catalogue
5.1 break up video into pictures
5.2 comparing image similarity
5.2.1 compare image similarity based on equality
5.2.2 calculate whether the pictures are equal based on numpy
5.2.3 hash based (taking mean hash algorithm as an example)
Basic idea:
1. Break up the video into pictures
2. Select appropriate methods (equality, numpy, hash) to compare image similarity
3. Remove the duplicate lens according to the similarity
5.1 break up video into pictures
Where, vc=cv2.VideoCapture ()
When the parameter is 0, that is, vc=cv2.VideoCapture (0), it means to turn on the built-in camera of the notebook;
The parameter is the video file path, that is, vc=cv2.VideoCapture ("... / testi.mp4"), which is to open the video file.
The code is as follows:
import os
import cv2
import subprocess
os.chdir(r'D:\pythonclass')#Go to directory
v_path='ghz.mp4'
image_save='./img'#Create a new folder for the generated pictures
cap=cv2.VideoCapture(v_path)
frame_count=cap.get(cv2.CAP_PROP_FRAME_COUNT)#Returns the number of frames
print(frame_count)
for i in range(int(frame_count)):
_,img=cap.read()
img=cv2.cvtColor(img,cv2.cv2.COLOR_BGR2GRAY) #cv2.COLOR_RGBGRAY cv2.COLOR_BGR2GRAY
#Uppercase are constants
cv2.imwrite('./img/image{}.jpg'.format(i),img)#Pass i into {}The effect is shown in the figure:
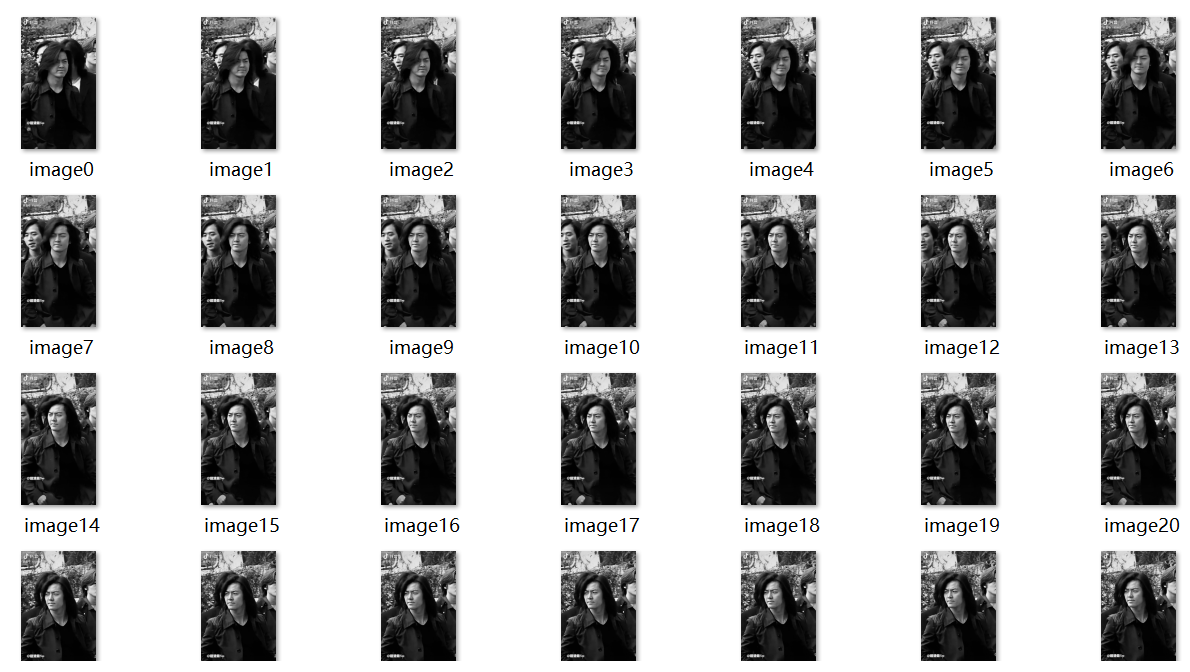
5.2 comparing image similarity
5.2.1 compare image similarity based on equality
Function involved: Operator (standard operator instead of function)
Among them, operator.eq(a,b) will be used.
eq(a, b) is the same as a == b.
Reference to other functions of the Operator: Operator -- standard operator substitution function -- Python 3.10.0 documentation
The code is as follows:
import operator
from PIL import Image
a=Image.open('./img/image0.jpg')
b=Image.open('./img/image0.jpg')
print(a)
out=operator.eq(a,b)
print(out)5.2.2 calculate whether the pictures are equal based on numpy
Functions involved: NumPy arithmetic function; any() function.
① umpy contains simple addition, subtraction, multiplication and division: add(), subtract(), multiply(), and divide().
np.subtract(a,b) indicates that two arrays are subtracted.
② Any() function: if any item in iterable is true or the iteratable object is empty, the any() function returns true; otherwise, it returns False.
All elements are TRUE except 0, empty and FALSE.
The code is as follows:
import operator
from PIL import Image
import os
os.chdir(r'D:\pythonclass')
a=Image.open('./img/image0.jpg')
b=Image.open('./img/image0.jpg')
out=operator.eq(a,b)
print(out)5.2.3 hash based (taking mean hash algorithm as an example)
Basic principle: the picture contains parts with different frequencies. Among them, the low-frequency component with small brightness change is the low-frequency component, and vice versa is the high-frequency component. Low frequency finished products describe a wide range of information, and high-frequency films describe details. The small picture lacks details, so it is low-frequency.
Basic idea of algorithm:
1. Reduce the picture size to 8 * 8
2. Convert to grayscale image
3. Calculate the average gray value of pixels
4. Generate hash value based on gray level
5. Separate the image into three RGB channels and calculate the similarity value of each channel
6. Compare the hash value (calculate the Hamming distance. The fewer different digits, the greater the image similarity)
Hash algorithm reference: Hash algorithm - image similarity calculation_ chenghaoy's blog - CSDN blog_ Mean hash algorithm
The code is as follows:
import cv2
import numpy as np
import matplotlib.pyplot as plt
import os
#Mean hash algorithm
def aHash(img):
#Zoom to 8 * 8
plt.imshow(img)
plt.axis('off')
plt.show()
img=cv2.resize(img,(8,8))
plt.imshow(img)
plt.axis('off')
plt.show()
#Convert to grayscale
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
s=0
hash_str='' # s is the pixel and the initial value is 0, hash_str is the hash value, and the initial value is' '
#Ergodic accumulation for pixel sum
for i in range(8):
for j in range(8):
s=s + gray[i,j]
#Average gray level
avg=s/64
#The gray level is greater than the average value of 1. On the contrary, it is 0 to generate the hash value of the picture
for i in range(8):
for j in range(8):
if gray[i,j]>avg:
hash_str=hash_str+'1'
else:
hash_str=hash_str+'0'
return hash_str
# The similarity is calculated by obtaining the histogram of each RGB channel
def classify_hist_with_split(image1,image2,size=(256,256)):
#After resizing the image, it is separated into three RGB channels, and then the similarity value of each channel is calculated
image1 = cv2.resize(image1,size)
image2 = cv2.resize(image2,size)
plt.imshow(image1)
plt.show()
plt.axis('off')
plt.imshow(image2)
plt.show()
plt.axis('off')
sub_image1=cv2.split(image1)
sub_image2=cv2.split(image2)
sub_data=0
for im1,im2 in zip(sub_image1,sub_image2):
sub_data+=calculate(im1,im2)
sub_data=sub_data/3
return sub_data
# Calculate the similarity value of histogram of single channel
def calculate(image1,image2):
hist1 = cv2.calcHist([image1],[0],None,[256],[0.0,225.0])
hist2 = cv2.calcHist([image2],[0],None,[256],[0.0,225.0])
plt.plot(hist1,color="r")
plt.plot(hist2,color="g")
plt.show()
# Calculate the coincidence degree of histogram
degree = 0
for i in range(len(hist1)):
if hist1[i]!=hist2[i]:
degree=degree+(1-abs(hist1[i])-hist2[i])/max(hist1[i],hist2[i])
else:
degree = degree + 1#Statistical similarity
degree = degree / len(hist1)
return degree
# Hash value comparison
def cmpHash(hash1,hash2):
n=0
print(hash1)
print(hash2)
# If the hash length is different, - 1 is returned, indicating an error in parameter transmission
if len(hash1)!=len(hash2):#!= Not equal to
return -1
#Ergodic judgment
for i in range(len(hash1)):
# If it is not equal, n count + 1, and N is the similarity finally
if hash1[i]!=hash2[i]:
n=n+1
return n
img1 = cv2.imread('./img/image0.jpg')
img2 = cv2.imread('./img/image1.jpg')
hash1 = aHash(img1)
hash2 = aHash(img2)
n=cmpHash(hash1,hash2)
print('Mean hash algorithm similarity:',n)
n=classify_hist_with_split(img1,img2)#I'm looking at image0 and image1
print('Three histogram algorithm similarity:',n)The effect is shown in the figure:

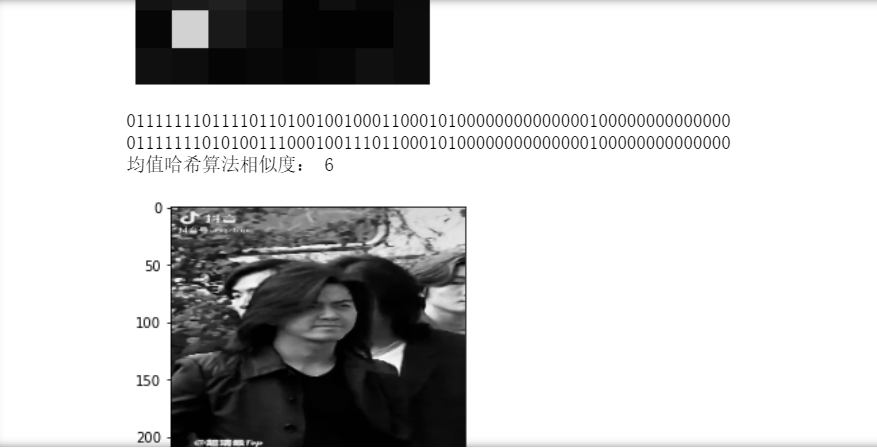
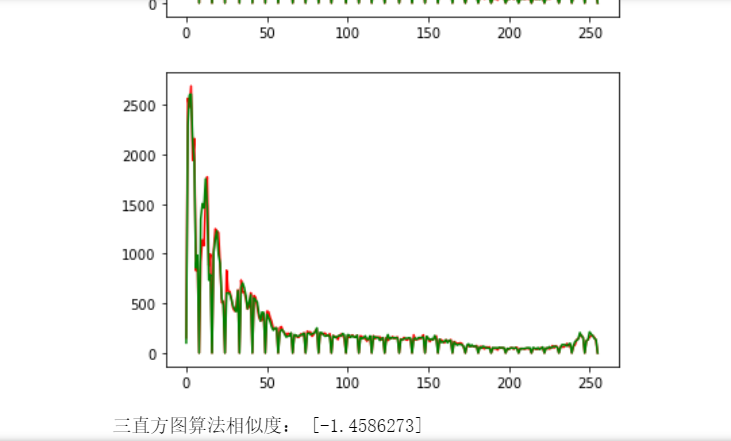
In addition, you can also compare split shots, remove duplicate shots, and place the filtered pictures in a folder.
The code is as follows:
import os
import cv2
from PIL import Image
os.chdir(r'D:\pythonclass\video')
print(os.getcwd())
#for f in os.listdir('./shot'):
for i in range(549):
img1 = cv2.imread('./img/image{}.jpg'.format(i))
img2 = cv2.imread('./img/image{}.jpg'.format(i+1))
hash1 = aHash(img1)
hash2 = aHash(img2)
n = cmpHash(hash1,hash2)
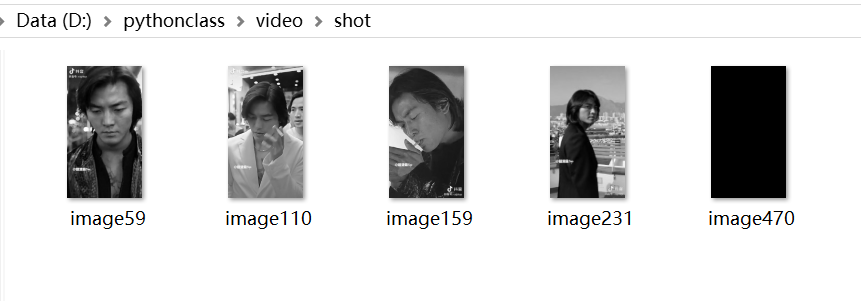
if (n>32):#Different lens numbers can be obtained by changing parameters
print('Mean hash algorithm similarity:',n/64)
cv2.imwrite('./shot/image{}.jpg'.format(i+1),img2)The effect is shown in the figure:

5.3 video capture: ffmpeg
Use ffmpeg to intercept 1min video.
Enter: ffmpeg -i food.mp4 -ss 1 -t 60 -codec copy foodcut.mp4 in the program box
Name the captured video cut.mp4
The effect is shown in the figure:

5.4 comprehensive application
On the basis of 5.3, the methods of 5.1 and 5.2 are used to process the intercepted video.
5.4.1 exercise 1
The code is as follows:
The effect is shown in the figure: