LruCache Source Profiling
Preface
Developers with some experience know this class. Most of the time, the LruCache class is used in the image cache, and it uses an algorithm that sounds tall - "Least recently used algorithm."After a round of source parsing, we will find that the internal is achieved using simple techniques.
Source Profiling
First let's look at how LruCache is constructed
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}You can see the internal implementation using LinkedHashMap.
In general, when an object needs to be cached, the put method is called
LruCache#put
public final V put(K key, V value) {
// Neither key nor value can be null
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
// ②
size += safeSizeOf(key, value);
// ③
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, value);
}
// ④
trimToSize(maxSize);
return previous;
}Let's look at #2, which calls the safeSizeOf method, which calculates the size of the value occupied.
private int safeSizeOf(K key, V value) {
int result = sizeOf(key, value);
if (result < 0) {
throw new IllegalStateException("Negative size: " + key + "=" + value);
}
return result;
}
/**
* Returns the size of the entry for {@code key} and {@code value} in
* user-defined units. The default implementation returns 1 so that size
* is the number of entries and max size is the maximum number of entries.
*
* <p>An entry's size must not change while it is in the cache.
*/
protected int sizeOf(K key, V value) {
return 1;
}You can see that the sizeof method returns 1 by default, so when we use the LruCache class, we often need to override it to specify the size of space used by key s and value s.
Returning to the put method, study the method (3) and call the put method of map, which is LinkedHashMap at the time of initialization, and LinkedHashMap inherits the put method of HashMap.
HashMap#put
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);
// hash value and length-1, equivalent to taking a balance and calculating a bitmark
int i = indexFor(hash, table.length);
// Find the location where hash and key are the same, if not empty and hash value is the same as key value, replace the old value
for (HashMapEntry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}Note that LinkedHashMap overrides HashMap's addEntry method, as if it didn't help anything, and then look at HashMap's method.
LinkedHashMap#addEntry
void addEntry(int hash, K key, V value, int bucketIndex) {
// Previous Android releases called removeEldestEntry() before actually
// inserting a value but after increasing the size.
// The RI is documented to call it afterwards.
// **** THIS CHANGE WILL BE REVERTED IN A FUTURE ANDROID RELEASE ****
// Remove eldest entry if instructed
LinkedHashMapEntry<K,V> eldest = header.after;
if (eldest != header) {
boolean removeEldest;
size++;
try {
removeEldest = removeEldestEntry(eldest);
} finally {
size--;
}
if (removeEldest) {
removeEntryForKey(eldest.key);
}
}
super.addEntry(hash, key, value, bucketIndex);
}HashMap#addEntry
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); //Double capacity
hash = (null != key) ? sun.misc.Hashing.singleWordWangJenkinsHash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}You can see that if the size of the added object is larger than the specified value, it will be expanded, regardless of it here.Continue to look at the createEntry method called at the end of the method.
HashMap#createEntry
/**
* This override differs from addEntry in that it doesn't resize the
* table or remove the eldest entry.
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMapEntry<K,V> old = table[bucketIndex];
LinkedHashMapEntry<K,V> e = new LinkedHashMapEntry<>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}
private static class LinkedHashMapEntry<K,V> extends HashMapEntry<K,V> {
// These fields comprise the doubly linked list used for iteration.
LinkedHashMapEntry<K,V> before, after;
LinkedHashMapEntry(int hash, K key, V value, HashMapEntry<K,V> next) {
super(hash, key, value, next);
}
...
}We can see that the new node invokes the addBefore method of the LinkedHashMapEntry object in addition to initializing the attributes inside the LinkedHashMapEntry (essentially initializing the internal attributes of the HashMapEntry and resolving conflicts using the chain address method during initialization).
LinkedHashMapEntry#addBefore
private void addBefore(LinkedHashMapEntry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}What is this header?
Let's look at the initialization of the header object and call the init method while constructing the LinkedHashMap initialization (and the parent HashMap initializes and calls the init method).
/**
* The head of the doubly linked list. Header of a two-way chained list, with the header's precursor and successor pointing to itself at initialization
*/
private transient LinkedHashMapEntry<K,V> header;
@Override
void init() {
header = new LinkedHashMapEntry<>(-1, null, null, null);
header.before = header.after = header;
}The header has no keys and values by default, and the default precursor and successor point to themselves.Figure:
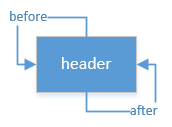
So after calling the addBefore method above, the structure is like this:
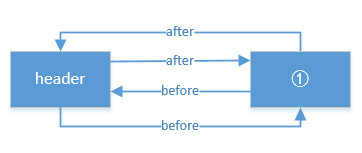
If you add a second node, or look at the addBefore method, the structure is as follows:
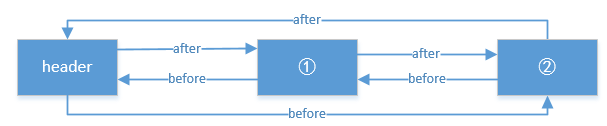
Finally let's go back to LruCache's put method and see step 4. What is trimToSize for?
LruCache#trimToSize
/**
* Remove the eldest entries until the total of remaining entries is at or
* below the requested size.
*
* @param maxSize the maximum size of the cache before returning. May be -1
* to evict even 0-sized elements.
*/
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize || map.isEmpty()) {
break;
}
Map.Entry<K, V> toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}You can see the official note that if the space requested is insufficient, the recently unused entry key pairs will be removed. What is the minimum recent use?Get the set container that holds all Entries first, remove the Entry obtained by the next method directly, remove the entry until the size is less than maxSize, which is really 666;
Now let's explore the entrySet and iterator and next methods.The entrySet method LinkedHashMap is inherited from HashMap
// ---------------- HashMap--------------
public Set<Map.Entry<K,V>> entrySet() {
return entrySet0();
}
private Set<Map.Entry<K,V>> entrySet0() {
Set<Map.Entry<K,V>> es = entrySet;
return es != null ? es : (entrySet = new EntrySet());
}
private final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return newEntryIterator(); // !!!!!!!!!! Look at this
}
...
}
Notice which method this newEntryIterator calls, and we can see that HashMap and LinkedHashMap both have this method
// HashMap
Iterator<Map.Entry<K,V>> newEntryIterator() {
return new EntryIterator();
}
private final class EntryIterator extends HashIterator<Map.Entry<K,V>> { // ①
public Map.Entry<K,V> next() {
return nextEntry();
}
}
// LinkedHashMap must have overridden the parent newEntryIterator method
Iterator<Map.Entry<K,V>> newEntryIterator() {
return new EntryIterator();
}
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> { // ②
public Map.Entry<K,V> next() { return nextEntry(); }
}
1 and 2 are obviously different, the parent is different.When I first started my research, I misread the subjects and made my last face blurred.The object of our study here is LinkedHashMap, so after calling the next method, the nextEntry method of LinkedHashIterator will be called.
LinkedHashMap internal class LinkedHashIterator
private abstract class LinkedHashIterator<T> implements Iterator<T> {
LinkedHashMapEntry<K,V> nextEntry = header.after;
LinkedHashMapEntry<K,V> lastReturned = null;
...
Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
LinkedHashMapEntry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}When Iterator traversal is performed for the first time, the object pointed to by header.after is the first one to be obtained. Combined with the trimToSize method above, it can be found that the object obtained by the first next is remove d directly by map.That means header.after is pointing to the least recently used object.
So, what happens to the internal structure of LinkedHashMap if I use the get method to take out objects for use?
So let's look at the get method of LinkedHashMap.
LinkedHashMap#get
public V get(Object key) {
// ①
LinkedHashMapEntry<K,V> e = (LinkedHashMapEntry<K,V>)getEntry(key);
if (e == null)
return null;
// ②
e.recordAccess(this);
return e.value;
}Let's see first what 1 has done.
HashMap#getEntry
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : sun.misc.Hashing.singleWordWangJenkinsHash(key);
for (HashMapEntry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}Nothing special about this method. Find the hash corresponding bitmark, find the object with the same hash value as the key value, and return the object in turn.
Let's go back to the get method and see what happened. It's even more powerful!!
LinkedHashMapEntry#recordAccess
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) { // accessOrder was set to true during LruCache's initialization of LinkedHashMap
lm.modCount++;
remove(); //
addBefore(lm.header);
}
}First look at the remove method.
private void remove() {
before.after = after;
after.before = before;
}When remove is called, the structure is shown in the following figure: (Suppose we want to get the object in Figure 1)
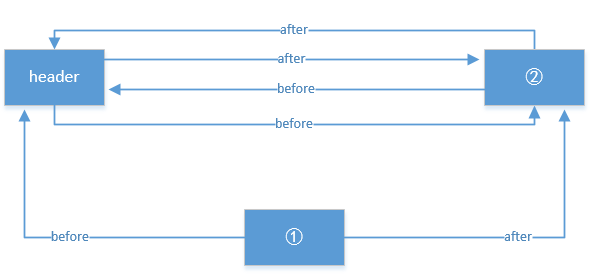
Now look at the addBefore method
private void addBefore(LinkedHashMapEntry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}After calling addBefore, the final structure is as follows:
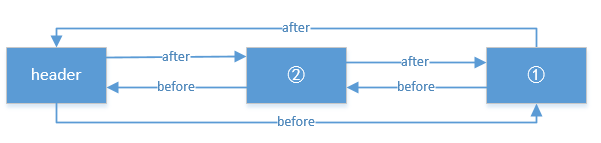
So when an object is "used" by the get method, it will be placed at the end of the list, so the least recently used object is the one that header.after points to.
summary
