5.Spring Data Elasticsearch
The Java client provided by Elasticsearch has some inconveniences:
- There are many places where you need to stitch Json strings. How horrible it is to stitch strings in java you should understand
- You need to serialize objects into json storage yourself
- Query results also need to be deserialized into objects
Therefore, we won't talk about the native Elastic search client API here.
Instead, learn the suite Spring provides: Spring Data Elastic search
5.1. introduction
Spring Data Elastic search is a sub-module under the Spring Data project.
View Spring Data's official website: http://projects.spring.io/spring-data/
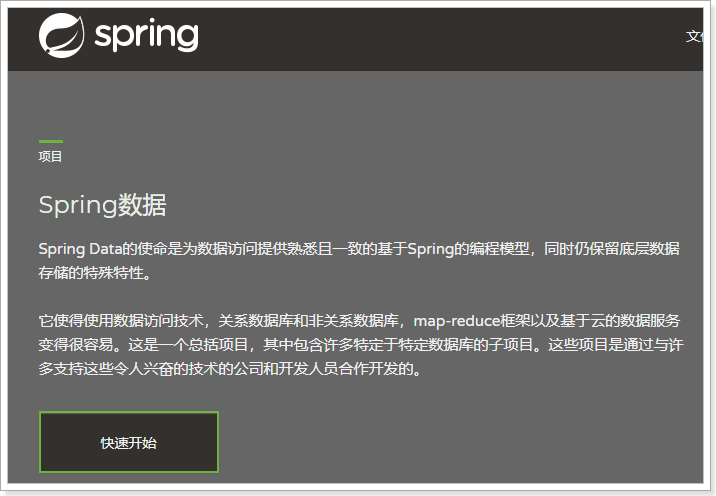
Spring Data's mission is to provide a unified programming interface for all kinds of data access, whether it's relational databases (MySQL), non-relational databases (Redis), or index databases like Elastic search. So it can simplify the developer's code and improve the efficiency of development.
Modules that contain many different data operations:

Spring Data Elastic search page: https://projects.spring.io/spring-data-elasticsearch/

Features:
- Spring-enabled @Configuration-based java configuration, or XML configuration
- A convenient tool class ** Elastic search Template ** for operating ES is provided. It includes automatic intelligent mapping between document and POJO.
- Functionally Rich Object Mapping Using Spring's Data Conversion Service
- Annotation-based metadata mapping approach, and can be extended to support more different data formats
- According to the persistence layer interface, the corresponding implementation method can be automatically generated without manual writing basic operation code (similar to mybatis, which can be realized automatically according to the interface). Of course, manual customized queries are also supported
5.2. Creating Demo Project
Let's build a new demo and learn Elastic search.
pom dependence:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.leyou.demo</groupId> <artifactId>elasticsearch</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>elasticsearch</name> <description>Demo project for Spring Boot</description> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.0.2.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>
application.yml file configuration:
spring: data: elasticsearch: cluster-name: elasticsearch cluster-nodes: 192.168.56.101:9300
5.3. Index operation
5.3.1. Creating Index and Mapping
Entity class
First we prepare the entity class:
public class Item { Long id; String title; //Title String category;// classification String brand; // brand Double price; // Price String images; // Picture address }
mapping
Spring Data declares mapping properties of fields through annotations, with the following three annotations:
-
@ Document acts on classes, marking entity classes as document objects, usually with two attributes
- indexName: corresponding index library name
- Type: Type corresponding to the type in the index library
- shards: Number of fragments, default 5
- replicas: number of copies, default 1
- @ id acts on member variables, marking a field as the id primary key
-
@ Field acts on member variables, labels them as fields of documents, and specifies field mapping properties:
- Type: Field type, is an enumeration: FieldType
- index: Indexed or not, Boolean type, default is true
- Store: Whether to store, Boolean type, default is false
- analyzer: participler name
Example:
@Document(indexName = "item",type = "docs", shards = 1, replicas = 0) public class Item { @Id private Long id; @Field(type = FieldType.Text, analyzer = "ik_max_word") private String title; //Title @Field(type = FieldType.Keyword) private String category;// classification @Field(type = FieldType.Keyword) private String brand; // brand @Field(type = FieldType.Double) private Double price; // Price @Field(index = false, type = FieldType.Keyword) private String images; // Picture address }
Create index
An API to create an index is provided in Elastic search Template:
@Test public void testCreate(){ //Creating Index Library elasticsearchTemplate.createIndex(Item.class); }
- It can be automatically generated based on class information, or indexName and Settings can be specified manually.
mapping
Mapping related API s:
@Test public void testCreate(){ //Create index Libraries elasticsearchTemplate.createIndex(Item.class); //Mapping relation elasticsearchTemplate.putMapping(Item.class); }
- Similarly, a mapping can be generated based on the bytecode information (annotation configuration) of the class, or it can be written manually.
We use the bytecode information of the class to create the index and map:
@Test public void createIndex() { // Create an index based on the @Document annotation information of the Item class esTemplate.createIndex(Item.class); // Configuration mapping, which automatically completes mapping based on fields such as id, Field in the Item class esTemplate.putMapping(Item.class); }
Result:
GET /item { "item": { "aliases": {}, "mappings": { "docs": { "properties": { "brand": { "type": "keyword" }, "category": { "type": "keyword" }, "images": { "type": "keyword", "index": false }, "price": { "type": "double" }, "title": { "type": "text", "analyzer": "ik_max_word" } } } }, "settings": { "index": { "refresh_interval": "1s", "number_of_shards": "1", "provided_name": "item", "creation_date": "1525405022589", "store": { "type": "fs" }, "number_of_replicas": "0", "uuid": "4sE9SAw3Sqq1aAPz5F6OEg", "version": { "created": "6020499" } } } } }
5.3.2. Delete Index
Delete the API of the index:
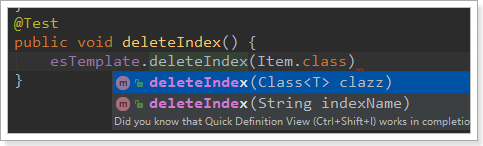
You can delete them based on the class name or index name.
Example:
@Test public void deleteIndex() { esTemplate.deleteIndex("heima"); }
5.4. Adding Document Data
5.4.1.Repository interface
The power of Spring Data is that you don't have to write any DAO processing to automatically CRUD operations based on method names or class information. As long as you define an interface and then inherit some of the sub-interfaces provided by Repository, you can have a variety of basic CRUD functions.
Look at Repository's inheritance relationship:
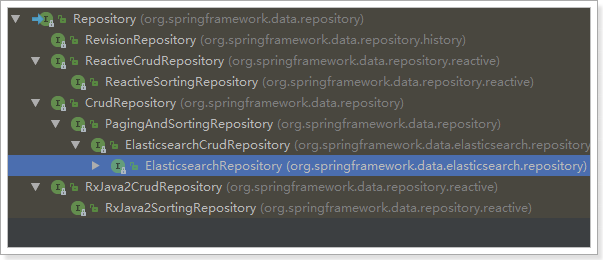
We see an Elastic search CrudRepository interface:
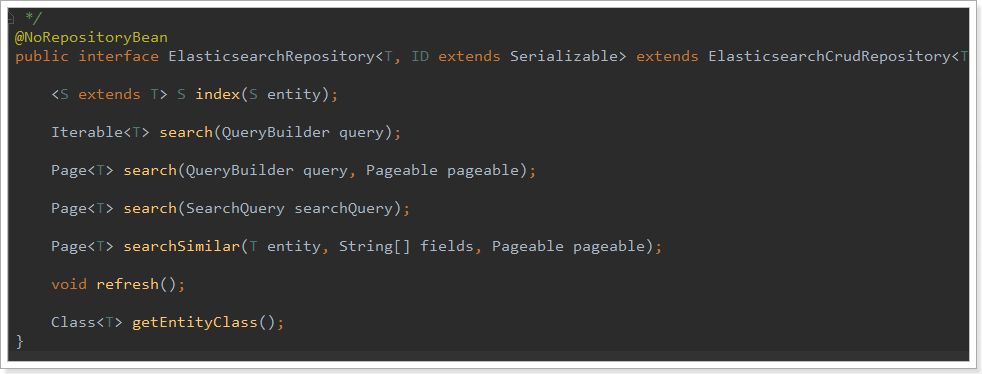
So, we just need to define the interface and inherit it to OK.
public interface ItemRepository extends ElasticsearchRepository<Item,Long> { }
Next, we test the new data:
5.4.2. Add a new object
@Autowired private ItemRepository itemRepository; @Test public void index() { Item item = new Item(1L, "Millet Mobile 7", " Mobile phone", "millet", 3499.00, "http://image.leyou.com/13123.jpg"); itemRepository.save(item); }
Go to the page and see:
{ "took": 0, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 1, "hits": [ { "_index": "item", "_type": "docs", "_id": "1", "_score": 1, "_source": { "id": 1, "title": "Millet Mobile 7", "category": " Mobile phone", "brand": "millet", "price": 3499, "images": "http://image.leyou.com/13123.jpg" } } } ] } }
5.4.3. New batches
Code:
@Test public void indexList() { List<Item> list = new ArrayList<>(); list.add(new Item(2L, "Nut mobile phone R1", " Mobile phone", "Hammer", 3699.00, "http://image.leyou.com/123.jpg")); list.add(new Item(3L, "HUAWEI META10", " Mobile phone", "HUAWEI", 4499.00, "http://image.leyou.com/3.jpg")); // Receiving Object Set to Realize Batch Addition itemRepository.saveAll(list); }
Go to the page again to query:
{ "took": 5, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 1, "hits": [ { "_index": "item", "_type": "docs", "_id": "2", "_score": 1, "_source": { "id": 2, "title": "Nut mobile phone R1", "category": " Mobile phone", "brand": "Hammer", "price": 3699, "images": "http://image.leyou.com/13123.jpg" } }, { "_index": "item", "_type": "docs", "_id": "3", "_score": 1, "_source": { "id": 3, "title": "HUAWEI META10", "category": " Mobile phone", "brand": "HUAWEI", "price": 4499, "images": "http://image.leyou.com/13123.jpg" } }, { "_index": "item", "_type": "docs", "_id": "1", "_score": 1, "_source": { "id": 1, "title": "Millet Mobile 7", "category": " Mobile phone", "brand": "millet", "price": 3499, "images": "http://image.leyou.com/13123.jpg" } } ] } }
5.4.4. modification
Modifications and additions are the same interface, and the distinction is based on id, which is similar to the way we initiate PUT requests on pages.
5.5. query
5.5.1. Basic queries
Elastic search repository provides some basic query methods:
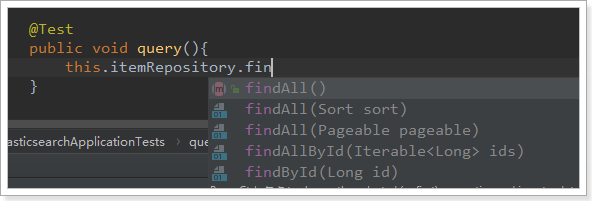
Let's try to query all:
@Test public void query(){ // Query all and install price descending sort Iterable<Item> items = this.itemRepository.findAll(Sort.by("price").descending()); for (Item item : items) { System.out.println("item = " + item); } }
Result:

5.5.2. Customization method
Another powerful feature of Spring Data is the automatic implementation of functions based on method names.
For example, your method is called findByTitle, so it knows that you query according to title, and then automatically help you complete it without writing implementation classes.
Of course, the method name should conform to certain agreements:
| Keyword | Sample | Elasticsearch Query String |
|---|---|---|
| And | findByNameAndPrice | {"bool" : {"must" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
| Or | findByNameOrPrice | {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
| Is | findByName | {"bool" : {"must" : {"field" : {"name" : "?"}}}} |
| Not | findByNameNot | {"bool" : {"must_not" : {"field" : {"name" : "?"}}}} |
| Between | findByPriceBetween | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
| LessThanEqual | findByPriceLessThan | {"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
| GreaterThanEqual | findByPriceGreaterThan | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
| Before | findByPriceBefore | {"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
| After | findByPriceAfter | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
| Like | findByNameLike | {"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
| StartingWith | findByNameStartingWith | {"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
| EndingWith | findByNameEndingWith | {"bool" : {"must" : {"field" : {"name" : {"query" : "*?","analyze_wildcard" : true}}}}} |
| Contains/Containing | findByNameContaining | {"bool" : {"must" : {"field" : {"name" : {"query" : "**?**","analyze_wildcard" : true}}}}} |
| In | findByNameIn(Collection<String>names) | {"bool" : {"must" : {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"name" : "?"}} ]}}}} |
| NotIn | findByNameNotIn(Collection<String>names) | {"bool" : {"must_not" : {"bool" : {"should" : {"field" : {"name" : "?"}}}}}} |
| Near | findByStoreNear | Not Supported Yet ! |
| True | findByAvailableTrue | {"bool" : {"must" : {"field" : {"available" : true}}}} |
| False | findByAvailableFalse | {"bool" : {"must" : {"field" : {"available" : false}}}} |
| OrderBy | findByAvailableTrueOrderByNameDesc | {"sort" : [{ "name" : {"order" : "desc"} }],"bool" : {"must" : {"field" : {"available" : true}}}} |
For example, let's define such a method by querying the price interval:
public interface ItemRepository extends ElasticsearchRepository<Item,Long> { /** * Query according to price interval * @param price1 * @param price2 * @return */ List<Item> findByPriceBetween(double price1, double price2); }
Then add some test data:
@Test public void indexList() { List<Item> list = new ArrayList<>(); list.add(new Item(1L, "Millet Mobile 7", "Mobile phone", "millet", 3299.00, "http://image.leyou.com/13123.jpg")); list.add(new Item(2L, "Nut mobile phone R1", "Mobile phone", "Hammer", 3699.00, "http://image.leyou.com/13123.jpg")); list.add(new Item(3L, "HUAWEI META10", "Mobile phone", "HUAWEI", 4499.00, "http://image.leyou.com/13123.jpg")); list.add(new Item(4L, "millet Mix2S", "Mobile phone", "millet", 4299.00, "http://image.leyou.com/13123.jpg")); list.add(new Item(5L, "glory V10", "Mobile phone", "HUAWEI", 2799.00, "http://image.leyou.com/13123.jpg")); // Receiving Object Set to Realize Batch Addition itemRepository.saveAll(list); }
There is no need to write implementation classes, and then we run them directly:
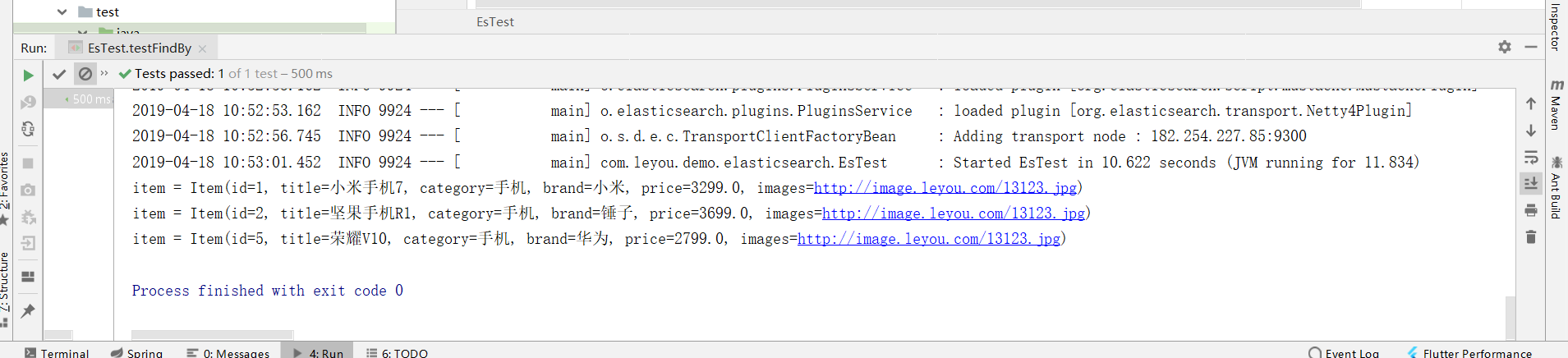
@Test public void testFindBy(){ List<Item> list = itemRepository.findByPriceBetween(2000d, 4000d); for (Item item : list) { System.out.println("item = "+item); } }
Result:
5.5.3. Custom Query
Let's start with the most basic match query:
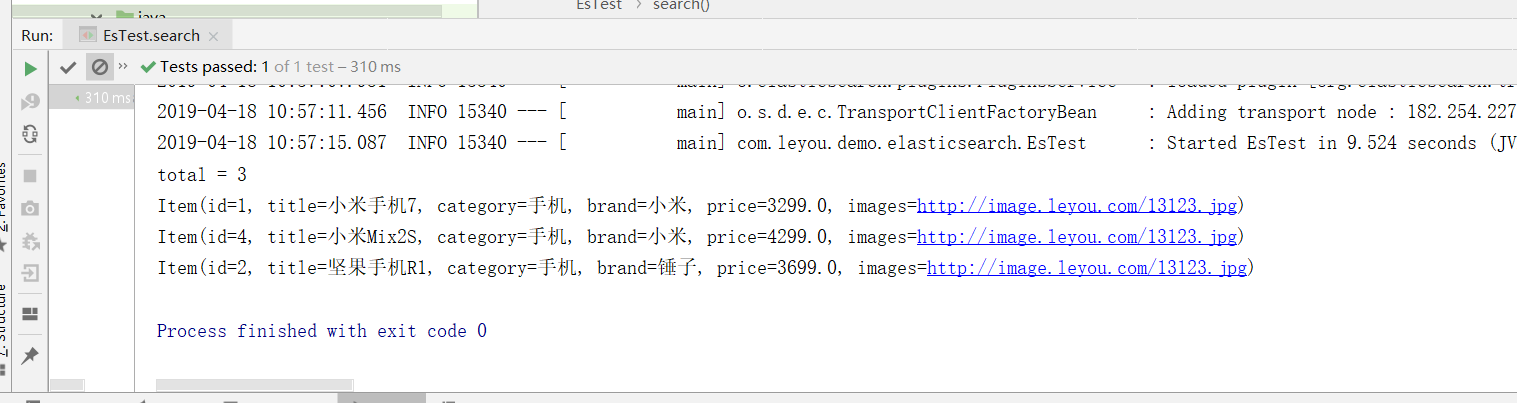
@Test public void search(){ // Constructing Query Conditions NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); // Adding Basic Word Segmentation Query queryBuilder.withQuery(QueryBuilders.matchQuery("title", "Mi phones")); // Search for results Page<Item> items = this.itemRepository.search(queryBuilder.build()); // Total number long total = items.getTotalElements(); System.out.println("total = " + total); for (Item item : items) { System.out.println(item); } }
-
Native SearchQuery Builder: Spring provides a query condition builder to help build json-formatted request bodies
-
QueryBuilders.matchQuery("title", "millet phone"): Use Query Builders to generate a query. Query Builders provides a large number of static methods for generating various types of queries:
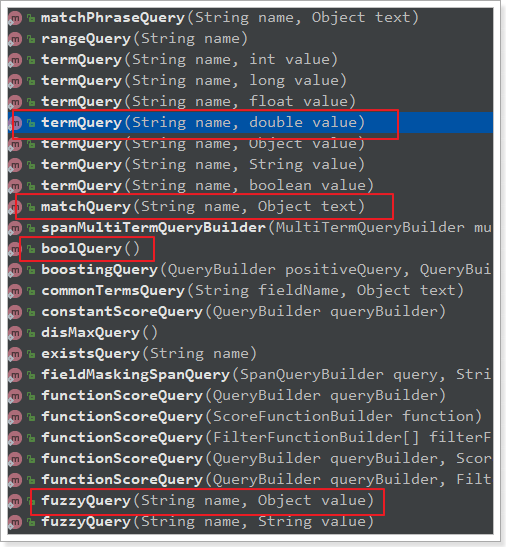
-
Page < item >: By default, it is a paging query, so it returns a paging result object with attributes:
-
TotElements: Total number of items
-
Total Pages: Total Pages
-
Iterator: Iterator, which implements the Iterator interface itself, can iterate directly to get the data of the current page.
-
Other attributes:
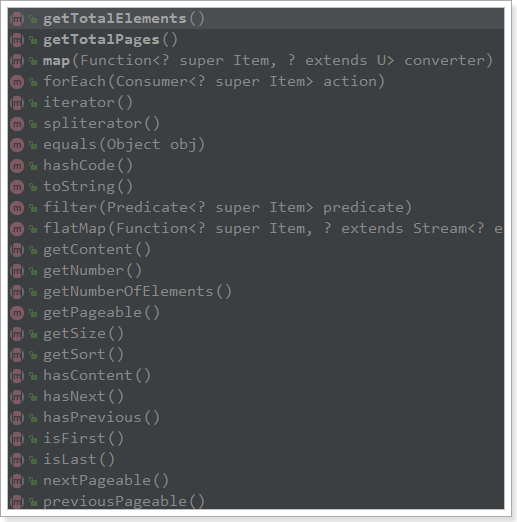
-
Result:
5.5.4. Paging queries
Paging can be easily realized by using Native SearchQuery Builder:
@Test public void searchByPage(){ // Constructing Query Conditions NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); // Adding Basic Word Segmentation Query queryBuilder.withQuery(QueryBuilders.termQuery("category", "Mobile phone")); // Paging: int page = 0; int size = 2; queryBuilder.withPageable(PageRequest.of(page,size)); // Search for results Page<Item> items = this.itemRepository.search(queryBuilder.build()); // Total number long total = items.getTotalElements(); System.out.println("Total number = " + total); // PageCount System.out.println("PageCount = " + items.getTotalPages()); // Current page System.out.println("Current page:" + items.getNumber()); // Size per page System.out.println("Size per page:" + items.getSize()); for (Item item : items) { System.out.println(item); } }
Result:
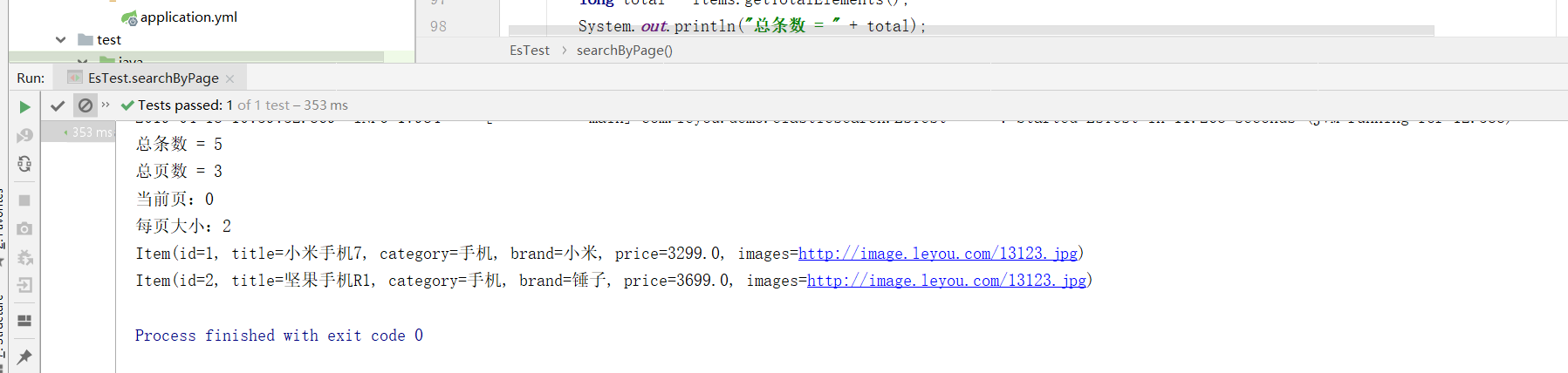
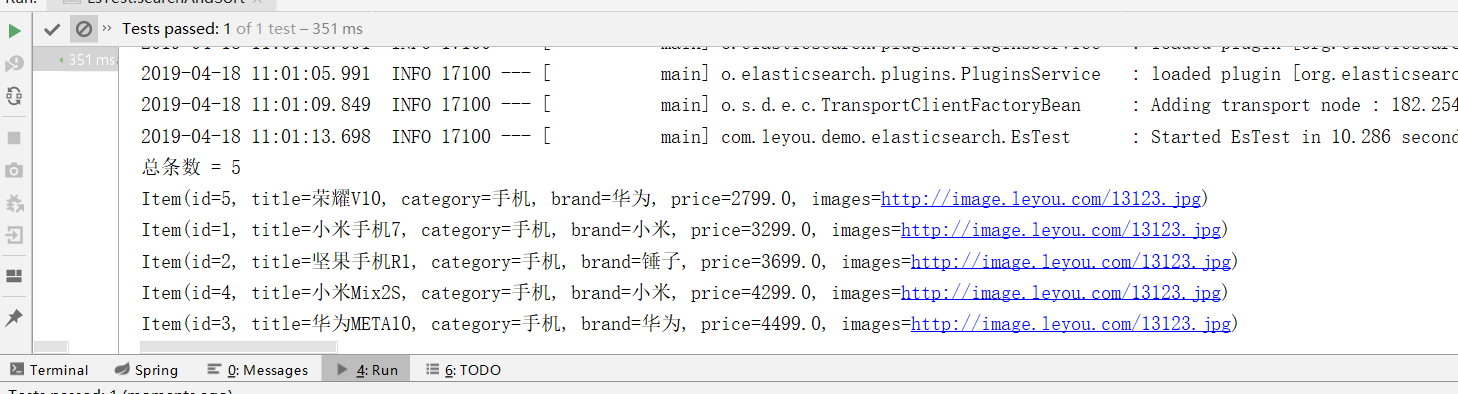
As you can see, the paging in Elastic search starts from page 0.
5.5.5. sorting
Sorting is also commonly done through Native SearchQuery Builder:
@Test public void searchAndSort(){ // Constructing Query Conditions NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); // Adding Basic Word Segmentation Query queryBuilder.withQuery(QueryBuilders.termQuery("category", "Mobile phone")); // sort queryBuilder.withSort(SortBuilders.fieldSort("price").order(SortOrder.ASC)); // Search for results Page<Item> items = this.itemRepository.search(queryBuilder.build()); // Total number long total = items.getTotalElements(); System.out.println("Total number = " + total); for (Item item : items) { System.out.println(item); } }
Result:
5.6. polymerization
5.6.1. Polymerization into barrels
Bucket is grouping, for example, here we grouped according to brand:
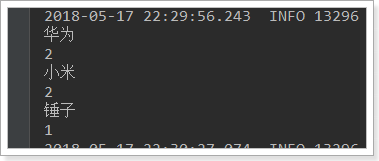
@Test public void testAgg(){ NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); // Do not query any results queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null)); // 1. Add a new aggregation, the aggregation type is terms, the aggregation name is brands, and the aggregation field is brand. queryBuilder.addAggregation( AggregationBuilders.terms("brands").field("brand")); // 2. Queries need to be strongly converted to Aggregated Page type AggregatedPage<Item> aggPage = (AggregatedPage<Item>) this.itemRepository.search(queryBuilder.build()); // 3, analysis // 3.1. Take the aggregation named brands from the result. // Because it's a term aggregation using String type fields, the result is strongly converted to StringTerm type. StringTerms agg = (StringTerms) aggPage.getAggregation("brands"); // 3.2. Acquisition Barrel List<StringTerms.Bucket> buckets = agg.getBuckets(); // 3.3, traversal for (StringTerms.Bucket bucket : buckets) { // 3.4. Get the key in the barrel, that is, the brand name System.out.println(bucket.getKeyAsString()); // 3.5. Get the number of documents in the bucket System.out.println(bucket.getDocCount()); } }
The results shown are as follows:
Key API:
-
AggregationBuilders: AggregationBuilders: Aggregated build factory classes. All aggregations are built by this class to see its static approach:
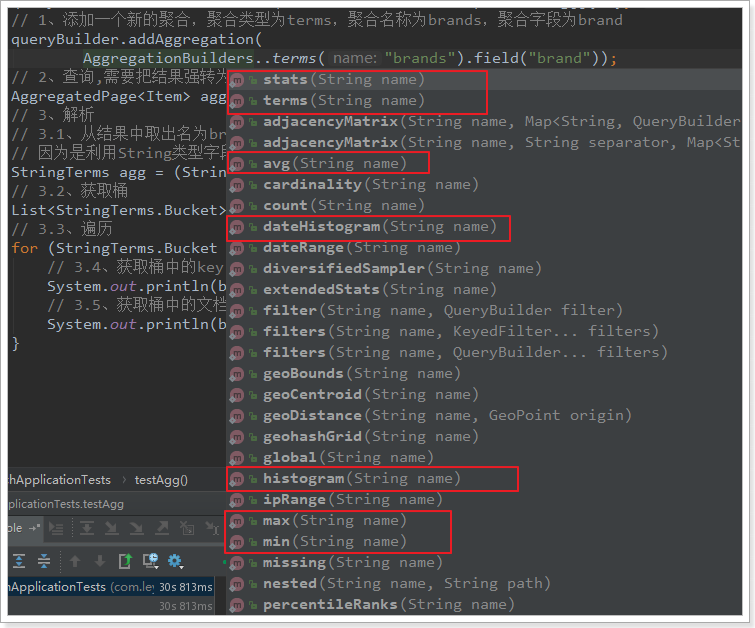
-
Aggregated Page: The result class of aggregated queries. It is a sub-interface of Page<T>:
Aggregated Page extends the functions related to aggregation on the basis of Page function. It is actually a kind of encapsulation of aggregation results. You can see from the JSON structure of aggregation results.
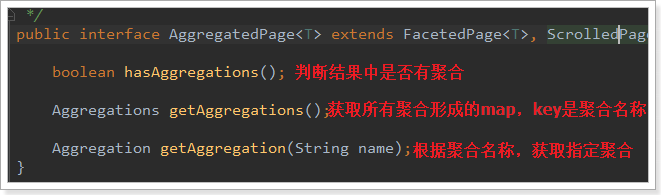
The returned results are Aggregation-type objects, but they are represented by different subclasses depending on the field type.
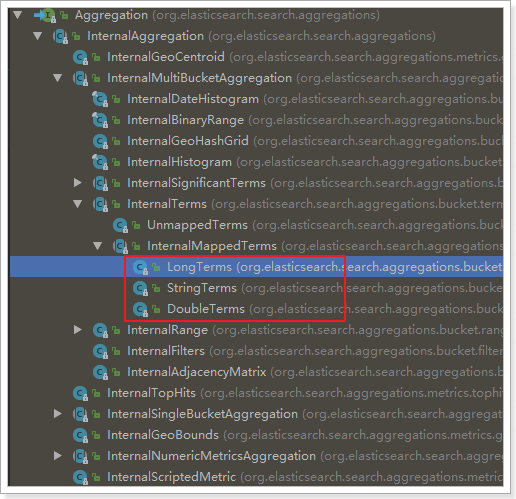
Let's take a look at the JSON results of the queries on the page as compared to the Java classes:
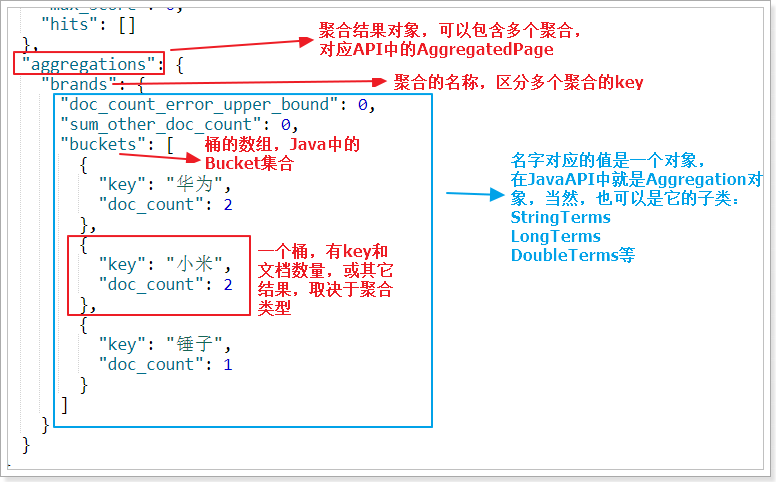
5.6.2. Nested aggregation, average
Code:
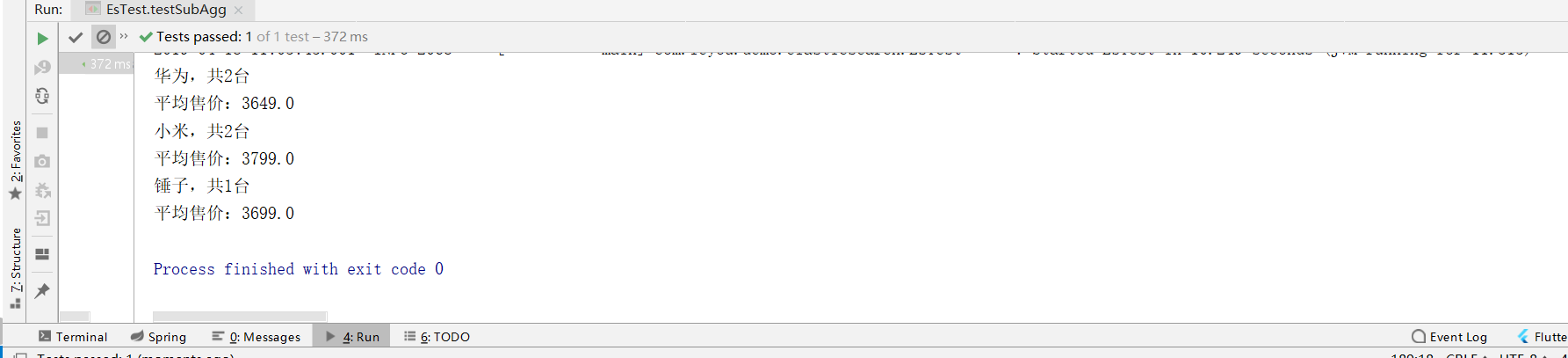
@Test public void testSubAgg(){ NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); // Do not query any results queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null)); // 1. Add a new aggregation, the aggregation type is terms, the aggregation name is brands, and the aggregation field is brand. queryBuilder.addAggregation( AggregationBuilders.terms("brands").field("brand") .subAggregation(AggregationBuilders.avg("priceAvg").field("price")) // Nested aggregation in brand aggregation bucket to get average value ); // 2. Queries need to be strongly converted to Aggregated Page type AggregatedPage<Item> aggPage = (AggregatedPage<Item>) this.itemRepository.search(queryBuilder.build()); // 3, analysis // 3.1. Take the aggregation named brands from the result. // Because it's a term aggregation using String type fields, the result is strongly converted to StringTerm type. StringTerms agg = (StringTerms) aggPage.getAggregation("brands"); // 3.2. Acquisition Barrel List<StringTerms.Bucket> buckets = agg.getBuckets(); // 3.3, traversal for (StringTerms.Bucket bucket : buckets) { // 3.4. Get the key in the bucket, that is, brand name 3.5, and the number of documents in the bucket. System.out.println(bucket.getKeyAsString() + ",common" + bucket.getDocCount() + "platform"); // 3.6. Obtain sub-aggregation results: InternalAvg avg = (InternalAvg) bucket.getAggregations().asMap().get("priceAvg"); System.out.println("Average selling price:" + avg.getValue()); } }
Result: