1 Install Spark-dependent Scala
1.1 Download and Decompress Scala
1.2 Configuring environment variables
2 Download and Decompress Spark
2.1 Download Spark Compression Packet
3.1 Configuring environment variables
3.2 Configure files in conf directory
4 Start and test Spark cluster
4.2 Testing and Using Spark Cluster
4.2.1 Access the URL provided by the Spark cluster
4.2.2 Run the sample program provided by Spark to calculate the circumference
Keyword: Linux CentOS Hadoop Spark Scala Java
Version number: CentOS 7 Hadoop 2.8.0 Spark 2.1.1 Scala 2.12.2 JDK 1.8
Note: Spark can install JDK only. scala It can be installed on a single machine directly, but in this way, it can only use a single machine mode to run code that does not involve distributed computing and distributed storage. For example, Spark can be installed on a single machine, and Spark program for calculating the circumference can be run on a single machine. But we're running a Spark cluster, and we need to call it hadoop Distributed file system, so please install Hadoop first. The installation of Hadoop cluster can refer to this blog:
http://blog.csdn.net/pucao_cug/article/details/71698903
Installing a stand-alone version of Spark can refer to this blog post:
http://blog.csdn.net/pucao_cug/article/details/72377219
Minimizing the installation of Spark clusters requires only these things: JDK, Scala, Hadoop, Spark
1 Install Spark-dependent Scala
For installation of Hadoop, please refer to the above blog, because Spark relies on scala, so before installing Spark, you need to install scala here. Installation is performed on each node.
1.1 Download and decompress Scala
Open the address: http://www.scala-lang.org/
The latest version is 2.12.2, so I'll install it.
As shown in the figure:
It is also possible to open the following address directly:
http://www.scala-lang.org/download/2.12.2.html
As shown in the picture:
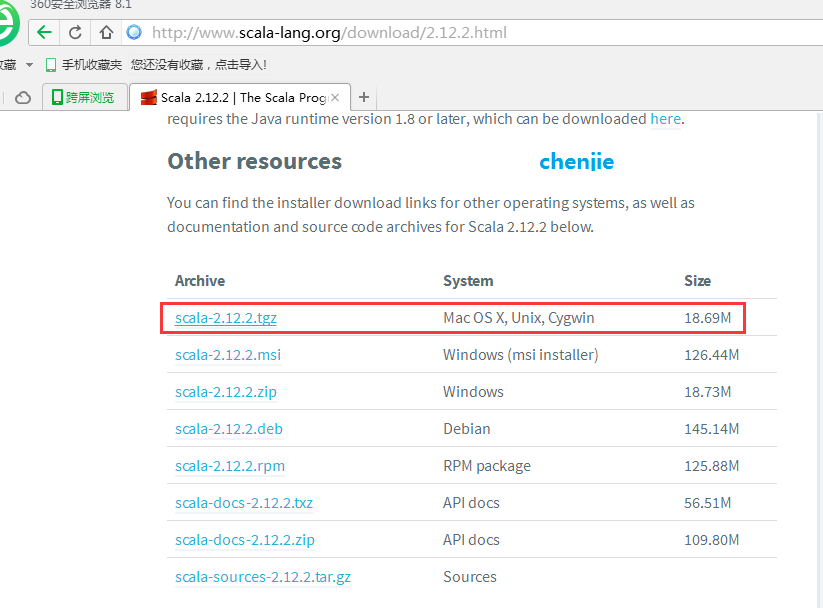
Download the tgz package directly at the following address:
https://downloads.lightbend.com/scala/2.12.2/scala-2.12.2.tgz
stay linux Create a new folder named scala under the opt directory of the server and upload the downloaded compressed package
As shown in the picture:
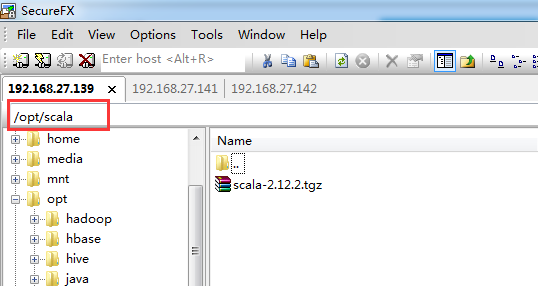
Execute the command and enter the directory:
cd /opt/scala
Execute commands to decompress:
tar -xvf scala-2.12.2
1.2 Configuring environment variables
Edit the file / etc/profile and add a line configuration to it:
- export SCALA_HOME=/opt/scala/scala-2.12.2
export SCALA_HOME=/opt/scala/scala-2.12.2
Add the following to the PATH variable of the file:
- {SCALA_HOME}/bin </span></span></li></ol></div><pre code_snippet_id="2398307" snippet_file_name="blog_20170516_2_9953280" name="code" class="plain" style="display: none;">
{SCALA_HOME}/bin
After adding, mine/etc/profile The configuration is as follows:
- export JAVA_HOME=/opt/java/jdk1.8.0_121
- export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
- export HADOOP_CONF_DIR={HADOOP_HOME}/etc/hadoop </span></li><li class=""><span>export HADOOP_COMMON_LIB_NATIVE_DIR=
- export HADOOP_COMMON_LIB_NATIVE_DIR={HADOOP_HOME}/lib/native
- export HADOOP_OPTS="-Djava.library.path={HADOOP_HOME}/lib" </span></li><li class=""><span>export HIVE_HOME=/opt/hive/apache-hive-2.1.1-bin </span></li><li class="alt"><span>export HIVE_CONF_DIR=
- export HIVE_HOME=/opt/hive/apache-hive-2.1.1-bin
- export HIVE_CONF_DIR={HIVE_HOME}/conf
- export SQOOP_HOME=/opt/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
- export HBASE_HOME=/opt/hbase/hbase-1.2.5
- export ZK_HOME=/opt/zookeeper/zookeeper-3.4.10
- export SCALA_HOME=/opt/scala/scala-2.12.2
- export CLASS_PATH=.:JAVAHOME/lib:{HIVE_HOME}/lib:CLASS_PATH </span></li><li class="alt"><span>export PATH=.:
- export PATH=.:{JAVA_HOME}/bin:HADOOPHOME/bin:{HADOOP_HOME}/sbin:SPARKHOME/bin:{ZK_HOME}/bin:HIVEHOME/bin:{SQOOP_HOME}/bin:HBASEHOME/bin:{SCALA_HOME}/bin:$PATH
export JAVA_HOME=/opt/java/jdk1.8.0_121
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export HIVE_HOME=/opt/hive/apache-hive-2.1.1-bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export SQOOP_HOME=/opt/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
export HBASE_HOME=/opt/hbase/hbase-1.2.5
export ZK_HOME=/opt/zookeeper/zookeeper-3.4.10
export SCALA_HOME=/opt/scala/scala-2.12.2
export CLASS_PATH=.:${JAVA_HOME}/lib:${HIVE_HOME}/lib:$CLASS_PATH
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${ZK_HOME}/bin:${HIVE_HOME}/bin:${SQOOP_HOME}/bin:${HBASE_HOME}/bin:${SCALA_HOME}/bin:$PATH
Note: You can only focus on the JDK SCALA Hadoop Spark environment variables mentioned at the beginning, and the rest, such as Zookeeper, Hbase,Hive Sqoop does not need to be managed.
As shown in the figure:

After the environment variable configuration is completed, execute the following commands:
- source /etc/profile
source /etc/profile
1.3 Verify Scala
Implement orders:
- scala -version
scala -version
Fig.

2 Download and Decompress Spark
Install Spark on each node, repeating the following steps.
2.1 Download Spark Compression Packet
Open the download address:
http://spark.apache.org/downloads.html
As shown in the picture:
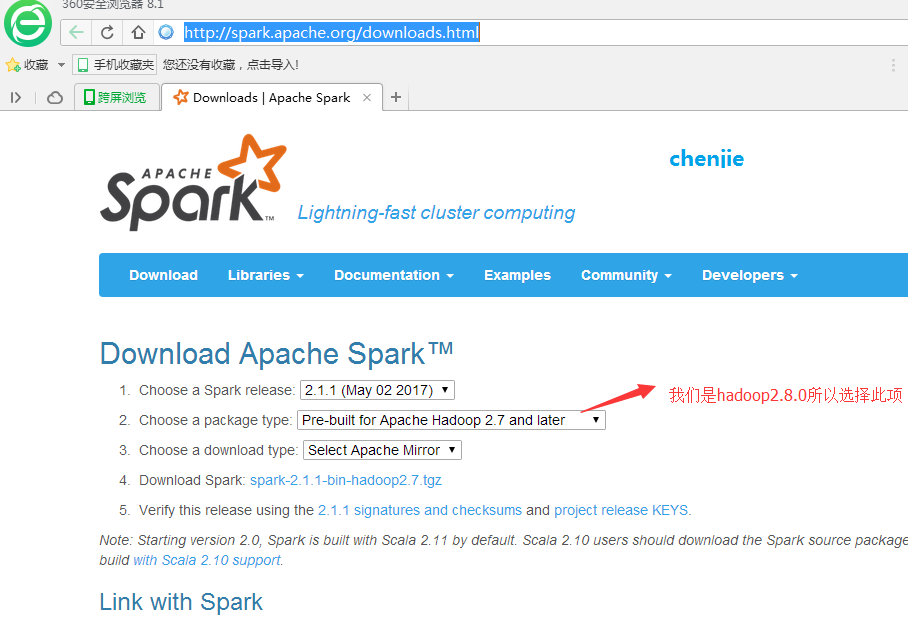
Clicking on the Download Spark in the picture above is equivalent to opening the address directly:
https://www.apache.org/dyn/closer.lua/spark/spark-2.1.1/spark-2.1.1-bin-hadoop2.7.tgz
After downloading, we got about 200M files: spark-2.1.1-bin-hadoop 2.7
It is also possible to use the following address directly:
http://mirrors.hust.edu.cn/apache/spark/spark-2.1.1/spark-2.1.1-bin-hadoop2.7.tgz
2.2 Decompression of Spark
After downloading, create a new folder named spark under the opt directory of the Linux server and upload the compressed package just downloaded.
As shown in the picture:
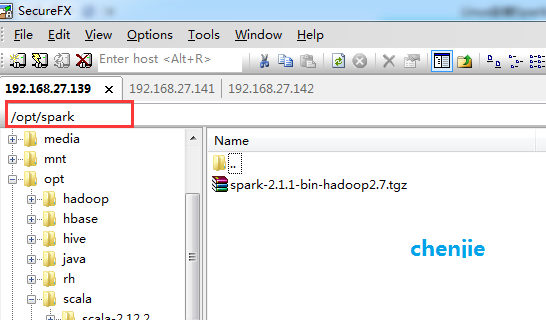
To enter the directory is to execute the following commands:
cd /opt/spark
Execute the decompression command:
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz
3. Spark-related configuration
Explanation: Because we build a Spark cluster based on hadoop cluster, I install Spark on every hadoop node. We need to configure it according to the following steps. If we start it, we only need to start it on the Master machine of the Spark cluster. Here I start it on hserver1.
3.1 Configuring environment variables
Edit / etc/profile file, add
- export SPARK_HOME=/opt/spark/spark-2.1.1-bin-hadoop2.7
export SPARK_HOME=/opt/spark/spark-2.1.1-bin-hadoop2.7
Edit the PATH variable in the file after adding the above variable.
- {SPARK_HOME}/bin </span></span></li></ol></div><pre code_snippet_id="2398307" snippet_file_name="blog_20170517_7_8203149" name="code" class="plain" style="display: none;">
{SPARK_HOME}/bin
Be careful:becauseSPARKHOME/sbin</span><spanstyle="color:red">orderrecordlowerYesOnesomewritingpiecenamecalland</span><spanstyle="color:red">There are some file names andHADOOP_HOME/sbinFiles under the directory have the same name. To avoid conflicting files with the same name, they are not here. PATH Add in variablesSPARKHOME/sbinonlyaddplus了<spanstyle="color:rgb(255,0,0);font−size:14px"><strong>SPARK_HOME/bin.
When the modification is completed, mine/etc/profile The contents of the document are as follows:
- export JAVA_HOME=/opt/java/jdk1.8.0_121
- export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
- export HADOOP_CONF_DIR={HADOOP_HOME}/etc/hadoop </span></li><li class=""><span>export HADOOP_COMMON_LIB_NATIVE_DIR=
- export HADOOP_COMMON_LIB_NATIVE_DIR={HADOOP_HOME}/lib/native
- export HADOOP_OPTS="-Djava.library.path={HADOOP_HOME}/lib" </span></li><li class=""><span>export HIVE_HOME=/opt/hive/apache-hive-2.1.1-bin </span></li><li class="alt"><span>export HIVE_CONF_DIR=
- export HIVE_HOME=/opt/hive/apache-hive-2.1.1-bin
- export HIVE_CONF_DIR={HIVE_HOME}/conf
- export SQOOP_HOME=/opt/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
- export HBASE_HOME=/opt/hbase/hbase-1.2.5
- export ZK_HOME=/opt/zookeeper/zookeeper-3.4.10
- export SCALA_HOME=/opt/scala/scala-2.12.2
- export SPARK_HOME=/opt/spark/spark-2.1.1-bin-hadoop2.7
- export CLASS_PATH=.:JAVAHOME/lib:{HIVE_HOME}/lib:CLASS_PATH </span></li><li class=""><span>export PATH=.:
- export PATH=.:{JAVA_HOME}/bin:HADOOPHOME/bin:{HADOOP_HOME}/sbin:SPARKHOME/bin:{ZK_HOME}/bin:HIVEHOME/bin:{SQOOP_HOME}/bin:HBASEHOME:{SCALA_HOME}/bin:$PATH
export JAVA_HOME=/opt/java/jdk1.8.0_121
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export HIVE_HOME=/opt/hive/apache-hive-2.1.1-bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export SQOOP_HOME=/opt/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
export HBASE_HOME=/opt/hbase/hbase-1.2.5
export ZK_HOME=/opt/zookeeper/zookeeper-3.4.10
export SCALA_HOME=/opt/scala/scala-2.12.2
export SPARK_HOME=/opt/spark/spark-2.1.1-bin-hadoop2.7
export CLASS_PATH=.:${JAVA_HOME}/lib:${HIVE_HOME}/lib:$CLASS_PATH
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${ZK_HOME}/bin:${HIVE_HOME}/bin:${SQOOP_HOME}/bin:${HBASE_HOME}:${SCALA_HOME}/bin:$PATH
Note: You can only focus on the JDK SCALA Hadoop Spark environment variables mentioned at the beginning, and the rest, such as Zookeeper, hbase,hive Sqoop does not need to be managed.
As shown in the figure:

After editing, execute the command:
source /etc/profile
3.2 Configure files in conf directory
Configure the files in the / opt/spark/spark-2.1.1-bin-hadoop 2.7/conf directory.
3.2.1 New spark-env.h file
Execute the command and enter the / opt/spark/spark-2.1.1-bin-hadoop 2.7/conf directory:
cd /opt/spark/spark-2.1.1-bin-hadoop2.7/conf
Create a spark-env.h file for the template we created with spark. The command is:
cp spark-env.sh.template spark-env.sh
As shown in the figure:

Edit the spark-env.h file and add the configuration (the specific path is your own):
- export SCALA_HOME=/opt/scala/scala-2.12.2
- export JAVA_HOME=/opt/java/jdk1.8.0_121
- export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
- export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
- export SPARK_HOME=/opt/spark/spark-2.1.1-bin-hadoop2.7
- export SPARK_MASTER_IP=hserver1
- export SPARK_EXECUTOR_MEMORY=1G
export SCALA_HOME=/opt/scala/scala-2.12.2 export JAVA_HOME=/opt/java/jdk1.8.0_121 export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export SPARK_HOME=/opt/spark/spark-2.1.1-bin-hadoop2.7 export SPARK_MASTER_IP=hserver1 export SPARK_EXECUTOR_MEMORY=1G
3.2.2 New slaves file
Execute the command and enter the / opt/spark/spark-2.1.1-bin-hadoop 2.7/conf directory:
cd /opt/spark/spark-2.1.1-bin-hadoop2.7/conf
Create a slaves file for the template we created with spark. The command is:
cp slaves.template slaves
As shown in the picture:

Edit the slaves file with the following contents:
- hserver2
- hserver3
hserver2 hserver3
4 Start and test Spark cluster
4.1 Start Spark
Because spark relies on the distributed file system provided by hadoop, make sure that Hadoop is running properly before starting spark. For installation and start-up of Hadoop 2.8.0, please refer to this blog:
http://blog.csdn.net/pucao_cug/article/details/71698903
Under the normal operation of hadoop, execute commands on hserver1 (that is, the namenode of hadoop, the marster node of spark):
cd /opt/spark/spark-2.1.1-bin-hadoop2.7/sbin
Execute the startup script:
./start-all.sh
As shown in the picture:

The complete content is:
- [root@hserver1 sbin]# cd/opt/spark/spark-2.1.1-bin-hadoop2.7/sbin
- [root@hserver1 sbin]# ./start-all.sh
- starting org.apache.spark.deploy.master.Master,logging to/opt/spark/spark-2.1.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-hserver1.out
- hserver2: startingorg.apache.spark.deploy.worker.Worker, logging to/opt/spark/spark-2.1.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hserver2.out
- hserver3: startingorg.apache.spark.deploy.worker.Worker, logging to/opt/spark/spark-2.1.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hserver3.out
- [root@hserver1 sbin]#
[root@hserver1 sbin]# cd/opt/spark/spark-2.1.1-bin-hadoop2.7/sbin [root@hserver1 sbin]# ./start-all.sh starting org.apache.spark.deploy.master.Master,logging to/opt/spark/spark-2.1.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-hserver1.out hserver2: startingorg.apache.spark.deploy.worker.Worker, logging to/opt/spark/spark-2.1.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hserver2.out hserver3: startingorg.apache.spark.deploy.worker.Worker, logging to/opt/spark/spark-2.1.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hserver3.out [root@hserver1 sbin]#
Note: In the above command, there is. / This cannot be omitted,. / which means to execute the start-all.sh script in the current directory.
4.2 Testing and Using Spark Clusters
4.2.1 Access the URL provided by the Spark cluster
Access Mster machine in browser, Master machine in my Spark cluster is hserver1, IP address 192.168.27.143, access 8080 port, URL is: http://192.168.27.143:8080/
As shown in the figure:
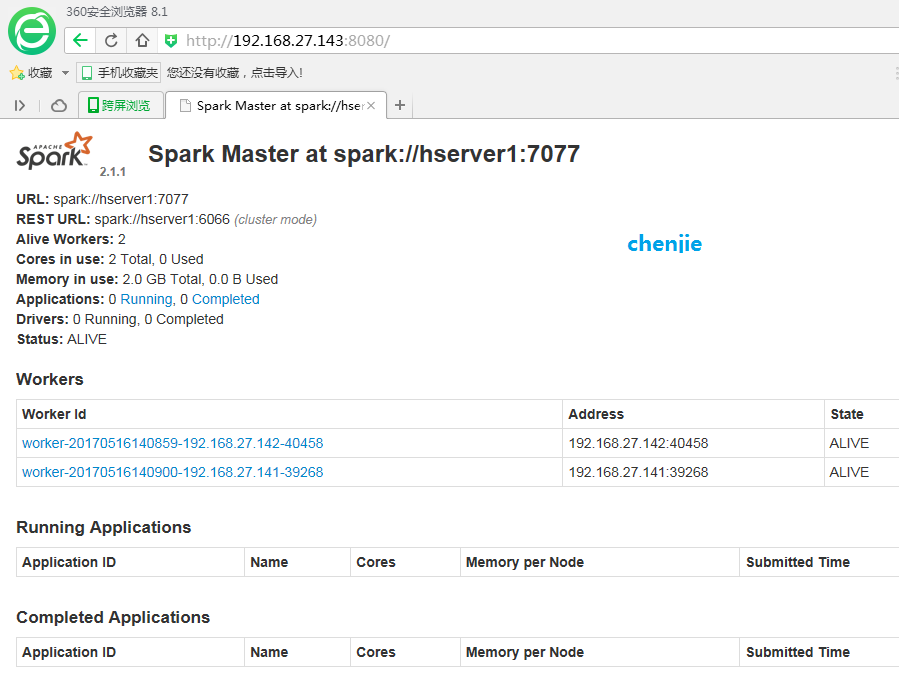
4.2.2 Run the sample program provided by Spark to calculate the circumference
Simply run a Demo to calculate the circumference in local mode. Follow these steps.
The first step is to enter the root directory of Spark, which is to execute the following script:
cd /opt/spark/spark-2.1.1-bin-hadoop2.7
As shown in the picture:

The second step is to call Spark's own Demo to calculate the circumference and execute the following command:
- ./bin/spark-submit –class org.apache.spark.examples.SparkPi –master local examples/jars/spark-examples_2.11-2.1.1.jar
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local examples/jars/spark-examples_2.11-2.1.1.jar
After the command is executed, the spark sample program has begun to execute
As shown in the figure:
The execution results came out quickly, and I marked them in red boxes.
As shown in the picture:
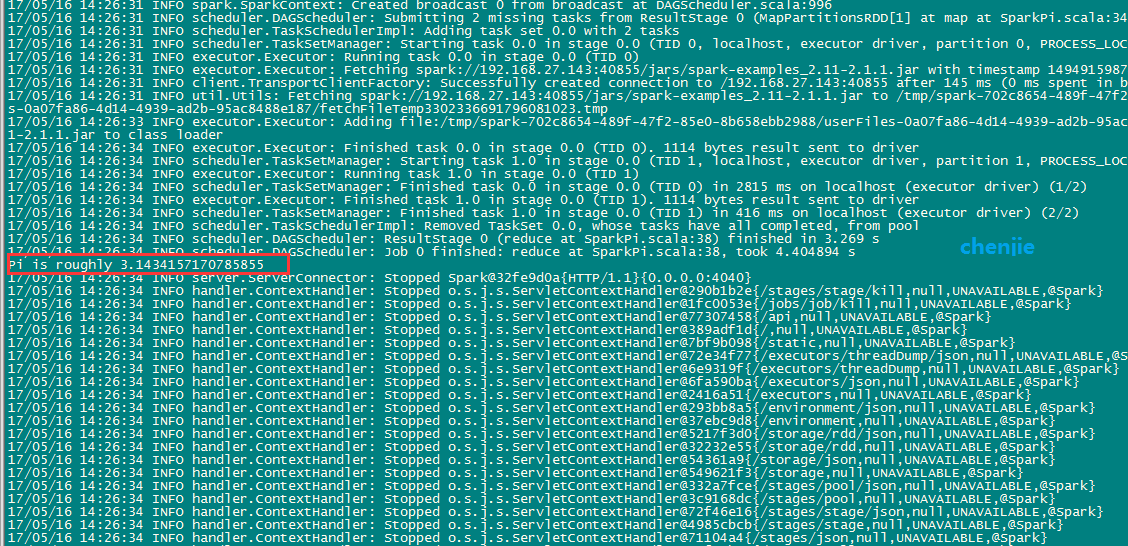
The complete console output is:
- [root@hserver1 bin]# cd /opt/spark/spark-2.1.1-bin-hadoop2.7
- [root@hserver1 spark-2.1.1-bin-hadoop2.7]# ./bin/spark-submit–class org.apache.spark.examples.SparkPi –master localexamples/jars/spark-examples_2.11-2.1.1.jar
- 17/05/16 14:26:23 INFO spark.SparkContext: Running Spark version2.1.1
- 17/05/16 14:26:24 WARN util.NativeCodeLoader: Unable to loadnative-hadoop library for your platform... using builtin-java classes whereapplicable
- 17/05/16 14:26:25 INFO spark.SecurityManager: Changing view acls to:root
- 17/05/16 14:26:25 INFO spark.SecurityManager: Changing modify aclsto: root
- 17/05/16 14:26:25 INFO spark.SecurityManager: Changing view aclsgroups to:
- 17/05/16 14:26:25 INFO spark.SecurityManager: Changing modify aclsgroups to:
- 17/05/16 14:26:25 INFO spark.SecurityManager: SecurityManager:authentication disabled; ui acls disabled; users with view permissions: Set(root); groups withview permissions: Set(); users withmodify permissions: Set(root); groups with modify permissions: Set()
- 17/05/16 14:26:25 INFO util.Utils: Successfully started service'sparkDriver' on port 40855.
- 17/05/16 14:26:26 INFO spark.SparkEnv: Registering MapOutputTracker
- 17/05/16 14:26:26 INFO spark.SparkEnv: RegisteringBlockManagerMaster
- 17/05/16 14:26:26 INFO storage.BlockManagerMasterEndpoint: Usingorg.apache.spark.storage.DefaultTopologyMapper for getting topology information
- 17/05/16 14:26:26 INFO storage.BlockManagerMasterEndpoint:BlockManagerMasterEndpoint up
- 17/05/16 14:26:26 INFO storage.DiskBlockManager: Created localdirectory at /tmp/blockmgr-cf8cbb42-95d2-4284-9a48-67592363976a
- 17/05/16 14:26:26 INFO memory.MemoryStore: MemoryStore started withcapacity 413.9 MB
- 17/05/16 14:26:26 INFO spark.SparkEnv: RegisteringOutputCommitCoordinator
- 17/05/16 14:26:26 INFO util.log: Logging initialized @5206ms
- 17/05/16 14:26:27 INFO server.Server: jetty-9.2.z-SNAPSHOT
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@5118388b{/jobs,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@15a902e7{/jobs/json,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@7876d598{/jobs/job,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4a3e3e8b{/jobs/job/json,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@5af28b27{/stages,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@71104a4{/stages/json,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@4985cbcb{/stages/stage,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@72f46e16{/stages/stage/json,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@3c9168dc{/stages/pool,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@332a7fce{/stages/pool/json,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@549621f3{/storage,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@54361a9{/storage/json,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@32232e55{/storage/rdd,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@5217f3d0{/storage/rdd/json,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@37ebc9d8{/environment,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@293bb8a5{/environment/json,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@2416a51{/executors,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@6fa590ba{/executors/json,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@6e9319f{/executors/threadDump,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@72e34f77{/executors/threadDump/json,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@7bf9b098{/static,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@389adf1d{/,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@77307458{/api,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@1fc0053e{/jobs/job/kill,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@290b1b2e{/stages/stage/kill,null,AVAILABLE,@Spark}
- 17/05/16 14:26:27 INFO server.ServerConnector: StartedSpark@32fe9d0a{HTTP/1.1}{0.0.0.0:4040}
- 17/05/16 14:26:27 INFO server.Server: Started @5838ms
- 17/05/16 14:26:27 INFO util.Utils: Successfully started service'SparkUI' on port 4040.
- 17/05/16 14:26:27 INFO ui.SparkUI: Bound SparkUI to 0.0.0.0, andstarted at http://192.168.27.143:4040
- 17/05/16 14:26:27 INFO spark.SparkContext: Added JARfile:/opt/spark/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jarat spark://192.168.27.143:40855/jars/spark-examples_2.11-2.1.1.jar withtimestamp 1494915987472
- 17/05/16 14:26:27 INFO executor.Executor: Starting executor IDdriver on host localhost
- 17/05/16 14:26:27 INFO util.Utils: Successfully started service'org.apache.spark.network.netty.NettyBlockTransferService' on port 41104.
- 17/05/16 14:26:27 INFO netty.NettyBlockTransferService: Servercreated on 192.168.27.143:41104
- 17/05/16 14:26:27 INFO storage.BlockManager: Usingorg.apache.spark.storage.RandomBlockReplicationPolicy for block replicationpolicy
- 17/05/16 14:26:27 INFO storage.BlockManagerMaster: RegisteringBlockManager BlockManagerId(driver, 192.168.27.143, 41104, None)
- 17/05/16 14:26:27 INFO storage.BlockManagerMasterEndpoint:Registering block manager 192.168.27.143:41104 with 413.9 MB RAM,BlockManagerId(driver, 192.168.27.143, 41104, None)
- 17/05/16 14:26:27 INFO storage.BlockManagerMaster: RegisteredBlockManager BlockManagerId(driver, 192.168.27.143, 41104, None)
- 17/05/16 14:26:27 INFO storage.BlockManager: InitializedBlockManager: BlockManagerId(driver, 192.168.27.143, 41104, None)
- 17/05/16 14:26:28 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@4e6d7365{/metrics/json,null,AVAILABLE,@Spark}
- 17/05/16 14:26:28 INFO internal.SharedState: Warehouse path is'file:/opt/spark/spark-2.1.1-bin-hadoop2.7/spark-warehouse'.
- 17/05/16 14:26:28 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@705202d1{/SQL,null,AVAILABLE,@Spark}
- 17/05/16 14:26:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3e58d65e{/SQL/json,null,AVAILABLE,@Spark}
- 17/05/16 14:26:28 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@6f63c44f{/SQL/execution,null,AVAILABLE,@Spark}
- 17/05/16 14:26:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@62a8fd44{/SQL/execution/json,null,AVAILABLE,@Spark}
- 17/05/16 14:26:28 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@1d035be3{/static/sql,null,AVAILABLE,@Spark}
- 17/05/16 14:26:30 INFO spark.SparkContext: Starting job: reduce atSparkPi.scala:38
- 17/05/16 14:26:30 INFO scheduler.DAGScheduler: Got job 0 (reduce atSparkPi.scala:38) with 2 output partitions
- 17/05/16 14:26:30 INFO scheduler.DAGScheduler: Final stage:ResultStage 0 (reduce at SparkPi.scala:38)
- 17/05/16 14:26:30 INFO scheduler.DAGScheduler: Parents of finalstage: List()
- 17/05/16 14:26:30 INFO scheduler.DAGScheduler: Missing parents:List()
- 17/05/16 14:26:30 INFO scheduler.DAGScheduler: SubmittingResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has nomissing parents
- 17/05/16 14:26:30 INFO memory.MemoryStore: Block broadcast_0 storedas values in memory (estimated size 1832.0 B, free 413.9 MB)
- 17/05/16 14:26:30 INFO memory.MemoryStore: Block broadcast_0_piece0stored as bytes in memory (estimated size 1167.0 B, free 413.9 MB)
- 17/05/16 14:26:31 INFO storage.BlockManagerInfo: Addedbroadcast_0_piece0 in memory on 192.168.27.143:41104 (size: 1167.0 B, free:413.9 MB)
- 17/05/16 14:26:31 INFO spark.SparkContext: Created broadcast 0 frombroadcast at DAGScheduler.scala:996
- 17/05/16 14:26:31 INFO scheduler.DAGScheduler: Submitting 2 missingtasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34)
- 17/05/16 14:26:31 INFO scheduler.TaskSchedulerImpl: Adding task set0.0 with 2 tasks
- 17/05/16 14:26:31 INFO scheduler.TaskSetManager: Starting task 0.0in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL,6026 bytes)
- 17/05/16 14:26:31 INFO executor.Executor: Running task 0.0 in stage0.0 (TID 0)
- 17/05/16 14:26:31 INFO executor.Executor: Fetchingspark://192.168.27.143:40855/jars/spark-examples_2.11-2.1.1.jar with timestamp1494915987472
- 17/05/16 14:26:31 INFO client.TransportClientFactory: Successfullycreated connection to /192.168.27.143:40855 after 145 ms (0 ms spent inbootstraps)
- 17/05/16 14:26:31 INFO util.Utils: Fetchingspark://192.168.27.143:40855/jars/spark-examples_2.11-2.1.1.jar to/tmp/spark-702c8654-489f-47f2-85e0-8b658ebb2988/userFiles-0a07fa86-4d14-4939-ad2b-95ac8488e187/fetchFileTemp3302336691796081023.tmp
- 17/05/16 14:26:33 INFO executor.Executor: Addingfile:/tmp/spark-702c8654-489f-47f2-85e0-8b658ebb2988/userFiles-0a07fa86-4d14-4939-ad2b-95ac8488e187/spark-examples_2.11-2.1.1.jarto class loader
- 17/05/16 14:26:34 INFO executor.Executor: Finished task 0.0 in stage0.0 (TID 0). 1114 bytes result sent to driver
- 17/05/16 14:26:34 INFO scheduler.TaskSetManager: Starting task 1.0in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL,6026 bytes)
- 17/05/16 14:26:34 INFO executor.Executor: Running task 1.0 in stage0.0 (TID 1)
- 17/05/16 14:26:34 INFO scheduler.TaskSetManager: Finished task 0.0in stage 0.0 (TID 0) in 2815 ms on localhost (executor driver) (1/2)
- 17/05/16 14:26:34 INFO executor.Executor: Finished task 1.0 in stage0.0 (TID 1). 1114 bytes result sent to driver
- 17/05/16 14:26:34 INFO scheduler.TaskSetManager: Finished task 1.0in stage 0.0 (TID 1) in 416 ms on localhost (executor driver) (2/2)
- 17/05/16 14:26:34 INFO scheduler.TaskSchedulerImpl: Removed TaskSet0.0, whose tasks have all completed, from pool
- 17/05/16 14:26:34 INFO scheduler.DAGScheduler: ResultStage 0 (reduceat SparkPi.scala:38) finished in 3.269 s
- 17/05/16 14:26:34 INFO scheduler.DAGScheduler: Job 0 finished:reduce at SparkPi.scala:38, took 4.404894 s
- Pi is roughly 3.1434157170785855
- 17/05/16 14:26:34 INFO server.ServerConnector: StoppedSpark@32fe9d0a{HTTP/1.1}{0.0.0.0:4040}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@290b1b2e{/stages/stage/kill,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@1fc0053e{/jobs/job/kill,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@77307458{/api,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@389adf1d{/,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@7bf9b098{/static,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@72e34f77{/executors/threadDump/json,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@6e9319f{/executors/threadDump,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@6fa590ba{/executors/json,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@2416a51{/executors,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@293bb8a5{/environment/json,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@37ebc9d8{/environment,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@5217f3d0{/storage/rdd/json,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@32232e55{/storage/rdd,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@54361a9{/storage/json,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@549621f3{/storage,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@332a7fce{/stages/pool/json,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@3c9168dc{/stages/pool,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@72f46e16{/stages/stage/json,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@4985cbcb{/stages/stage,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@71104a4{/stages/json,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@5af28b27{/stages,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@4a3e3e8b{/jobs/job/json,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@7876d598{/jobs/job,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@15a902e7{/jobs/json,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@5118388b{/jobs,null,UNAVAILABLE,@Spark}
- 17/05/16 14:26:34 INFO ui.SparkUI: Stopped Spark web UI athttp://192.168.27.143:4040
- 17/05/16 14:26:34 INFO spark.MapOutputTrackerMasterEndpoint:MapOutputTrackerMasterEndpoint stopped!
- 17/05/16 14:26:34 INFO memory.MemoryStore: MemoryStore cleared
- 17/05/16 14:26:34 INFO storage.BlockManager: BlockManager stopped
- 17/05/16 14:26:34 INFO storage.BlockManagerMaster: BlockManagerMasterstopped
- 17/05/16 14:26:34 INFOscheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint:OutputCommitCoordinator stopped!
- 17/05/16 14:26:34 INFO spark.SparkContext: Successfully stoppedSparkContext
- 17/05/16 14:26:34 INFO util.ShutdownHookManager: Shutdown hookcalled
- 17/05/16 14:26:34 INFO util.ShutdownHookManager: Deleting directory/tmp/spark-702c8654-489f-47f2-85e0-8b658ebb2988
- [root@hserver1 spark-2.1.1-bin-hadoop2.7]#
[root@hserver1 bin]# cd /opt/spark/spark-2.1.1-bin-hadoop2.7
[root@hserver1 spark-2.1.1-bin-hadoop2.7]# ./bin/spark-submit--class org.apache.spark.examples.SparkPi --master localexamples/jars/spark-examples_2.11-2.1.1.jar
17/05/16 14:26:23 INFO spark.SparkContext: Running Spark version2.1.1
17/05/16 14:26:24 WARN util.NativeCodeLoader: Unable to loadnative-hadoop library for your platform... using builtin-java classes whereapplicable
17/05/16 14:26:25 INFO spark.SecurityManager: Changing view acls to:root
17/05/16 14:26:25 INFO spark.SecurityManager: Changing modify aclsto: root
17/05/16 14:26:25 INFO spark.SecurityManager: Changing view aclsgroups to:
17/05/16 14:26:25 INFO spark.SecurityManager: Changing modify aclsgroups to:
17/05/16 14:26:25 INFO spark.SecurityManager: SecurityManager:authentication disabled; ui acls disabled; users with view permissions: Set(root); groups withview permissions: Set(); users withmodify permissions: Set(root); groups with modify permissions: Set()
17/05/16 14:26:25 INFO util.Utils: Successfully started service'sparkDriver' on port 40855.
17/05/16 14:26:26 INFO spark.SparkEnv: Registering MapOutputTracker
17/05/16 14:26:26 INFO spark.SparkEnv: RegisteringBlockManagerMaster
17/05/16 14:26:26 INFO storage.BlockManagerMasterEndpoint: Usingorg.apache.spark.storage.DefaultTopologyMapper for getting topology information
17/05/16 14:26:26 INFO storage.BlockManagerMasterEndpoint:BlockManagerMasterEndpoint up
17/05/16 14:26:26 INFO storage.DiskBlockManager: Created localdirectory at /tmp/blockmgr-cf8cbb42-95d2-4284-9a48-67592363976a
17/05/16 14:26:26 INFO memory.MemoryStore: MemoryStore started withcapacity 413.9 MB
17/05/16 14:26:26 INFO spark.SparkEnv: RegisteringOutputCommitCoordinator
17/05/16 14:26:26 INFO util.log: Logging initialized @5206ms
17/05/16 14:26:27 INFO server.Server: jetty-9.2.z-SNAPSHOT
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@5118388b{/jobs,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@15a902e7{/jobs/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@7876d598{/jobs/job,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4a3e3e8b{/jobs/job/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@5af28b27{/stages,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@71104a4{/stages/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@4985cbcb{/stages/stage,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@72f46e16{/stages/stage/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@3c9168dc{/stages/pool,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@332a7fce{/stages/pool/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@549621f3{/storage,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@54361a9{/storage/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@32232e55{/storage/rdd,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@5217f3d0{/storage/rdd/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@37ebc9d8{/environment,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@293bb8a5{/environment/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@2416a51{/executors,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@6fa590ba{/executors/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@6e9319f{/executors/threadDump,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@72e34f77{/executors/threadDump/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@7bf9b098{/static,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@389adf1d{/,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@77307458{/api,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@1fc0053e{/jobs/job/kill,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@290b1b2e{/stages/stage/kill,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO server.ServerConnector: StartedSpark@32fe9d0a{HTTP/1.1}{0.0.0.0:4040}
17/05/16 14:26:27 INFO server.Server: Started @5838ms
17/05/16 14:26:27 INFO util.Utils: Successfully started service'SparkUI' on port 4040.
17/05/16 14:26:27 INFO ui.SparkUI: Bound SparkUI to 0.0.0.0, andstarted at http://192.168.27.143:4040
17/05/16 14:26:27 INFO spark.SparkContext: Added JARfile:/opt/spark/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jarat spark://192.168.27.143:40855/jars/spark-examples_2.11-2.1.1.jar withtimestamp 1494915987472
17/05/16 14:26:27 INFO executor.Executor: Starting executor IDdriver on host localhost
17/05/16 14:26:27 INFO util.Utils: Successfully started service'org.apache.spark.network.netty.NettyBlockTransferService' on port 41104.
17/05/16 14:26:27 INFO netty.NettyBlockTransferService: Servercreated on 192.168.27.143:41104
17/05/16 14:26:27 INFO storage.BlockManager: Usingorg.apache.spark.storage.RandomBlockReplicationPolicy for block replicationpolicy
17/05/16 14:26:27 INFO storage.BlockManagerMaster: RegisteringBlockManager BlockManagerId(driver, 192.168.27.143, 41104, None)
17/05/16 14:26:27 INFO storage.BlockManagerMasterEndpoint:Registering block manager 192.168.27.143:41104 with 413.9 MB RAM,BlockManagerId(driver, 192.168.27.143, 41104, None)
17/05/16 14:26:27 INFO storage.BlockManagerMaster: RegisteredBlockManager BlockManagerId(driver, 192.168.27.143, 41104, None)
17/05/16 14:26:27 INFO storage.BlockManager: InitializedBlockManager: BlockManagerId(driver, 192.168.27.143, 41104, None)
17/05/16 14:26:28 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@4e6d7365{/metrics/json,null,AVAILABLE,@Spark}
17/05/16 14:26:28 INFO internal.SharedState: Warehouse path is'file:/opt/spark/spark-2.1.1-bin-hadoop2.7/spark-warehouse'.
17/05/16 14:26:28 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@705202d1{/SQL,null,AVAILABLE,@Spark}
17/05/16 14:26:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3e58d65e{/SQL/json,null,AVAILABLE,@Spark}
17/05/16 14:26:28 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@6f63c44f{/SQL/execution,null,AVAILABLE,@Spark}
17/05/16 14:26:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@62a8fd44{/SQL/execution/json,null,AVAILABLE,@Spark}
17/05/16 14:26:28 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@1d035be3{/static/sql,null,AVAILABLE,@Spark}
17/05/16 14:26:30 INFO spark.SparkContext: Starting job: reduce atSparkPi.scala:38
17/05/16 14:26:30 INFO scheduler.DAGScheduler: Got job 0 (reduce atSparkPi.scala:38) with 2 output partitions
17/05/16 14:26:30 INFO scheduler.DAGScheduler: Final stage:ResultStage 0 (reduce at SparkPi.scala:38)
17/05/16 14:26:30 INFO scheduler.DAGScheduler: Parents of finalstage: List()
17/05/16 14:26:30 INFO scheduler.DAGScheduler: Missing parents:List()
17/05/16 14:26:30 INFO scheduler.DAGScheduler: SubmittingResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has nomissing parents
17/05/16 14:26:30 INFO memory.MemoryStore: Block broadcast_0 storedas values in memory (estimated size 1832.0 B, free 413.9 MB)
17/05/16 14:26:30 INFO memory.MemoryStore: Block broadcast_0_piece0stored as bytes in memory (estimated size 1167.0 B, free 413.9 MB)
17/05/16 14:26:31 INFO storage.BlockManagerInfo: Addedbroadcast_0_piece0 in memory on 192.168.27.143:41104 (size: 1167.0 B, free:413.9 MB)
17/05/16 14:26:31 INFO spark.SparkContext: Created broadcast 0 frombroadcast at DAGScheduler.scala:996
17/05/16 14:26:31 INFO scheduler.DAGScheduler: Submitting 2 missingtasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34)
17/05/16 14:26:31 INFO scheduler.TaskSchedulerImpl: Adding task set0.0 with 2 tasks
17/05/16 14:26:31 INFO scheduler.TaskSetManager: Starting task 0.0in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL,6026 bytes)
17/05/16 14:26:31 INFO executor.Executor: Running task 0.0 in stage0.0 (TID 0)
17/05/16 14:26:31 INFO executor.Executor: Fetchingspark://192.168.27.143:40855/jars/spark-examples_2.11-2.1.1.jar with timestamp1494915987472
17/05/16 14:26:31 INFO client.TransportClientFactory: Successfullycreated connection to /192.168.27.143:40855 after 145 ms (0 ms spent inbootstraps)
17/05/16 14:26:31 INFO util.Utils: Fetchingspark://192.168.27.143:40855/jars/spark-examples_2.11-2.1.1.jar to/tmp/spark-702c8654-489f-47f2-85e0-8b658ebb2988/userFiles-0a07fa86-4d14-4939-ad2b-95ac8488e187/fetchFileTemp3302336691796081023.tmp
17/05/16 14:26:33 INFO executor.Executor: Addingfile:/tmp/spark-702c8654-489f-47f2-85e0-8b658ebb2988/userFiles-0a07fa86-4d14-4939-ad2b-95ac8488e187/spark-examples_2.11-2.1.1.jarto class loader
17/05/16 14:26:34 INFO executor.Executor: Finished task 0.0 in stage0.0 (TID 0). 1114 bytes result sent to driver
17/05/16 14:26:34 INFO scheduler.TaskSetManager: Starting task 1.0in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL,6026 bytes)
17/05/16 14:26:34 INFO executor.Executor: Running task 1.0 in stage0.0 (TID 1)
17/05/16 14:26:34 INFO scheduler.TaskSetManager: Finished task 0.0in stage 0.0 (TID 0) in 2815 ms on localhost (executor driver) (1/2)
17/05/16 14:26:34 INFO executor.Executor: Finished task 1.0 in stage0.0 (TID 1). 1114 bytes result sent to driver
17/05/16 14:26:34 INFO scheduler.TaskSetManager: Finished task 1.0in stage 0.0 (TID 1) in 416 ms on localhost (executor driver) (2/2)
17/05/16 14:26:34 INFO scheduler.TaskSchedulerImpl: Removed TaskSet0.0, whose tasks have all completed, from pool
17/05/16 14:26:34 INFO scheduler.DAGScheduler: ResultStage 0 (reduceat SparkPi.scala:38) finished in 3.269 s
17/05/16 14:26:34 INFO scheduler.DAGScheduler: Job 0 finished:reduce at SparkPi.scala:38, took 4.404894 s
Pi is roughly 3.1434157170785855
17/05/16 14:26:34 INFO server.ServerConnector: StoppedSpark@32fe9d0a{HTTP/1.1}{0.0.0.0:4040}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@290b1b2e{/stages/stage/kill,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@1fc0053e{/jobs/job/kill,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@77307458{/api,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@389adf1d{/,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@7bf9b098{/static,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@72e34f77{/executors/threadDump/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@6e9319f{/executors/threadDump,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@6fa590ba{/executors/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@2416a51{/executors,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@293bb8a5{/environment/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@37ebc9d8{/environment,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@5217f3d0{/storage/rdd/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@32232e55{/storage/rdd,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@54361a9{/storage/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@549621f3{/storage,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@332a7fce{/stages/pool/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@3c9168dc{/stages/pool,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@72f46e16{/stages/stage/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@4985cbcb{/stages/stage,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@71104a4{/stages/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@5af28b27{/stages,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@4a3e3e8b{/jobs/job/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@7876d598{/jobs/job,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@15a902e7{/jobs/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@5118388b{/jobs,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO ui.SparkUI: Stopped Spark web UI athttp://192.168.27.143:4040
17/05/16 14:26:34 INFO spark.MapOutputTrackerMasterEndpoint:MapOutputTrackerMasterEndpoint stopped!
17/05/16 14:26:34 INFO memory.MemoryStore: MemoryStore cleared
17/05/16 14:26:34 INFO storage.BlockManager: BlockManager stopped
17/05/16 14:26:34 INFO storage.BlockManagerMaster: BlockManagerMasterstopped
17/05/16 14:26:34 INFOscheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint:OutputCommitCoordinator stopped!
17/05/16 14:26:34 INFO spark.SparkContext: Successfully stoppedSparkContext
17/05/16 14:26:34 INFO util.ShutdownHookManager: Shutdown hookcalled
17/05/16 14:26:34 INFO util.ShutdownHookManager: Deleting directory/tmp/spark-702c8654-489f-47f2-85e0-8b658ebb2988
[root@hserver1 spark-2.1.1-bin-hadoop2.7]#Note: The above is just using single-machine local mode to call Demo and cluster mode to run Demo. Please refer to this blog.
http://blog.csdn.net/pucao_cug/article/details/72453382