interface, downloading Robomongo requires a link to an external address.
Once downloaded, install it with one click, and then link to the local database to associate the Mongodb server.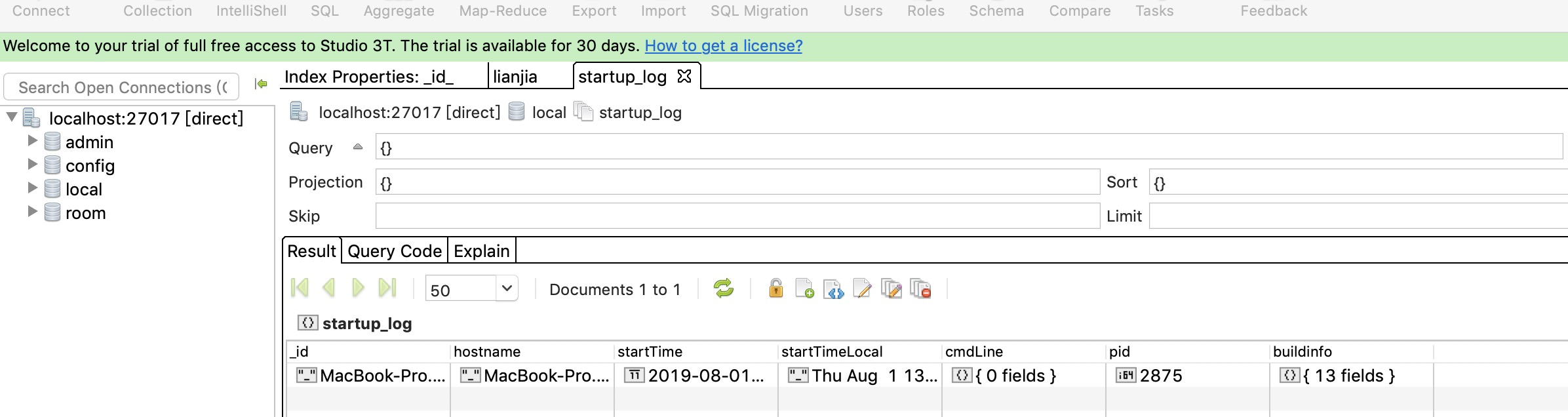
This is where the Mac version of the Magodb is installed.
Create a py crawler using the following Python command:
Scrapy command
Create a project
scrapy startproject XXX
Open the project to create a crawler
scrapy genspider XXX xxx.com
Create a script launcher in the project directory
from scrapy.cmdlineimport execute
execute("scrapy crawl lianjia".split())
For example, we create a new Py crawler project and then run the following command on the Terminal command line:
scrapy startproject testSpider
A crawler project is created in the root directory of the project: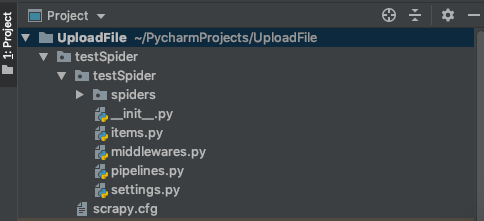
Then we need to go to the root directory of the crawler project and use the following command to create a crawler for a Web site in the root directory of the project:
cd testSpider scrapy genspider baidu baidu.com
Then we create a script to start the crawler in the root directory of the project:
from scrapy.cmdline import execute
execute("scrapy crawl testSpider".split())
Crawler configuration
The project settings.py configuration needs to be changed:
1) Line 19, which is configured as the USER_AGENT of your system browser after opening, will be accessed by the robot by default if it is not configured here.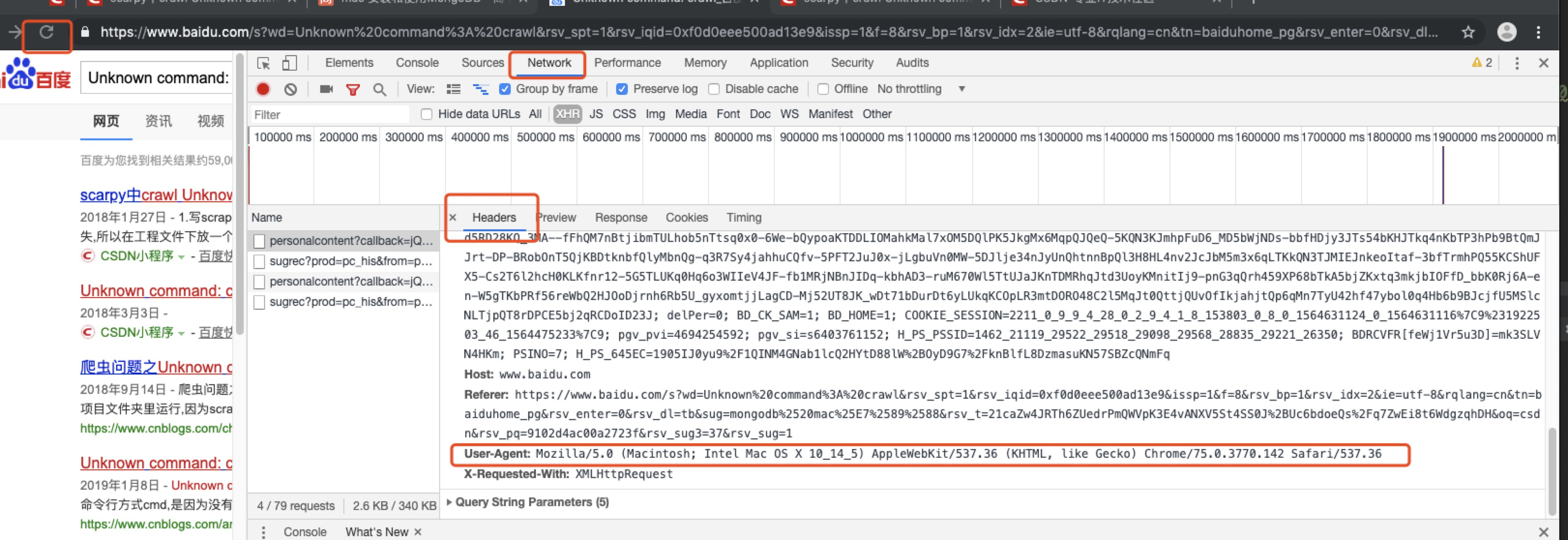
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
2) Line 22, open, set to False.
ROBOTSTXT_OBEY = False
3) Set the execution interval:
DOWNLOAD_DELAY = 1
4) In line 67, set the database storage class configuration:
ITEM_PIPELINES = {
'testSpider.pipelines.MysqlPipeline': 300,
}
Mongodb is used for storage, so the corresponding storage class pipelines.py needs to be changed to the same class name.
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from pymysql import connect
class MongoPipeline(object):
def open_spider(self, spider):
self.client = pymongo.MongoClient()
def process_item(self, item, spider):
self.client.room.lianjia.insert(item)
return item
def close_spider(self, spider):
self.client.close()
class MysqlPipeline(object):
def open_spider(self, spider):
self.client = connect(host="localhost", prot=3306, user="root", password="123456", db="room", charset="utf8")
self.cursor = self.client.cursor()
def process_item(self, item, spider):
args=[]
return item
def close_spider(self, spider):
self.cursor.close()
self.client.close()
Once these are all configured, you can start some data parsing classes, which are your Spider data parsing classes.
# -*- coding: utf-8 -*-
import scrapy
class LianjiaSpider(scrapy.Spider):
name = 'lianjia'
allowed_domains = ['lianjia.com']
start_urls = ['https://bj.lianjia.com/ershoufang/pg{}/'.format(num) for num in range(1, 2)]
def parse(self, response):
urls = response.xpath('//div[@class="info clear"]/div[@class="title"]/a/@href').extract()
for url in urls:
yield scrapy.Request(url, callback=self.parse_info)
def parse_info(self, response):
total = response.xpath(
'concat(//span[@class="total"]/text(),//span[@class="unit"]/span/text())').extract_first()
unitPriceValue = response.xpath('string(//span[@class="unitPriceValue"])').extract_first()
xiao_qu = response.xpath('//div[@class="communityName"]/a[1]/text()').extract_first()
qu_yu = response.xpath('string(//div[@class="areaName"]/span[@class="info"])').extract_first()
base = response.xpath('//div[@class="base"]//ul')
hu_xing = base.xpath('./li[1]/text()').extract_first()
lou_ceng = base.xpath('./li[2]/text()').extract_first()
mian_ji = base.xpath('./li[3]/text()').extract_first()
zhuang_xiu = base.xpath('./li[9]/text()').extract_first()
gong_nuan = base.xpath('./li[last()-2]/text()').extract_first()
chan_quan = base.xpath('./li[last()]/text()').extract_first()
transaction = response.xpath('//div[@class="transaction"]//ul')
yong_tu = transaction.xpath('./li[4]/span[2]/text()').extract_first()
nian_xian = transaction.xpath('./li[last()-3]/span[2]/text()').extract_first()
di_ya = response.xpath('string(//*[@id="introduction"]/div/div/div[2]/div[2]/ul/li[7]/span[2])').extract_first()
yield {
"total": total,
"unitPriceValue": unitPriceValue,
"xiao_qu": xiao_qu,
"qu_yu": qu_yu,
"hu_xing": hu_xing,
"lou_ceng": lou_ceng,
"mian_ji": mian_ji,
"zhuang_xiu": zhuang_xiu,
"gong_nuan": gong_nuan,
"chan_quan": chan_quan,
"yong_tu": yong_tu,
"nian_xian": nian_xian,
"di_ya": di_ya,
}
Then you can open the crawler script and crawl the data.
Rule definitions for data crawling need to be used XPath plug-in This is a plug-in for Google Browser to locate element content.
Xpath Baidu Encyclopedia XPath is the XML Path Language, which is a language used to locate a part of an XML document.
Xpath grammar XPath is a language for finding information in XML documents. XPath can be used to traverse elements and attributes in XML documents.
1) Node
In XPath, there are seven types of nodes: elements, attributes, text, namespaces, processing instructions, annotations, and document (root) nodes. XML documents are treated as node trees. The root of a tree is called a document node or root node.
2) Selecting Nodes
XPath uses path expressions to select nodes in an XML document. Nodes are selected by following a path or step.
The most useful path expressions are listed below: Expressions Noename Selects all child nodes of this node. / Select from the root node. // Select the nodes in the document from the current node that matches the selection, regardless of their location. Select the current node. Select the parent node of the current node. @ Select attributes.
3) Predicates
A predicate is used to find a particular node or a node that contains a specified value. Predicates are embedded in square brackets.
Example
In the table below, we list some path expressions with predicates and the results of the expressions:
Path expression results / bookstore/book[1] selects the first book element that belongs to the bookstore child element. / bookstore/book[last()] selects the last book element that belongs to the bookstore child element. / bookstore/book[last()-1] selects the penultimate book element that belongs to the bookstore subelement. / Bookstore / book [position ()< 3] selects the first two book elements belonging to the child elements of the bookstore element. // title[@lang] Selects all title elements that have attributes called Lang. // title[@lang='eng'] selects all title elements, and these elements have a lang attribute with the value of Eng. / Bookstore / book [price > 35.00] selects all book elements of the bookstore element, and the value of the price element must be greater than 35.00. / Bookstore/book [price > 35.00]/title selects all title elements of the book element in the bookstore element, and the value of the price element must be greater than 35.00.
4) Selecting Unknown Nodes
XPath wildcards can be used to select unknown XML elements.
Wildcard character description * Match any element node. @* Match any attribute node. node() matches any type of node.
5) XPath axis
The axis defines the node set relative to the current node.
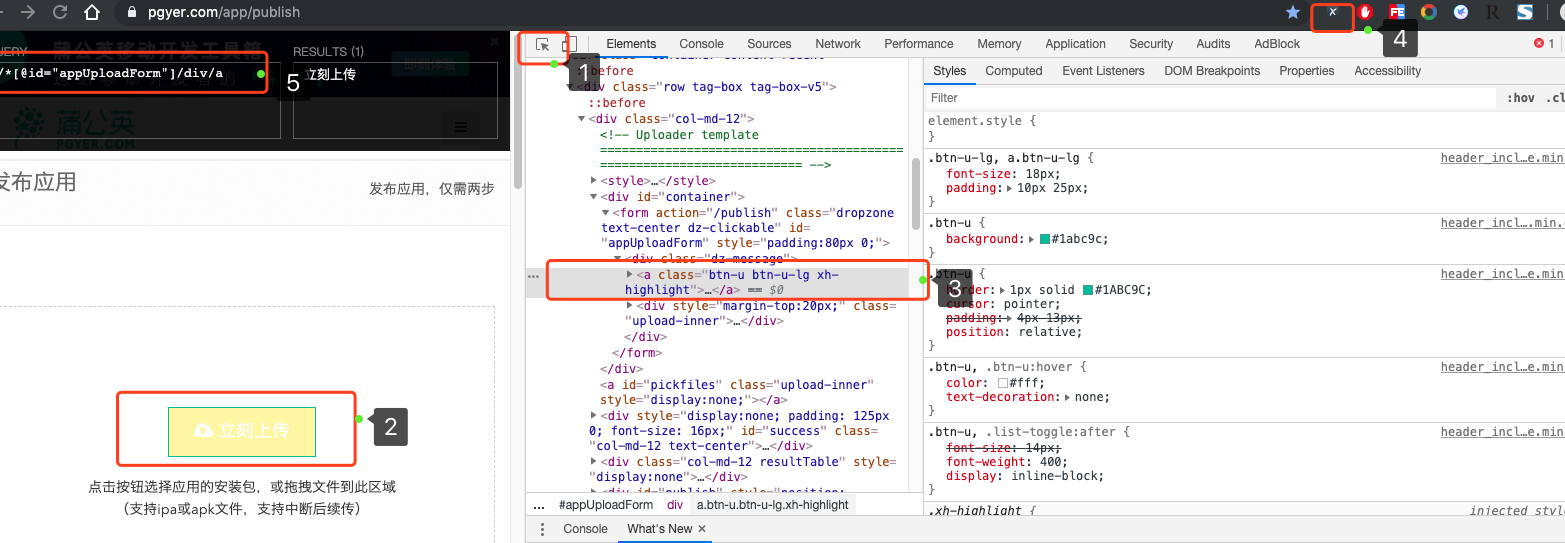
How do you use the Xpath plug-in to locate page elements? Let's take dandelion upload APK as an example:
After opening the page, you log in to the dandelion account and upload the Apk file page. Now we press F12 to view the source code of the web page, click on the button in the upper right corner of the source code, and then select the page element that needs to be located. We can use this path to determine the page element.