1, Spark cluster topology
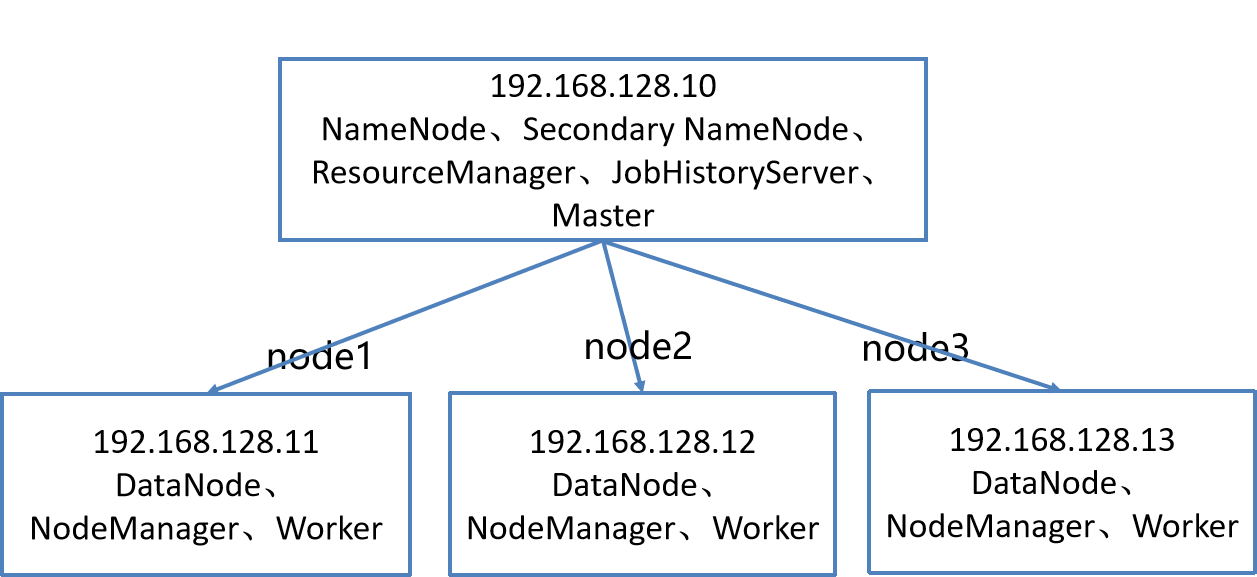
1.1 cluster scale
192.168.128.10 master 1.5G ~2G Memory, 20 G Hard disk NAT,1~2 Nuclear; 192.168.128.11 node1 1G Memory, 20 G Hard disk NAT,1 nucleus 192.168.128.12 node2 1G Memory, 20 G Hard disk NAT,1 nucleus 192.168.128.13 node3 1G Memory, 20 G Hard disk NAT,1 nucleus
1.2 Spark installation mode
1. Local mode
Install Spark on a node and run the program using local threads in a non distributed environment
2. Pseudo distributed
Spark single machine pseudo distributed has both Master and Worker processes on one machine
3. Fully distributed
The fully distributed mode is used for production and requires at least 3 ~ 4 machines, one of which is the Master node and deploys the Master, and the other node deploys the Worker
4. HA high availability mode
On the basis of full distribution, Master-slave backup is realized by Zookeeper
2, Spark installation configuration
2.1 Spark configuration file
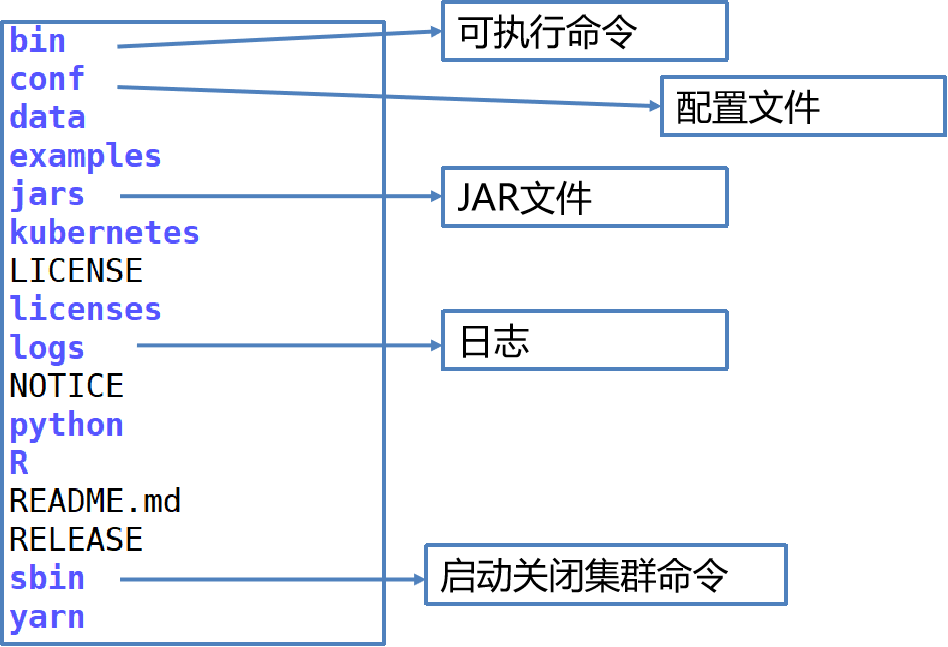
Data: data used in spark mllib;
Ec2: script deployed on Amazon cloud platform
Examples: example code;
Python: Python interface;
R: R interface
2.1.1 interpretation of configuration file

Template is a template
HADOOP_CONF_DIR: the path where the Hadoop configuration file is located. Spark needs to find relevant things in Hadoop, such as the address related to hdfs. For example, we may need to upload data or logs on it
SPARK_WORKER_INSTANCES: sets the worker process for each node
SPARK_WORKER_MEMORY: sets all the memory that the node can give to the executors
SPARK_WORKER_CORES: sets the number of cores used by this machine
SPARK_EXECUTOR_CORES: the number of cores used by the executor
SPARK_EXECUTOR_MEMORY: memory of each executor
Spark_WORKER_CORES: how many cores does each worker occupy and how many cores do we allocate to each virtual machine
SPARK_WORKER_INSTANCES: how many instances are there in each worker node
For example, if there are two INSTANCES and three nodes, there are six workers, which is equivalent to six HADOOP nodes
2.1.2 interpretation of configuration file

2.2 configuration steps
1. Upload spark-2.4.0-bin-hadoop 2.6.tgz to / opt directory and unzip it
tar -zxf /opt/spark-2.4.0-bin-hadoop2.6.tgz
2. Enter / opt / spark-2.4.0-bin-hadoop 2.6/conf
Copy slave.template:
cp slaves.template slaves vi slaves
Modify the slave, delete the localhost, and then add:
node1 node2 node3
3. Modify spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf vi spark-defaults.conf
add to:
spark.master spark://master:7077 spark.eventLog.enabled true spark.eventLog.dir hdfs://master:8020/spark-logs spark.history.fs.logDirectory hdfs://master:8020/spark-logs
4. Modify spark-env.sh
cp spark-env.sh.template spark-env.sh vi spark-env.sh
add to:
JAVA_HOME=/usr/java/jdk1.8.0_221-amd64 HADOOP_CONF_DIR=/opt/hadoop-3.1.4/etc/hadoop SPARK_MASTER_IP=master SPARK_MASTER_PORT=7077 SPARK_WORKER_MEMORY=512m SPARK_WORKER_CORES=1 SPARK_EXECUTOR_MEMORY=512m SPARK_EXECUTOR_CORES=1 SPARK_WORKER_INSTANCES=1
5. Start the Hadoop cluster and create a new directory in HDFS:
hdfs dfs -mkdir /spark-logs
6. Distribute Spark installation package to other nodes
scp -r /opt/spark-2.4.0-bin-hadoop2.6/ node1:/opt/ scp -r /opt/spark-2.4.0-bin-hadoop2.6/ node2:/opt/ scp -r /opt/spark-2.4.0-bin-hadoop2.6/ node3:/opt/
7. Configure Spark environment variables on all nodes
(master,node1,node2,node3)
vi /etc/profile
Add at the end of the document:
export SPARK_HOME=/opt/spark-2.4.0-bin-hadoop2.6 export PATH=$PATH:$SPARK_HOME/bin
Execute source /etc/profile to make the command effective
8. Start spark
Enter / opt / spark-2.4.0-bin-hadoop 2.6/sbin
implement
./start-all.sh
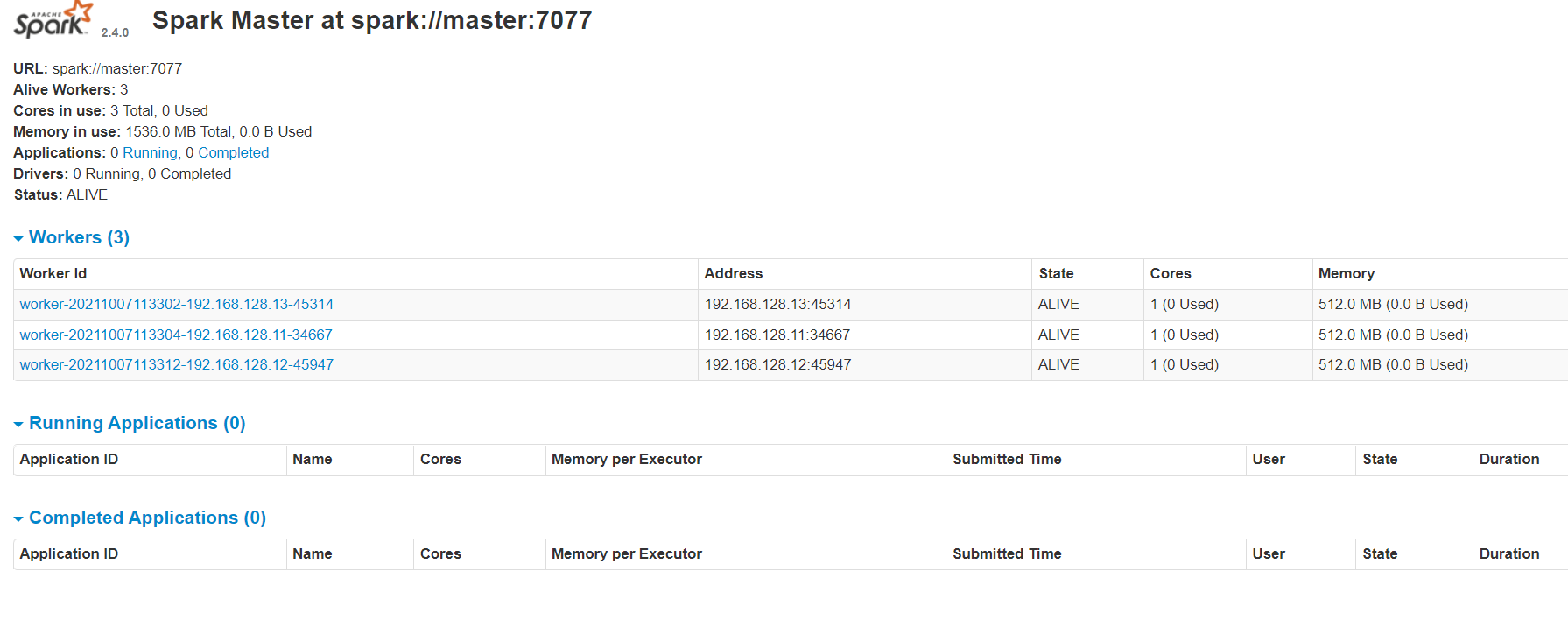
9. View client
http://master:8080
2.3 start and close Spark
Go to / usr / local / spark-2.4.0-bin-hadoop 2.6/
1. Start Spark
sbin/start-all.sh
2. Start log service
sbin/start-history-server.sh hdfs://master:8020/spark-logs
3. Turn off Spark
sbin/stop-all.sh sbin/stop-history-server.sh hdfs://master:8020/spark-logs
2.5. View client
Spark monitoring: http://master:8080