Mybatis
| Required environment | review |
|---|---|
| JDK1.8 | JDBC |
| Mysql5.7/8.0 | Mysql |
| maven3.6.1 | Maven |
| IDEA | Junit |
SSM (Spring + SpringMvc + Mybatis) framework: related to configuration files. The best way to learn: official documents.
1, Introduction
1.1. What is Mybatis

- MyBatis is an excellent persistence layer framework.
- It supports custom SQL, stored procedures, and advanced mapping.
- MyBatis eliminates almost all JDBC code and the work of setting parameters and obtaining result sets.
- MyBatis can configure and map primitive types, interfaces and Java POJO s (Plain Old Java Objects) to records in the database through simple XML or annotations.
- MyBatis was originally an open source project ibatis of apache. In 2010, the project was migrated from apache software foundation to google code and renamed MyBatis. Moved to Github in November 2013
Get Mybatis
- maven warehouse
<!-- https://mvnrepository.com/artifact/org.mybatis/mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.2</version>
</dependency>
- Chinese documents:[ https://mybatis.org/mybatis-3/zh/index.html ]Mybatis learns the most important documents.
- Github:[https://github.com/mybatis/mybatis-3/releases]
1.2 persistence
Data persistence
-
Persistence is the process of transforming program data in persistent state (hard disk / external memory) and transient state (memory)
-
Random Access Memory (RAM): power loss
I read a book about the history of the early industrial revolution in the University and learned that there was a device called relay. The core of the early memory was the relay, and the specific structure was a shrapnel. It moved with the potential information (next to 1 and not next to 0, which is another evidence of why the bottom layer of the calculator is binary), The potential information of this relay comes from the address bus (several are what we call the 32 / 64 operating system, which means the memory size). Because it is directly controlled by the address bus, it can directly locate (Access) a position, which is why the memory speed is fast. At the same time, the core component of the memory is the relay. Once the power is off, the relay paddle will rebound immediately, resulting in a return to the initial state, that is, the data will become the 000000 sequence, and the data will no longer exist. This is the characteristic of RAM memory. It is fast and afraid of power failure. It plays the role of memory in the computer. After all, it is the knowledge learned after class, and it is not a subject class, so it may be wrong, Wang Gaoren pointed out.
- Database (JDBC), io file persistence.
in essence, they are all placed on external storage. Learning extra-curricular knowledge. It is divided into solid state disk and mechanical disk. The mechanical hard disk can be regarded as the CD operation principle of the CD player you saw when you were a child. There is a small pointer on it and it rotates. This is re reading. Therefore, the mechanical hard disk is afraid of falling. If the needle deviates, it can't be read without biting. Solid state drive, semiconductor technology, ignorant, do not understand, only know that he has a professional term is particle.
Why persist
- If we make a student information management system, we get a student information from the view layer. A teacher worked hard in the morning and recorded 300 students for most of the day. At noon, he went to the computer to cut off the power. The data in the memory (RAM) was lost. All of them were lost. He was busy in vain. So we need to transfer it to external storage, save it for a long time, and transfer it to the database. It's much easier to look at the table.
- Memory is too expensive
Persistence layer: Dao layer, Service layer and Controller layer.
- Code block that completes the persistence work
- The layer boundary is very obvious
1.3 why do you need Mybatis
- It is convenient to help programmers store data into the database
- Traditional JDBC code is too complex, simplified, framework, automation.
- You don't need Mybatis. It's easier to learn. There is no distinction between high and low technology.
- advantage
- Easy to learn
- flexible
- The separation of sql and code improves maintainability.
- Provide mapping labels to support the mapping of orm fields between objects and databases
- Provide object relationship mapping labels to support object relationship construction and maintenance
- Provide xml tags to support writing dynamic sql.
Summary and own thinking
the Mybatis framework is completely unnecessary. You can use the more automatic Hibernate framework. In the same sentence, there is no difference between good and bad frameworks, but this is the mainstream direction now, so in order to cater, we must learn.
at the same time, for the framework, I just want to say, don't worry too much. The root shaving problem is a tool made for us by others. You can use it, just learn the grammar / configuration file specified by others. You can give someone who doesn't understand the underlying implementation to learn how to use the framework. Using the framework makes the development faster and faster. The framework is the rules set by others. It's very simple for you to learn to use it to achieve your goals and be an API caller; But it's hard to be a Framework Developer (tool builder). Therefore, the learning framework is a process of going up and down the mountain. Go up the mountain to learn how to use it quickly, go down the mountain and root out the problem, so as to explore how the function of others is realized. The question of depth and breadth is up to you.
2, The first Mybatis program
Idea: build environment – > Import Mybatis – > write code – > test
2.1 construction environment
Build database
CREATE DATABASE `mybatis`; USE mybatis; CREATE TABLE `user`( `id` INT(20) NOT NULL, `name` VARCHAR(30) DEFAULT NULL, `pwd` VARCHAR(30) DEFAULT NULL, PRIMARY KEY(`id`) )ENGINE=INNODB DEFAULT CHARSET=utf8; INSERT INTO `user` (`id`,`name`,`pwd`) VALUES (1,'Mad God','123456'), (2,'Zhang San','456852'), (3,'Li Si','qwertyuiop');
New project
-
Create a normal maven project
-
Delete the src directory (using the parent project sub project mode, in order to respond to everything)
-
Import maven dependency from parent project pom.xml
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.26</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
2.2. Create a sub module
Create a sub module, which is also a common project of maven.
- Write the core configuration file of mybatis
Write mybatis-config.xml in the resource directory of the sub module (it is clear in web learning that it will be directly under the current directory after packaging and export) (it is officially recommended to name it this way).
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false"/>
<property name="username" value="root"/>
<property name="password" value="456852"/>
</dataSource>
</environment>
</environments>
</configuration>
Do not write Chinese comments on the configuration file (change UTF-8 to UTF8/GBK)!
& Replace&
- Write mybatis tool class
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.InputStream;
//In essence, sqlSession is built in sqlSessionFactory
public class MybatisUtil {
private static SqlSessionFactory sqlSessionFactory;
static {
try {
//Step 1 of using MybatisUtils: get the sqlSessionFactory object
String resource = "mybatis-config.xml";
InputStream resourceAsStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
} catch (IOException e) {
e.printStackTrace();
}
}
//Now that we have SqlSessionFactory, as the name suggests, we can get an instance of SqlSession from it.
// SqlSession provides all the methods required to execute SQL commands in the database.
public static SqlSession getSqlSession() {
return sqlSessionFactory.openSession();
}
}
2.3. Code writing
- Entity class pojo
It is written under the corresponding package and corresponds to the database table one by one.
public class UserModel {
private int id;
private String name;
private String pwd;
//get,set,toString
}
- DAO interface
public interface IUserDao {
List<UserModel> getUserList();
}
- The interface implementation class is transformed from the original UserDaoImpl to a Mapper configuration file
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.kuang.dao.IUserDao">
<select id="getUserList" resultType="com.kuang.pojo.UserModel">
SELECT * FROM mybatis.`user`
</select>
</mapper>
Exclamation warning on the right, database is not configured. Configure Mysql , it is convenient to quickly query the corresponding tables and fields.
- Go to the core configuration file of mybatis for configuration
<mappers>
<mapper resource="com/kuang/dao/userDaoMapper.xml"/>
</mappers>
Because you want to access the xml file in a directory instead of the class file, you should use /, instead of.
2.4 test
junit test should be carried out in the test directory. Therefore, the same package structure as src should be established in the test directory.
import com.kuang.pojo.UserModel;
import com.kuang.util.MybatisUtil;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import java.util.List;
public class userDaoTest {
@Test
public void userDaoTest() {
//Step 1: get SqlSession object
SqlSession sqlSession = MybatisUtil.getSqlSession();
//implement
IUserDao userDao = sqlSession.getMapper(IUserDao.class);
List<UserModel> userList = userDao.getUserList();
for (UserModel userModel : userList) {
System.out.println(userModel);
}
sqlSession.close();
}
}
Possible problems
- The profile is not registered
Go to the core configuration file of mybatis to register and bind relevant xml files
- Binding interface error (namespace)
- Wrong method name (id)
- Wrong return type (resultType)

- Maven export resource problem
In order to increase the relevance of Mybatis, we often put configuration files such as XML files and classes together. However, the default import package does not export the configuration file under src. Therefore, add a filter under pom.xml under the parent project.
For relevance:

In order not to be filtered, you need to add it in pom.xml
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>false</filtering>
</resource>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>false</filtering>
</resource>
</resources>
</build>
2.5 summary
Mybatis is to change our previous practice of writing userDaoImple implementation class into writing an xml file. Let's simplify a lot of code we wrote before (connection, preparestation, etc.).
evolutionary process
| Previous practice | Mybatis practice |
|---|---|
| implements interface | namespace = "package permission interface name" |
| Implementation interface method | id = "interface method name" |
| Return value | resultType = "class name with package permission" |
mybatis is to change the implementation class into writing an xml tag, and its tag body focuses on SQL statements. After writing the xml, remember to register in the core configuration file of mybatis. namespace is a binding. Adding to the core configuration file is called registration.
3, CRUD
- id: is the method name in the corresponding namespace;
- resultType: return value of SQL statement!
- parameterType: parameter type.
With Mybatis, the CRUD steps are the same.
Write interface - > write the sql statement in mapper.xml corresponding to the interface - > Test (four fixed steps: open sqlSession; obtain sqlSession.getmapper (interface. class); perform relevant operations; and finally close sqlSession)
Select
Select, query statement;
- Write interface
//The lower the name is, the more convenient it is for the higher level to call to achieve reuse. DAO and Service want to be a dialogue between two people
UserModel getUserRecordById(int id);
- Write the sql statement in the corresponding mapper
<select id="getUserRecordById" parameterType="int" resultType="com.kuang.pojo.UserModel">
SELECT * FROM mybatis.`user` where id = #{id}
</select>
- test
@Test
public void selectTest() {
SqlSession sqlSession = MybatisUtil.getSqlSession();
IUserDao userDao = sqlSession.getMapper(IUserDao.class);
System.out.println(userDao.getUserRecordById(2));
sqlSession.close();
}
Insert
<!--The properties in the object can be extracted directly-->
<insert id="addUserRecord" parameterType="com.kuang.pojo.UserModel">
insert into mybatis.user (id, name, pwd) VALUES (#{id},#{name},#{pwd})
</insert>
Update
<update id="updateUserRecord" parameterType="com.kuang.pojo.UserModel">
update mybatis.user set name = #{name},pwd = #{pwd} where id = #{id}
</update>
Delete
<delete id="deleteUserRecordById" parameterType="int">
delete from mybatis.user where id = #{id}
</delete>
It should be noted that business submission sqlSession.commit() must be performed for addition, deletion and modification operations;
Several problems were found during the.
- If the parameter name is one, it can be named arbitrarily. If the id is changed to goushi, it can be any. If the donkey's lips on both sides are not right, the horse's mouth can be. This should be related to the bottom layer of mybatis. We will study it in depth at that time. (learned from the omnipotent map later, a single parameter can be automatically matched to a formal parameter without writing.)
- For addition, deletion and modification operations, the return value can be int (but this int is not the number of affected rows) and boolean. I don't understand why there can be two return values. It should be related to the bottom layer. Let's talk about it after learning.
Possible wrong reasons
- Label to match. The update tag is used by the update SQL statement, and the delete tag is used by the delete SQL statement.
- The resource binding mapper path uses / link. As mentioned earlier, you need to access the xml file in a directory instead of the class file, so you need to use /, instead of.
3.1. Mybatis passes multiple parameters (Universal Map)
Recalling the above, when updating a user, you should not pass a user, but should pass id (which to change), name and pwd (what to change); Or consider the problem that if an entity class has 100 field values, you have to fill them in for half a day. We only fill in what we need.
IUserDao
//Duplicate name, can you test it? No, an error is reported. Mapped Statements collection already contains
//map mapping already has one, that is, method overloading is not feasible in mybatis
//boolean updateUserRecord(Map<String,Object> map);
boolean updateUserRecordNew(Map<String,Object> map);
userDaoMapper.xml
<update id="updateUserRecordNew">
#The updateName updatePwd whichId as like as two peas are exactly the same as those used in the plug.
update mybatis.user set name = #{updateName},pwd = #{updatePwd} where id = #{whichId}
</update>
test
@Test
public void newUpdate() {
SqlSession sqlSession = MybatisUtil.getSqlSession();
IUserDao userDao = sqlSession.getMapper(IUserDao.class);
Map<String, Object> map = new HashMap<>();
map.put("whichId",0);
map.put("updateName","Xiao Ming Wang");
map.put("updatePwd","mzby");
//#The key value updateName updatePwd whichId of the plug here must be consistent with the time when the xml is obtained
//Otherwise, 0/false is returned during execution, and the database has not changed
System.out.println("Did you succeed?" + userDao.updateUserRecordNew(map));
sqlSession.commit();
sqlSession.close();
}
Therefore, it is recommended that when passing multiple parameters, Mybatis use map (set parameterType = "map") and directly take out the key in sql!
Yes, but it is not recommended to transfer object instances (set parameterType = "class name with package permission"), and directly take out the object properties in sql!
When there is only one basic type parameter, you can get it in sql, regardless of the parameter name! The underlying reason seems to be the following.
Use Map or annotation for multiple parameters!
Other multiparameter transfer references This blog post Yes, but the simplest and most intuitive is to recommend using Map (the official also says so).
After this example, I also learned that methods in * * Mybatis cannot be overloaded, because you are bound by name, and the problem of duplicate name cannot be solved** Recalling the underlying principle of method name duplication (overloading), we can see that the method name at the bottom is not this at all, but with numbers, such as fun_1(),fun_2() and so on, but from the programmer's point of view, they have the same name.
fuzzy search
- When executing Java code, pass wildcard%%
List<User> userList = mapper.getUserLike("%Lee%");
- Use wildcards in sql splicing!
select * from mybatis.user where name like "%"#{value}"%"
4, Configuration resolution
4.1. Core configuration file
- mybatis-config.xml (it is officially recommended to put this name in the resources directory and export it in the target along with the java code)
- The MyBatis configuration file contains settings and attribute information that deeply affect MyBatis behavior
configuration(Configuration) properties(Properties) settings(Settings) typeAliases(Type alias) typeHandlers(Type (processor) objectFactory(Object factory) plugins(Plug in) environments(Environment configuration) environment(Environment variables) transactionManager(Transaction manager) dataSource((data source) databaseIdProvider(Database (vendor ID) mappers(Mapper)
4.2. Environment variables
MyBatis can be configured to adapt to a variety of environments. This mechanism helps to apply SQL mapping to multiple databases (Mysql, Oracle). In reality, there are many reasons to do so. For example, development, test, and production environments require different configurations.
However, remember that although multiple environments can be configured, only one environment can be selected for each SqlSessionFactory instance.
Learn to use and configure multiple operating environments
The default transaction manager of Mybatis is JDBC, and the connection pool is POOlED
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!--....-->
</dataSource>
</environment>
4.3. Properties
We can reference the configuration file through the properties property
These properties can be configured externally and can be replaced dynamically. You can configure these properties either in a typical Java properties file or in a child element of the properties element. Typical Java properties [db.properties]
db.properties is placed in the resources directory and packaged directly in the classpath
driver=com.mysql.cj.jdbc.Driver url=jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false username=root password=456852
Reference in core configuration file
<!--Introduced in the core configuration file, the following database connection ${}You can use it-->
<properties resource="db.properties">
<!--You can also add some attributes directly-->
<property name="usernameOne" value="root"/>
<property name="password" value="qwert"/>
</properties>
- You can import external files directly
- You can add some more property configurations
- If the external configuration and the property tag of xml have the same field, the external configuration file will be used first
Moreover, from this problem, we have learned that XML file tags have structural order!!!
You can see that if the relevant XML is written incorrectly, the IDEA will also report an error.
If you go deep into the bottom layer to see the parseConfiguration method of XMLConfigBuilder class, you can see that its resolution is sequential
private void parseConfiguration(XNode root) {
try {
//issue #117 read properties first
propertiesElement(root.evalNode("properties"));
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
loadCustomLogImpl(settings);
typeAliasesElement(root.evalNode("typeAliases"));
pluginElement(root.evalNode("plugins"));
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}

4.4 type aliases
- Type alias sets an abbreviated name for a Java type.
- Fully qualified class name writing to reduce redundancy
<typeAliases>
<typeAlias type="com.kuang.pojo.User" alias="User"/>
</typeAliases>
In the actual development, the fully qualified name will still be used under the work project, so that it can be understood at a glance in the future!
4.5 setting
Or all reference Official documents.
These are extremely important tuning settings in MyBatis, which change the runtime behavior of MyBatis.
The four most important parameters should be familiar.
| Set name | describe | Effective value | Default value |
|---|---|---|---|
| cacheEnabled | Globally turn on or off any cache configured in all mapper profiles. | true/false | true |
| lazyLoadingEnabled | Global switch for delayed loading. When on, all associated objects are loaded late. In a specific association, the switch state of the item can be overridden by setting the fetchType property. | true/false | false |
| logImpl | Specify the specific implementation of the log used by MyBatis. If it is not specified, it will be found automatically. | SLF4J LOG4J LOG4J2 JDK_LOGGING COMMONS_LOGGING STDOUT_LOGGING NO_LOGGING | nothing |
| mapUnderscoreToCamelCase | Whether to enable automatic hump naming mapping, that is, from the classic database column name A_COLUMN maps to the classic Java property name aColumn. | true/false | false |
Hump conversion sometimes needs to be turned on. We know that the database field names are generally separated by underscores. Because the database is not sensitive to case and the Oracle database is all uppercase, they need to be separated by underscores, and the attribute names in the entity class follow the hump naming method, so the connection between the two needs to be modified.
4.6 mappers
As mentioned earlier, when the xml of the implementation of the relevant interface (such as userDaoImpl) is written, it will be registered in the core configuration file immediately.
Method 1: [highly recommended] universal, write right, absolutely available
<mappers>
<mapper resource="com/kuang/dao/userDaoMapper.xml"/>
</mappers>
We know that the relevant files are located according to the path, so we use / instead of. Or to be exact, only the Java directory structure uses. For in-depth access, while all other files are consistent with the operating system.
Method 2: [not recommended if there are additional requirements] use class file binding for registration
<mappers>
<mapper class="com.kuang.dao.UserMapper"></mapper>
</mappers>
- Interface and its Mapper configuration file must have the same name
- Interface and its Mapper configuration file must be under the same package
4.7 others
Refer to official documents.
- typeHandlers
- objectFactory (object factory)
- Plugins plug-in
- mybatis-generator-core
- mybatis-plus
- General mapper
5, Lifecycle and scope
In this section, I want to say it alone, because it contains design ideas.
Scope and lifecycle categories are critical because incorrect use can lead to very serious concurrency problems.
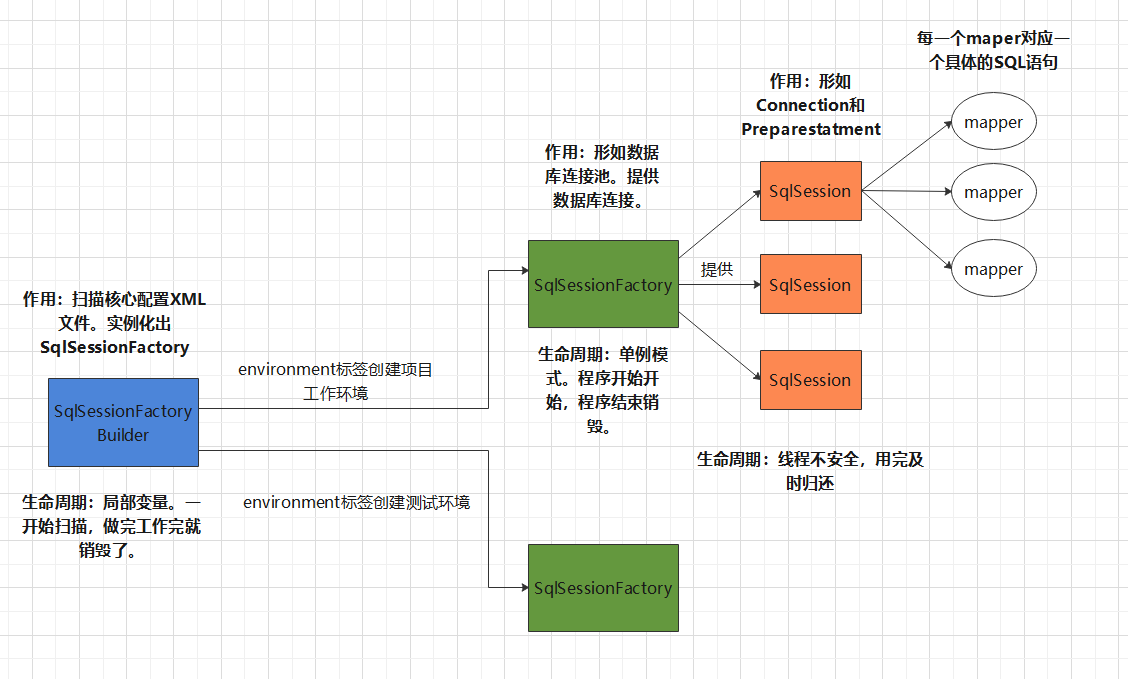
5.1,SqlSessionFactoryBuilder
- Once SqlSessionFactoryBuilder is created, it is no longer needed
- local variable
You can go deep into the source code. SqlSessionFactoryBuilder mainly provides build methods for external to get a SqlSessionFactory. The essence of these build methods is to parse the core configuration XML file!
It can be understood as follows: its function is to read XML files and generate different sqlsessionfactories according to the XML (environment tag) instance. SqlSessionFactoryBuilder is to read the core configuration file to generate SqlSessionFactory. We know that an environment tag will generate different environments. SqlSessionFactoryBuilder creates SqlSessionFactory based on this.
This class can be instantiated, used, and discarded. Once SqlSessionFactory is created, it is no longer needed. Therefore, the best scope of the SqlSessionFactoryBuilder instance is the method scope (that is, local method variables).
5.2,SqlSessionFactory
- Once SqlSessionFactory is created, it should always exist during the operation of the application. There is no reason to discard it or recreate another instance. (it ends when the program starts and the program closes)
- Therefore, the best scope of SqlSessionFactory is the application scope.
- The simplest is to use singleton mode or static singleton mode.
SqlSessionFactory is an instance of the corresponding environment (environment label). It can be understood as a database connection pool, which exists all the time when the program is running. Database connection pool for a database (JDBC/Oracle). It should be a single instance. Once the program runs completely, the environment (a database) will be closed again with the closing of the program. Single case reason: only one environment (one database) can be used for a program run.
The main method of its source code is an openSession(). From this, we can be more sure that it is a database connection pool, which provides external database connections and multiple connections.
5.3,SqlSession
- A collection similar to Connection and preparestatation
- The instance of SqlSession is not thread safe, so it cannot be shared, so its best scope is the request or method scope.
- You need to close it immediately after it is used up, otherwise the resources will be occupied.
SqlSession can be regarded as a connection obtained from the database connection pool (SqlSessionFactory) (with the ability of connection and preparestation). Thread is unsafe. Return it in time after use.
We can see its source code. SqlSession is an interface, which contains
void commit(); void rollback(); Connection getConnection(); <T> T getMapper(Class<T> type); //mybatis mainly uses this
From the above, it is the combination of Connection and preparestatation.
5.4 image of three objects of Mybatis
6, Solve the inconsistency between attribute name and field name
Java adopts the hump naming principle, while the data adopts the underline division naming principle. There will certainly be inconsistencies between the two.
For example, the following is the case.
Fields in the database
Entity class
public class UserModel {
private int id;
private String name;
private String password;
}
There is a problem with the test
Query carefully to understand the problem. The SQL statement in the xml file of the relevant mapper
//select * from mybatis.user where id = #{id}
//Equal to
//select id,name,pwd from mybatis.user where id = #{id}
*pwd is selected because all field names in the database are selected. At this time, the entity class attribute name is password, which is inconsistent, so it is not found (it is obvious that the reflection mechanism is used in the later analysis).
6.1 solution 1: alias (database level)
select id,name,pwd as password from mybatis.user where id = #{id}
You only need to match its alias and attribute name when constructing sql statement. Analyze the reason: in fact, a new table will be created after sql execution. The name of the table will follow the above, and then it will be consistent at this time (it is convenient for reflection).
This solution is too low. If there are many inconsistent fields and attributes, it will be greatly increased. Mybatis has its own solution.
6.2. Solution 2: result mapping resultMap (Java level, key)
Property name: id name password Field name: id name pwd
This mapping relationship is described in the XML related to mapper and expressed in a mapper tag
<mapper namespace="com.kuang.dao.IUserDao">
<resultMap id="resultMapOne" type="com.kuang.pojo.UserModel">
<result property="id" column="id"/>
<result property="name" column="name"/>
<result property="password" column="pwd"/>
</resultMap>
<select id="getUserList" resultMap="resultMapOne">
select * from mybatis.user
</select>
</mapper>
In fact, the same can be deleted. You can delete the mapping of id and name without affecting the result.
6.3. Use an example to understand that the bottom layer of resultMap is reflection execution
to be honest, I feel very cordial when I see this resultMap. I have done relevant work (see details) Independent implementation of simple ORM framework ). I have personally implemented this resultMap mechanism, and its root is the * * reflection mechanism * *!
When I saw that mybatis was the same as my previous practice, I couldn't help but be ecstatic, but how should I measure it and draw the conclusion that it uses the reflection mechanism? It's a process of game guessing and dialogue. Share it here.
At the beginning, I deleted all gettersetter methods of the entity class. I don't have reflection execution methods. I see how you reflect.
(1) Delete all getsetter s. I'll see how you reflect without them
public class UserModel {
private int id;
private String name;
private String password;
}
But the results came out. From this, it can be seen that the designers of mybatis framework consider this situation and create relevant set methods without relevant set methods. admire! Then keep eating my next move.
(2) Getsetter is set to private, which defines how you can set it to private
Unfortunately, the designer of mybatis framework won again this time. Results can still be performed. I understand from this that there is a black technology such as setaccessible in reflection, and the priavte modifier is useless here.
(3) It was helpless. Finally, I thought of the little yellow duck debugging method
Directly add an output statement to the setgettet method to see whether it outputs, and then judge whether the reflection mechanism is used.
public class UserModel {
private int id;
private String name;
private String password;
public int getId() {
return id;
}
public void setId(int id) {
System.out.println("setId Reflection is executed");
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
System.out.println("setName Reflection is executed");
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
System.out.println("setPassword Reflection is executed");
this.password = password;
}
}
The answer is satisfactory. It is indeed output. It also directly proves that the resultMap is implemented using the reflection mechanism, which is similar to the ORM framework I made before.
This is just the basic use of resultMap to map simple fields and attributes. But we know that a database must be complex, and the properties of classes are not simple. There are eight basic types, and there must be class types. Therefore, other tags such as association are introduced after resultMap, which is the high-level usage of resultMap. However, I just want to investigate its essence. There is no need to be afraid of advanced usage at all. The label of resultMap in XML only describes the different parts between tables and classes. With an image in mind, you can quickly understand whether you write or read! Association is to describe the mapping relationship between fields and attributes from other tables, trace the labels in them or describe the mapping relationship between fields and attributes. At this time, we can extract this mapping relationship to form a class propertycolumndefinition like the framework I made, which is the practice of my ORM framework, I don't know how the bottom layer of Mybatis does, but I think it's convenient for me to understand the object-oriented idea.
Summary: mybatis has two solutions for different attribute and field names. These two are the database level and the Java level. Modifications at the database level can be solved through * * aliases, while at the Java level, it is necessary to use the reflection mechanism * *.
At the same time, the process of seeking solutions is interesting and painful. From this, we can see how robust the Mybatis framework is! Worship!
7, Log
If an exception occurs during database operation, we need to troubleshoot it. Log is the best assistant!
Once: South (little yellow duck test method), debug
Now: log factory.
- LOG4J [Master]
- STDOUT_LOGGING [mastering]
Which log implementation to use in Mybatis can be set in settings!
STDOUT_LOGGING standard log output
In the mybatis core configuration file, configure the log!
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
Log4j
What is Log4j
- Log4j is an open source project of Apache. By using log4j, we can control that the destination of log information transmission is console, file and GUI components
- We can also control the output format of each log;
- By defining the level of each log information, we can control the log generation process in more detail.
- It can be configured flexibly through a configuration file without modifying the application code.
- Import log4j package under pom
<!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
- The related configurations of log4j are placed in log4j.properties under resources
#Output the log information with the level of DEBUG to the two destinations of console and file. The definitions of console and file are in the following code
1og4j.rootLogger=DEBUG, console,file
#Settings related to console output
log4j.appender.console = org.apache.log4j.ConsoleAppender
1og4j.appender.console.Target = System.out
log4j.appender.console.Threshold=DEBUG
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.conversionPattern=[%c]-%m%n
#Settings related to file output
log4j.appender.file = org.apache.log4j.RollingFileAppender
1og4j.appender.file.File=./log/kuang.log
log4j.appender.file.MaxFileSize=10mb
log4j.appender.file.Threshold=DEBUG
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=[%p][%d{yy-MM-dd}][%c ]%m%n
#Target output level
log4j.logger.org.mybatis=DEBUG
log4j.logger.java.sq1=DEBUG
1og4j.logger.java.sq1.statement=DEBUG
log4j.logger.java.sq1.ResultSet=DEBUG
log4j.logger.java.sq1.PreparedStatement=DEBUG
3. Configure log4j as the implementation of log
<settings>
<setting name="logImpl" value="LOG4J"/>
</settings>
Used in Log4j class
-
In the class to use log4j, import the package import org.apache.log4j.Logger;
-
Log object. The parameter is the class of the current class
static Logger logger = Logger.getLogger(UserDaoTest.class);
- log level
logger.info("info: Entered testLog4j");
logger.debug("debug: Entered testLog4j");
logger.error("error: Entered testLog4j");
Understand what happened to the packaged project
I encountered the problem that I couldn't find relevant resources here. After online search, I solved it and deeply understood what happened to the packaged project?
first, the directory structure of a Mavne project is analyzed from src, which is divided into two parts: main and test. java under main (marked in blue): this directory is the source code at the end of the. java suffix we wrote, and resources (marked in yellow): this directory is the xml and properties files required by our project. Test is the test, which needs to be carried out by the programmer himself to form an image with main.
once the Maven project is running, it is packaged. main and test form the classes and test classes directories respectively. Classes directory development as like as two peas in java directory, the same file, but the name becomes.Class bytecode file. In order to protect the source code, what we pass to others in the future is the packaged classes file; At the same time, it is also found that there is no resources directory, but all files in the original resources directory are directly attached to the classes file. This is why we do not need to add a path to access the resource file every time after packaging, because the program is currently in the classes directory, which is based on this, We have an important title * * classPath * * for accessing other relative locations. classPath is the first path before our programmers write code and the class path after packaging. The resources directory is automatically merged with the packaging. So is test.
InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-config.xml");
//This is why we do not need to add any path before we can directly access the resource file, because it is currently under classPath
//In the future, all access paths will be located in this classPath
Thread.currentThread().getContextClassLoader().getResource("")
//In this sentence, you can get the absolute path of the current program running (the one with drive letter) according to classLoad, and you can know which physical path is currently true
So we will only mention the concept of classPath in the future. The src of an ordinary Java program is classPath, and the src of a web project is classPath. As long as you start coding, the classPath is used. The resources directory is automatically merged with the packaging, and the files in other paths are relatively located according to the current classPath!
8, Pagination
Think: why pagination?
- Reduce data processing
- One page cannot be displayed
7.1. Use Limit paging
Paging SQL statement limit
select * from mybatis.user limit startIndex,pageSize; #Start with the subscript (startIndex) and display the PageSize select * from mybatis.user limit 3; #[0,3]
Pagination using Mybatis, core SQL
1. Interface
List<UserModel> getUserListLimit(Map<String, Integer> paraMap);
2. Bind a mapper.xml
<mapper namespace="com.kuang.dao.IUserDaoFour">
<resultMap id="getUserListLimitPropertyColumnMapping" type="com.kuang.pojo.UserModel">
<result property="password" column="pwd"/>
</resultMap>
<select id="getUserListLimit" parameterType="map" resultMap="getUserListLimitPropertyColumnMapping">
select * from mybatis.user limit #{startIndex},#{pageSize}
</select>
</mapper>
3. Test
public void test() {
SqlSession sqlSession = MybatisUtil.getSqlSession();
Map<String,Integer> paraMap = new HashMap<>();
paraMap.put("startIndex", 0);
paraMap.put("pageSize", 3);
IUserDaoFour iUserDaoFour = sqlSession.getMapper(IUserDaoFour.class);
List<UserModel> userListLimit = iUserDaoFour.getUserListLimit(paraMap);
for (UserModel userModel : userListLimit) {
System.out.println(userModel);
}
sqlSession.commit();
sqlSession.close();
}
RowBounds paging
It's out of date. It's not recommended to study.
Paging plug-in
9, Using annotation development
9.1 interface oriented programming
-Everyone has studied object-oriented programming and interface before, but in real development, we often choose interface oriented programming
-Root cause: decouple, expand and improve reuse. In layered development, the upper layer does not care about the specific implementation. Everyone abides by common standards, making the development easier and more standardized
-In an object-oriented system, various functions of the system are completed by many different objects. In this case, how each object implements itself is not so important to system designers;
-The cooperative relationship between various objects has become the key of system design. From the communication between different classes to the interaction between modules, we should focus on it at the beginning of system design, which is also the main work of system design. Interface oriented programming means programming according to this idea.
Understanding of interfaces
-From a deeper understanding, the interface should be the separation of definition (specification, constraint) and Implementation (the principle of separation of name and reality).
-The interface itself reflects the system designer's abstract understanding of the system.
-There shall be two types of interfaces:
-The first type is the abstraction of an individual, which can correspond to an abstract class-
-The second is the abstraction of an aspect of an individual, that is, the formation of an abstract interface-
-An individual may have multiple Abstract faces. Abstract bodies are different from abstract faces.
Three oriented differences
-Object - oriented means that when we consider a problem, we take the object as the unit and consider its attributes and methods
-Process oriented means that when we consider a problem, we consider its implementation in a specific process (transaction process)
-Interface design and non interface design are aimed at reuse technology. They are not a problem with object-oriented (process). They are more reflected in the overall architecture of the system
Interface oriented programming I understand: interfaces are designed by experienced architects. An excellent architect can design a very practical framework with many reuse times. In engineering, interface oriented programming is to * * save money * * and speed up development efficiency. After Java, you develop a system for one school, complete it, and then develop them for another school Does the system need to start from scratch? This is unnecessary. Therefore, with the concept of framework, the framework is equivalent to human bones, and the meat grows with the bones. That is to say, other icing on the cake needs should not be considered in the framework. The framework only serves as the internal structure of the main system. The framework is built according to the layer structure, the Dao layer only does the Dao layer's business, and the Service only does its own business . the interface of this layer only does its own interface.
I have a deeper thinking about the interface, plug and play. I just set a direction and how to implement the interface. No matter how you inject different implementation classes into me, the interface can be reused.
9.2 development using annotations
- Annotation is implemented on the interface (the interface implements impl, just a simple SQL)
@Select("select * from mybatis.user")
List<UserModel> getUserList();
- You need to bind the interface in the core configuration file!
<mappers>
<!--<mapper resource="com/kuang/dao/UserDaoFourMapper.xml"></mapper>-->
<mapper class="com.kuang.dao.IUserDaoFour"/>
<!-- Resource Use when Binding / Access files, class Just use.visit java file -->
</mappers>
- test
Essence: reflection mechanism and dynamic proxy mechanism
9.3,CRUD
Write the interface and add comments
@Select("select * from user")
List<User> getUsers();
//Method has multiple parameters. All parameters must be preceded by @ Param("id") annotation
@Select("select * from user where id = ${id}")
User getUserById(@Param("id") int id);
@Insert("insert into user(id,name,pwd) values (#{id},#{name},#{password})")
int addUser(User user);
@Update("update user set name=#{name},pwd=#{password} where id = #{id}")
int updateUser(User user);
Test class
[note that the interface registration must be bound to the core configuration file]
@Test
public void test(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
IUserDaoFour mapper = sqlSession.getMapper(UserMapper.class);
mapper.updateUser(new User(98, "sino", "abcdef"));
sqlSession.commit();//No, the database won't have
sqlSession.close();
}
About @ Param("") annotation
- Basic type parameters or String types need to be added faster
- Reference type does not need to be added (class type cannot be mapped to)
- If there is only one basic type, it can be ignored (the bottom layer is found according to the subscript), and it is recommended to add it.
- The property name set in @ Param("uid") is referenced in SQL
#{} (prevent SQL injection), ${} (can be spliced, resulting in SQL injection)
9.4,Lombok
Without learning, getsetter can be written quickly. There is no need for others to do it for you. At the same time, getsetter is the soul of object-oriented (encapsulation idea)! Moreover, if you want your own strange pojo output format, you need to write your own toString method. Don't rely on others to write everything for you.
10, Many to one (association)
ER diagram
Many to one:
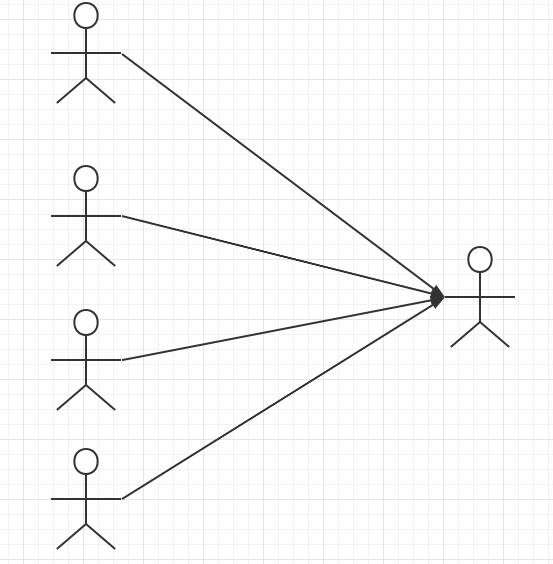
- Multiple students correspond to one teacher
- For students, multiple students and one teacher [many to one]
- For teachers, a teacher has many students [one to many]
Database diagram
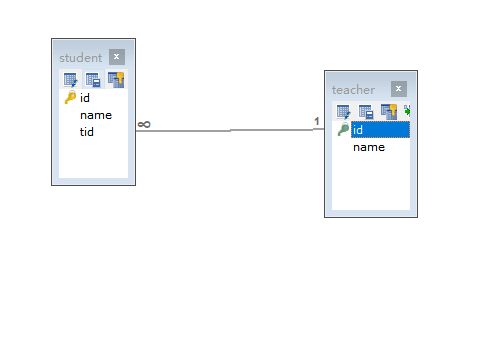
Required database:
CREATE TABLE `teacher`( `id` INT(20) NOT NULL, `name` VARCHAR(30) DEFAULT NULL, PRIMARY KEY(`id`) )ENGINE=INNODB DEFAULT CHARSET=utf8; INSERT INTO `teacher`(`id`,`name`) VALUES (1,'Miss Zhu'); INSERT INTO `teacher`(`id`,`name`) VALUES (2,'Crazy teacher'); CREATE TABLE `student`( `id` INT(20) NOT NULL, `name` VARCHAR(30) DEFAULT NULL, `teacher_id` INT(10) DEFAULT NULL, PRIMARY KEY(`id`), KEY `fktid` (`teacher_id`), CONSTRAINT `fktid` FOREIGN KEY (`teacher_id`) REFERENCES `teacher` (`id`) )ENGINE=INNODB DEFAULT CHARSET=utf8; INSERT INTO `student`(`id`,`name`,`teacher_id`) VALUES(1,'Xiao Ming',1); INSERT INTO `student`(`id`,`name`,`teacher_id`) VALUES(2,'Xiao Hong',2); INSERT INTO `student`(`id`,`name`,`teacher_id`) VALUES(3,'Xiao Zhang',1); INSERT INTO `student`(`id`,`name`,`teacher_id`) VALUES(4,'petty thief',2); INSERT INTO `student`(`id`,`name`,`teacher_id`) VALUES(5,'Xiao Wang',1);
It is recommended to implement step by step, otherwise the data will be inserted before the table is established, resulting in an error.
In engineering, it is still recommended not to create foreign keys. Here, foreign keys are set only for examples.
Create entity class
TeacherModel
public class TeacherModel {
private int id;
private String name;
//getset toString
}
StudentModel
public class StudentModel {
private int id;
private String name;
//private int teacherId; after careful consideration, it is unnecessary
private TeacherModel teacherModel;
//get set toString
}
Whether this teacherId is in StudenModel or not has the following considerations.
teacherId exists:
Advantages: in the future, you can get a student model, and you can directly find its teacher according to its tid (later, it seems that teacher means that the teacherId really doesn't exist, so delete it immediately)
Disadvantages: data redundancy. The meaning of teacherId is the same as that of teacher. Data redundancy.
In the world of java, teacher is a teacher. It is also an entity class. I don't care what your database number is. I only know that student has the attribute of teacher. Therefore, int teacherId is not necessary. Alternatively, you can write this teacherId, but it is not displayed externally. get method package permission and set method package permission are only used internally and not displayed externally.
From this, I understand that java is the world of java and database is the world of database. What we want is different, and the representation is different.
Establish interface
public interface IStudentDao {
List<StudentModel> getStudentList();
}
XML file for establishing interface implementation
Solution 1: nested query according to the results (even table query, important to master)
StudentDaoMapper.xml
<mapper namespace="com.kuang.dao.IStudentDao">
<select id="getStudentList" resultMap="getStudentListPropertyColumnMapping">
select s.id as sid,s.name as sname,s.teacher_id as tid,t.name as tname
from student as s,teacher as t where s.teacher_id = t.id
</select>
<resultMap id="getStudentListPropertyColumnMapping" type="com.kuang.pojo.StudentModel">
<!--Write only the current table and pojo Class properties are different-->
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<!--Complex properties require association Deeper-->
<association property="teacherModel" javaType="com.kuang.pojo.TeacherModel">
<result property="id" column="tid"/><!--Without that, teacher Incomplete injection-->
<result property="name" column="tname"/>
</association>
</resultMap>
</mapper>
The most important thing here is to write SQL statements. Here I also fully understand SQL statements. Here is a summary.
select statement body
SELECT (find out the column name of the new table, and it is strongly recommended to use as to write the column name of the new table) FROM (for which tables, it is recommended to also use as as as alias to distinguish which table column is) WHERE (if the condition is not added, it will become the form of Cartesian product)
To write a SELECT statement, first write the body, SELECT... FROM... WHERE, and then fill it according to the requirements. (use as to express the alias, don't just write a space)
select s.id as sid,s.name as sname,s.teacher_id as tid,t.name as tname from student as s,teacher as t where s.teacher_id = t.id
The SQL statement of join table query is easy to write and analyze. The above SQL statement represents the new result table formed from the student table (alias s) and the teacher table (alias t). The sid column is the ID of the student table; The sname column of the new table is the name of the student table; The tid column of the new table is the teacher of the student table_ id; The new table tname is the name of the teacher table; The condition is the teacher of the student table_ The ID is equal to the ID of the teacher table.
The reason for aliasing is: the new column name of the new table formed by the select query is based on the alias. If it is not set, it is based on the source table; At the same time, the alias is set, and the mybtatis write parameter will follow the new table.
Register in the mybatis core configuration XML file
<mappers>
<mapper resource="com/kuang/dao/StudentDaoMapper.xml"/>
</mappers>
Test, successful.
Solution 2: nested processing according to query (sub query, complex, not recommended)
- Query the information of all students
- According to the student's tid, find the corresponding teacher! Subquery
StudentDaoMapper.xml
<select id="getStudentListOne" resultMap="getStudentListOnePropertyColumnMapping">
select * from student
# Direct look-up table
</select>
<resultMap id="getStudentListOnePropertyColumnMapping" type="com.kuang.pojo.StudentModel">
<association property="teacherModel" column="teacher_id" javaType="com.kuang.pojo.TeacherModel" select="exSelect"/>
<!-- More queries -->
</resultMap>
<select id="exSelect" resultType="com.kuang.pojo.TeacherModel">
select * from teacher where id = #{id}
</select>
Register in the mybatis core configuration XML file; The test was also successful.
However, it is recommended to use join table query, which is simple and easy to understand.
The SQL constructed by the linked table query can be directly input on the database console and then see the results. The sub query does not work. The sub query also involves parameter transmission, so it is complex and difficult to understand and debug.
11, One to many (collection)
For example: a teacher has multiple students!
For teachers, it is a one to many relationship
Entity class
public class TeacherModel {
private int id;
private String name;
private List<StudentModel> studentList;
}
Interface
public interface ITeacherDao {
TeacherModel getTeacherById(@Param("teacherId") int id);
}
XML file for establishing interface implementation
TeacherDaoMapper.xml
<mapper namespace="com.kuang.dao.ITeacherDao">
<select id="getTeacherById" resultMap="getTeacherByIdPropertyColumnMapping">
SELECT s.id AS sid, s.name AS sname, t.name AS tname, t.id AS tid
FROM student AS s, teacher AS t
WHERE s.teacher_id = t.id AND t.id = #{teacherId}
</select>
<resultMap id="getTeacherByIdPropertyColumnMapping" type="com.kuang.pojo.TeacherModel">
<result property="id" column="tid"/>
<result property="name" column="tname"/>
<collection property="studentList" ofType="com.kuang.pojo.StudentModel">
<result property="id" column="sid"></result>
<result property="name" column="sname"></result>
</collection>
</resultMap>
</mapper>
Go to the mybatis core configuration file to register and test ok.
Only the linked table query is written, and the sub query is not written, which is difficult and difficult to understand.
Summary
- association - association [many to one]
- Set - collection [one to many]
- javaType: used to specify the type of attribute in the entity class
- ofType is used to specify the pojo type mapped to List or collection, and the constraint type in generic type!
Note:
- Ensure the readability of SQL and make it easy to understand
- Pay attention to one to many and many to one, attribute names and fields!
- If the problem is not easy to troubleshoot, you can use the log
The gap between slow sql 1s and 1000s. After learning the knowledge of sql indexing, put aside the sql we are writing and write it by reference.
12, Dynamic SQL
What is dynamic SQL: dynamic SQL refers to generating different SQL statements according to different conditions
if
<select id="queryBlogIF" parameterType="map" resultType="Blog">
select *
from mybatis.blog where 1=1
<if test="title != null">
and title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</select>
where 1 = 1 this is because the where statement must appear, but I don't know whether the following conditions are met. So write a 1 = 1. 1 = 1 forever true, 1 < > 1 forever false. The query of where 1 < > 1 shows that the table data is not required as long as the table structure.
choose (when, otherwise) is like a switch statement
<select id="queryBlogIF" parameterType="map" resultType="Blog">
select * from mybatis.blog
<where>
<choose>
<when test="title != null">
title = #{title}
</when>
<when test="author != null">
and author = #{author}
</when>
<otherwise>
and views = #{views}
</otherwise>
</choose>
</where>
</select>
Instead of using where 1 = 1, the where tag is used. The where tag allows the SQL string to be spliced correctly.
With the where tag, it is not recommended to use where 1=1. where 1=1 will invalidate the data index in the table.
The so-called dynamic SQL is still an SQL statement in essence, but it can execute a logical code at the SQL level
SQL fragments and foreach operations are not involved.
My opinion on dynamic SQL
How to put it, I think it's OK to understand and write the simplest if. Dynamic SQL is splicing SQL strings, and mybatis is the framework for operating the database. According to the separation principle, the database only cares about the operation of the database, less logical operations, and it's good to introduce an if. Without dynamic SQL, you can always divide DAO operations with fine granularity. The simpler and more basic methods you write, the smaller the granularity and the higher the reusability. It can be called meta operation.
13, Cache
Cache (Cache, kashi, kachi correction of read errors) is a very important concept. Caching plays an important role in mybatis optimization. Caching is to improve query efficiency.
//todo screenshot madness, cache introduction
in the beginning, a single server, a small number of users request resources from the server, and the server is only responsible for connecting with the customer. The resource file certainly does not exist on the server, but on the database. The server analyzes the customer's request, and then obtains relevant data from the database and returns it. This was the case in the early days;
with the increasing development of the network and the surge in the number of users, the traditional single server can not bear great pressure, so multiple servers are needed to process. These servers can be set across regions to meet the experience of users in different regions and quickly respond to application user requests.
although the processing speed of requests is fast due to multiple servers, the real resources need to be obtained from the database; The essence of database is also a server, and its main work is reading and writing. The pressure has shifted to the database. What should I do? There is nothing in the architecture that cannot be solved by adding a layer. It is analyzed that read operations and write operations should be independent. Therefore, a layer of memoryCache cache is added. memoryCache stores common database resources to realize the separation of read and write. The read operation reads the memoryCache first and does not read from the database again, and the writing pressure is all on the database.
if you don't think the processing speed is fast enough, you can make multiple databases to share the pressure. However, data consistency should be considered for multiple databases. How to guarantee it? Master slave copy!
From the above development history, you can also understand that cache is a warehouse (pool) for storing common data, which is convenient for users to get it quickly.
So does caching in Mybatis
1. What is Cache
- There is temporary data in memory.
- Put the data frequently queried by users in the cache (memory), and users do not need to query from the disk (relational database data file) but from the cache to query the data, so as to improve the query efficiency and solve the performance problem of high concurrency system.
2. Why cache?
- Reduce the number of interactions with the database, reduce system overhead and improve system efficiency.
3. What kind of data can be cached?
- Frequently queried and infrequently changed data.
Mybatis cache
- MyBatis includes a very powerful query caching feature that makes it easy to customize and configure caching. Caching can greatly improve query efficiency.
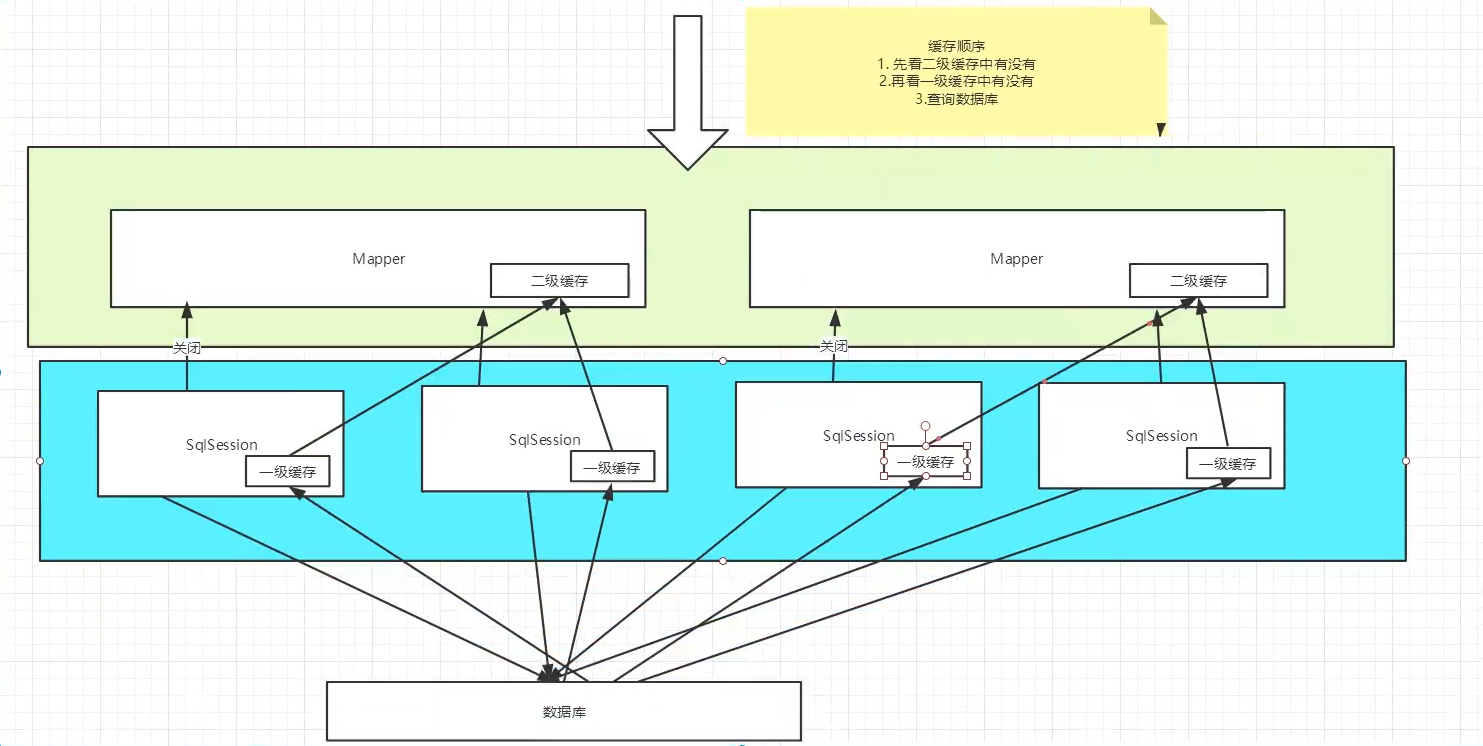
- Two levels of cache are defined by default in MyBatis system: L1 cache and L2 cache
- By default, only L1 cache is on. (SqlSession level cache, also known as local cache). The L2 cache needs to be manually enabled and configured. It is based on the namespace (mapper.xml of an interface) level cache.
- In order to improve scalability, MyBatis defines the Cache interface Cache. We can customize the L2 Cache by implementing the Cache interface
Mybatis L1 cache
mybatis L1 cache is also called local cache.
-
L1 cache is on by default
-
The L1 cache life cycle is one session (one open and one close of sqlSession), which is valid during this session
public void test() {
SqlSession sqlSeeion = MybatisUtil.getSqlSeeion(); //openSession
//L1 cache is only valid between
sqlSeeion.commit();
sqlSeeion.close();
}
(1) The data queried during the same session with the database will be placed in the local cache.
(2) In the future, if you need to obtain the same data, you can get it directly from the cache. You don't have to query the database again;
- The example proves the existence of L1 cache
@Test
public void test() {
SqlSession sqlSeeion = MybatisUtil.getSqlSeeion();
IUserDaoFive mapper = sqlSeeion.getMapper(IUserDaoFive.class);
UserModelFive user = mapper.getUserById(1);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
UserModelFive anotherUser = mapper.getUserById(1);
System.out.println("Do they have the same address value?" + (user == anotherUser)); //true
sqlSeeion.commit();
sqlSeeion.close();
}
The output is true and the same id is queried. At first, I thought that the bottom layer must use the reflection mechanism to create a new pojo object. At this time = = is true, indicating that the address values are the same, indicating that the two objects are the same at this time, which proves the existence of L1 cache. At the same time, it can be seen from the log information that the relevant SQL is executed only once, indicating that the object is fetched from the level-1 cache for the second time.
- L1 cache invalidation
(1) insert, update and delete operations may change the original data. In order to ensure real-time data, the first level cache will be refreshed
(2) Query different mapper.xml (that is, check the implementation XML file of another interface. From this, we know that the caches of different mappers under the same sqlsession are different. Later, it is proved that different mapper.xml correspond to different L2 caches. Later, we learn that mapper.xml can pass L2 caches by reference)
@Test
public void testMapperOneCache() {
SqlSession sqlSeeion = MybatisUtil.getSqlSeeion();
IUserDaoFive mapperOne = sqlSeeion.getMapper(IUserDaoFive.class);
UserModelFive userOne = mapperOne.getUserById(1);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
IUserDaoSix mapperTwo = sqlSeeion.getMapper(IUserDaoSix.class);
UserModelFive userTwo = mapperTwo.getUserByUserId(1);
System.out.println("Are the address values the same?" + (userOne == userTwo));
//false. It shows that different mapper.xml has different L1 caches (it was later verified that different mapper.xml corresponds to different L2 caches)
sqlSeeion.commit();
sqlSeeion.close();
}
(3) Manual cache cleanup
sqlSeeion.clearCache();
Mybatis L2 cache
- L2 cache is also called global cache. The scope of L1 cache is too low (it will be closed after one sqlseesion), so L2 cache was born
- Based on the namespace level cache, a namespace and a mapper.xml correspond to a L2 cache;
- Working mechanism
- When a session queries a piece of data, the data will be placed in the first level cache of the current session;
- If the current session is closed, the L1 cache corresponding to the session is gone; But what we want is that the session is closed and the data in the L1 cache is saved to the L2 cache;
- The new session query information can get the content from the L2 cache;
- The data found by different mapper s will be placed in their corresponding cache (map);
Use steps
- Prerequisite 1: enable the global cache in the core configuration file
<settings>
<setting name="cacheEnabled" value="true"/>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
- Prerequisite 2: enable L2 cache in current Mapper.xml
<!--current mapper.xml Enable L2 cache in-->
<!--<cache/> It can be started in a simple sentence. The following are parameters that can also be added-->
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
-
All data will be put in the first level cache first, and will be transferred to the second level cache only when the session is submitted (sqlSeeion.commit()) or closed (sqlSeeion.close())!
-
After the above two conditions are enabled, the L2 cache takes effect. When the L1 cache is closed (after the sqlsession is closed), the queried objects under the same mapper.xml will be placed in the L2 cache; different mapper.xml has its own unique L2 cache.
@Test
public void testTwoCache() {
SqlSession sqlSeeion = MybatisUtil.getSqlSeeion();
IUserDaoFive mapper = sqlSeeion.getMapper(IUserDaoFive.class);
UserModelFive user = mapper.getUserById(1);
sqlSeeion.commit();
sqlSeeion.close();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
SqlSession sqlSeeion1 = MybatisUtil.getSqlSeeion();
IUserDaoFive mapper1 = sqlSeeion1.getMapper(IUserDaoFive.class);
UserModelFive user1 = mapper1.getUserById(1);
sqlSeeion1.commit();
sqlSeeion1.close();
System.out.println("Are the address values the same?" + (user == user1));
//true
//1. Core file enable display enable cache < setting name = "cacheenabled" value = "false" / >
//2.mapper.xml defines the cache < cache / >
//If there is no readOnly="true" in the cache, an deserialized exception will be reported, which is related to the stream
}
- Different mapper.xml references the cache of other mapper.xml
@Test
public void testMapperMoveStore() {
SqlSession sqlSeeion = MybatisUtil.getSqlSeeion();
IUserDaoFive mapper = sqlSeeion.getMapper(IUserDaoFive.class);
UserModelFive user = mapper.getUserById(1);
sqlSeeion.commit();
sqlSeeion.close();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
SqlSession sqlSeeion1 = MybatisUtil.getSqlSeeion();
IUserDaoSix mapper1 = sqlSeeion1.getMapper(IUserDaoSix.class);
UserModelFive user1 = mapper1.getUserByUserId(1);
sqlSeeion1.commit();
sqlSeeion1.close();
System.out.println("Different mapper Can the L2 cache of be referenced?" + (user == user1));
//true. The inquiry process is very interesting
}
<!--<cache/>--> <!--Do not use your own L2 cache pool, but refer to others mapper.xml L2 cache pool of corresponding interface-->
<cache-ref namespace="com.kuang.dao.IUserDaoFive"/>
After trying for a long time here, it was false, and the mentality collapsed. It was different from the cache ref mentioned in the official document. At the time of the crash, I searched online and finally solved the puzzle. Refer to the boss's blog cache-ref It is understood that cache is an instance object, and neither < cache / > nor < cache ref / > can be introduced. After parsing the < cache / > node, mapper creates a cache instance for itself and no longer references the cache instance of < cache ref / >. In other words, a mapper can either define its own L2 cache or reference someone else's L2 cache, and can only use one pool.
Cache schematic image
Custom cache
Of course, you can use your own customized cache. Let's first look at the org.apache.ibatis.cache.Cache interface.
package org.apache.ibatis.cache;
import java.util.concurrent.locks.ReadWriteLock;
public interface Cache {
String getId();
void putObject(Object key, Object value);
Object getObject(Object key);
Object removeObject(Object key);
void clear();
int getSize();
default ReadWriteLock getReadWriteLock() {
return null;
}
}
If you want to implement custom caching, you need to implement the interface and complete all its specified methods.
I see from here. In fact, designing an interface and proposing these methods is to design a policy! Specify what you must accomplish. The implementation class implementing the interface is the specific implementation of the policy.
Then import the related mapper.xml into the custom cache
<cache type="com.domain.something.MyCache"/>
Generally, the work is cached in Redis (which has been done to the extreme) database. It is in the form of K-V key value pairs. They are stored in K-V, retrieved directly and placed directly. We will learn this later.
My opinion on cache
The purpose of caching is to improve query efficiency.
The scope of L1 cache is that with the death of sqlSession, it is only valid under the same sqlSession package. Different sqlsessions have their own different L1 caches.
The precondition of L2 cache is to enable the display of core configuration files and enable the cache tag under mapper.xml. All data will be placed in L1 cache first, only session submission (sqlSeeion.commit()) or shutdown (sqlSeeion.close()) When the first level cache is closed, the objects queried by the same mapper.xml will be transferred to the same second level cache, and the objects queried by different mapper.xml will be placed in different second level caches. Different mapper.xml You can use your own L2 cache pool or reference another mapper.xml L2 cache pool.