Basic introduction and configuration
Video link #Crazy God said sql

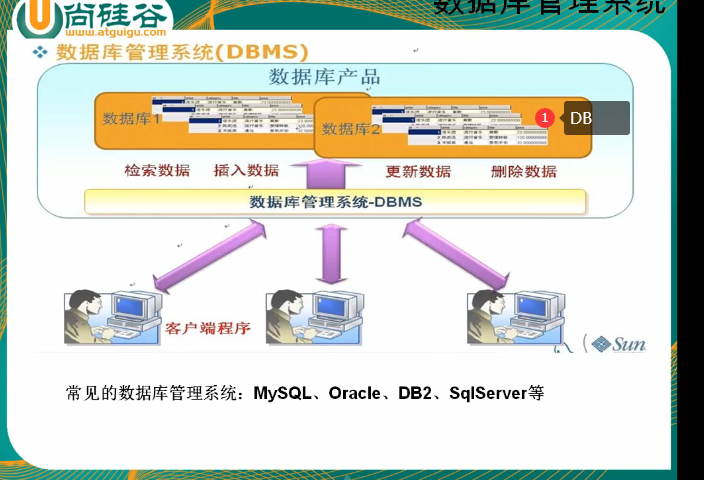
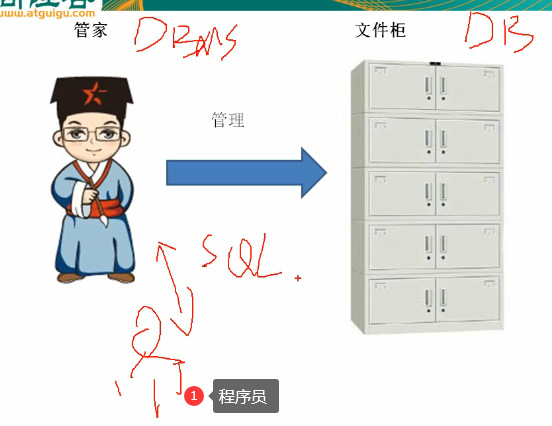


Query data storage place
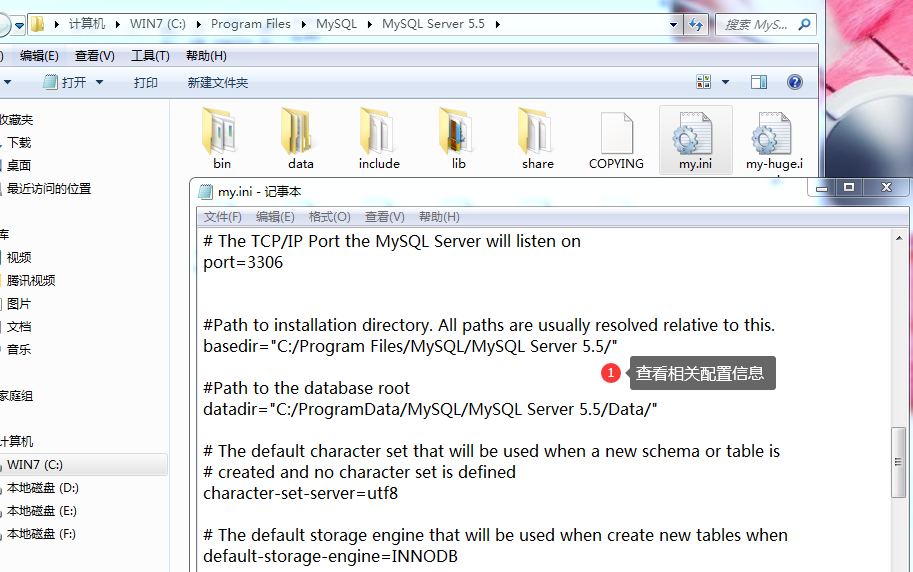
Start service + enter database management system
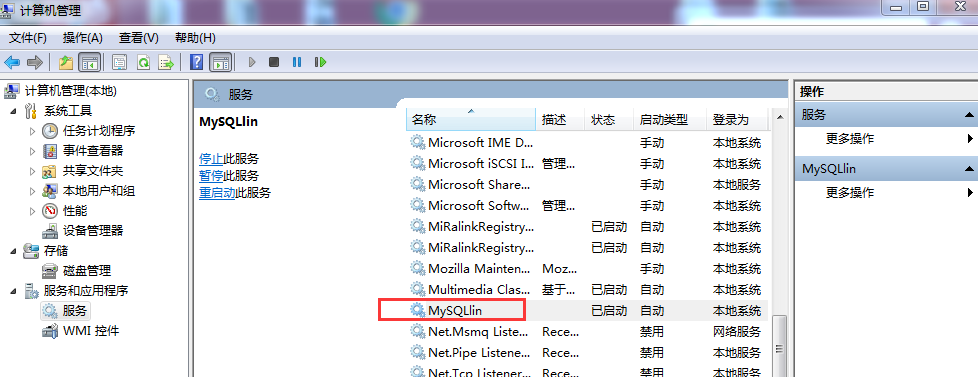
1 – start local mysql service
- computer management system
- command line
net stop/start mysqllin
2 – enter the management system with the password
Username root password 123456

Exit: exit /ctrl+c
Language part

Writing standard
- First write the statements after select and group by, and then supplement the others. The field after group by also appears after select
- Command to be executed; At the end of the sign, do not add; It means that you can wrap lines if you haven't finished writing
- When F9 executes the mission, the mouse selects which lines and which lines run, and F12 writes normally
- There are three ways to SELECT the 'field' in query: handwriting, SELECT *, handwriting and mouse punctuation
- Keywords uppercase, other lowercase SELECT 'name' from table1;
- After select, order by, having, you can use an alias (that is, change the field as of the original a into b, and then use b to have)
- Due to the execution order, if the table is aliased, it will not select the original table name
- where a IS NOT NULL
- select A from employee e, the general alias is not added as

DQL (Data Query Language): data query language - select
1. Basic query
#Advanced 1: basic query #Just view USE myemployees; DESC employees;#View all fields of the table SELECT hiredate,last_name FROM employees; SELECT * FROM employees; ##Check the constant pool, and select feels like print SELECT 100; SELECT "john";#Single and double quotation marks SELECT VERSION(); SELECT 100+80 AS 'sum'; SELECT last_name AS 'lastname','first_name' AS 'name' FROM employees;#You can add single and double quotation marks or not. If you want to add keywords, SELECT last_name ,first_name AS lastname, name FROM employees;#Wrong writing SELECT last_name ,first_name AS name FROM employees;#This is correct. Only the name is assigned SELECT last_name*12 AS name FROM employees;#It is also correct. It is equivalent to processing the query results and then outputting them (instead of searching 0) SELECT DISTINCT `department_id` FROM employees;#Remove the same fields ## Use of plus sign SELECT 100+90;#190 + in SQL only indicates addition SELECT "100"+90=190#Try to convert "" into int first. Success is int, otherwise it is 0 SELECT "hello"+90;#Treat characters as 0 + 90 = 90 SELECT NULL+0;#As long as one party is null, the result is null, which is the same in concat ##concat splicing uses the meaning of contact connection SELECT CONCAT(last_name ,first_name) AS full name FROM employees; SELECT `commission_pct` FROM employees; SELECT IFNULL(`commission_pct`,0) AS Bonus rate FROM employees; SELECT CONCAT(`commission_pct`,',',IFNULL(`commission_pct`,0)) AS Bonus rate FROM employees;#Two output columns merge into one
2. Query criteria where
#Advanced level 2: conditional query where -- - and or, like% _, between 100 and 200 [100,200],in,is null,is not null SELECT * FROM employees WHERE salary>12000; SELECT `last_name`,`manager_id` FROM employees WHERE `department_id`!=90; SELECT CONCAT(`first_name`,'-',`last_name`) AS full name,`salary`,`commission_pct` FROM employees WHERE `salary`>10000 AND `salary`<20000; SELECT `last_name` FROM employees WHERE last_name LIKE '%a%';#%Wildcard, indicating that there is any one before and after SELECT `last_name` FROM employees WHERE last_name LIKE '__st%';#One_ It means there is only one uncertain thing ahead SELECT `last_name` FROM employees WHERE last_name LIKE '_\_%';#\Indicates escape SELECT `salary`,last_name FROM employees WHERE salary IN (10000,20000);#The contents of the in list should be compatible. In means = and cannot be written in the list_ a ', this is like SELECT `last_name`,`commission_pct` FROM employees WHERE `commission_pct` IS NULL;#Cannot write = = null, unrecognized
3. Sort query
#Advanced level 3: sort query order by field ASC (ascending by default, the lower the larger) / desc SELECT `last_name`,`salary` FROM employees ORDER BY salary DESC; SELECT salary*12 AS Annual salary FROM employees ORDER BY Annual salary DESC; SELECT LENGTH(`last_name`),`last_name`FROM employees ORDER BY LENGTH(`last_name`) DESC; SELECT * FROM employees ORDER BY salary ASC,`manager_id` ASC;
4. Single line function
##1. Character function
/*length(" ")Number of bytes returned
concat(a,b)
upper(last_name),lower(first_name)
SELECT SUBSTR("1234567",5) AS output;#567
SELECT SUBSTR("12345678",5,2) AS output;#56 Specify character length
instr:Gets the index of the first occurrence of a substring
trim
lpad,rpad
replace
*/
SELECT CONCAT(UPPER(SUBSTRING(last_name,1,1)),"_",LOWER(SUBSTRING(last_name,2))) AS full name FROM employees;
SELECT INSTR("ssaaddcc","a") AS output;
SELECT TRIM(" I ") AS output;
SELECT TRIM("a" FROM "aaa I aaa") AS output;#I
SELECT LPAD("I",10,"*")AS output;#*********I filled 10 in total
SELECT LPAD("aaaa",2,"*")AS output;#aa
SELECT REPLACE("aabbbbbaa","aa","ww") AS output;#wwbbbbbww
##2. Mathematical function
/*
ceil:Round up and return the minimum integer select ceil (1.00) greater than or equal to the parameter= one
floor: Round down to return the smallest integer greater than or equal to the parameter
round: round(-1.7)=-2, regardless of negative sign, round first and then negative sign
round(1.346,2)=1.345 Keep and then round
truncate:truncate(1.699,1)=1.6
mod:Take mold, same as 10% 3
rand:Gets a random number and returns a decimal number between 0 and 1
*/
##3. Date function
/*
now: Return current date + time 2021-08-20 15:56:07 select now(); SELECT CURTIME(); SELECT CURDATE();
year:Return year SELECT YEAR(NOW());
month: Return month
day:Return day
hour:hour
minute:minute
second: second
datediff: Returns the number of days between two dates
date_format:Convert date to character
curdate:Returns the current date
str_to_date:Convert characters to dateselect str_ TO_ DATE("1998-3-2",'%Y-%c-%d') AS output;# 1998-03-02
datediff:Returns the number of days between two dates
monthname:Return month in English*/
SELECT DATE_FORMAT(`hiredate`,'%m month/%d day/%year')FROM employees;#April 3, 1992 00:00:00 April / March / year
##4. Other system functions
/*version The version of the current database server select version();
database Currently open database
user Current user
password('Character '): returns the password form of this character
md5('Character '): returns the md5 encrypted form of the character*/
##5. Process control function
/*
①if(Conditional expression, expression 1, expression 2): if the conditional expression is true, return expression 1; otherwise, return expression 2
②case Case 1 similar switch is used for equivalence calculation
case Variable or expression or field
when Constant 1 then value 1
when Constant 2 then value 2
...
else Value n
end
③case Case 2 is similar to if else for condition
case
when Condition 1 then value 1
when Condition 2 then value 2
...
else Value n
end*/
SELECT IF(10<5,"large","Small");#Small
#case 1
SELECT salary Original salary,`department_id`,
CASE `department_id`
WHEN 30 THEN salary*1.1
WHEN 40 THEN salary*1.5
ELSE salary
END AS New salary
FROM employees;
#Case case 2 if else is used for condition
SELECT salary Original salary,salary,
CASE
WHEN salary>20000 THEN 'A'
WHEN salary>15000 THEN 'B' #The condition is if else, naturally < 20000
ELSE 'C'
END AS Wage scale
FROM employees;
## 6. Grouping function
/*All of the following grouping functions are satisfied
1.(Used for statistics, also known as aggregation function). The previous operations above, such as salary*1.5, will return the information of each person (107 IDS). Here, the aggregation function only
Returns a number
2.sum And avg are generally used to deal with numerical types
max,min,count Can handle any data type
3.Null is ignored in the above grouping functions (any operation with null will become null)
4.Can be used with distinct to realize the statistics of de duplication
5. count(Field): count the number of non null values in this field. count(*)=107: count the number of rows in the result set. Note that count (any field) = 107 can be 107, which will be supplemented automatically
Efficiency:
MyISAM Storage engine, count(*) max
InnoDB Storage engine, count(*) and count(1) efficiency > count (field)
6.The fields queried together with the grouping function must be the fields that appear after group by
*/
/*
1,classification
max Maximum
min minimum value
sum and
avg average value
count Number of calculations*/
SELECT SUM(salary),MAX(salary) FROM employees;#691400.00 24000.00
SELECT SUM(DISTINCT salary),SUM(salary) FROM employees;
SELECT COUNT(salary) FROM employees;#105
SELECT COUNT(*) FROM employees;#107. If there is null in salary, the number of rows will not be calculated, so (*) is reliable
5. Group query
- ##Note: the field after group by also appears after select
- First write the statements after select and group by, and then supplement the others
- Key points of 3, 4 and 5 examples
# Grouping query /* select Grouping function, field after grouping from surface [where [filter criteria] group by Grouped fields [having Filter after grouping] [order by Sort list] ##be careful: 1.group by The following fields should also appear after select 2.First write the statements after select and group by, and then supplement the others 3.You can group by multiple fields separated by commas 4.Sorting can be supported 5.having After that, you can support aliases (that is, change the field as of the original a into b, and then use b to have) 2, Features: the data sources filtered by the two are different Use keywords Filtered tables position Filter before grouping where Original table In front of group by Filter after grouping having Results after grouping Behind group by */ SELECT AVG(salary) ,job_id FROM employees GROUP BY job_id; SELECT COUNT(*),location_id FROM employees GROUP BY location_id; #1. Query the average salary of each department with a character in the mailbox SELECT AVG(salary) ,`department_id`FROM employees WHERE `email` LIKE '%a%' GROUP BY `department_id`; #2. After grouping -- query which department has more than 2 employees SELECT COUNT(*),department_id FROM employees GROUP BY department_id HAVING COUNT(*)>2; #3. Query the work type number and maximum salary of employees with bonus of each work type whose maximum salary is > 12000 #The first step is to query the maximum salary of employees with bonus in each type of work SELECT MAX(salary),job_id FROM employees WHERE `commission_pct` IS NOT NULL GROUP BY department_id #Further > 12000 job number and maximum wage HAVING MAX(salary)>12000; #4. Query the minimum wage of each leader with leader number > 102 and the leader number with leader number > 5000 and their minimum wage ##The first step is to write the foundation SELECT `manager_id`,MIN(`salary`) FROM employees GROUP BY `manager_id`; ##Step 2, conditions SELECT `manager_id`,MIN(`salary`) FROM employees WHERE `manager_id`>102 GROUP BY `manager_id`; ##The third step is to add conditions SELECT `manager_id`,MIN(`salary`) FROM employees WHERE `manager_id`>102 GROUP BY `manager_id` HAVING MIN(salary)>5000; ##5. Average salary of each department and type of work SELECT AVG(`salary`),`manager_id`,`job_id` FROM employees GROUP BY `manager_id`,`job_id`;

6. Connection query
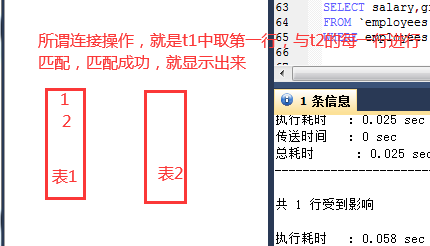
When querying two tables, you must add join conditions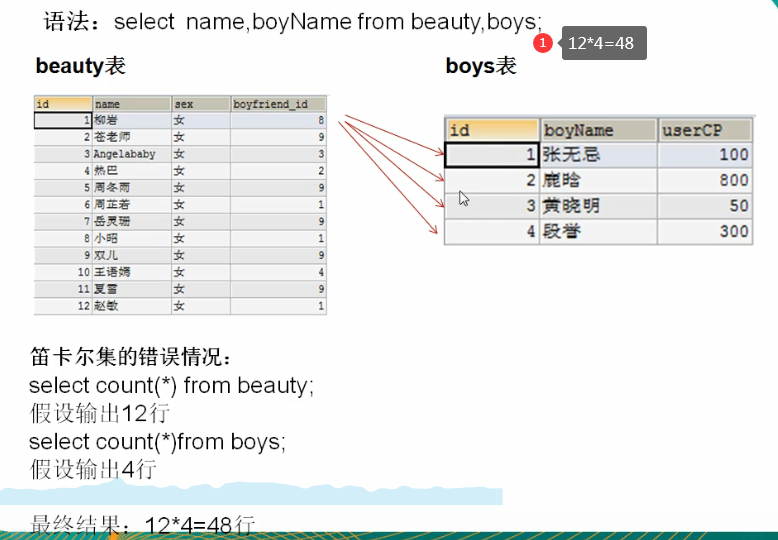
sql92 connection
Classification by age: sql92: equivalence non-equivalence Self connection It also supports some external connections (for oracle,sqlserver,mysql (not supported) 1, Meaning When multiple table fields are involved in the query, you need to use multi table connection select Field 1, field 2 from Table 1, table 2,...; Cartesian product: when querying multiple tables, no valid connection conditions are added, resulting in complete connection of all rows in multiple tables How to solve: add a valid connection condition 1,Equivalent connection Syntax: select Query list from Table 1 aliases,Table 2 aliases where Table 1.key=Table 2.key [and [filter criteria] [group by [group fields] [having Filter after grouping] [order by Sort field] characteristic: ① It is generally a table alias ②The order of multiple tables can be changed ③n Table connection requires at least n-1 Multiple connection conditions ④The result of equivalent connection is the intersection of multiple tables 2,Non equivalent connection Syntax: select Query list from Table 1 aliases,Table 2 aliases where Non equivalent connection conditions [and [filter criteria] [group by [group fields] [having Filter after grouping] [order by Sort field] 3,Self connection Syntax: select Query list from Table alias 1,Table alias 2 where Equivalent connection conditions [and [filter criteria] [group by [group fields] [having Filter after grouping] [order by Sort field] */ #1. Equivalent connection SELECT NAME,boyName FROM boys,beauty WHERE beauty.`boyfriend_id` =boys.id; SELECT last_name,e.job_id,job_title FROM employees e,jobs j WHERE e.job_id =j.job_id AND e.`commission_pct` IS NOT NULL; #Query the number of departments in each city SELECT COUNT(*), city FROM departments, locations WHERE departments.`location_id`=locations.`location_id` GROUP BY city; #2. Non equivalent connection #Query employee salary and salary level SELECT salary,grade_level FROM `employees`,`job_grades` j WHERE salary BETWEEN j.`lowest_sal` AND j.`highest_sal`; #3. Self connection #(name a table into multiple tables and use them as different tables) SELECT e.employee_id, e.last_name,m.employee_id,m.last_name, FROM employees e, employees m WHERE e.`manager_id`=m.`employee_id`;
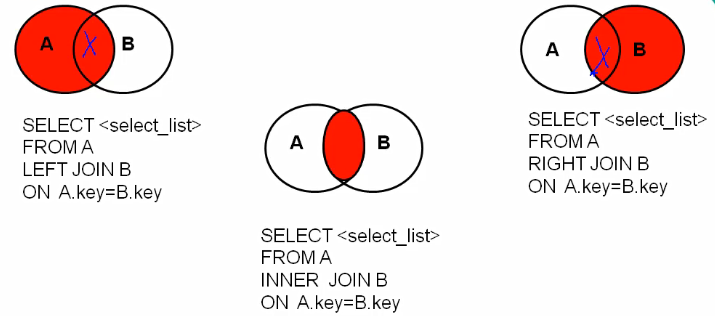
sql99 connection [recommended]
==
Case 1:
select a,b from table A and table B. when the two fields after the select are from different tables, join query should be used
Case 2: the following code block, classic==
#3. Query the employee number, name and salary of employees in each department whose salary is higher than the average salary of the Department #① Query the average salary of each department SELECT AVG(salary),department_id FROM employees GROUP BY department_id #② ① connect the result set and the employees table for filtering SELECT employee_id,last_name,salary,e.department_id FROM employees e INNER JOIN ( SELECT AVG(salary) ag,department_id FROM employees GROUP BY department_id ) ag_dep ON e.department_id = ag_dep.department_id WHERE salary>#3. Query the employee number, name and salary of employees in each department whose salary is higher than the average salary of the Department #① Query the average salary of each department SELECT AVG(salary),department_id FROM employees GROUP BY department_id #② ① connect the result set and the employees table for filtering SELECT employee_id,last_name,salary,e.department_id FROM employees e INNER JOIN ( SELECT AVG(salary) ag,department_id FROM employees GROUP BY department_id ) ag_dep ON e.department_id = ag_dep.department_id WHERE salary>ag_dep.ag ; ;#Here ag_dep.ag was originally grouped by department. It may be 10 rows, but salary is 107 rows, which is difficult to compare. Therefore, you need to connect the query and splice the employees and the following ones, so salary > ag_dep.ag, you can
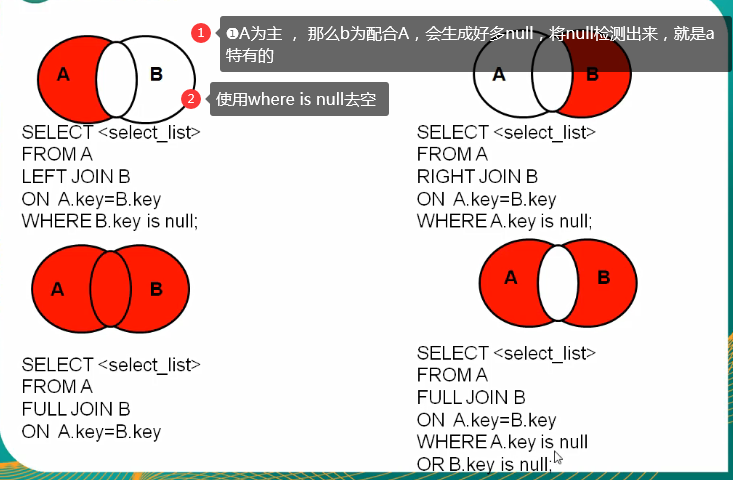
- Inner join to query the intersection of two tables
- External connection: query whether a table has one or not, and the relationship between the two tables is master-slave (a row of a traverses all of b. if not, the current behavior of a is null; if yes, it is internal connection). Therefore, external connection includes internal connection
- Which department to query is the main table, and which department has no employees, so the Department is the main table
sql99[[recommended] Inner connection equivalence non-equivalence Self connection External connection Left outer Right outer Total external( mysql (not supported) Cross connect
/* 4, SQL99 syntax Syntax: select Query list from Table 1 aliases Connection type join table 2 alias on Connection conditions [Connection type] Yes inner inner Can be omitted left [outer][outer]Can be omitted right[outer] full [outer] cross Post append where Screening conditions group by Group list having Filtering after grouping order by Sort list limit Clause; 1,Inner connection Classification: Equivalent connection Non equivalent connection Self connection characteristic: ①The order of tables can be changed ②Result of inner join = intersection of multiple tables ③n Table connection requires at least n-1 connection conditions 2,External connection Syntax: select Query list from Table 1 aliases left|right|full[outer] join Table 2 alias on connection conditions where Screening conditions group by Group list having Filtering after grouping order by Sort list limit Clause; characteristic: ①Query result = all rows in the master table. If the slave table matches it, the matching row will be displayed. If there is no matching row in the slave table, null will be displayed ②left join The main table is on the left, and the main table is on the right ③full join Both sides are the main table, which is composed of three parts, intersection, the differences of a and b It is generally used to query the remaining mismatched rows except the intersection part 3,Cross connect Syntax: select Query list from Table 1 aliases cross join Table 2 alias; characteristic: Similar to Cartesian product Left table 11, right table 4, output 44 */ #1. Inner connection SELECT last_name, department_name FROM employees e INNER JOIN departments d ON e.`department_id` = d.`department_id` INNER JOIN jobs j ON e.`job_id`=j.`job_id`#It is equivalent to that the above two tables have formed a large table, and then connected with this table WHERE e.`last_name` LIKE "%e%"; #2. External connection #Left outer SELECT b.name, bo.* FROM beauty b LEFT JOIN boys bo ON b.`boyfriend_id`=bo.`id`#At this point, the boys table has been expanded into a table with the same rows as beauty WHERE bo.id IS NULL; #Right outer SELECT b.name, bo.* FROM boys bo RIGHT JOIN beauty b ON b.`boyfriend_id`=bo.`id`#At this point, the boys table has been expanded into a table with the same rows as beauty WHERE bo.id IS NULL; #Total external #3. Cross connect
7. Sub query
- The subquery looks complex. Write it in separate steps and finally integrate it into ()
- Subqueries are usually focused on where and having, and less on others

1, Meaning Nested inside other statements select Statements are called subqueries or intra queries, The outer statement can be insert,update,delete,select Wait, general select There are many external statements If it's outside select Statement, this statement is called an external query or a main query characteristic: 1,Subqueries are placed in parentheses 2,Subqueries can be placed in from Back select Back where Back having Behind, but generally on the right side of the condition 3,The sub query takes precedence over the main query, which uses the execution results of the sub query 4,Sub queries are divided into the following two categories according to the number of rows in the query results: ① single-row subqueries The result set has only one row Generally used with single line operators:> < = <> >= <= Illegal use of sub query: a,The result of a subquery is a set of values b,The result of subquery is null ② Multiline subquery The result set has multiple rows Generally used with multiline operators: any,all,in,not in in: It belongs to any one of the sub query results any and all It can often be replaced by other queries, any: How about any one? It can be used min,max replace 2, Classification 1,Press where it appears select After: Only scalar subqueries are supported from After: Table subquery where or having After: ☆ scalar subquery ☆ Column subquery ☆Multiple rows and one column Row subquery Multi row and multi column exists After: scalar subquery Column subquery Row subquery Table subquery 2,Rows and columns by result set Scalar subquery (single row subquery): the result set is one row and one column Column subquery (multi row subquery): the result set is multiple rows and one column Row sub query: the result set is multi row and multi column Table subquery: the result set is multi row and multi column */ 3, Example 1. scalar subquery WHERE or HAVING behind 1,scalar subquery Case: query the name and salary of the minimum wage employee ①minimum wage SELECT MIN(salary) FROM employees ②Query the employee's name and salary and ask for salary=① SELECT last_name,salary FROM employees WHERE salary=( SELECT MIN(salary) FROM employees ); ##1. Whose salary is higher than Abel's? #-a - query Abel's salary, single line, single column SELECT salary FROM employees WHERE last_name ="Abel"; #-b - query employees and meet the conditions SELECT * FROM employees WHERE salary>( SELECT salary FROM employees WHERE last_name ="Abel" ); ##2. The subquery () in parentheses returns scalar SELECT last_name,job_id,salary FROM employees WHERE job_id=( SELECT job_id FROM employees WHERE employee_id=141) AND salary>( SELECT salary FROM employees WHERE employee_id=143); ##3. Query the Department id whose minimum wage is greater than the minimum wage of department No. 50 and its minimum wage SELECT MIN(salary) FROM employees WHERE department_id =50; SELECT MIN(salary),department_id FROM employees GROUP BY department_id; #screen SELECT MIN(salary),department_id FROM employees GROUP BY department_id HAVING MIN(salary)>( SELECT MIN(salary) FROM employees WHERE department_id =50 ); 2,Column subquery Case: query the names of all employees who are leaders ①Query the of all employees manager_id SELECT manager_id FROM employees ②Query name, employee_id belong to①A of the list SELECT last_name FROM employees WHERE employee_id IN( SELECT manager_id FROM employees ); ##1. Return to location_id is the name of all employees in the Department in 1400 or 1700 SELECT department_id FROM departments WHERE location_id=1400 OR location_id=1700 SELECT `last_name`,department_id FROM employees WHERE department_id IN ( SELECT department_id FROM departments WHERE location_id=1400 OR location_id=1700 ); 3.Table subquery,WHERE Harsh conditions SELECT * FROM employees WHERE (employee_id,salary)=( SELECT MIN(employee_id),MAX(salary) FROM employees ); # Put in select #Query the Department name with employee No. = 102 SELECT ( SELECT department_name FROM departments d INNER JOIN employees e ON d.department = e.department_id WHERE e.employee_id=102 ) ; III FROM behind /* The sub query results must be aliased to act as a table */ #Case: query the salary grade of the average salary of each department #① Query the average salary of each department SELECT AVG(salary),department_id FROM employees GROUP BY department_id SELECT * FROM job_grades; #② Connect the result set of ① with the job_grades table, filter criteria, average salary between lowest_sal and highest_sal SELECT ag_dep.*,g.`grade_level` FROM ( SELECT AVG(salary) ag,department_id FROM employees GROUP BY department_id ) ag_dep INNER JOIN job_grades g ON ag_dep.ag BETWEEN lowest_sal AND highest_sal; III EXISTS Later (related sub query) SELECT department_name FROM departments d WHERE EXISTS( SELECT * FROM employees e WHERE d.`department_id`=e.`department_id` ); #Case 2: query the boyfriend information without a girlfriend #in SELECT bo.* FROM boys bo WHERE bo.id NOT IN( SELECT boyfriend_id FROM beauty ) #exists SELECT bo.* FROM boys bo WHERE NOT EXISTS( SELECT boyfriend_id FROM beauty b WHERE bo.`id`=b.`boyfriend_id` );
8. Paging query (widely used)
#Advanced 8: paging query ★
/*
Application scenario: when one page of data to be displayed is incomplete, you need to submit sql requests in pages. For example, 10 pieces of information are displayed to the customer first, and then 10 pieces are displayed
Syntax:
select Query list
from surface
[join type join Table 2
on Connection conditions
where Screening conditions
group by Grouping field
having Filtering after grouping
order by Sorted fields]
limit [offset,]size;
offset The starting index of the entry to display (starting from 0)
size Number of entries to display
characteristic:
①limit Statement is placed at the end of the query statement
②formula
Number of pages to display page, number of entries per page size
select Query list
from surface
limit (page-1)*size,size;
size=10
page
1 0
2 10
3 20
*/
#Case 1: query the first five employee information
SELECT * FROM employees LIMIT 0,5;
SELECT * FROM employees LIMIT 5;
#Case 2: query Article 11 - Article 25
SELECT * FROM employees LIMIT 10,15;
#Case 3: the top 10 employees with bonus and higher salary are displayed
SELECT
*
FROM
employees
WHERE commission_pct IS NOT NULL
ORDER BY salary DESC
LIMIT 10 ;
9. Joint query
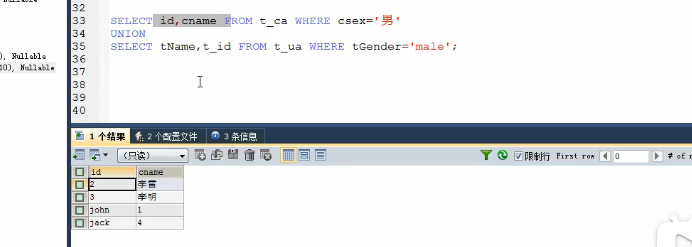
#Advanced 9: joint query /* union Union merge: merge the results of multiple query statements into one result Syntax: Query statement 1 union Query statement 2 union ... Application scenario: When the results to be queried come from multiple tables, and multiple tables have no direct connection relationship, but the query information is the same Features: ★ 1,The number of query columns of multiple query statements is required to be consistent! 2,The type and order of each column of the query requiring multiple query statements should be consistent 3,union Keyword is de duplicated by default (the information of the same field is automatically de duplicated). If union all is used, duplicate items can be included */ #Imported case: query employee information with department number > 90 or mailbox containing a SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90; SELECT * FROM employees WHERE email LIKE '%a%' UNION SELECT * FROM employees WHERE department_id>90; #Case: query the male information of Chinese users and the middle-aged male user information of foreign users SELECT id,cname FROM t_ca WHERE csex='male' UNION ALL SELECT t_id,tname FROM t_ua WHERE tGender='male';
DML (data manipulation language): data manipulation language - insert,update,delete
#DML language /* Data operation language: Inserting: insert ing Modify: update Delete: delete */
Inserting: insert ing
#1, Insert statement
SELECT * FROM beauty;
#1. The type of the inserted value should be consistent or compatible with the type of the column
INSERT INTO beauty(id,NAME,sex,borndate,phone,photo,boyfriend_id)
VALUES(13,'Tang Yixin','female','1990-4-23','1898888888',NULL,2);
#2. Non nullable columns must insert values. How do nullable columns insert values?
INSERT INTO beauty(id,NAME,sex,borndate,phone,photo,boyfriend_id)
VALUES(13,'Tang Yixin','female','1990-4-23','1898888888',NULL,2);
#3. Can the sequence of columns be changed
INSERT INTO beauty(NAME,sex,id,phone)
VALUES('Jiang Xin','female',16,'110');
INSERT INTO beauty
VALUES(18,'Fei Zhang','male',NULL,'119',NULL,NULL);
#Mode 2:
/*
Syntax:
insert into Table name
set Column name = value, column name = value
*/
INSERT INTO beauty
SET id=19,NAME='Liu Tao',phone='999';
#Two ways: big pk ★
#1. Method 1 supports inserting multiple rows, while method 2 does not
INSERT INTO beauty
VALUES(23,'Tang Yixin 1','female','1990-4-23','1898888888',NULL,2)
,(24,'Tang Yixin 2','female','1990-4-23','1898888888',NULL,2)
,(25,'Tang Yixin 3','female','1990-4-23','1898888888',NULL,2);
#2. Method 1 supports sub query, while method 2 does not
INSERT INTO beauty(id,NAME,phone)
SELECT id,boyname,'1234567'#Insert the results of the subquery into the table
FROM boys WHERE id<3;
Modify: update
#2, where should be added to the modified statement, otherwise all the statements will be modified /* 1.Record of modification order table ★ Syntax: update Table name set Column = new value, column = new value where Screening conditions; 2.Modify multi table records [ supplement ] Syntax: sql92 Syntax: update Table 1 aliases, table 2 aliases set Column = value where Connection conditions and Screening conditions; sql99 Syntax: update Table 1 aliases inner|left|right join Table 2 aliases on Connection conditions set Column = value where Screening conditions; */ #1. Record of modification sheet UPDATE beauty SET beauty.`phone`='199999998', boyfriend_id=11 WHERE beauty.`name` LIKE '%Tang%'; #2. Modify multi table records #Case 1: modify the mobile phone number of Zhang Wuji's girlfriend to 114 UPDATE boys bo INNER JOIN beauty b ON bo.`id`=b.`boyfriend_id`#Sir, make a big watch and set again SET b.`phone`='119',bo.`userCP`=1000 WHERE bo.`boyName`='zhang wuji';
Delete: delete
#3, Delete statement
/*
Method 1: delete
Syntax:
1,Deletion of single table [★]
delete from Table name where filter criteria
2,Deletion of multiple tables [supplement]
sql92 Syntax:
delete Aliases for table 1, aliases for table 2
from Table 1 aliases, table 2 aliases
where Connection conditions
and Screening conditions;
sql99 Syntax:
delete Aliases for table 1, aliases for table 2
from Table 1 aliases
inner|left|right join Table 2 alias on connection conditions
where Screening conditions;
Mode 2: truncate
Syntax: truncate table name;
*/
#Method 1: delete
#1. Deleting a single table
#Case: delete the goddess information whose mobile phone number ends with 9
DELETE FROM beauty WHERE phone LIKE '%9';
SELECT * FROM beauty;
#2. Deleting multiple tables
#Case: delete the information of Zhang Wuji's girlfriend
DELETE b
FROM beauty b
INNER JOIN boys bo ON b.`boyfriend_id` = bo.`id`
WHERE bo.`boyName`='zhang wuji';
#Case: delete Huang Xiaoming's information and his girlfriend's information
DELETE b,bo
FROM beauty b
INNER JOIN boys bo ON b.`boyfriend_id`=bo.`id`
WHERE bo.`boyName`='Huang Xiaoming';
#Method 2: truncate statement
#Case: delete the male god information with charm value > 100
TRUNCATE TABLE boys ;
#delete pk truncate
/*
1.delete The where condition can be added, but the truncate condition cannot be added
2.truncate Delete, high efficiency, lost
3.If there are self growing columns in the table to be deleted,
If you use delete to delete and then insert data, the value of the growth column starts from the breakpoint. For example, there are 5 data in the table before deletion. After all deletion, add insert data, starting from 6
After truncate is deleted, the data is inserted, and the value of the growing column starts from 1. For example, there are 5 data in the table before deletion. After all data are deleted, insert data is added, starting from 1
4.truncate There is no return value for deletion, and there is a return value for delete
5.truncate Deleting cannot be rolled back. Deleting can be rolled back
*/
SELECT * FROM boys;
DELETE FROM boys;
TRUNCATE TABLE boys;
INSERT INTO boys (boyname,usercp)
VALUES('Fei Zhang',100),('Liu Bei',100),('Guan Yunchang',100);
DDL (data definition language): data definition language - create,drop,alter
1. Warehouse management + 2. Table management
The name of the library cannot be changed. The table can
#DDL /* Data definition language Library and table management 1, Library management Create, modify, delete 2, Table management Create, modify, delete Create: create Modify: alter Deleting: drop */ #1, Library management #1. Library creation /* Syntax: create database [if not exists]Library name; */ #Case: creating library Books CREATE DATABASE IF NOT EXISTS books ; #2. Library modification RENAME DATABASE books TO New library name; #Change the character set of the library ALTER DATABASE books CHARACTER SET gbk; #3. Library deletion DROP DATABASE IF EXISTS books; #2, Table management #1. Table creation ★ /* Syntax: create table Table name( Column name column type [(length) constraint], Column name column type [(length) constraint], Column name column type [(length) constraint], ... Column name column type [(length) constraint] ) */ #Case: creating table Book CREATE TABLE book( id INT,#number bName VARCHAR(20),#Book name price DOUBLE,#Price authorId INT,#Author number publishDate DATETIME#Publication date ); DESC book; #1. Create table author CREATE TABLE IF NOT EXISTS author( id INT, au_name VARCHAR(20), nation VARCHAR(10) ) DESC author; #2. Modification of table /* grammar alter table Table name add|drop|modify|change column Column name [column type constraint]; */ #① Modify column name ALTER TABLE book CHANGE COLUMN publishdate pubDate DATETIME; #② Modify the type or constraint of the column ALTER TABLE book MODIFY COLUMN pubdate TIMESTAMP; #③ Add new column ALTER TABLE author ADD COLUMN annual DOUBLE; #④ Delete column ALTER TABLE book_author DROP COLUMN annual; #⑤ Modify table name ALTER TABLE author RENAME TO book_author; DESC book; #3. Deletion of table DROP TABLE IF EXISTS book_author; SHOW TABLES; #4. Table replication #4.1. Copy table structure only CREATE TABLE copy LIKE author; #4.2. Copy table structure + data CREATE TABLE copy2 SELECT * FROM author; #4.3. Copy only part of the data CREATE TABLE copy3 SELECT id,au_name FROM author WHERE nation='China'; #4.4. Copy only some fields CREATE TABLE copy4 SELECT id,au_name FROM author WHERE 0;#No data
2. Data type
3. Common constraints
#Common constraints /* Meaning: a restriction used to restrict the data in a table in order to ensure the accuracy and reliability of the data in the table Classification: Six constraints NOT NULL: Non empty, used to ensure that the value of this field cannot be empty Such as name, student number, etc DEFAULT:Default, used to ensure that the field has a default value Like gender PRIMARY KEY:Primary key, which is used to ensure that the value of this field is unique and non empty Such as student number, employee number, etc UNIQUE:Unique. It is used to ensure that the value of this field is unique. It can be blank Like seat number CHECK:Check constraints [not supported in mysql] Such as age, gender FOREIGN KEY:The foreign key is used to restrict the relationship between two tables and ensure that the value of this field must come from the value of the associated column of the main table When adding a foreign key constraint from the table, it is used to reference the value of a column in the main table For example, the major number of the student table, the department number of the employee table, and the type of work number of the employee table When to add constraints: 1.When creating a table 2.When modifying a table Add classification of constraints: Column level constraints: The six constraints are syntactically supported, but foreign key constraints have no effect Table level constraints: Except for non empty and default, all others are supported Comparison between primary key and unique: Whether uniqueness is allowed to be null. How many tables can there be in a table? Whether combination is allowed Primary key √ × At most 1 √, but not recommended only √ √ There can be multiple √, but it is not recommended Foreign key: 1,Requires a foreign key relationship to be set in the slave table 2,The type of the foreign key column of the slave table and the type of the associated column of the master table are required to be consistent or compatible, and the name is not required 3,The associated column of the main table must be a key (usually a primary key or unique) 4,When inserting data, insert the master table first and then the slave table When deleting data, delete the secondary table first, and then the primary table */ CREATE TABLE Table name( Field name field type column level constraint, Field name field type, Table level constraints ) CREATE DATABASE students; #1, Add constraints when creating tables #1. Add column level constraints /* Syntax: You can append constraint type directly after field name and type. Only default, non empty, primary key and unique are supported */ USE students; DROP TABLE stuinfo; CREATE TABLE stuinfo( id INT PRIMARY KEY,#Primary key stuName VARCHAR(20) NOT NULL UNIQUE,#Non empty gender CHAR(1) CHECK(gender='male' OR gender ='female'),#inspect seat INT UNIQUE,#only age INT DEFAULT 18,#Default constraint majorId INT REFERENCES major(id)#Foreign key ); CREATE TABLE major( id INT PRIMARY KEY, majorName VARCHAR(20) ); #View all indexes in stuinfo, including primary key, foreign key and unique key SHOW INDEX FROM stuinfo; #2. Add table level constraints /* Syntax: at the bottom of each field [constraint Constraint name] constraint type (field name) */ DROP TABLE IF EXISTS stuinfo; CREATE TABLE stuinfo( id INT, stuname VARCHAR(20), gender CHAR(1), seat INT, age INT, majorid INT, CONSTRAINT pk PRIMARY KEY(id),#Primary key CONSTRAINT uq UNIQUE(seat),#Unique key CONSTRAINT ck CHECK(gender ='male' OR gender = 'female'),#inspect CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id)#Foreign key ); SHOW INDEX FROM stuinfo; #Common writing method: ★ CREATE TABLE IF NOT EXISTS stuinfo( id INT PRIMARY KEY, stuname VARCHAR(20), sex CHAR(1), age INT DEFAULT 18, seat INT UNIQUE, majorid INT, CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id) ); #2, Add constraints when modifying tables /* 1,Add column level constraints alter table Table name modify column field name field type new constraint; 2,Add table level constraints alter table Table name add [constraint name] constraint type (field name) [reference of foreign key]; */ DROP TABLE IF EXISTS stuinfo; CREATE TABLE stuinfo( id INT, stuname VARCHAR(20), gender CHAR(1), seat INT, age INT, majorid INT ) DESC stuinfo; #1. Add a non empty constraint ALTER TABLE stuinfo MODIFY COLUMN stuname VARCHAR(20) NOT NULL; #2. Add default constraint ALTER TABLE stuinfo MODIFY COLUMN age INT DEFAULT 18; #3. Add primary key #① Column level constraint ALTER TABLE stuinfo MODIFY COLUMN id INT PRIMARY KEY; #② Table level constraints ALTER TABLE stuinfo ADD PRIMARY KEY(id); #4. Add unique #① Column level constraint ALTER TABLE stuinfo MODIFY COLUMN seat INT UNIQUE; #② Table level constraints ALTER TABLE stuinfo ADD UNIQUE(seat); #5. Add foreign keys ALTER TABLE stuinfo ADD CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id); #3, Delete constraints when modifying tables #1. Delete non empty constraint ALTER TABLE stuinfo MODIFY COLUMN stuname VARCHAR(20) NULL; #2. Delete default constraint ALTER TABLE stuinfo MODIFY COLUMN age INT ; #3. Delete primary key ALTER TABLE stuinfo DROP PRIMARY KEY; #4. Delete unique ALTER TABLE stuinfo DROP INDEX seat; #5. Delete foreign keys ALTER TABLE stuinfo DROP FOREIGN KEY fk_stuinfo_major; SHOW INDEX FROM stuinfo;
TCL (Transaction Control Language): transaction control language - commit,rollback
SQL index
Tree understanding
Index video

- An index is a data structure that helps Mysql obtain data efficiently
- In RDBMS, the index is stored on the hard disk.
innodb storage engine supports b+tree and hash data structures
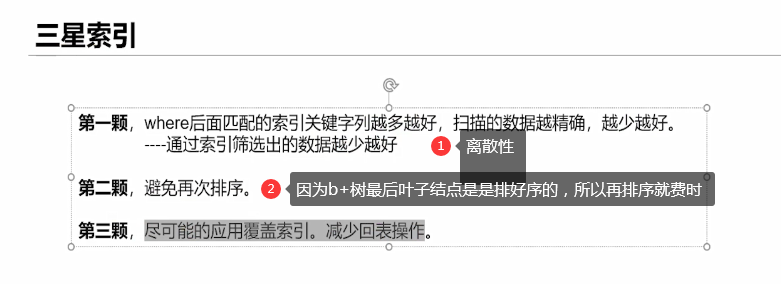
Characteristics of index: 1. Discrete type 2. Leftmost matching principle
1. B + tree data structure
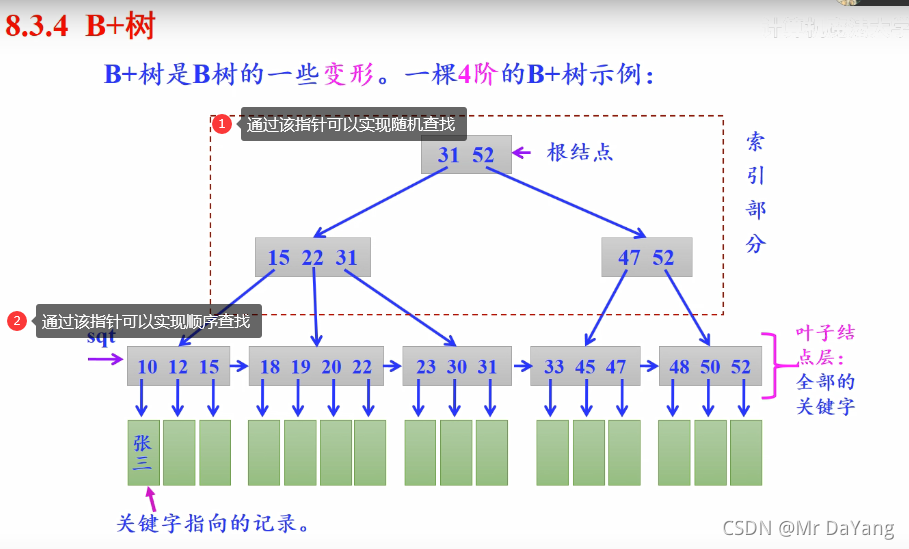
b tree stores keyword + data area + pointer, and b + tree stores keyword + pointer, so b + tree is wider and shorter.
Why does mysql use b+tree for indexing?
1. The database and table scanning based on index has strong ability, because all data is in the leaf node
2. The search data is more stable. You must go to the leaf node to find the datat, while the b tree node saves the keyword + data area + pointer
3. The relative number of IO reads and writes is reduced. The b + tree stores keywords + pointers, and the more keywords to be found when reading into memory at one time
2. Strong ability to sort based on index. For example, to find information about people aged 18-22, first find 18 by random search, and then find 22 by order, which is very fast
2. Storage engine
Myisam, the index structure and data are stored in two files respectively
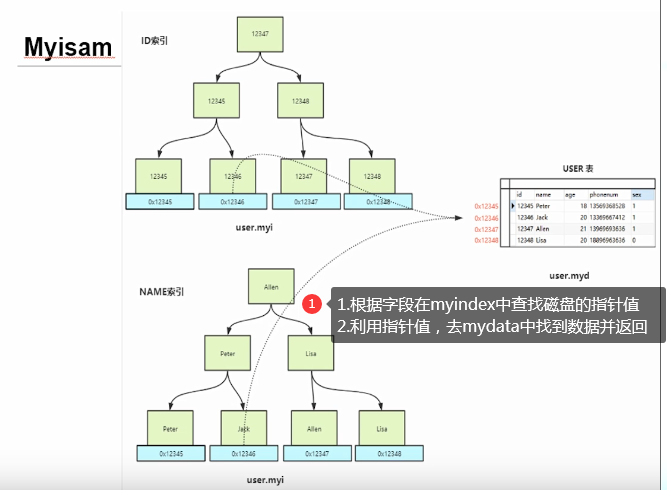
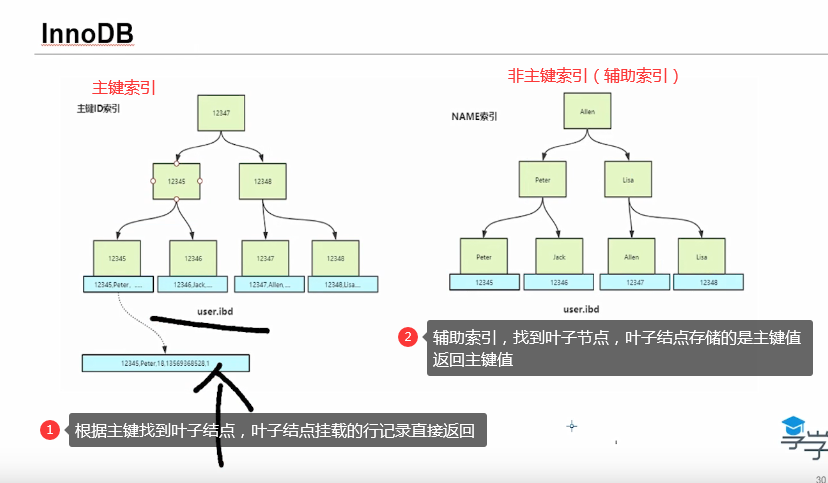
InnoDB
InnoDB, the index structure and data are only stored in one file. ibd
In lnnoDB engine, only the primary key is a clustered index, and other indexes are non clustered indexes.
The non clustered index returns the current keyword and primary key value. Use the primary key value to search the primary key index, and then return the row record
3. The disadvantage of creating your own primary key is not shown?
Because the leaf node of the primary key index mounts row records, mysql will automatically create a hidden primary key _rowid (int 6byte) when it does not create a primary key
1. Waste of resources int 6byte
2. It will change row lock into table lock
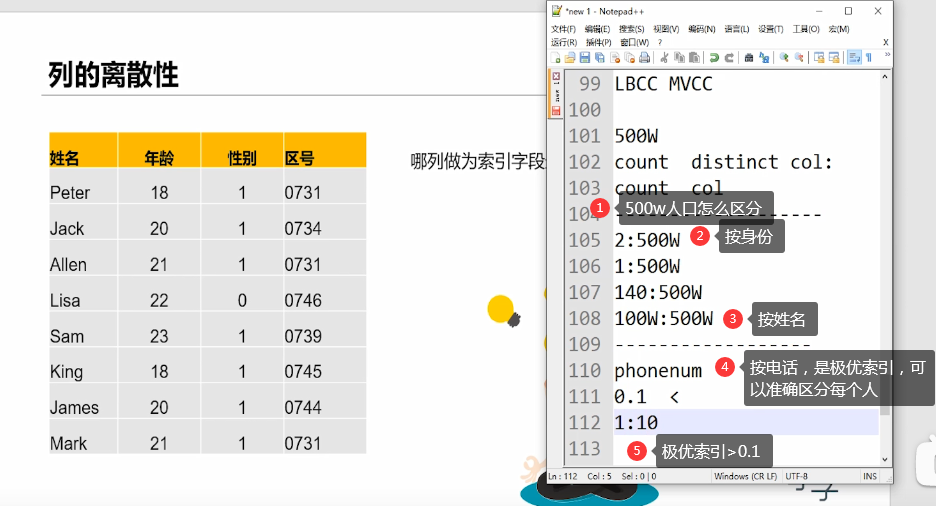
4. Column discreteness: the data repeatability is too high and the index is invalid
5. Joint index (leftmost matching principle)
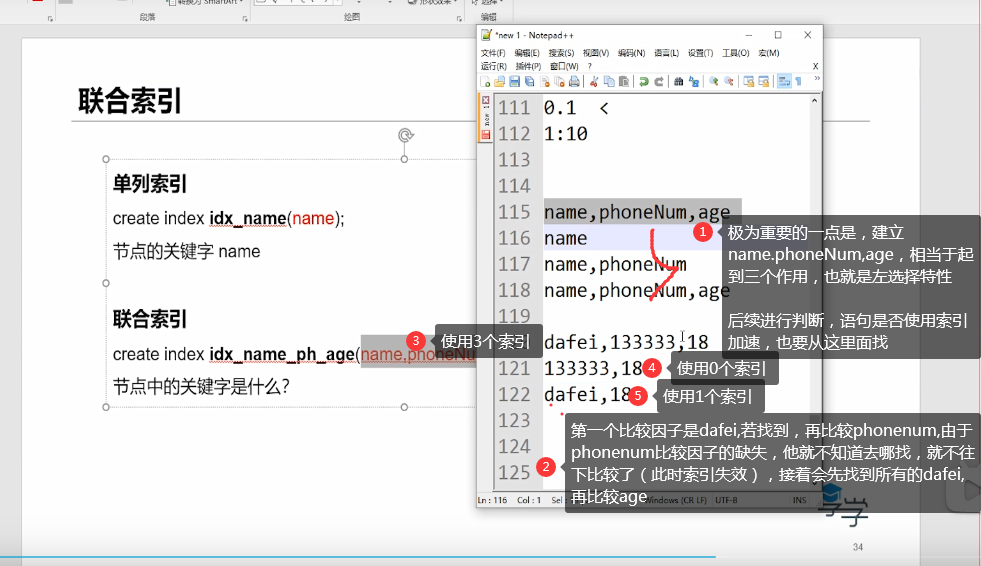

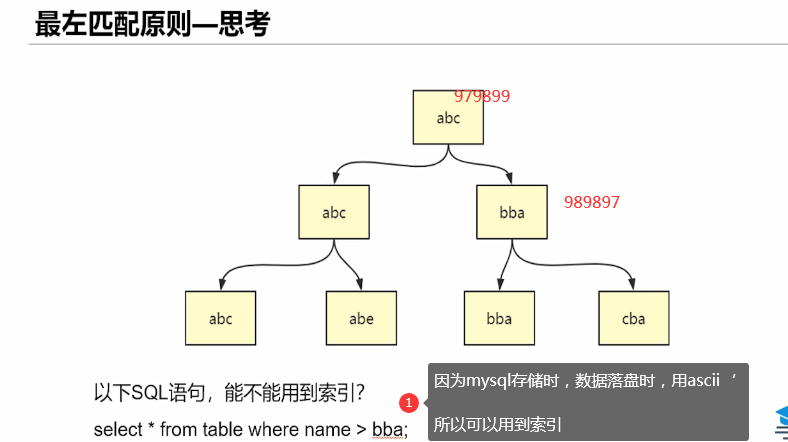

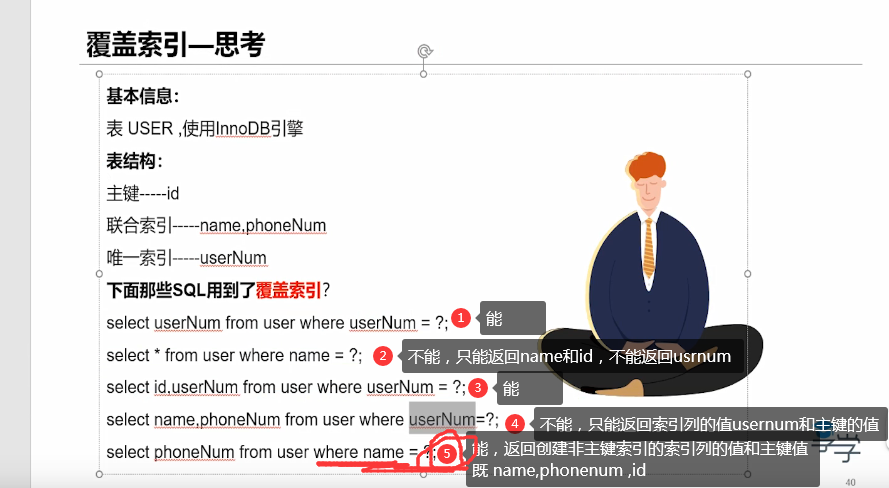
6. Overwrite the index (return the value of the current index instance and the value of the primary key)
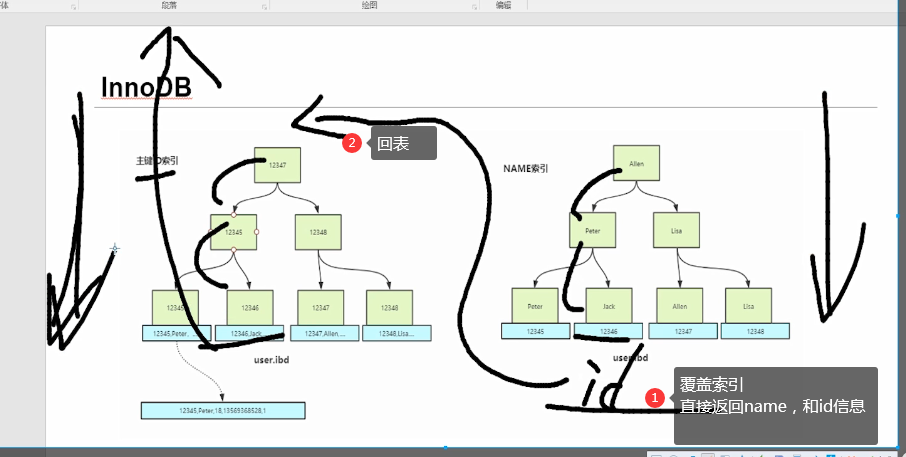
- If the queried column can be directly returned through the information of the index item, the index is called the overlay index of the query SQL.
- Try to use overlay index because it can speed up our query and reduce io operations.
select * from user where name=dafei return table index (less used)
select name,id from user where name=dafei name index is the overlay index
7. Samsung index
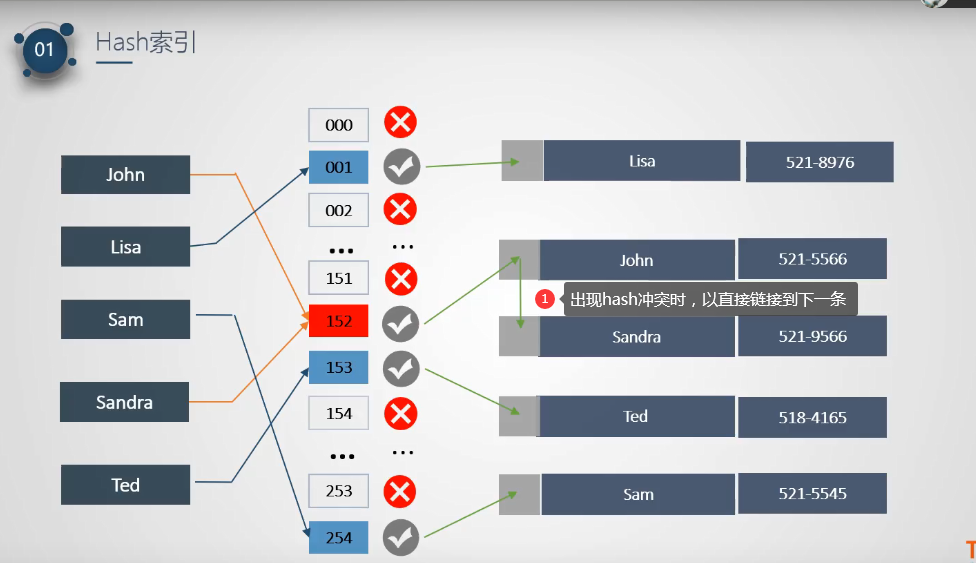
8.hashsql
How to resolve hash conflicts
- In the re hashing method (the same hash function), if there is a conflict between p=H(key), hash again based on p, p1=H §.
- Multiple hashes (different hash functions). When R1=H1(key1) conflicts, R2=H2(key1) is calculated.
- In the chain address method, the elements with the same hash value form a single linked list of synonyms, and the head pointer of the single linked list is stored in the hash
In the ith cell of the table, the search, insertion and deletion are mainly carried out in the synonym linked list. The linked list method is suitable for frequent insertion and deletion. - Establish a public overflow area, divide the hash table into public table and overflow table, and put all overflow data into the overflow area when overflow occurs.
1. What is the difference between internal connection and external connection and self connection?
Inner join is usually used when there is a primary foreign key relationship between two tables,
There are two ways to implement inner join query,
1 is to specify the join condition in the WHERE clause
2 is to use join... on in the FROM clause
Inner join queries usually join not only 2 tables, but also 3 or more tables
The tables participating in the inner join have equal status
In the outer join, the tables participating in the join can be divided into master and slave. Each row of data in the master table is used to match the data columns of the slave table, which meets the conditions
The data will be directly returned to the result set. If it does not meet the requirements, it will be filled with NULL (NULL value) and then returned to the result set.
2.delete,drop
Delete only deletes the data and does not delete the structure (definition) of the table. This operation will be placed in the rollback segement. The operation can be rolled back and restored.
truncate only deletes the data, does not delete the structure (definition) of the table, and cannot roll back
drop deletes the structure of the table and frees up all the space occupied by the table.
Summary of knowledge points
1.Basic query
SELECT CONCAT(last_name ,first_name) AS full name FROM employees;
SELECT DISTINCT `department_id` FROM employees;#Remove the same fields
2.Condition query where
SELECT `salary`,last_name FROM employees WHERE salary IN (10000,20000);
3.Sort query
SELECT `last_name`,`salary` FROM employees ORDER BY salary DESC; ASC
4.Single-Row Functions
SELECT salary Original salary,salary,
CASE
WHEN salary>20000 THEN 'A'
WHEN salary>15000 THEN 'B' #The condition is if else, naturally < 20000
ELSE 'C'
END AS Wage scale
FROM employees;
5.Grouping query
#1. Query the average salary of each department if the mailbox contains a character, and filter before Where grouping
SELECT AVG(salary) ,`department_id`FROM employees WHERE `email` LIKE '%a%' GROUP BY `department_id`;
#2. After grouping - query which department has more than 2 employees, and filtering after grouping
SELECT COUNT(*),department_id FROM employees GROUP BY department_id HAVING COUNT(*)>2;
6.join query
select Query list from Table 1 alias connection types join Table 2 aliases on Connection conditions.
[line type]have
inner-Inner connection left ,right, full External connection cross Cross linking (similar to Cartesian product)
SELECT b.name, bo.* FROM beauty b
LEFT JOIN boys bo ON b.`boyfriend_id`=bo.`id`#At this point, the boys table has been expanded into a table with the same rows as beauty
WHERE bo.id IS NULL;
7.Subquery
SELECT MIN(salary),department_id
FROM employees
GROUP BY department_id
HAVING MIN(salary)>(
SELECT MIN(salary)
FROM employees
WHERE department_id =50
);
8.Paging query (widely used)
SELECT * FROM employees LIMIT 0,5;
9.Federated query (multiple tables have no direct connection relationship)
union Union merge: merge the results of multiple query statements into one result, and the number of query columns is the same
SELECT * FROM employees WHERE email LIKE '%a%'
UNION SELECT * FROM employees WHERE department_id>90;
10. Data operation Data Manipulate Language(insert,delete,update)
INSERT INTO beauty(NAME,sex,id,phone) VALUES('Jiang Xin','female',16,'110'), ('Tang Yixin','female',15,2);
#Case: delete the information of Zhang Wuji's girlfriend
DELETE b FROM beauty b
INNER JOIN boys bo ON b.`boyfriend_id` = bo.`id`
WHERE bo.`boyName`='zhang wuji';
UPDATE beauty SET beauty.`phone`='199999998'
UPDATE boys bo INNER JOIN beauty b ON bo.`id`=b.`boyfriend_id`#Sir, make a big watch and set again
SET b.`phone`='119',bo.`userCP`=1000
WHERE bo.`boyName`='zhang wuji';
11.Table structure operation Data Define Languge( create,drop,alter)
CREATE TABLE IF NOT EXISTS author(id INT, au_name VARCHAR(20),)
DROP TABLE IF EXISTS book_author;
alter table Table name add|drop|modify|change column Column name [column type constraint];
ALTER TABLE author ADD COLUMN annual DOUBLE;
ALTER TABLE book_author DROP COLUMN annual;
ALTER TABLE book CHANGE COLUMN publishdate pubDate DATETIME;
ALTER TABLE author RENAME TO book_author;
12.Three ways to create an index
alter table Table name add INDEX Index name(column_list)
create INDEX Index name table_name(column_list)
create TABLE table_name(KEY name(first_name, last_name),)
13.Three paradigms of database
Atomicity: that is to ensure that each column can not be further divided.
Uniqueness: on the basis of satisfying the first normal form, considering the second normal form, the attribute completely depends on the primary key.
(Order No. (product No.) is the joint primary key, and the order time is only related to the order, so To split into two tables
Directness: on the basis of meeting the second normal form, ensure that the attribute does not depend on other non primary attributes, and the attribute directly depends on the primary key.
The student number is the primary key, the head teacher's name is directly dependent, and the head teacher's age is indirectly dependent, so To split into two tables
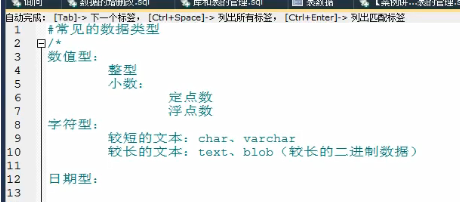
14.sql data type
Characters refer to letters, numbers, words and symbols used in computers. Two bytes are required for one Chinese character storage and one byte is required for one English character storage
Numerical type
integer(int)
Fixed point number DECIMAL(size,d) d Fixed decimal point,
Floating point number FOLAT(size,d) double(size,d)
character
Shorter text char(size) Save fixed length string varchar(size) Save variable length strings size Is the largest
Longer text text blob
Date type
DATE() TIME() YEAR()
15.What is the difference between inner connection and outer connection and self connection?
Inner join is usually used when there is a primary foreign key relationship between two tables,
There are two ways to implement inner join query,
1 Yes WHERE Clause
2 Yes FROM Used in Clause join...on
Inner join queries usually join not only 2 tables, but also 3 or more tables
The tables participating in the inner join have equal status,The tables participating in the outer join can be divided into master and slave. Match the data columns of the slave table with each row of data in the master table, and the data that meets the conditions
The data will be directly returned to the result set. If it does not meet the requirements, it will be used NULL(Null value) and then return to the result set.
16.delete,drop
delete Delete only data, not table structure(definition) ,This operation will be put into rollback segement in,The operation can be rolled back to recover.
truncate Delete only data, not table structure(definition),Cannot rollback
drop Delete the structure of the table and release all the space occupied by the table.