"Everything is a file", a concept heard just after contacting Linux, embodies the design philosophy of Linux, abstracts all software and hardware resources into files, enables users to operate almost all system resources with the same api, brings great convenience to application development, and also makes a unified interface framework for the implementation of the underlying driver. The concept of "file" has been redefined in Linux. It is not only a piece of data on the disk, but also an entry to interact with the system. In Linux, the file system is responsible for organizing and managing these files, and it also needs to provide various interfaces for file operation. Its concept is no longer just a way to organize disk data, but also contains a complex framework and strategy. What is the role of "file system" in Linux? What features are available? Let's try to comb through this series.
summary
To find out what functions the file system contains in Linux, my idea is to start directly from the source code and see what codes are in the fs / directory. Since the kernel designer must have a reason to classify these functions as fs, I sort out the following general structure:
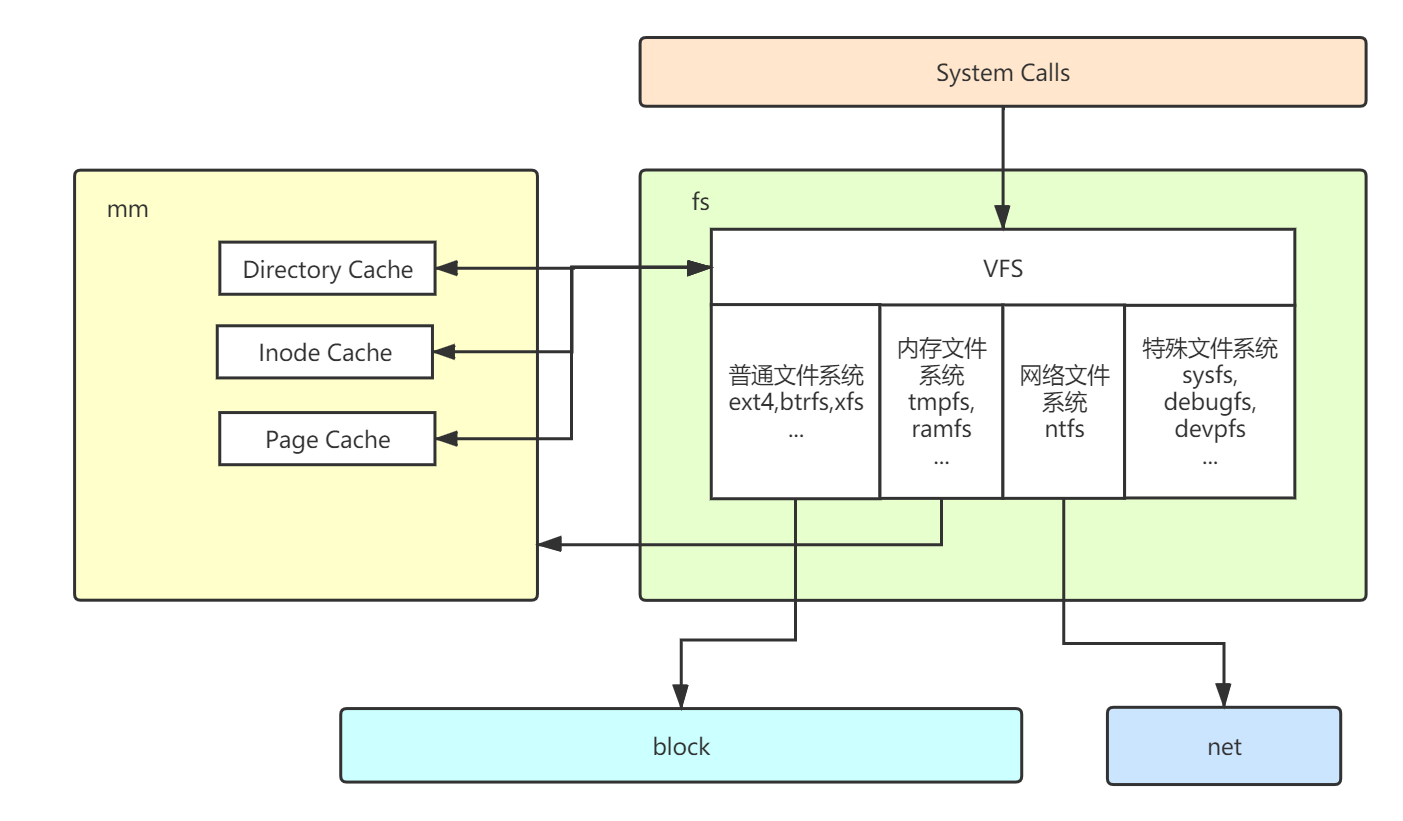
Most of the code in fs / is about IO mode, which is not included in the figure. Summarize the functions of the file system in Linux, which are mainly divided into four parts. This series is also discussed according to this:
- vfs: the abstraction and interaction of various components in the file system, and what operations are provided.
- fs implementation: what type of file system Linux supports and what interfaces a file system needs to implement.
- Cache: how to manage cache with memory subsystem to improve IO performance.
- IO mode: which IO modes are provided according to the different IO requirements of the application.
VFS
The advantage of Linux file system lies in its strong scalability and compatibility. The file system driver is integrated in the kernel in the form of modules, which makes the maintenance and expansion of each file system very convenient. When the system is running, Linux makes a variety of file systems coexist harmoniously. Users can freely mount different disks or partitions anywhere in the directory tree. After that, users can use the unified interface to operate each file system transparently without considering the underlying differences. In order to achieve this effect, VFS plays a key role. The VFS layer uses the object-oriented design method to abstract the file system, so that any file system can be described with fixed objects. The file system driver implements relevant methods according to the VFS framework. When the user operates, VFS uses different methods to complete the underlying processing according to the type of file system.
Four main objects of VFS
super_block
Describes a mounted file system, including device name, partition size, block size and other basic data, superblock method set, inode list, etc. Superblock contains a lot of information, which corresponds to the actual data on the disk. It is often referenced by the internal and external interfaces as an input parameter, and its updates will be synchronized to the disk in time.
struct super_block {
struct list_head s_list; /* Keep this first */ //sb list pointer
...
struct file_system_type *s_type; //File system class
const struct super_operations *s_op; //sb method set
...
struct dentry *s_root; //Root dentry
...
struct hlist_node s_instances; //In S_ type->fs_ Index nodes in the super linked list
...
/*
* Keep s_fs_info, s_time_gran, s_fsnotify_mask, and
* s_fsnotify_marks together for cache efficiency. They are frequently
* accessed and rarely modified.
*/
void *s_fs_info; /* Filesystem private info */ //Each file system contains different information, which is reserved for the driver to save data
...
/*
* The list_lru structure is essentially just a pointer to a table
* of per-node lru lists, each of which has its own spinlock.
* There is no need to put them into separate cachelines.
*/
struct list_lru s_dentry_lru; //dentry lru inode
struct list_lru s_inode_lru; //inode lru inode
...
/* s_inode_list_lock protects s_inodes */
spinlock_t s_inode_list_lock ____cacheline_aligned_in_smp;
struct list_head s_inodes; /* all inodes */ //All inode lists contained
...
}The implementation of superblock is mainly to allocate, update, release, delete and process the data of the inode object.
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb); //Assign inode objects
void (*destroy_inode)(struct inode *); //Release inode object
void (*free_inode)(struct inode *);
void (*dirty_inode) (struct inode *, int flags); //Identify the inode as "dirty", and then update the inode data on the disk
int (*write_inode) (struct inode *, struct writeback_control *wbc); //Update inode data
int (*drop_inode) (struct inode *); //Called when the last user releases the inode
void (*evict_inode) (struct inode *);
void (*put_super) (struct super_block *); //Release superblock, called when unmount
int (*sync_fs)(struct super_block *sb, int wait); //superblock update all "dirty" data to disk
...
}inode
Describe a file (including ordinary file, directory, FIFO, etc.), including file type, size, update time and other data. The information contained in the inode method set also corresponds to the data on the disk and needs to be synchronized in time.
struct inode {
umode_t i_mode; //File type (normal file, directory, fifo...)
...
const struct inode_operations *i_op; //inode method set
struct super_block *i_sb; //superblock
struct address_space *i_mapping; //Mapping address in pagecache
...
//Basic data
dev_t i_rdev;
loff_t i_size;
struct timespec64 i_atime;
struct timespec64 i_mtime;
struct timespec64 i_ctime;
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
unsigned short i_bytes;
...
}The methods of inode implementation are mainly used to find, create and delete inodes. The difference between superblock and superblock is that superblock focuses on managing inode resources, inode focuses on managing the relationship between inode and inode, inode and dentry.
In linux, the definition of "file" is enlarged, including seven types of ordinary files, directories, fifo, etc. the method set of different types of inodes is also different. Generally, the underlying file system driver will install the corresponding method set for different types of inodes. For example, the common file inode method set in ext4 is ext4_file_inode_operations, and the directory inode method set is ext4_dir_inode_operations.
struct inode_operations {
struct dentry * (*lookup) (struct inode *,struct dentry *, unsigned int); //Find the child inode of the current inode (directory) according to dentry
...
int (*create) (struct inode *,struct dentry *, umode_t, bool); //Create a child inode under the current inode (directory)
int (*link) (struct dentry *,struct inode *,struct dentry *); //Create a hard connection with dentry and execute the inode pointed to by the given dentry
int (*unlink) (struct inode *,struct dentry *); //Remove the hard connection from dentry to inode
int (*symlink) (struct inode *,struct dentry *,const char *);
int (*mkdir) (struct inode *,struct dentry *,umode_t); //Create a child inode under the current inode (directory)
int (*rmdir) (struct inode *,struct dentry *); //Delete dentry to point to inode (directory)
int (*mknod) (struct inode *,struct dentry *,umode_t,dev_t); //Create a child inode (disk index node) under the current inode (directory)
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *, unsigned int); //Move the inode pointed by dentry under the current inode (directory) to the new inode (directory), and the new file name is specified by the new dentry
...
}dentry
Describes a node in the system directory tree, usually points to an inode. Its main information includes the parent-child dentry of the dentry, the file name, the inode pointed to, the dentry method set, etc. the main function of dentry is to record the location of an inode in the directory tree. Dentry structure is stored in memory dcache, but there is no directly related data in disk.
dentry is translated into directory item, which needs to be distinguished from directory, for example, a path "/ var/log/txt.log ”, which contains 4 directory entries' / ', "var", "log"“ txt.log ", the first three directory entries point to the directory inode, and the last one points to the normal file inode.
struct dentry {
...
struct dentry *d_parent; /* parent directory */ //Parent dentry
struct qstr d_name; //file name
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */ //inode to
...
const struct dentry_operations *d_op; //dentry method set
struct super_block *d_sb; /* The root of the dentry tree */ //superblock
unsigned long d_time; /* used by d_revalidate */
...
struct list_head d_child; /* child of parent list */ //Its d_ parent->d_ Index nodes in subdirs linked list
struct list_head d_subdirs; /* our children */ //Child dentry list
...
}The implementation of dentry is to initialize, compare, verify and delete the dentry structure. Because dentry is usually only maintained in memory, the underlying file system driver often does not need to implement all methods, and the system has a default processing flow.
struct dentry_operations {
int (*d_revalidate)(struct dentry *, unsigned int); //Judge whether the dentry is still valid
int (*d_weak_revalidate)(struct dentry *, unsigned int);
int (*d_hash)(const struct dentry *, struct qstr *); //Generate the hash value of dentry
int (*d_compare)(const struct dentry *,
unsigned int, const char *, const struct qstr *); //Compare two dentry filenames
...
}
file
Describes a file opened by a process, which is created when it is opened. The main information is the collection of file methods and the offset of the current file. For a file, its inode object is unique, and a file can be opened by multiple processes, and its file object can have multiple.
struct file {
...
struct path f_path; //File path
struct inode *f_inode; /* cached value */ //File inode object
const struct file_operations *f_op; //file method collection
...
loff_t f_pos; //File current offset
...
struct address_space *f_mapping; //Address of the file in pagecache
...
}The main method of file implementation is the operation of file content.
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int); //Update file offset
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *); //Reading data
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *); //Write data
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *); //Asynchronous read
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *); //Asynchronous write
...
int (*mmap) (struct file *, struct vm_area_struct *); //File memory mapping
unsigned long mmap_supported_flags;
int (*open) (struct inode *, struct file *); //After the open call creates the file structure, it provides the driver with an interface to implement the initialization process
...
}Other data structures
struct file_system_type
Describes a file system class, which corresponds to a file system driver module. The main information includes the name of the file system, and the most important is the mount function, which initializes the superblock of the file system. The file system driver module loads to initialize the structure and calls register_filesystem() adds it to the global filesystem class chain.
struct file_system_type {
const char *name; //File system name
...
struct dentry *(*mount) (struct file_system_type *, int,
const char *, void *); //What to do when mount is called
...
struct file_system_type * next; //Global file system class list pointer
struct hlist_head fs_supers; //Super block linked list belonging to the file system class
...
}struct mount
Describes a mount point, including its parent mount point, dentry corresponding to the mount point, and root dentry, superblock of the mounted file system. "Mount" is a great feature of linux file system. You can install the root directory of a disk file system on any node of the system directory tree, covering the content of the original file system under that node. When searching for files, if the path passes through the nodes of the installed file system, you need to jump to the installed file system to continue searching. struct mount is the data structure that records the information of these mounted nodes, which is the bridge connecting the two file systems.
The mount structure is managed by hash table and managed by & MNT_ Parent - > MNT and mnt_mountpoint computes the hash, which enables you to find the mount directly according to the current path structure when traversing the path, so as to find the next mounted file system.
struct mount {
struct hlist_node mnt_hash; //Index the hash node of the mount structure to & MNT_ Parent - > MNT and mnt_mountpoint calculation hash
struct mount *mnt_parent; //Mount to the file system where the mount node is located
struct dentry *mnt_mountpoint; //dentry of the file system where the node is mounted
struct vfsmount mnt; //New mount file system information
...
}struct vfsmount {
struct dentry *mnt_root; /* root of the mounted tree */
struct super_block *mnt_sb; /* pointer to superblock */
int mnt_flags;
}struct path
Describes the path under a file system, which contains the vfsmount structure of its file system and the dentry of the current node.
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
}struct address_space
Describes a part of page in pagecache, which is used to cache data in an inode or block device.
struct address_space {
struct inode *host; //The owner of the cache can be inode or block device
struct xarray i_pages; //Page list (the old version of kernel uses radius tree to manage page)
...
struct rb_root_cached i_mmap; //Organization Address_ rbtree node of space structure
struct rw_semaphore i_mmap_rwsem;
unsigned long nrpages; //How many page s are included
...
const struct address_space_operations *a_ops; //address_space method set
...
}address_ The implementation of space mainly includes data reading and writing between memory page and storage device, as well as providing hook interface for file system driver during operation.
struct address_space_operations {
int (*writepage)(struct page *page, struct writeback_control *wbc); //Write a page data to disk
int (*readpage)(struct file *, struct page *); //Read a page from disk
/* Write back some dirty pages from this mapping. */
int (*writepages)(struct address_space *, struct writeback_control *); //Write multiple page data to disk
/* Set a page dirty. Return true if this dirtied it */
int (*set_page_dirty)(struct page *page); //Identify a page as "dirty"
/*
* Reads in the requested pages. Unlike ->readpage(), this is
* PURELY used for read-ahead!.
*/
int (*readpages)(struct file *filp, struct address_space *mapping,
struct list_head *pages, unsigned nr_pages); //Read multiple page s from disk for read ahead only
...
ssize_t (*direct_IO)(struct kiocb *, struct iov_iter *iter); //directIO, bypassing pagecache to read and write between the address provided by the user and the disk
...
}Interaction relationship
The file system needs to match the directory tree of the system with the actual files on the disk, and provide access methods. An example is given to illustrate the interaction between objects. Suppose that the following file system of a system is in ext4 format. Mount a disk of fat format in / media/sda. Now read and write the 1.log file under the root directory of the fat disk, that is, directly read and write the "/ media/sda/1.log" file in the system.
First, see how to find the inode of the file in the fat disk according to the path. The structure chart is as follows:
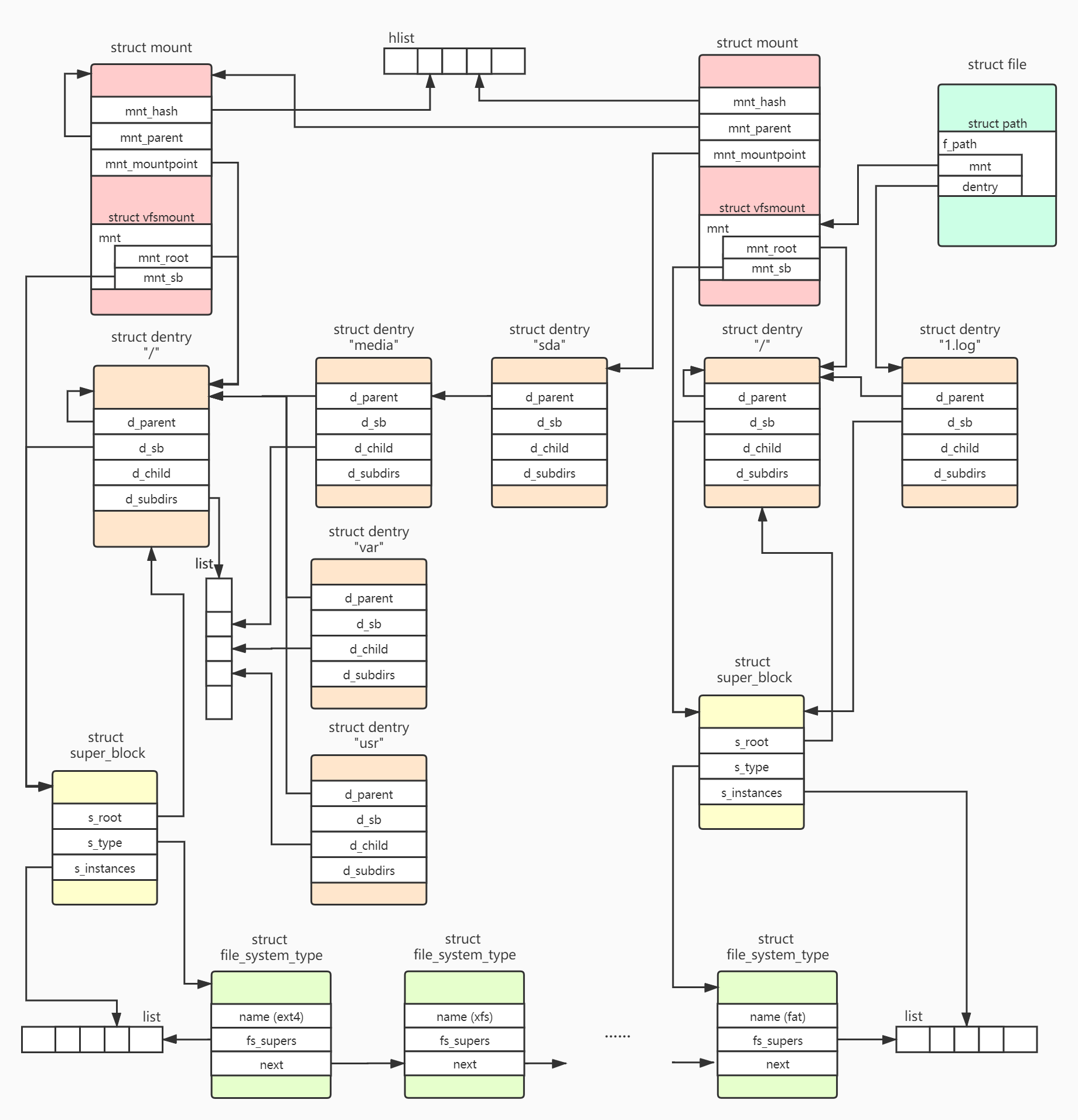
After the system is started, all file system drivers are loaded_ system_ The type structure is created and added to the global list management.
After the file system is mounted, super_block, mount, and root dentry structures are created and set up to relate to each other.
Execute open("/media/sda/1.log") and start to search dentry item by item from the system root directory "/". The search strategy is to search from the cache first. If not, create a new dentry and associate it with the inode of the corresponding file on the file system. When traversing the "sda" of the root file system, it is found that the dentry is a mount point (dentry - > d_ Flags are marked with DCache_ Mount), find the mount of the fat disk according to the current path, change the next found dentry to the root dentry of the fat, complete the jump between different file systems, finally find the "1.log"dentry, establish the connection with the file, and open the end to return.
After finding the dentry and inode of the target file, let's see how to read and write. The structure chart is as follows:
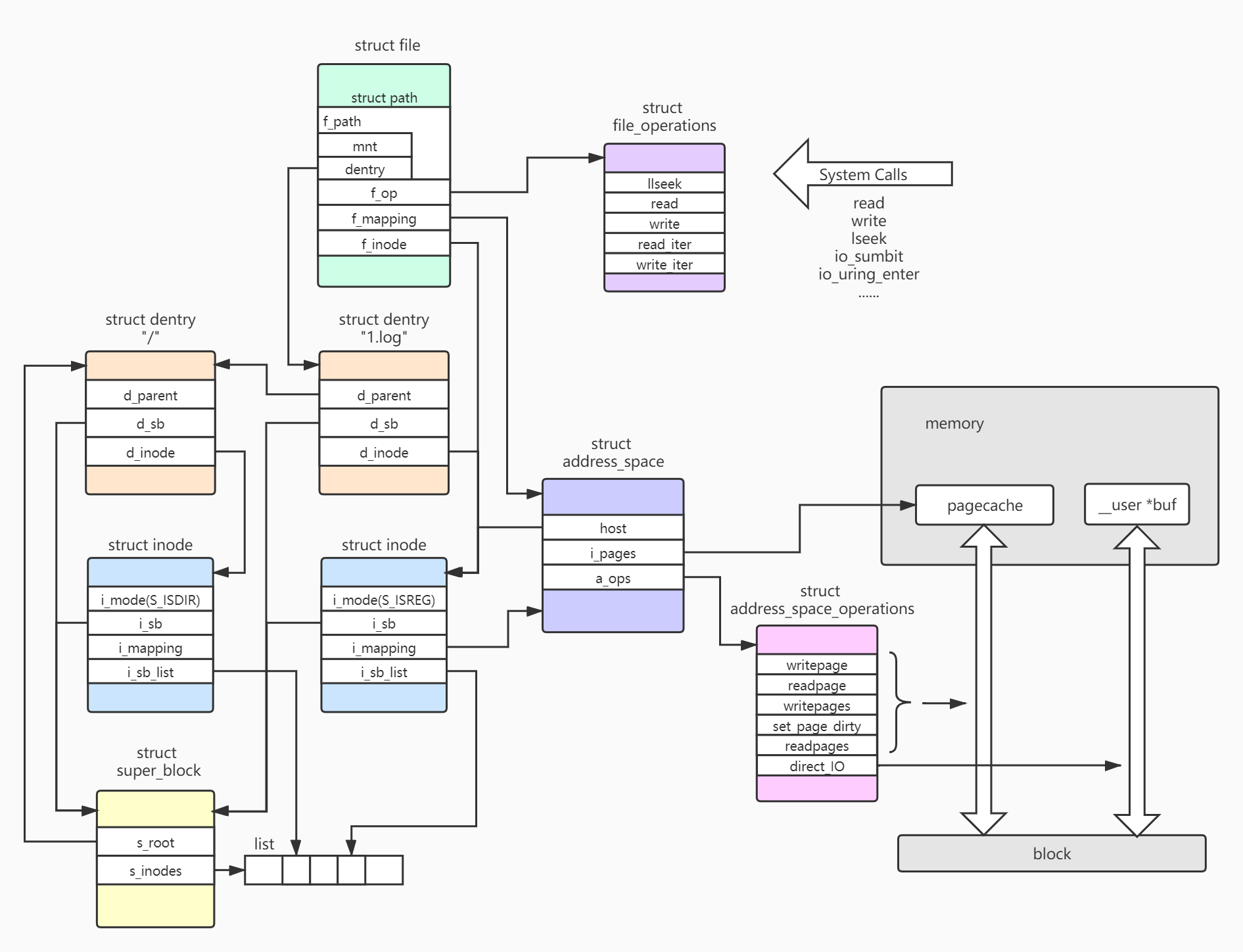
The system call reads and writes the file through the file structure. The file holds the inode of the corresponding file and its mapped address in pagecache_ space. The read-write process is mainly through file_operations, and address_space_ The two interfaces of operations are completed. file_operations is a set of upper interface, which is provided for system calls and internal modules to implement various IO models and other kernel functions requiring IO operations. address_space_operations is responsible for reading and writing data between the disk and memory, converting file operations to disk IO and sending it to the block layer. The memory side is usually pagecache, if O is specified_ Direct mode can also be the memory address provided by the application.
For example, for the last ordinary buffer IO read in ext4, the data on the disk will be read into the memory pagecache first, and then the data in the pagecache will be copied to the user buf. The approximate path is: the system calls read() - > file_ operations.read_ iter() -> generic_ file_ buffered_ read() -> address_ space_ operations.readpage () -> copy_page_to_iter()
summary
VFS associates the directory tree of the system with the files on the disk, and defines the methods to support each object in the file system. It makes writing the file system driver do not need to pay too much attention to how to use the system, just need to implement according to the interface. The upper system calls and kernel modules using file IO do not need to pay attention to the underlying implementation, but can only focus on the specific read-write logic. It can be said that VFS plays a key role in the Linux file system.
This article mainly talks about how VFS abstracts the file system and the relationship and interface of each object, and what is under these abstractions and interfaces? The next part is about the implementation of file system driver.