Overview of Linux Cluster
According to the function, it can be divided into two categories: high availability and load balancing.
High availability clusters usually consist of two servers, one working and the other serving as redundancy. When the serving machine goes down, redundancy will take over and continue to serve.
Open source software for high availability includes heartbeat, keepalived
Load balancing cluster needs a server as distributor, which is responsible for distributing users'requests to the back-end server for processing. In this cluster, besides distributor, it is the server that provides services to users. The number of these servers is at least 2.
Open source software for load balancing includes LVS, keepalived, haproxy, nginx, and commercial F5, Netscaler.
Introduction to keepalived
Here we use keepalived to implement high availability cluster, because heartbeat has some problems on centos6, which affect the experimental results.
keepalived achieves high availability through VRRP (Virtual Router Redundancy Protocl).
In this protocol, multiple routers with the same function will be organized into a group, in which there will be a master role and N (N > = 1) backup role.
Master will send VRRP packets to each backup in the form of multicast. When the backup can't receive VRRP packets from the master, it will think that the master is down. At this point, we need to decide who will become the new mater according to the priority of each backup.
Keepalived has three modules: core, check and vrrp. The core module is the core of keeping alived. It is responsible for the initiation, maintenance of the main process and loading and parsing of the global configuration file. The check module is responsible for the health check. The VRRP module is used to implement the VRRP protocol.
Configuring high availability with keepalived
Prepare two machines 130 and 131, 130 as master and 131 as backup.
Both machines execute Yum install-y keepalived
Both machines have nginx installed, of which 130 has been compiled and installed nginx, 131 needs yum to install nginx: yum install-y nginx
master configuration:
Set vip to 100
Edit the keepalived configuration file on 130, >/etc/keepalived/keepalived.conf clears the original configuration file.
vim /etc/keepalived/keepalived.conf
global_defs { notification_email { cc@cclinux.com } notification_email_from root@cclinux.com smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id LVS_DEVEL } vrrp_script chk_nginx { script "/usr/local/sbin/check_ng.sh" interval 3 } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass cclinux>com } virtual_ipaddress { 192.168.109.100 } track_script { chk_nginx } }
130 Edit Monitoring Script
vim /usr/local/sbin/check_ng.sh
#!/bin/bash #Time variable for logging d=`date --date today +%Y%m%d_%H:%M:%S` #Calculate the number of nginx processes n=`ps -C nginx --no-heading|wc -l` #If the process is 0, start nginx and detect the number of nginx processes again. #If it's still 0, it means that nginx can't start, and you need to turn off keepalived if [ $n -eq "0" ]; then /etc/init.d/nginx start n2=`ps -C nginx --no-heading|wc -l` if [ $n2 -eq "0" ]; then echo "$d nginx down,keepalived will stop" >> /var/log/check_ng.log systemctl stop keepalived fi fi
Give scripts 755 privileges
chomd 755 /usr/local/sbin/check_ng.sh
System CTL start keepalived //130 start service

backup configuration:
Edit configuration file on 131
vim /etc/keepalived/keepalived.conf
global_defs { notification_email { cc@cclinux.com } notification_email_from root@cclinux.com smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id LVS_DEVEL } vrrp_script chk_nginx { script "/usr/local/sbin/check_ng.sh" interval 3 } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 51 priority 90 advert_int 1 authentication { auth_type PASS auth_pass cclinux>com } virtual_ipaddress { 192.168.109.100 } track_script { chk_nginx } }
Editing monitoring scripts on 131
vim /usr/local/sbin/check_ng.sh
#Time variable for logging d=`date --date today +%Y%m%d_%H:%M:%S` #Calculate the number of nginx processes n=`ps -C nginx --no-heading|wc -l` #If the process is 0, start nginx and detect the number of nginx processes again. #If it's still 0, it means that nginx can't start, and you need to turn off keepalived if [ $n -eq "0" ]; then systemctl start nginx n2=`ps -C nginx --no-heading|wc -l` if [ $n2 -eq "0" ]; then echo "$d nginx down,keepalived will stop" >> /var/log/check_ng.log systemctl stop keepalived fi fi
Give script 755 privileges
chmod 755 /usr/local/sbin/check_ng.sh
Service is also started on system CTL start keepalived //131

Inspection:
master, after we stopped nginx, nginx restarted as shown in the following figure, indicating that the keepalived configuration was successful
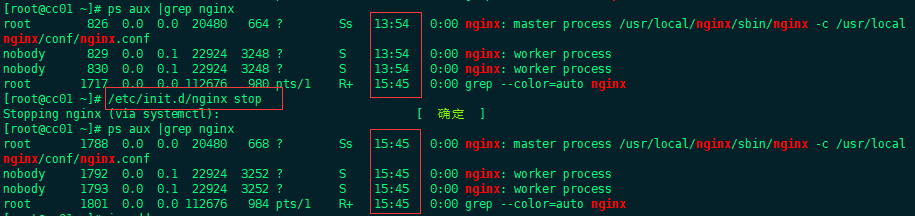
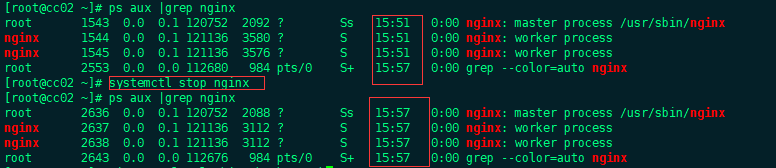
The backup is the same:
Browser testing:
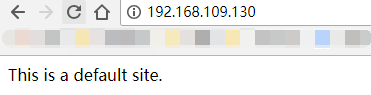
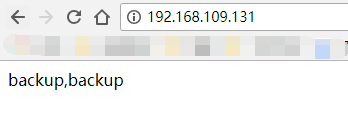
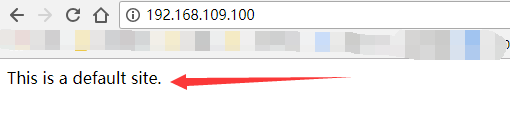
From the above, we can see that our vip100 settings are successful, bound to the master!
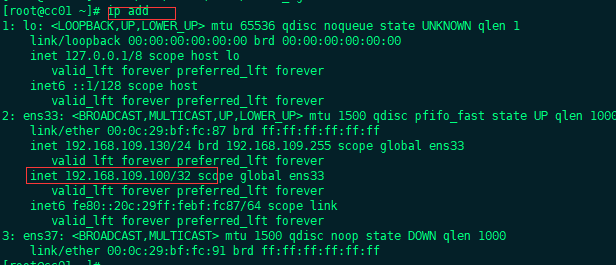
Example 1 tests:
Adding iptabls rules to master
iptables -I OUTPUT -p vrrp -j DROP
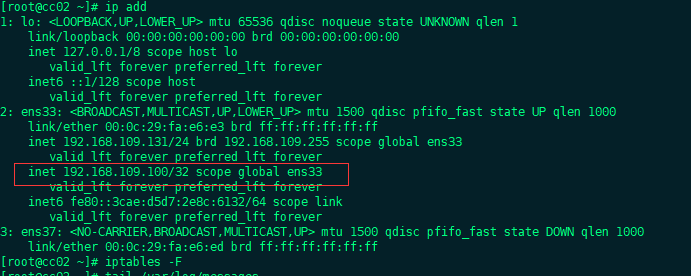
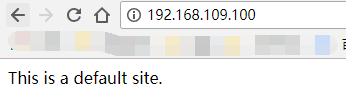
As shown above, although there are 100 above, vip is still on master, so this is not feasible.
Example 2 tests:
Stop the master's keepalived service
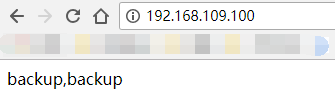
We can see that vip switched to 131 server immediately.
But when we restart the keepalived 130, vip will immediately return to our 130 machine:
The log will show immediately:
