In this lesson, we mainly introduce the entry program of Flink and the implementation of SQL form.
In the last lesson, we have explained Flink's common application scenarios and architecture model design. In this lesson, we will start from a simple WordCount case and implement it in SQL mode at the same time, laying a solid foundation for the later practical courses.
First of all, we will start with environment construction and introduce how to build scaffolding for local debugging environment; then we will develop word counting from two ways of DataSet (batch processing) and DataStream (stream processing); finally, we will introduce the use of Flink Table and SQL.
Flink development environment
Generally speaking, any big data framework runs in the form of cluster in the actual production environment, and most of our debugging code will build a template project locally, and Flink is no exception.
Flink is an open source big data project with Java and Scala as development languages. Generally, we recommend using Java as development language and Maven as compilation and package management tools for project construction and compilation. For most developers, JDK, Maven and Git are three essential development tools.
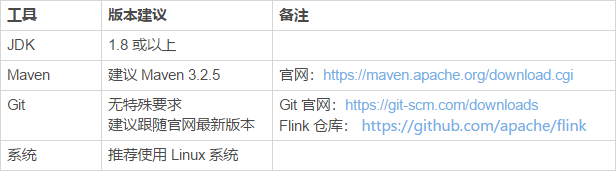
The installation recommendations for JDK, Maven, and Git are as follows:
Project creation
Generally speaking, we are creating projects through IDE. We can create new projects by ourselves, add Maven dependency, or directly create applications with mvn command:
mvn archetype:generate \ -DarchetypeGroupId=org.apache.flink \ -DarchetypeArtifactId=flink-quickstart-java \ -DarchetypeVersion=1.10.0
Create a new project by specifying the three elements of Maven project, namely GroupId, ArtifactId, and Version. At the same time, Flink provides me with a more convenient way to create a Flink project:
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.10.0
We execute the command directly at the terminal:
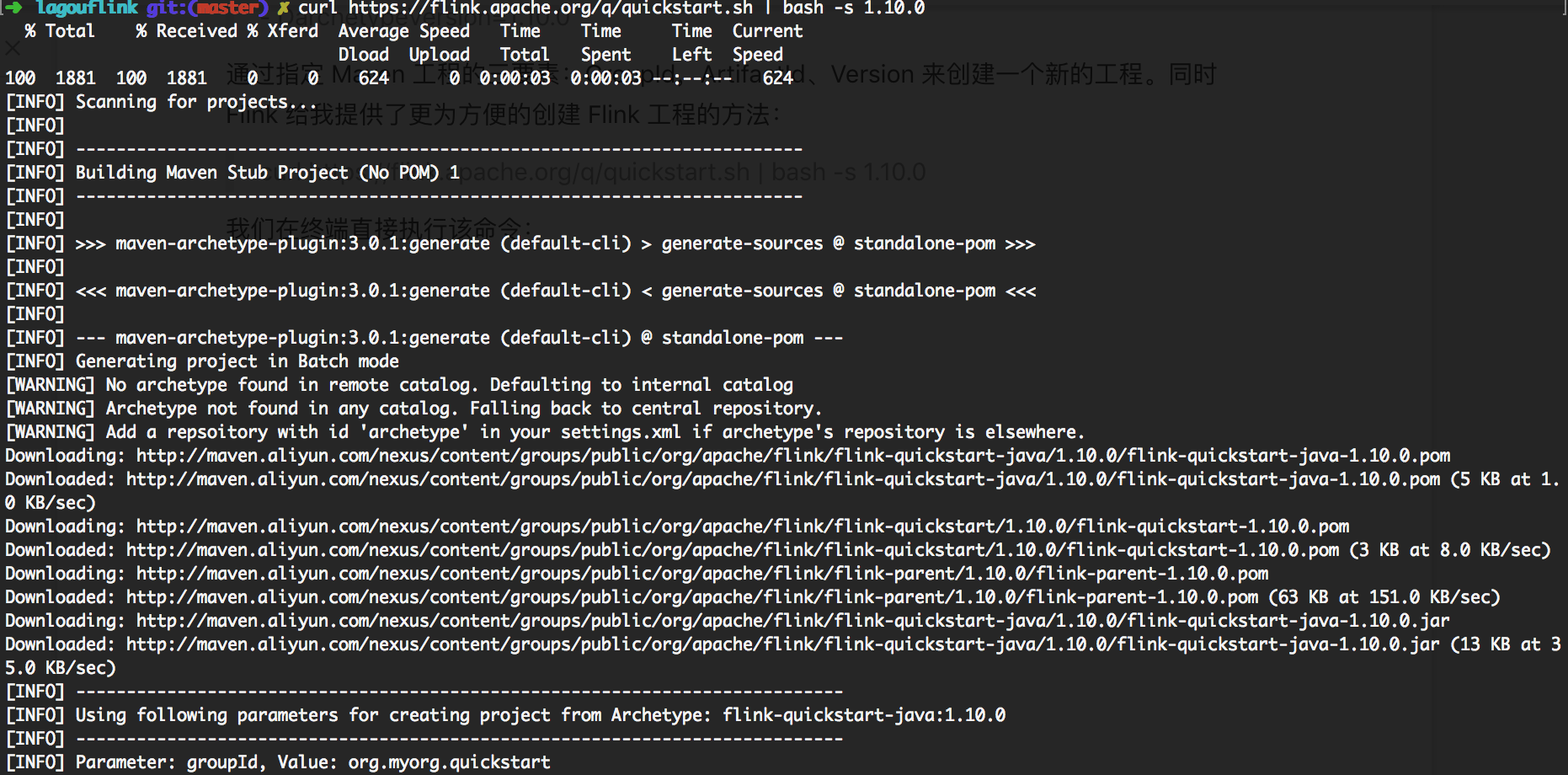
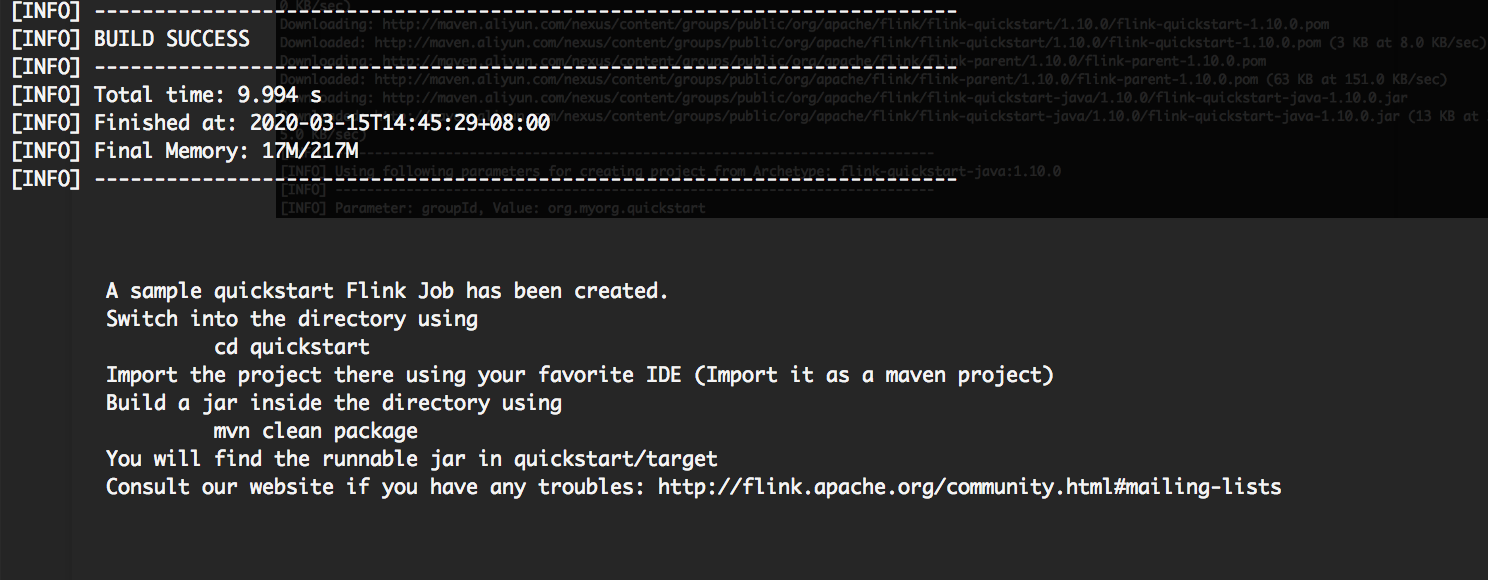
The Build Success message appears directly. We can see a project named quickstart that has been built in the local directory.
The main thing we need here is to comment out the scope in the automatically generated project pom.xml file for the dependency on Flink:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <!--<scope>provided</scope>--> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> <!--<scope>provided</scope>--> </dependency>
DataSet WordCount
WordCount program is the introduction program of big data processing framework, commonly known as "word count". This program is mainly divided into two parts: one is to split the text into words; the other is to count the words in groups and print out the results.
The overall code is as follows:
public static void main(String[] args) throws Exception { //Create context environment for Flink to run final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); //Create a DataSet, where our input is line by line text DataSet<String> text = env.fromElements( "Flink Spark Storm", "Flink Flink Flink", "Spark Spark Spark", "Storm Storm Storm" ); //Calculation through Flink's built-in conversion function DataSet<Tuple2<String, Integer>> counts = text.flatMap(new LineSplitter()) .groupBy(0) .sum(1); //Results printing counts.printToErr(); } public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { //Split text String[] tokens = value.toLowerCase().split("\\W+"); for (String token : tokens) { if (token.length() > 0) { out.collect(new Tuple2<String, Integer>(token, 1)); } } }
The whole process of implementation is divided into the following steps.
First, we need to create a context running environment for Flink:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
Then, use the fromElements function to create a DataSet object, which contains our input, and use the FlatMap, GroupBy, SUM functions to transform it.
Finally, print the output directly on the console.
We can right-click to run the main method, and the calculation results we print will appear in the console:
DataStream WordCount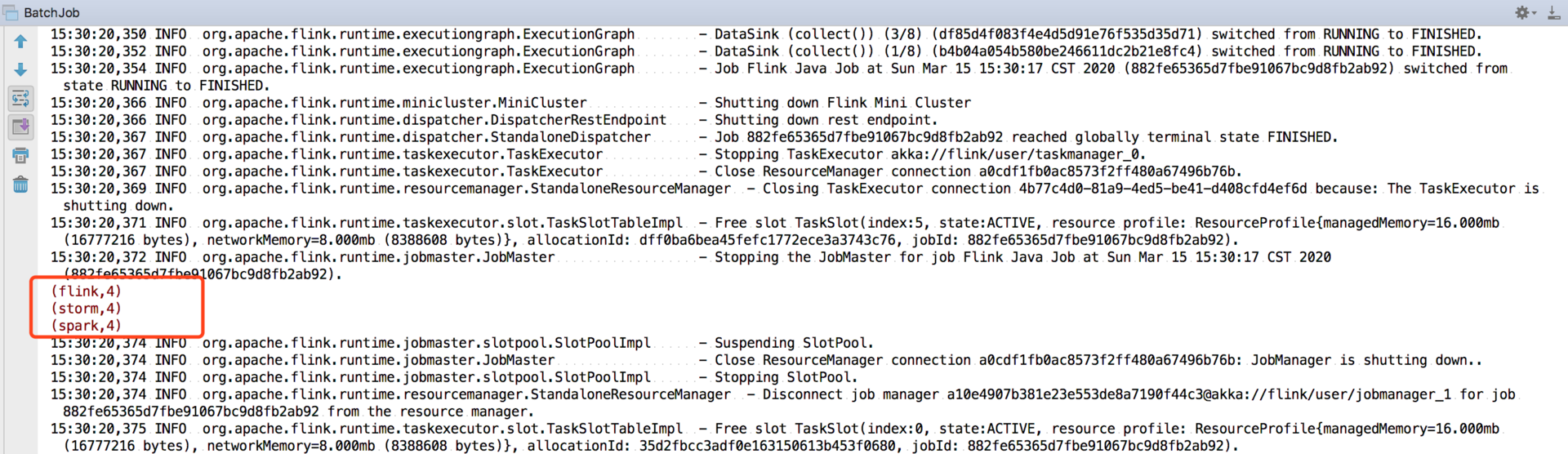
In order to simulate a streaming computing environment, we choose to listen to a local Socket port, and use the scroll window in Flink to print the calculation results every 5 seconds. The code is as follows:
public class StreamingJob { public static void main(String[] args) throws Exception { //Creating Flink's streaming computing environment final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //Listen to local 9000 port DataStream<String> text = env.socketTextStream("127.0.0.1", 9000, "\n"); //Split, group, calculate and aggregate the received data DataStream<WordWithCount> windowCounts = text .flatMap(new FlatMapFunction<String, WordWithCount>() { @Override public void flatMap(String value, Collector<WordWithCount> out) { for (String word : value.split("\\s")) { out.collect(new WordWithCount(word, 1L)); } } }) .keyBy("word") .timeWindow(Time.seconds(5), Time.seconds(1)) .reduce(new ReduceFunction<WordWithCount>() { @Override public WordWithCount reduce(WordWithCount a, WordWithCount b) { return new WordWithCount(a.word, a.count + b.count); } }); //Print results windowCounts.print().setParallelism(1); env.execute("Socket Window WordCount"); } // Data type for words with count public static class WordWithCount { public String word; public long count; public WordWithCount() {} public WordWithCount(String word, long count) { this.word = word; this.count = count; } @Override public String toString() { return word + " : " + count;
The whole flow calculation process is divided into the following steps.
First, create a streaming computing environment:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Then listen to the local 9000 port, split, group, calculate and aggregate the received data. Flink's window function is used in the code, which will be explained in detail in the following lessons.
We use the netcat command locally to start a port:
nc -lk 9000
Then run our main method directly:
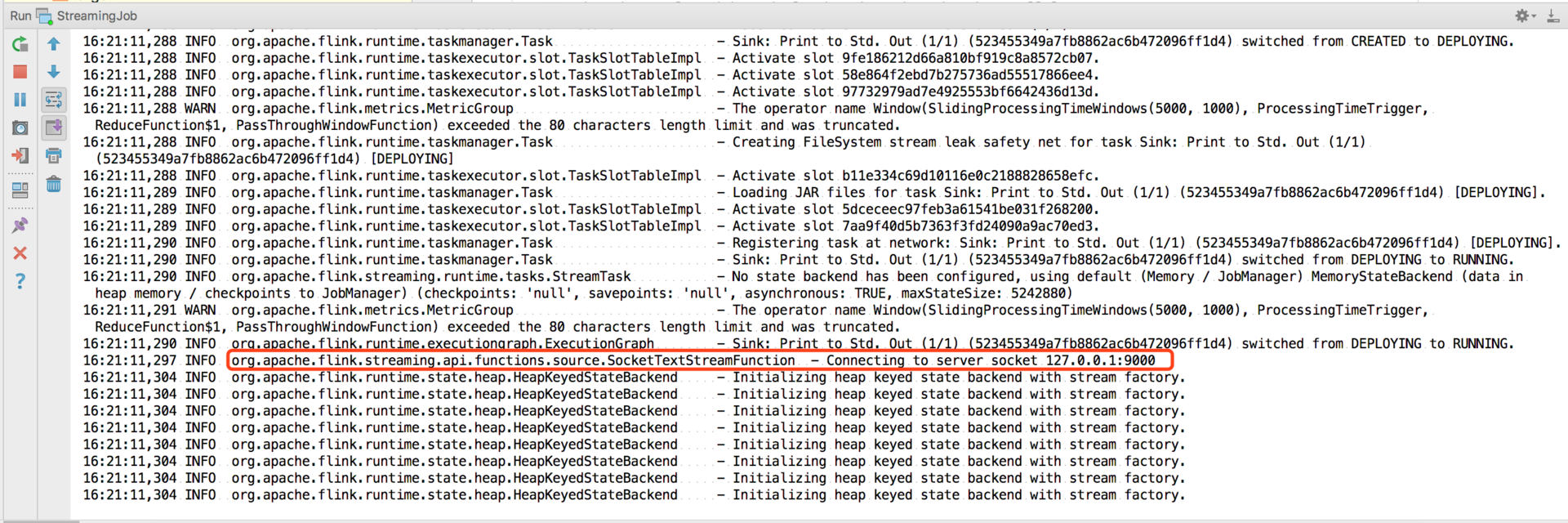
As you can see, the 9000 port of 127.0.0.1 will be monitored after the project is started.
Enter in nc:
$ nc -lk 9000 Flink Flink Flink Flink Spark Storm
You can see in the console:
Flink : 4 Spark : 1 Storm : 1
Flink Table & SQL WordCount
Flink SQL is a development language designed by Flink real-time computing to simplify the computing model and reduce the threshold of real-time computing.
A complete program written by Flink SQL includes the following three parts.
-
Source Operator: it is an abstraction of external data sources. At present, Apache Flink has built in many common data source implementations, such as MySQL, Kafka, etc.
-
Transformation Operators: operator operations are mainly completed such as query and aggregation operations. Currently, Flink SQL supports operations supported by most traditional databases, such as Union, Join, Projection, Difference, Intersection and window.
-
Sink Operator: it is an abstraction of external result tables. At present, Apache Flink also has many commonly used result table abstractions built in, such as Kafka Sink.
We also use one of the most classic WordCount programs as a starting point, which has been developed through the DataSet/DataStream API. Then, to realize the same WordCount function, the Flink table & SQL core only needs one line of code:
//Omit common code such as initialization environment SELECT word, COUNT(word) FROM table GROUP BY word;
First of all, the dependencies in our pom in the whole project are as follows:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.10.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.11 <version>1.10.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java-bridge_2.11</artifactId> <version>1.10.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner-blink_2.11</artifactId> <version>1.10.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner_2.11</artifactId> <version>1.10.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-scala-bridge_2.11</artifactId> <version>1.10.0</version> </dependency>
The first step is to create a context:
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment(); BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
The second step is to read a row of analog data as input:
String words = "hello flink hello lagou"; String[] split = words.split("\\W+"); ArrayList<WC> list = new ArrayList<>(); for(String word : split){ WC wc = new WC(word,1); list.add(wc); } DataSet<WC> input = fbEnv.fromCollection(list);
Step 3: register as a table, execute SQL, and output:
//DataSet to sql, specify field name Table table = fbTableEnv.fromDataSet(input, "word,frequency"); table.printSchema(); //Register as a table fbTableEnv.createTemporaryView("WordCount", table); Table table02 = fbTableEnv.sqlQuery("select word as word, sum(frequency) as frequency from WordCount GROUP BY word"); //Convert table to DataSet DataSet<WC> ds3 = fbTableEnv.toDataSet(table02, WC.class); ds3.printToErr();
The overall code structure is as follows:
public class WordCountSQL { public static void main(String[] args) throws Exception{ //Get operating environment ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment(); //Create a tableEnvironment BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv); String words = "hello flink hello lagou"; String[] split = words.split("\\W+"); ArrayList<WC> list = new ArrayList<>(); for(String word : split){ WC wc = new WC(word,1); list.add(wc); } DataSet<WC> input = fbEnv.fromCollection(list); //DataSet to sql, specify field name Table table = fbTableEnv.fromDataSet(input, "word,frequency"); table.printSchema(); //Register as a table fbTableEnv.createTemporaryView("WordCount", table); Table table02 = fbTableEnv.sqlQuery("select word as word, sum(frequency) as frequency from WordCount GROUP BY word"); //Convert table to DataSet DataSet<WC> ds3 = fbTableEnv.toDataSet(table02, WC.class); ds3.printToErr(); } public static class WC { public String word; public long frequency; public WC() {} public WC(String word, long frequency) { this.word = word; this.frequency = frequency; } @Override public String toString() { return word + ", " + frequency;
We run the program directly, and you can see the output results in the console:
summary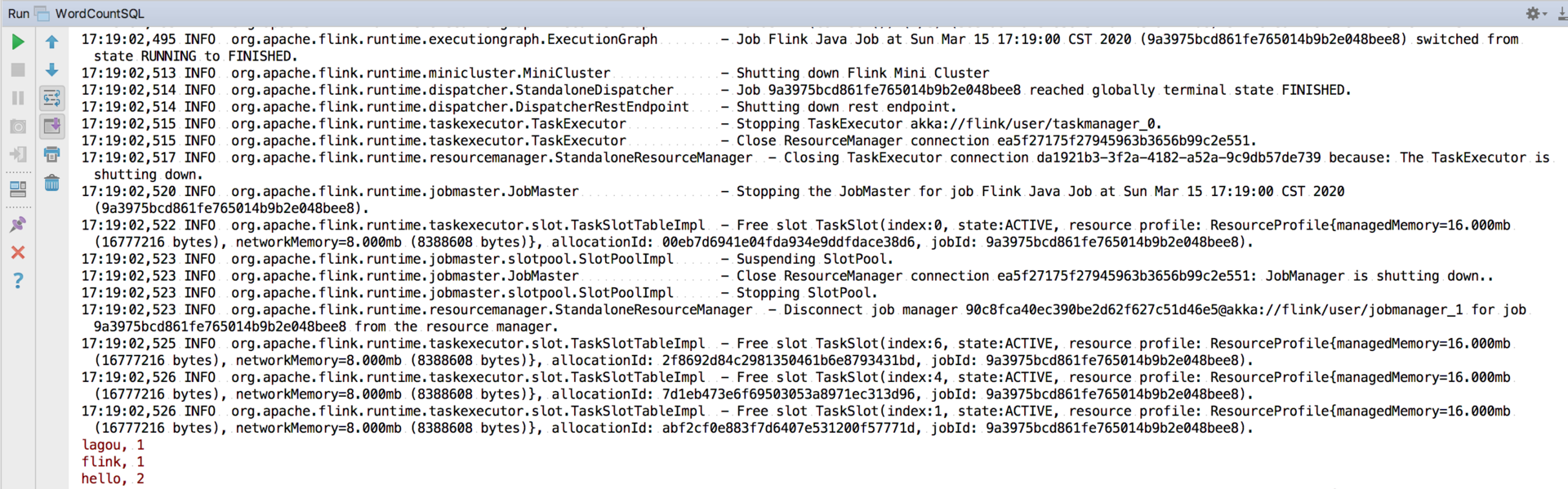
This lesson introduces the project creation of Flink, how to build the scaffolding of debugging environment, and at the same time, the simplest and most classic scenario of word count is implemented with Flink. The first time I experienced the power of Flink SQL, let you have an intuitive understanding, and lay a good foundation for the follow-up content.