LinkedHashMap learning
brief introduction
LinkedHashMap is an extension of HashMap. It rewrites the Node class of HashMap and maintains a two-way linked list to ensure the insertion order of elements. It can be used to implement LRU cache policy. LinkedHashMap has all the features of HashMap.
attribute
LinkedHashMap inherits from HashMap and has all its features. And added some properties
//Bidirectional chain header node. The old node is saved in the header node transient LinkedHashMap.Entry<K,V> head; //The tail node of the bidirectional linked list. The new node is saved in the tail node transient LinkedHashMap.Entry<K,V> tail; // Whether to sort by access order. If false, the elements are stored in the insertion order. Otherwise, the elements are stored in the access order final boolean accessOrder;
Entry inner class
LinkedHashMap rewrites the Node internal class of HashMap and adds two attributes before and after to record the head Node and tail Node.
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after; //Used to record the previous node and the next node of the current node.
//Call the construction method of the Node of the HashMap
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
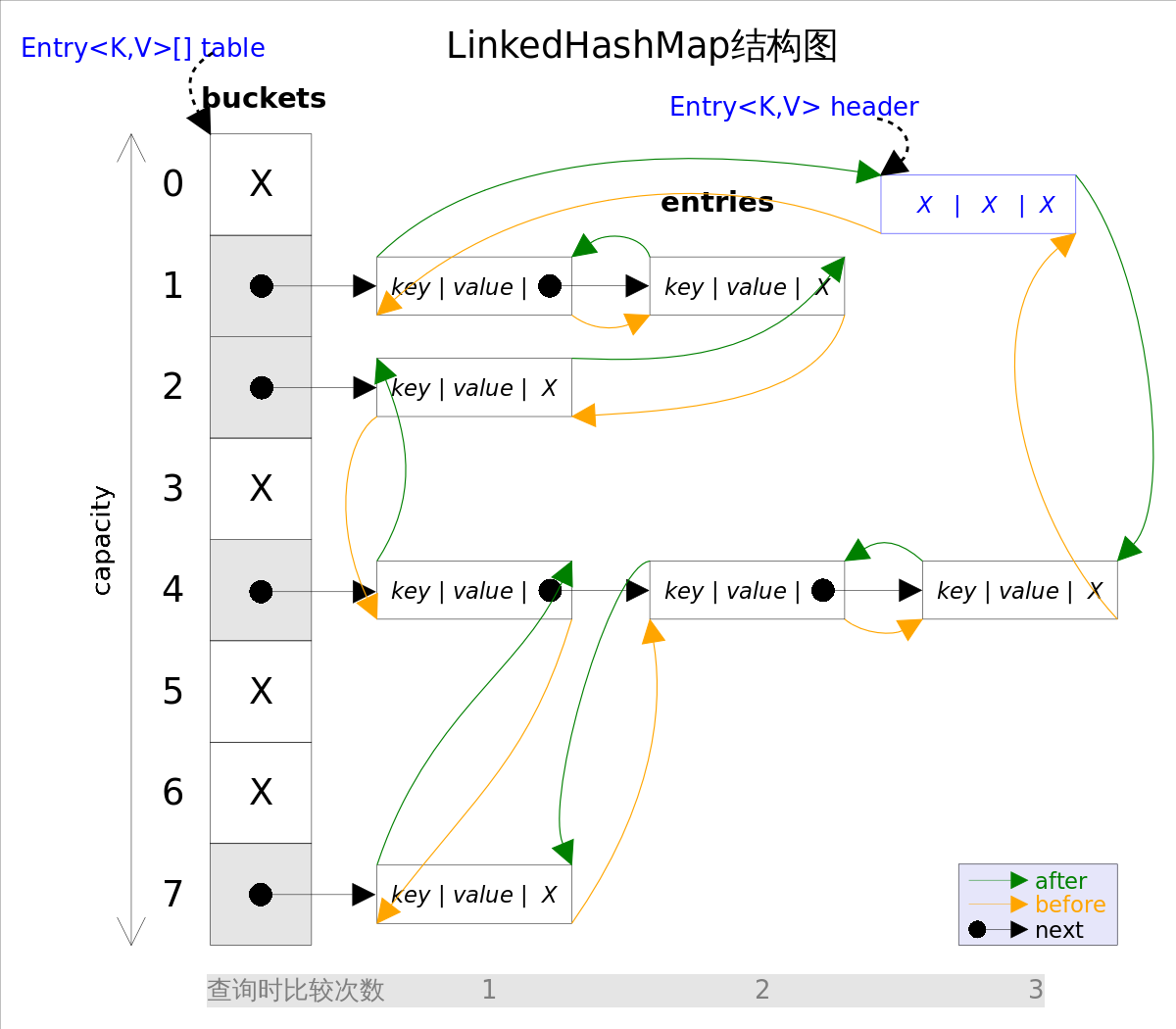
The structure of each node of LinkedHashMap includes the hash, key, value, next (used to point to the next node in the linked list with the same hash) defined by the HashMap and the new before and after nodes (these two attributes are used to ensure the insertion order or access order. The hash values of before and after nodes are not necessarily equal, but the hash of next must be equal). Specific data result chart
Constructor
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
The first four constructors accessOrder is equal to false by default, indicating that the bidirectional linked list stores elements in insertion order.
The last constructor accessOrder is determined by the parameter. If true, it is stored in the access order (the key to implementing the LRU cache strategy), and if false, it is stored in the insertion order.
LinkedHashMap mainly analyzes how java implements sequential storage and access storage according to accessOrder.
Add element
LinkedHashMap inherits from HashMap. Add elements to refer to another article HashMap source code learning , it has its own method to generate new nodes
//Click to view the call of this method, all of which are called by HashMap. Called when a new element is added to the HashMap.
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
//Maintain two-way linked list head and tail.
linkNodeLast(p);
return p;
}
//Generate tree node
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p);
return p;
}
//Maintain a two-way linked list and link according to the insertion order.
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
//Looking at the source code of HashMap, you will find that this method will be called when inserting elements, but HashMap is an empty implementation. LinkedHashMap implements
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
//Determine whether to remove the oldest element according to evict and whether the header node is empty.
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
//Remove the head node.
removeNode(hash(key), key, null, false, true);
}
}
//The oldest element is not removed by default
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
removeNode implementation
After adding an element, you will judge whether to delete the oldest element. LinkedHashMap implements the afterNodeRemoval method.
//Simple linked list bidirectional linked list node deletion.
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
Access element get(key)
LinkedHashMap ensures the order of inserting elements and deletes the oldest node (implements LRU algorithm). How does LinkedHashMap store data in access order? How accessOrder is done.
//Access the data according to the key value, and implement the analysis according to HashMap. LinkedHashMap has one more layer of logic
//When accessOrder is true, afterNodeAccess (e);
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return defaultValue;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
//When accessOrder is true, move the current node to the end of the bidirectional linked list.
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
//Only the current node is not the tail node
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
Implement LRU algorithm
According to the source code analysis, the oldest data will not be removed when adding elements to the LinkedHashMap. To implement it, you need to rewrite the removeEldestEntry() method. You need to consider the expansion of the HashMap (the removal is executed after the expansion), which can be implemented simply
class LRUHashMap<K, V> extends LinkedHashMap<K, V> {
// Save cache capacity
private int capacity;
public LRU(int capacity) {
super(capacity, 0.75f, true);
this.capacity = capacity;
}
/**
* Override the removeEldestEntry() method to set when to remove old elements
* @param eldest
* @return
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// When the number of elements exceeds the capacity of the cache, the elements are removed
return size() > this.capacity;
}
}
summary
- The implementation of LinkedHashMap is relatively simple. It is LinkedList+HashMap. It has the characteristics of HashMap and maintains the storage order or access order of two-way linked list. The old data exists in the front, and the new data is inserted at the end.
- The implementation of LinkedHashMap almost implements the empty method not implemented by HashMap, the hook method of HashMap and the method of reusing HashMap. This way that the parent class exposes the implementation of hook function subclasses can be implemented in subsequent development.
- LinkedHashMap can be used to implement LRU elimination strategy.
- LinkedHashMap points to realize element storage / access before and after node addition, and trades space for time.