regular expressions are powerful tools and techniques for string processing.
regular expression uses a predefined pattern to match a class of strings with common characteristics. It is mainly used to process strings. It can quickly and accurately complete complex search, replacement and other processing requirements. It has important applications in text editing and processing, web crawler and so on.
in Python, the re module provides the functions required for regular expression operations.

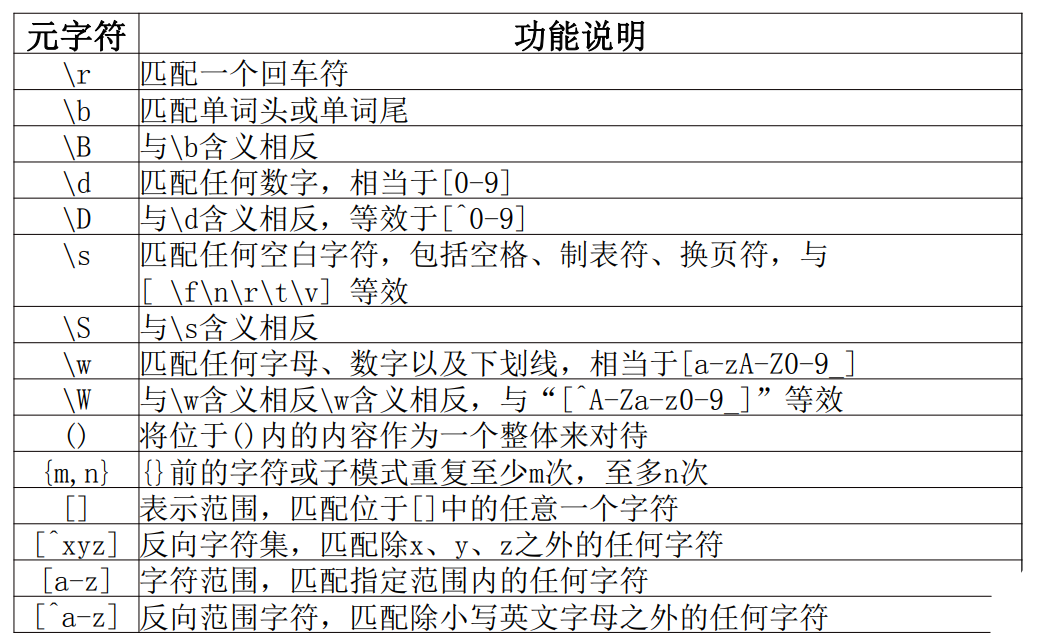



Main methods of re module
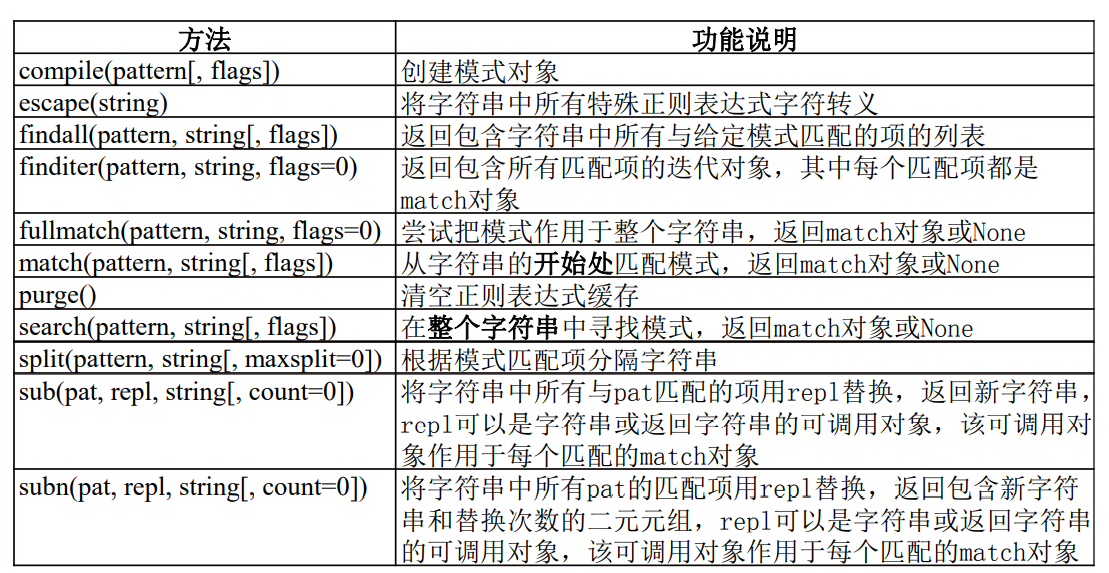
>>> import re #Import re module
>>> text = 'alpha. beta....gamma delta' #Test string
>>> re.split('[\. ]+', text) #Use the specified character as a separator
['alpha', 'beta', 'gamma', 'delta']
>>> re.split('[\. ]+', text, maxsplit=2) #Separated up to 2 times
['alpha', 'beta', 'gamma delta']
>>> re.split('[\. ]+', text, maxsplit=1) #Separated up to 1 time
['alpha', 'beta....gamma delta']
>>> pat = '[a-zA-Z]+'
>>> re.findall(pat, text) #Find all words
['alpha', 'beta', 'gamma', 'delta']
>>> pat = '{name}'
>>> text = 'Dear {name}...'
>>> re.sub(pat, 'Mr.Dong', text) #String substitution
'Dear Mr.Dong...'
>>> s = 'a s d'
>>> re.sub('a|s|d', 'good', s) #String substitution
'good good good'
>>> s = "It's a very good good idea"
>>> re.sub(r'(\b\w+) \1', r'\1', s) #Deal with continuous repeated words
"It's a very good idea"
>>> re.sub(r'((\w+) )\1', r'\2', s)
"It's a very goodidea"
>>> re.sub('a', lambda x:x.group(0).upper(), 'aaa abc abde')
#repl is a callable object
'AAA Abc Abde'
>>> re.sub('[a-z]', lambda x:x.group(0).upper(), 'aaa abc abde')
'AAA ABC ABDE'
>>> re.sub('[a-zA-z]', lambda x:chr(ord(x.group(0))^32), 'aaa
aBc abde')
#English letters are case interchangeable
'AAA AbC ABDE'
>>> re.subn('a', 'dfg', 'aaa abc abde') #Returns a new string and the number of substitutions
('dfgdfgdfg dfgbc dfgbde', 5)
>>> re.sub('a', 'dfg', 'aaa abc abde')
'dfgdfgdfg dfgbc dfgbde'
>>> re.escape('http://www.python.org ') # string escape
'http\\:\\/\\/www\\.python\\.org'
>>> example = 'Beautiful is better than ugly.'
>>> re.findall('\\bb.+?\\b', example) #A complete word beginning with the letter b
#Question mark here? Indicates a non greedy mode
['better']
>>> re.findall('\\bb.+\\b', example) #Matching results of greedy patterns
['better than ugly']
>>> re.findall('\\bb\w*\\b', example)
['better']
>>> re.findall('\\Bh.+?\\b', example) #The remainder of a word that does not begin with h and contains the letter h
['han']
>>> re.findall('\\b\w.+?\\b', example) #All words
['Beautiful', 'is', 'better', 'than', 'ugly']
>>> re.findall('\d+\.\d+\.\d+', 'Python 2.7.13')
#Find and return a number in the form of x.x.x
['2.7.13']
>>> re.findall('\d+\.\d+\.\d+', 'Python 2.7.13,Python 3.6.0')
['2.7.13', '3.6.0']
>>> s = '<html><head>This is head.</head><body>This is
body.</body></html>'
>>> pattern = r'<html><head>(.+)</head><body>(.+)</body></html>'
>>> result = re.search(pattern, s)
>>> result.group(1) #First sub mode
'This is head.'
>>> result.group(2) #Second sub mode
'This is body.'
Using regular expression objects
first compile the regular expression to generate a regular expression object using the compile() method of the re module, and then use the method provided by the regular expression object for string processing.
using compiled regular expression objects can improve string processing speed.
the match(string[, pos[, endpos]]) method of the regular expression object is used to search at the beginning of the string or at the specified position, and the pattern must appear at the beginning of the string or at the specified position;
the search(string[, pos[, endpos]]) method of regular expression object is used to search the whole string;
the findall(string[, pos[, endpos]]) method of the regular expression object is used to find a list of all strings that match the regular expression in the string.
>>> import re
>>> example = 'ShanDong Institute of Business and Technology'
>>> pattern = re.compile(r'\bB\w+\b') #Find words beginning with B
>>> pattern.findall(example) #Use the findall() method of the regular expression object
['Business']
>>> pattern = re.compile(r'\w+g\b') #Find words that end with the letter g
>>> pattern.findall(example)
['ShanDong']
>>> pattern = re.compile(r'\b[a-zA-Z]{3}\b')#Find 3 letter long words
>>> pattern.findall(example)
['and']Sub mode
Use () to represent a sub pattern. The contents in parentheses appear as a whole. For example, '(red) +' can match multiple repeated 'Red' such as' redred 'and' redred '.
>>> telNumber = '''Suppose my Phone No. is 0535-1234567,
yours is 010-12345678, his is 025-87654321.'''
>>> pattern = re.compile(r'(\d{3,4})-(\d{7,8})')
>>> pattern.findall(telNumber)
[('0535', '1234567'), ('010', '12345678'), ('025', '87654321')]
The match object is returned after the match method and search method of the regular expression object are successfully matched. The main methods of match object are:
group(): returns the content of one or more matching sub patterns
groups(): returns a tuple containing all matched sub schema contents
groupdict(): returns a dictionary containing all matched named sub schema contents
start(): returns the starting position of the specified sub mode content
end(): returns the previous position of the end position of the specified sub mode content
span(): returns a tuple containing the starting position and ending position of the specified sub mode content.
>>> m = re.match(r"(\w+) (\w+)", "Isaac Newton, physicist")
>>> m.group(0) #Returns the entire schema content
'Isaac Newton'
>>> m.group(1) #Return to the first sub mode content
'Isaac'
>>> m.group(2) #Returns the content of the second sub - mode
'Newton'
>>> m.group(1, 2) #Returns the contents of the specified multiple sub modes
('Isaac', 'Newton')