I. Weighting the Index
package com.wsy;
import java.io.File;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class IndexUtil {
private String[] ids = {"1", "2", "3", "4", "5", "6"};
private String[] emails = {"a@a.com", "b@b.com", "c@c.com", "d@d.com", "e@e.com", "f@f.com"};
private String[] contents = {"content 1", "content 2", "content 3", "content 4", "content 5", "content 6"};
private int[] attachFiles = {1, 2, 3, 4, 5, 6};
private String[] names = {"qianyi", "zhaoer", "zhangsan", "lisi", "wangwu", "liuliu"};
private Directory directory = null;
private Map<String, Float> scores = new HashMap<>();
public IndexUtil() {
try {
// Set the weight, the default weight is 1.0, the larger the value, the higher the weight.
scores.put("a.com",1.5f);
scores.put("b.com",1.6f);
scores.put("c.com",1.7f);
scores.put("d.com",1.8f);
scores.put("e.com",1.9f);
scores.put("f.com",2.0f);
directory = FSDirectory.open(new File("E:\\Lucene\\IndexLibrary"));
} catch (IOException e) {
e.printStackTrace();
}
}
public void index() {
IndexWriter indexWriter = null;
try {
indexWriter = new IndexWriter(directory, new IndexWriterConfig(Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35)));
Document document = null;
for (int i = 0; i < ids.length; i++) {
document = new Document();
document.add(new Field("id", ids[i], Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS));
document.add(new Field("email", emails[i], Field.Store.YES, Field.Index.NOT_ANALYZED));
document.add(new Field("content", contents[i], Field.Store.NO, Field.Index.ANALYZED));
document.add(new Field("name", names[i], Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS));
String emailType = emails[i].substring(emails[i].lastIndexOf("@")+1);
if(scores.containsKey(emailType)){
document.setBoost(scores.get(emailType));
} else {
document.setBoost(0.1f);
}
indexWriter.addDocument(document);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (indexWriter != null) {
try {
indexWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public void search() {
try {
IndexReader indexReader = IndexReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// Search for content fields that contain "content"
TermQuery termQuery = new TermQuery(new Term("content", "content"));
TopDocs topDocs = indexSearcher.search(termQuery, 10);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("name")+" "+document.getBoost());
}
} catch (IOException e) {
e.printStackTrace();
}
}
}There is something wrong with the output here. We need to study it again.
II. Use of Luke
Luke's version should correspond to Lucene's version, otherwise the index can't be opened.
After downloading, put it in a folder and create a startup.bat file in the folder. The file contents are as follows. Put luke-3.5.0.jar into the target under the current folder, and then run the bat file directly when Luke is started.
start javaw -jar .\target\luke-3.5.0.jar
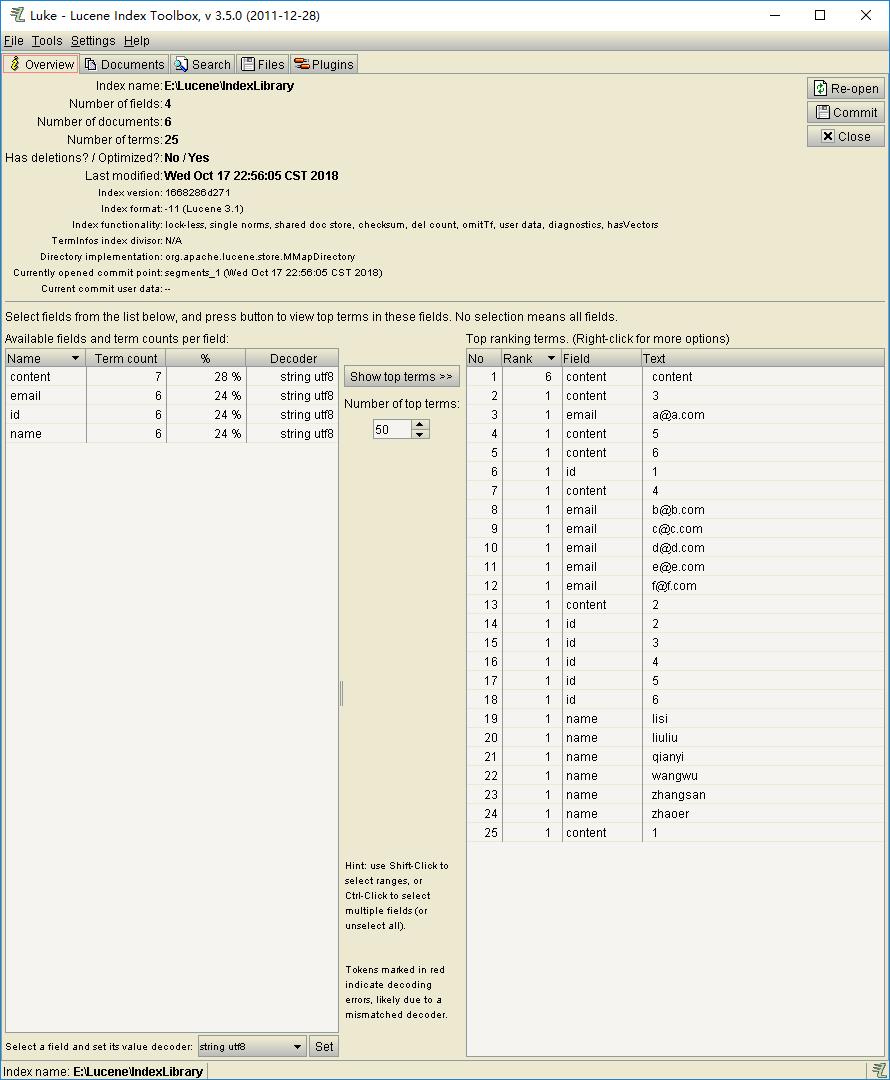
Look at a picture first, and then you will use it if you touch it slowly.