introduction
In previous project ERNIE for CSC: can't you tell the difference? Here comes the Savior! In, we introduced how to train a text error correction model from 0.
At the end of the article, the Taskflow of PaddleNLP is mentioned. This paper launches an interesting project on Taskflow based on text error correction: how to make AI do the homework of correcting typos.
Typo correction has always been the "reserved repertoire" of Chinese examination. You must be familiar with the following forms of exercises, right?
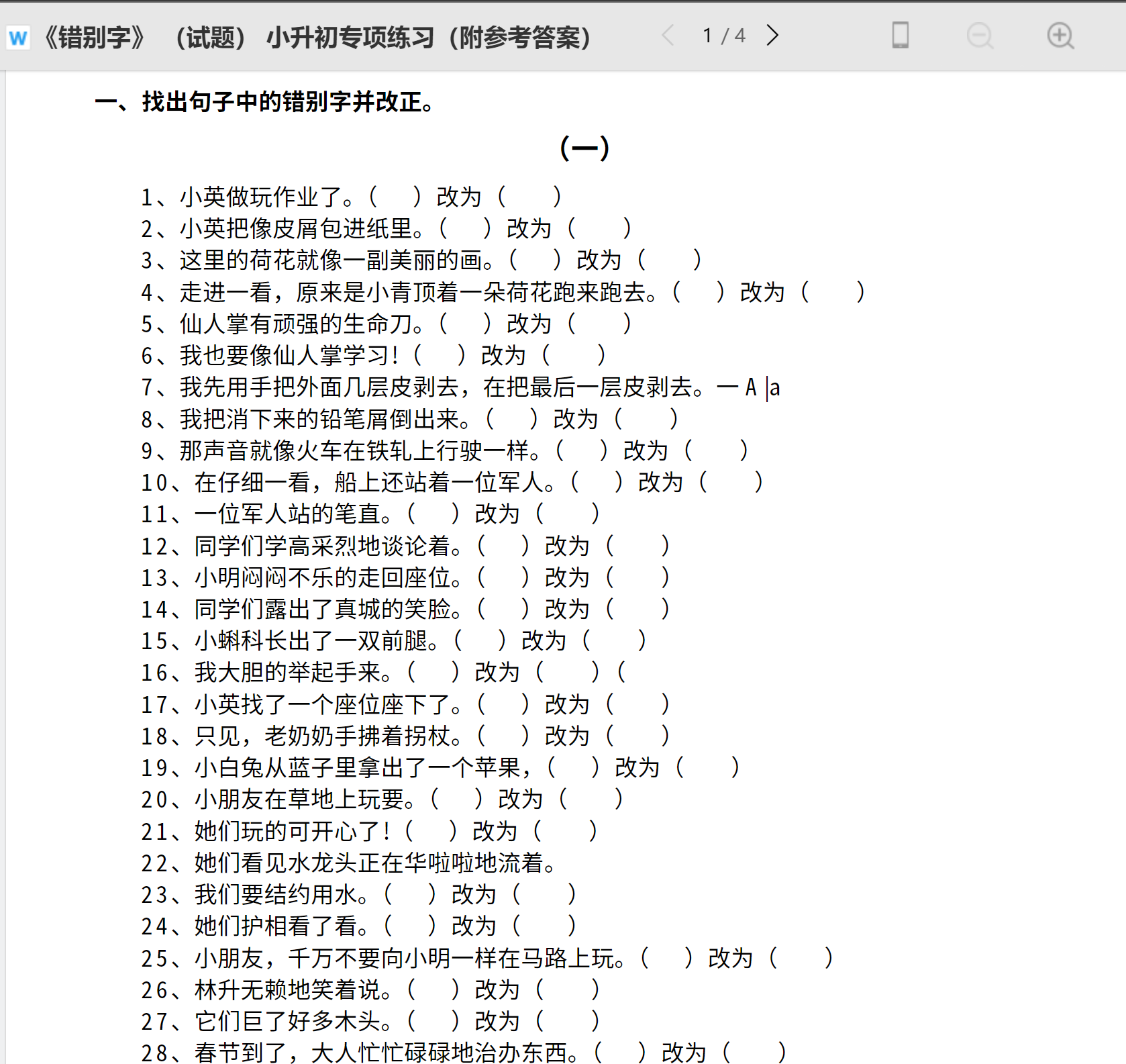
This paper studies how to realize AI automatic answer based on paddelnlp Taskflow and detect its "language level".
PaddleNLP Taskflow introduction
paddlenlp.Taskflow is designed to provide NLP preset tasks out of the box, covering two core applications: natural language understanding and natural language generation, and providing industrial effect and extreme prediction performance in Chinese scenes.
Task list
Currently, paddlenlp.Taskflow supports the following tasks. The text error correction used in this article is one of them.
| Natural language understanding task | Natural language generation task |
|---|---|
| Chinese word segmentation | Generative Q & A |
| Part of speech tagging | Intelligent poetry writing |
| Named entity recognition | Text translation (TODO) |
| Text error correction | Open domain dialog (TODO) |
| Syntactic analysis | Automatic couplet (TODO) |
| Emotional analysis |
With the iteration of the version, paddlenlp.Taskflow will continue to open more application scenarios.
usage
Then let's look at its usage.
from paddlenlp import Taskflow
corrector = Taskflow("text_correction")
corrector('When encountering adversity, we must have the courage to face it, and the more setbacks, the more courage, so that we can move forward on the road of success.')
>>> [{'source': 'When encountering adversity, we must have the courage to face it, and the more setbacks, the more courage, so that we can move forward on the road of success.', 'target': 'When encountering adversity, we must have the courage to face it, and the more setbacks, the more courage, so that we can move forward on the road of success.', 'errors': [{'position': 3, 'correction': {'unexpectedly': 'Boundary'}}]}]
corrector(['When encountering adversity, we must have the courage to face it, and the more setbacks, the more courage, so that we can move forward on the road of success.',
'Life is like this. Only through training can we make ourselves stronger and more optimistic.'])
>>> [{'source': 'When encountering adversity, we must have the courage to face it, and the more setbacks, the more courage, so that we can move forward on the road of success.', 'target': 'When encountering adversity, we must have the courage to face it, and the more setbacks, the more courage, so that we can move forward on the road of success.', 'errors': [{'position': 3, 'correction': {'unexpectedly': 'Boundary'}}]}, {'source': 'Life is like this. Only through training can we make ourselves stronger and more optimistic.', 'target': 'Life is like this. Only through training can we make ourselves stronger and more optimistic.', 'errors': [{'position': 18, 'correction': {'Clumsy': 'Thrive'}}]}]
If you still have questions about this example, think about PaddleHub. In fact, the two are very similar, right? In fact, Paddle trains the model and provides a very simple way for users to call.
As for... Why did the PaddleHub create the paddlenlp.Taskflow wheel... I don't know
As users, just pay attention to whether they are easy to use
Environmental preparation
# The version of paddlenlp in this project should be upgraded to 2.1 !pip install -U paddlenlp !pip install pypinyin --upgrade
Typo detection and result encapsulation
from paddlenlp import Taskflow
text_correction = Taskflow("text_correction")
text = 'If growth is a work, then trouble is a word hidden in the depths of the paragraph; If growth is a piece of white paper, then trouble is a defect attached to the back'
result = text_correction(text)
[2021-11-04 23:43:35,039] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/vocab.txt
# View where typos are detected result[0]['errors'][0]['position']
# View correction information result[0]['errors'][0]['correction']
{'Measure': 'wrong'}
# Do a post-processing, splicing error correction effect postprocess= text[:result[0]['errors'][0]['position']] + str(result[0]['errors'][0]['correction']) + text[result[0]['errors'][0]['position']+1:]
text[:result[0]['errors'][0]['position']] + list(result[0]['errors'][0]['correction'].keys())[0] + '(' + list(result[0]['errors'][0]['correction'].values())[0] + ')' + text[result[0]['errors'][0]['position']+1:]
'If growth is a work, then trouble is the wrong words hidden in the depths of the paragraph; If growth is a piece of white paper, then trouble is a defect attached to the back'
In the above operation, we correct the test statements by comparing the encapsulation of "violence", and combine them into an effect similar to that required for answering questions.
However, it is obvious that this process can also be optimized. For example, it is not through "violence" to splice parentheses, but through replacement, which at least seems more reasonable; At the same time, this practice also paves the way for dealing with sentences with multiple typos at the same time.
# The string replacement model replaces the text of the specified index bit in the string with another
def replace_char(string, char, index):
string = list(string)
string[index] = char
return ''.join(string)
replace_char(text, (list(result[0]['errors'][0]['correction'].keys())[0] + '(' + list(result[0]['errors'][0]['correction'].values())[0] + ')'), result[0]['errors'][0]['position'])
'If growth is a work, then trouble is the wrong words hidden in the depths of the paragraph; If growth is a piece of white paper, then trouble is a defect attached to the back'
Treatment of Chinese sentence breaks
The typo correction we implemented earlier can only correct one sentence. If the statement length is too long, we will see the model strike
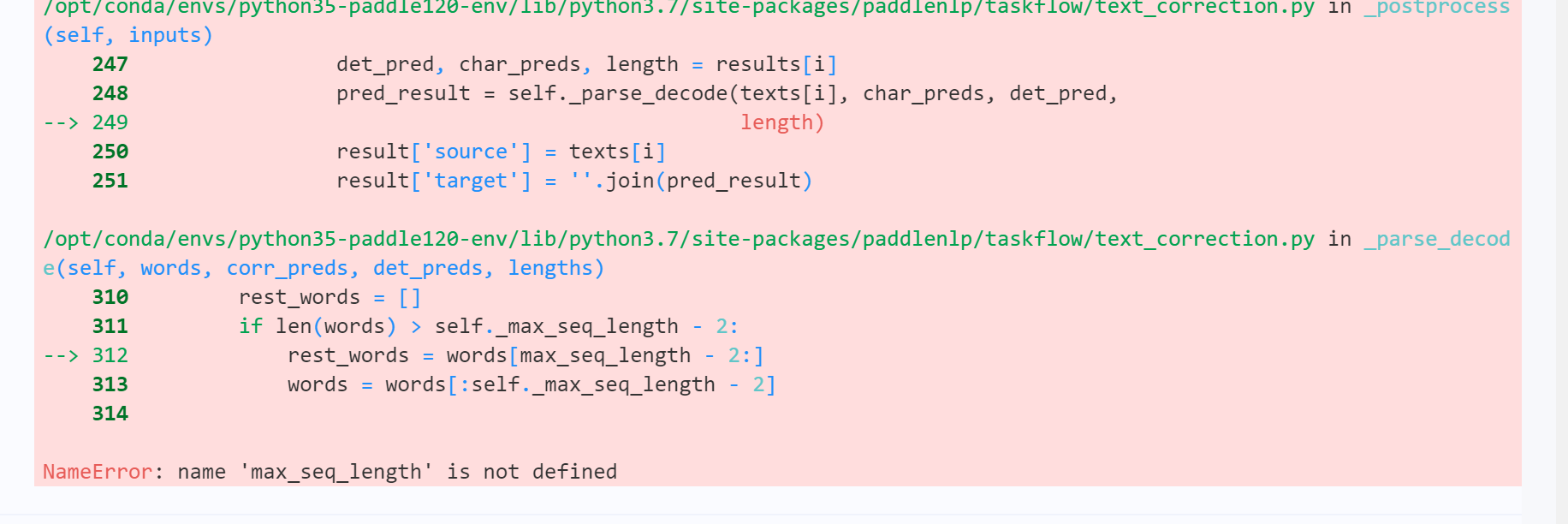
Obviously, limited by the current computing power and model results, it doesn't make much sense for NLP to deal with too long statements.
Therefore, if we want this text error correction model to deal with a whole large paragraph, we need to make Chinese clauses.
import re
def cut_sent(para):
para = re.sub('([. !?\?])([^"'])', r"\1\n\2", para) # Single character break
para = re.sub('(\.{6})([^"'])', r"\1\n\2", para) # English ellipsis
para = re.sub('(\...{2})([^"'])', r"\1\n\2", para) # Chinese Ellipsis
para = re.sub('([. !?\?]["'])([^,. !?\?])', r'\1\n\2', para)
# If there is a terminator before the double quotation mark, then the double quotation mark is the end of the sentence. Put the clause break after the double quotation mark and note that the double quotation marks are carefully retained in the previous sentences
para = para.rstrip() # If there is excess at the end of the segment, remove it
# Semicolons are considered in many rules;, But I ignore it here. Dashes and English double quotation marks are also ignored. If you need to make some simple adjustments.
return para.split("\n")
There are many forms to realize paragraph clauses - extreme points, and reference word segmentation training model can also be used. However, this paper uses the method based on regular expression, which is obviously much more efficient and sufficient in most cases.
Reference link:
Fine Chinese clause segmentation in python (based on regular expression)
Next, we use the following carefully designed paragraph to test the text error correction model and test the correction effect sentence by sentence.
para = "One weekend in the first year of junior high school, Lao Lu's mother came to the flowing County for the first time to see me at school. Seeing my mother, I couldn't wait to say, "Mom, have you brought anything delicious?" My mother excitedly stuffed me with a box of beautifully packaged nutrient solution. I was surprised and asked my mother, "our family is so difficult. Why do you buy it?" my mother smiled and said, "take care of the name and meaning, nutrient solution, replenish your brain, and you can go to College after drinking it." I touched the box of nutrient solution and muttered, "it's so expensive,Borrow money again?" The mother smiled, "No!The beautiful silver bracelet was handed down to her mother by her grandmother. It is the most valuable thing for a poor mother. She has been reluctant to wear it for many years and pressed at the bottom of the box."
sents = cut_sent(para)
print("\n".join(sents))
results = text_correction(cut_sent(para))
for idx, item in enumerate(sents):
res = text_correction(item)
if (len(res[0]['errors'])) > 0:
for i, error in enumerate(res[0]['errors']):
if i == 0:
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), res[0]['errors'][i]['position'])
else:
# If there are multiple misspellings in the sentence, the subsequent misspelling index will move back 3 digits for each replacement of the previous word: that is, brackets + words = 3 digits
p = res[0]['errors'][i]['position'] + i * 3
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), p)
print(item)
else:
print(item)
One weekend in the first year of junior high school, Lao Lu's mother came to the flowing County for the first time to see me at school. When I saw my mother, I couldn't wait and said, "Mom, have you brought anything delicious?" My mother excitedly stuffed me with a box of nutrient solution packaged with teren (wheel). I was surprised and asked my mother, "our family is so difficult. Why do you buy it?" The mother smiled and said, "take care of the name and meaning. Nutrient solution can replenish the brain. After drinking it, you will be able to enter the University." I rubbed (knocked) the box of nutrient solution and muttered, "it's so expensive,Borrow money again?" The mother smiled, "No!It's a bracelet. The beautiful silver bracelet was handed down to her mother by her grandmother. It is the most valuable thing for a poor mother. She has been reluctant to wear it for many years and pressed at the bottom of the box.
In this way, an AI typo detection answering machine was basically born!
In fact, there are many typos in this paragraph. Only part of them can be found by using paddlenlp.Taskflow. If you go to the exam, you may fail.
Therefore, if it is in an industrial scene, it is necessary to enrich the data set based on the pre training model to obtain better results. This paper will give some ideas of supplementary data sets later.
Word document error correction
Next, we will continue to enrich the implementation of paddlenlp.Taskflow text error correction in different scenarios. Word document is a very common form in our work. In order to save some copy and paste time, now we study how to directly carry out intelligent error correction of the whole word document
We know that although the word document has its own syntax recognition function, it is obviously not perfect... For example, the following example:
An inventory of typos in a certain novel (I)
Most of these typos have escaped the grammar recognition of word - if they can be recognized early in the morning, the author may have changed the codeword long ago
Then, let's take a look at the effect of the built-in model of paddlenlp.Taskflow on the recognition of typos in online novels. Finally, we will save the detection results to a new word document.
# Install dependent Libraries !pip install python-docx
from docx import Document from docx.shared import Inches
def get_paragraphs_text(path):
"""
Gets the text of all paragraphs
:param path: word route
:return: list Type, such as:
['Test', 'hello world', ...]
"""
document = Document(path)
# Extract body text
paragraphs_text = ""
for paragraph in document.paragraphs:
# Splice a list, including the structure and content of paragraphs
paragraphs_text += paragraph.text + "\n"
return paragraphs_text
text = get_paragraphs_text('csc-qd.docx')
print("\n".join(cut_sent(text)))
csc_result = text_correction(cut_sent(text))
for idx, item in enumerate(cut_sent(text)):
if item is not '':
res = text_correction(item)
if (len(res[0]['errors'])) > 0:
for i, error in enumerate(res[0]['errors']):
if i == 0:
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), res[0]['errors'][i]['position'])
else:
p = res[0]['errors'][i]['position'] + i * 3
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), p)
print(item)
else:
print(item)
Finally, he led a large and small family out of the Cang mountain It's just that the wind in early spring made all the girls intoxicated The clouds were shining and looked very shocking Only the sound of horses' hoofs and the sound of horses' noses could be heard Each one is very moist Then he went to King Jing's house to meet the familiar prince The two Toons came and went So when fan (anti) enters the Imperial College in his spare time At the age of seventeen, he was a great red man in the imperial court The students' sense of separation gradually faded away But after all, the name of his poem has already spread abroad He also went around with his boss to check the situation after Ju Zi entered Beijing Think of the story that uncle wuzhu told in Dan (Australia) Since it's not a favor of the city Fan Xian (ya) was slightly surprised, and his clear eyes immediately returned (recovered) to calm In addition to a trace of comfort, it is more about fan Xian (domain) who seems to be content with his official career and has some confidence. A few days later, he first led Wan'er back to the prime minister's house. "Naturally, the investigation is necessary, but it's not as reckless as you, "said Li Changshou Ao Yi was easily distracted. At the moment, Li Changshou also heard (got) quite with emotion. Jiang Sier is the happiest of the two spirit fish Ao Yi and Jiang Sier reluctantly bid farewell. Li Changshou and ling'e made a bow to the gate keeper Li Changshou nodded calmly It is rare for the temple of Poseidon to be cold during the day Maybe it's because these people were squeezed too hard by the imperial court I'm worried that Lao Lu will continue to attack JianNu (female) regardless of everything. I don't think the eunuchs who took the army to Henan would kindly distribute their ammunition to Lao Lu. You say, how did he offend Yang Sichang and raise (QI) the potential of these villains? Hong Chengchou's leisurely(Road: Honestly do the sill (ground) car to keep the spirit No, I tried my best to save the dead tree until it died. Qian Duoduo is lying on his bed with his feet tilted. There is a shoe hanging on his big toe, shaking and shaking, but he is not willing to fall from his feet. He Changshi looked at Qian Duoduo anxiously and said: He Changshi reluctantly walked to the door Si Liren turned his head and glanced silently at Li altar After all, the drama of cleaning up the school should be particularly fierce The man sat on the ground in panic and stepped back. Everyone, look over there Li Shentan looked down helplessly Luo Lan slowly backed away Between heaven and earth, there emerged one avenue after another, and they were breaking The supreme creature coughed up a mouthful of blood and Huo looked up. Don't let the departed real body look at this world! Will come back desperate It's also like the debris of indelible creatures that have been erased!
It should be said that the text error correction model of paddlenlp.Taskflow has some attainments in the distinction of [place, place, get] - probably the relationship between data sets.
Although the accuracy of error detection and correction still needs to be improved, it looks much better than answering well-designed questions?
new_document = Document()
for idx, item in enumerate(cut_sent(text)):
if item is not '':
res = text_correction(item)
if (len(res[0]['errors'])) > 0:
for i, error in enumerate(res[0]['errors']):
if i == 0:
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), res[0]['errors'][i]['position'])
else:
p = res[0]['errors'][i]['position'] + i * 3
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), p)
new_document.add_paragraph(item)
else:
new_document.add_paragraph(item)
# Save results to a new document
new_document.save('csc-result.docx')
PDF homework answer
Let's ask AI to do another problem. This time, the text format is PDF.
!pip install pdfplumber
import pdfplumber
import pandas as pd
with pdfplumber.open("12345.pdf") as pdf:
page = pdf.pages[0] # Information on the first page
text = page.extract_text()
print(text)
Basic knowledge·chinese characters 6,There is no typo in the following sentence is (). A.Books are the ladder of human progress. B.Teachers often use their spare time to feed and guide us in our study. C.Junior high school learning life is coming to an end, and students cherish this time. D.Dream Garden World Cup, the Chinese team took off from Xi'an.
for idx, item in enumerate(cut_sent(text)):
if item is not '':
res = text_correction(item)
if (len(res[0]['errors'])) > 0:
for i, error in enumerate(res[0]['errors']):
if i == 0:
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), res[0]['errors'][i]['position'])
else:
p = res[0]['errors'][i]['position'] + i * 3
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), p)
print(item)
else:
print(item)
Basic knowledge·chinese characters 6,There is no typo in the following sentence is (). A.Books (precepts) are the ladder of human progress. B.Teachers often use their spare time to feed (accompany) us in our study. C.Junior high school learning life is coming to an end, and students cherish this time. D.Dream garden (round) World Cup, the Chinese team took off from Xi'an.
In option A, in fact, the model has been positioned as A typo, but the change is A little outrageous... Generally speaking, although the answer to this question is bumpy, at least AI has selected the correct answer. However, when dealing with PDF, the line feed problem is still A headache. For example, if the line feed of option C is not handled well, the answer result will change.
PDF line feed problem
with pdfplumber.open("14540300364943.pdf") as pdf:
page = pdf.pages[0] # Information on the first page
text = page.extract_text()
print(text)
Basic knowledge·chinese characters 6,One of the following sentences without typos is (). A.Books are the ladder of human progress. B.Teachers often use their spare time to feed and guide us in our study. C.Junior high school study life is coming to an end, and the students cherish it For a while. D.Dream Garden World Cup, the Chinese team took off from Xi'an.
for idx, item in enumerate(cut_sent(text)):
if item is not '':
res = text_correction(item)
if (len(res[0]['errors'])) > 0:
for i, error in enumerate(res[0]['errors']):
if i == 0:
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), res[0]['errors'][i]['position'])
else:
p = res[0]['errors'][i]['position'] + i * 3
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), p)
print(item)
else:
print(item)
else:
print(item)
Basic knowledge·chinese characters 6,One of the following sentences without typos (like) is (). A.Books (precepts) are the ladder of human progress. B.Teachers often use their spare time to feed (accompany) us in our study. C.Junior high school study life is coming to an end, and the students cherish it A short time. D.Dream garden (round) World Cup, the Chinese team took off from Xi'an.
Because the newline statement is directly sent into the model prediction, it is obvious that there is a misunderstanding.
Summary and thinking
From the previous questions of paddlenlp.Taskflow, if you directly take the typo detection test, you will get an estimated 50-60 points, which is obviously not very qualified.
However, as we all know, the in-depth learning model is "fed" by data. I believe that if the model "has seen" five-year simulated three-year college entrance examination "," Huanggang secret volume "and so on, its performance should be higher?
Here are some ideas for supplementary data sets:
- A full series of [typo special] in Baidu documents
- The most common typos sorted out in biting words
- More data automatically generated for Chinese text error correction tasks
There are also many ways to label data sets. For example, sgml format data can be labeled as follows:
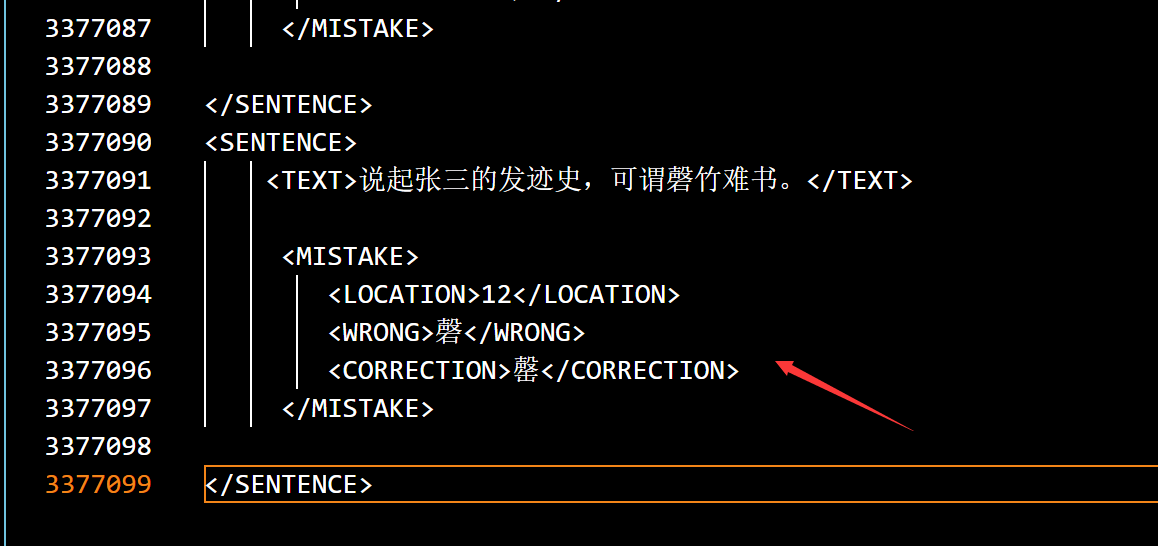
Considering that there are only those Chinese test contents, I feel that if targeted data sets are supplemented, it is more promising for AI to start homework well and quickly.