# ajax dynamic loading web page
# How to judge whether a web page is dynamically loaded?
# Check the source code of the web page. If there is no data you want in the source code, try to visit the next page. When you click the next page, the whole page is not refreshed, but partially refreshed, most likely ajax loading
# In case of ajax loading, the general solution step is to analyze the response request through the browser or software package capture, and check which data you need in the response,
# Then analyze the URL requested by the headers, which URL to request directly, of course, there will be some interfaces that need to build post requests
import json
import jsonpath
import requests
headers = {
'User-Agent':"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10",
}
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&_v=0.11045029&x-zp-page-request-id=7d6ccc963ff14b1d995b6f21942f2295-1542632726829-135321'
r = requests.get(url=url.format(3*60),headers=headers)
demo = r.text
# string = json.dumps(demo, ensure_ascii=False)
obj = json.loads(demo)
ret = jsonpath.jsonpath(obj, '$..company.name')
print(ret)# ajax dynamic loading web page
# How to judge whether a web page is dynamically loaded?
# Check the source code of the web page. If there is no data you want in the source code, try to visit the next page. When you click the next page, the whole page does not refresh,
# It's just a partial refresh, most likely ajax loading
# In the case of ajax loading, the general solution is to analyze the response request through the browser or software package capture, and check which data is needed in the response,
# Then analyze the URL requested by the headers, which URL to request directly, of course, there will be some interfaces that need to build post requests
#If a red wavy line appears below the imported package, the pip install name is enough
import json
import jsonpath
import requests
headers = {
'User-Agent':"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10",
}
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&_v=0.11045029&x-zp-page-request-id=7d6ccc963ff14b1d995b6f21942f2295-1542632726829-135321'
r = requests.get(url=url.format(3*60),headers=headers)
demo = r.text
# string = json.dumps(demo, ensure_ascii=False)
obj = json.loads(demo)
ret = jsonpath.jsonpath(obj, '$..company.name')
print(ret)
----- Web Capture----

Through observation, change the number after start, different data will appear, the first page is 0, the second page is 60, increasing in turn, pagesize is how many pieces appear on each page, it is better not to change
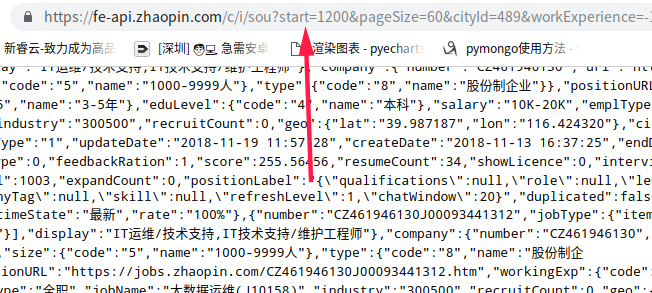
Paste the content of the web page into online json parsing, and you can see that this is a standard json data, and you can see a clear structure through online parsing

The acquired data is a string in json format, which needs to be parsed with jsonpath to obtain the contents. The company name of the current request is selected in the figure
