This chapter includes
- Download and process actual go game records
- Understand the standard format for storing go games
- Training an in-depth learning model using such data to predict the landing
- Run your own experiments and evaluate them
In the previous chapter, you saw many basic elements of building an in-depth learning application and built some neural networks to test the tools you learned. The key is that you still lack good data to learn. A supervised deep neural network requires you to improve your data - but so far, you only have the data you generate.
In this chapter, you will learn about SGF, the most common data format for go data. You can get SGF game records from almost every popular go server. In this chapter, you will download many SGF files from the go server, code them in an intelligent way, and use these data to train the neural network. The resulting trained neural network will be much better than any previous model.
Figure 7.1 illustrates what can be built by the end of this chapter.
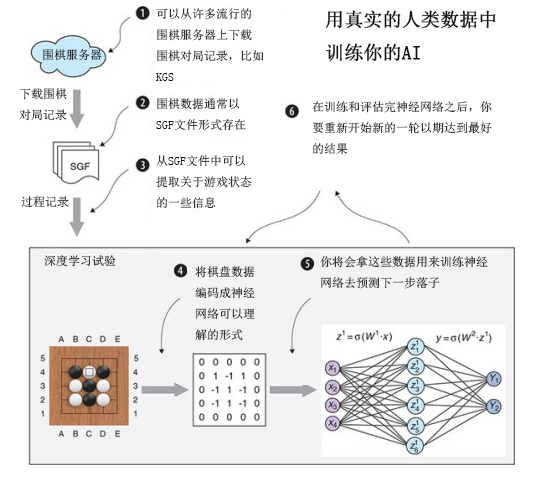
At the end of this chapter, you can run your own experiments using complex neural networks to build a powerful AI completely independently. To start, you need access to real go data.
7.1. Importing go data
So far, all the go data you use is generated by yourself. In the previous chapter, you trained a deep neural network to predict the location of the generated data. You want your network to be able to predict these drops perfectly. In this case, the network will function as a tree search algorithm to generate data. To some extent, the data you enter, oak, provides an upper limit for deep learning robot training. The robot cannot exceed the generated data. If you use the powerful human chess player game record as the input of deep neural network, you can greatly improve the level of your robot. Now you will use the game data of KGS go server (formerly known as kiseido go server), which is the most popular go game platform in the world. Before introducing how to download and process data from KGS, we will first introduce you to the data format of go data.
7.1.1 SGF file format
SGF was developed in the late 1980s. Its current fourth major release (for FF[4]) was released in the late 1990s. SGF is a text-based format that can be used to express go games and variations of go games (for example, game reviews of go Masters) and other board games. For the rest of the chapter, you'll assume that the SGF file you're working on is made up of go games, nothing else. In this section, we will teach you some basic knowledge about this rich game format, but if you want to learn more about it, please go to https://senseis.xmp.net/?SmartGameFormat.
SGF mainly includes game situation and drop data. It is wrapped in two braces by two specified capital letters. For example, in SGF, a go board with a size of 9 × 9 will be encoded as SZ[9]. Go drop will be encoded as follows: white drop will be W[cc] at the intersection of the third row and the third column, while black drop will be represented as B[gc] at the intersection of the seventh row and the third column; the letters B and W represent the color of the chess piece, and the coordinates of the rows and columns are indexed in alphabetical order. To represent pass, use empty steps B [] and w [].
The following SGF file example is taken from the complete match on the 9 * 9 chessboard in Chapter 2. It shows a go game (GM[1] stands for go), HA[0] stands for 0, KM[6.5] stands for 6.5, Ru [Japanese] stands for Japanese rule, RE[W9.5] stands for 6.5 win in vain

An SGF file is organized into a list of nodes separated by semicolons. The first node contains information about the game: board size, rules used, game results, and other background information. Each subsequent node represents a drop in the game. Finally, you can also see the points belonging to white chess territory, listed under TW, and the points belonging to black chess territory, listed under TB.
7.1.2. Download and playback of Go game records from KGS
If you go to https://u go.net/gamerecords/, you will see a table with game records in various formats available for download. This game data is collected from the KGS go server. All these games are played on a 19 × 19 board. In Chapter 6, we only use a 9 × 9 board to reduce the calculation.
This is an incredibly powerful data set that can be used for go drop prediction, which you will use in this chapter to power powerful deep learning robots. You need to be able to automatically download through the link to get a single file, then extract the file, and finally process the SGF game records contained in it.
As a first step in using this data as input to the deep learning model, you can create a new sub module named data in the main dlgo module and provide an empty . Py as usual. This sub module will contain all the data processing required for this book.
Next, to download the game data, you can add a new file in the data sub module index? Processor.py, create a class named KGSIndex, and implement the download? Files method in it
7.2 preparing data for deep learning
In Chapter 6, you saw a simple go data encoder that already represents the Board and GameState classes introduced in Chapter 3. When using SGF files, you first need to play back the content, generate a corresponding match, and get the necessary game information.
7.2.1. Replay go match according to SGF record
Reading the game information of SGF file means understanding and implementing the format specification. Although this is not particularly difficult (just to impose a rule on a string of Texts), it is not the most exciting aspect of building go AI, which requires a lot of effort and time to be perfect. For these reasons, we will introduce another sub module, gosgf, into dlgo, which is responsible for all the logic required to process SGF files. The gosgf module is adapted from the gomil Python library. The address is https://mjw.woodcraft.me.uk/gomill/
You will need an entity from gosgf that is sufficient to handle everything you need: sgf_game. Let's see how to use SGF game to load an SGF game, read out the game information step by step, and apply the drop to the Game State object. Figure 7.2 shows the start of the go game, represented by the SGF command.

Replay the game record from the SGF file. The original SGF file encodes game moves and strings, such as B[ee]. The Sgf_game class decodes these strings and returns them as Python tuples. You can apply these drops to GameState objects to rebuild the game
# First, import the SGF game class from the new gosgf module
from dlgo.gosgf import Sgf_game
from dlgo.goboard_fast import GameState, Move
from dlgo.gotypes import Point
from dlgo.utils import print_board
# Define the sample SGF string, which will come later from the downloaded data
sgf_content = "(;GM[1]FF[4]SZ[9];B[ee];W[ef];B[ff]" + ";W[df];B[fe];W[fc];B[ec];W[gd];B[fb])"
# Using the from string method, you can create an SGF game
sgf_game = Sgf_game.from_string(sgf_content)
game_state = GameState.new_game(19)
# Repeat the main sequence of the game, you ignore board changes and reviews
for item in sgf_game.main_sequence_iter():
# The terms in this main sequence are (color, falling) pairs, where "falling" is a pair of coordinates.
color, move_tuple = item.get_move()
if color is not None and move_tuple is not None:
row, col = move_tuple
point = Point(row + 1, col + 1)
move = Move.play(point)
# Apply the read drop to the chessboard
game_state = game_state.apply_move(move)
print_board(game_state.board)Essentially, after you have a valid SGF string, you can get the main sequences based on it, which you can get by iterating. The above code is the core of this chapter, which gives a rough outline of how to continue to process the data required for deep learning:
- Download and extract the go game file.
- Traverse each SGF file contained in these files, read the contents of the file into strings, and then create a Sgf_game from these strings.
- Read out the main order of go game of each SGF string, ensure to handle important details, such as placing pieces, and input the generated drop data into the GameState object.
- For each drop, the chessboard situation is encoded into features by an encoder, and the drop itself is stored as a label, and then placed on the chessboard. In this way, you will create the drop prediction data for further learning in later exercises.
- 5. Store the generated features and tags in the appropriate format so that you can add them to the neural network later.
In the next few sections, you will work on these five tasks in great detail. After processing the data, you can go back to your post prediction application to see how the data affects the post prediction accuracy.
7.2.2. Build go data processor
In this section, you will build a go data processor that converts raw SGF data into features and tags for machine learning algorithms. This will be a relatively long implementation, so I'll break it up into several parts. When you're done, you're ready to run a deep learning model on real data.
To start, create a new file called processor.py under the data module. Let's import several Core Python libraries. In addition to NumPy for data output, you need quite a lot of packages to process the files.
import os.path import tarfile import gzip import glob import shutil import numpy as np from keras.utils import to_categorical
As for the functionality required by dlgo itself, you need to import many of the core classes that have been built so far.
from dlgo.gosgf.sgf import Sgf_game from dlgo.agent.FastRandomAgent.goboard_fast import Board, GameState, Move from dlgo.gotypes import Player, Point from dlgo.Encoder.Base import get_encoder_by_name from dlgo.data.index_processor import KGSIndex from dlgo.data.sampling import Sampler # Sampling training and test data from files
We haven't introduced the last two, but we will introduce them in building go data processors. To continue using processor.py, GoDataProcessor is initialized by providing an Encoder as a string and a data "directory" to store the go Secretary path
class GoDataProcessor:
def __init__(self,encoder="OnePlaneEncoder",data_directory="data"):
self.encoder = get_encoder_by_name(encoder,19)
self.data_directory = data_directoryNext, you'll implement the main data processing method, called load_go_data. In this method, you can specify the number of games to process and the type of data to load, that is, training or test data. Load ﹣ go ﹣ data will download online game records from KGS, sample a specified number of games, process them by creating functions and labels, and then persist the results to local as NumPy array.
parallel.py
"""
//Converting sgf files to machine learning usable formats
"""
# File related class begin
import os.path
import tarfile
import gzip
import glob
import shutil
# File related class end
import os
from os import sys
import multiprocessing
import numpy as np
from keras.utils import to_categorical
from dlgo.gosgf.sgf import Sgf_game
from dlgo.agent.FastRandomAgent.goboard_fast import Board, GameState, Move
from dlgo.gotypes import Player, Point
from dlgo.Encoder.Base import get_encoder_by_name
from dlgo.data.index_processor import KGSIndex
from dlgo.data.Sample import Sampler
from dlgo.data.generator import DataGenerator
def worker(jobinfo):
try:
clazz, encoder, zip_file, data_file_name, game_list = jobinfo
clazz(encoder=encoder).process_zip(zip_file, data_file_name, game_list)
except (KeyboardInterrupt, SystemExit):
raise Exception('>>> Exiting child process.')
class GoDataProcessor:
def __init__(self,encoder="OnePlaneEncoder",data_directory="data"):
self.encoder = get_encoder_by_name(encoder,19)
self.data_directory = data_directory
self.encoder_string = encoder
# Load game training data
# data_type, you can select train or test,num_samples is the number of loads from the data
def load_go_data(self,data_type='train',num_samples=1000,use_generator=False):
"""index = KGSIndex(data_directory=self.data_directory)
index.download_files()"""
sampler = Sampler(data_dir=self.data_directory)
# Samples a specified data type and a specified number of office records.
data = sampler.draw_data(data_type,num_samples)
# Send load work to CPU
self.map_to_workers(data_type, data)
# Return generator and dataset based on Selection
if use_generator:
generator = DataGenerator(self.data_directory, data)
return generator
else:
features_and_labels = self.consolidate_games(data_type, data)
return features_and_labels
# Decompression data
def unzip_data(self, zip_file_name):
this_gz = gzip.open(self.data_directory + '/' + zip_file_name)
# Remove the suffix gz
tar_file = zip_file_name[0:-3]
this_tar = open(self.data_directory + '/' + tar_file, 'wb')
# Copy the contents of the extracted file to the "tar" file
shutil.copyfileobj(this_gz, this_tar)
this_tar.close()
return tar_file
# Process the compressed file, get the features and labels, and save all the sgf file subscripts under the zip folder in the game list
def process_zip(self,zip_file_name,data_file_name,game_index_list):
tar_file = self.unzip_data(zip_file_name)
zip_file = tarfile.open(self.data_directory+"/"+tar_file)
# Get all the file names under the zip
name_list = zip_file.getnames()
# Determine the total number of dropped data in this compressed file, which corresponds to the total number of data
total_examples = self.num_total_examples(zip_file, game_index_list, name_list)
# Infer the shape of features and labels from the encoder you use, i.e. (1,19,19)
shape = self.encoder.shape()
# Insert the total number of data into the first shape array. Such a thinking array has several three-dimensional arrays, that is, it represents several disk faces, and each three-dimensional array is a single plane shape after coding
feature_shape = np.insert(shape, 0, np.asarray([total_examples]))
features = np.zeros(feature_shape)
# One bureau should face one label, so there are several labels in several bureaus
labels = np.zeros((total_examples,))
# Subscripts for features and labels
counter = 0
# Traverse each file
for index in game_index_list:
name = name_list[index+1]
# Read the contents of the file
sgf_content = zip_file.extractfile(name).read()
# Use the from string method to create a SGF game based on the content of the file
sgf = Sgf_game.from_string(sgf_content)
# Get the initial game state
game_state,first_move_done = self.get_handicap(sgf)
# Traversing the main falling subsequence in a file
for item in sgf.main_sequence_iter():
color,move_tuple = item.get_move()
point = None
if color is not None:
# Have fallen
if move_tuple is not None:
row,col =move_tuple
point = Point(row+1,col+1)
move = Move.play(point)
# Player pass ed
else:
move = Move.pass_turn()
#If the first step is done, add the previous situation and the next step to the feature and tag array after coding
if first_move_done and point is not None:
features[counter] = self.encoder.encode(game_state)
labels[counter] = self.encoder.encode_point(point)
counter+=1
game_state = game_state.apply_move(move)
first_move_done = True;
# Save feature matrix and label matrix to file
feature_file_base = self.data_directory + '/' + data_file_name + '_features_%d'
label_file_base = self.data_directory + '/' + data_file_name + '_labels_%d'
chunk = 0 # Because the file contains a lot of content, it is split after chunksize
chunksize = 1024
# Divide the total data by 1024, and save each block in a separate file
while features.shape[0] >= chunksize:
feature_file = feature_file_base % chunk
label_file = label_file_base % chunk
chunk += 1
# The current block and function and label are cut off
current_features, features = features[:chunksize], features[chunksize:]
current_labels, labels = labels[:chunksize], labels[chunksize:]
# It is then stored in a separate file, each of which stores 1024 pieces of data
np.save(feature_file, current_features)
np.save(label_file, current_labels)
# Merge all arrays into one
def consolidate_games(self, data_type, samples):
files_needed = set(file_name for file_name, index in samples)
file_names = []
for zip_file_name in files_needed:
file_name = zip_file_name.replace('.tar.gz', '') + data_type
file_names.append(file_name)
feature_list = []
label_list = []
for file_name in file_names:
file_prefix = file_name.replace('.tar.gz', '')
base = self.data_directory + '/' + file_prefix + '_features_*.npy'
for feature_file in glob.glob(base):
label_file = feature_file.replace('features', 'labels')
x = np.load(feature_file)
y = np.load(label_file)
x = x.astype('float32')
y = to_categorical(y.astype(int), 19 * 19)
feature_list.append(x)
label_list.append(y)
features = np.concatenate(feature_list, axis=0)
labels = np.concatenate(label_list, axis=0)
np.save('{}/features_{}.npy'.format(self.data_directory, data_type), features)
np.save('{}/labels_{}.npy'.format(self.data_directory, data_type), labels)
def map_to_workers(self, data_type, samples):
zip_names = set()
indices_by_zip_name = {}
for filename, index in samples:
zip_names.add(filename)
if filename not in indices_by_zip_name:
indices_by_zip_name[filename] = []
indices_by_zip_name[filename].append(index)
zips_to_process = []
for zip_name in zip_names:
base_name = zip_name.replace('.tar.gz', '')
data_file_name = base_name + data_type
if not os.path.isfile(self.data_directory + '/' + data_file_name):
zips_to_process.append((self.__class__, self.encoder_string, zip_name,
data_file_name, indices_by_zip_name[zip_name]))
cores = multiprocessing.cpu_count() # Determine number of CPU cores and split work load among them
pool = multiprocessing.Pool(processes=cores)
p = pool.map_async(worker, zips_to_process)
try:
_ = p.get()
except KeyboardInterrupt: # Caught keyboard interrupt, terminating workers
pool.terminate()
pool.join()
sys.exit(-1)
# Get the initial chessboard state of the conceded (possibly not conceded) chess piece. After the conceded, it means that the black chess piece has given up the right of first move, so the first move done is true
@staticmethod
def get_handicap(sgf):
go_board = Board(19, 19)
first_move_done = False
move = None
game_state = GameState.new_game(19)
# If you have a pawn, add a pawn
if sgf.get_handicap() is not None and sgf.get_handicap() != 0:
for setup in sgf.get_root().get_setup_stones():
for move in setup:
row, col = move
go_board.place_stone(Player.black, Point(row + 1, col + 1))
first_move_done = True
game_state = GameState(go_board, Player.white, None, move)
return game_state, first_move_done
def num_total_examples(self, zip_file, game_index_list, name_list):
total_examples = 0
for index in game_index_list:
name = name_list[index + 1]
# Suffix is. sgf
if name.endswith('.sgf'):
# Read the contents of sgf file
sgf_content = zip_file.extractfile(name).read()
# Create a SGF game based on content
sgf = Sgf_game.from_string(sgf_content)
game_state, first_move_done = self.get_handicap(sgf)
# Just count the number of real drops
num_moves = 0
for item in sgf.main_sequence_iter():
color, move = item.get_move()
if color is not None:
if first_move_done:
num_moves += 1
first_move_done = True
total_examples = total_examples + num_moves
else:
raise ValueError(name + ' is not a valid sgf')
return total_examples
if __name__ == "__main__":
process = GoDataProcessor()
generator = process.load_go_data('train', 100, use_generator=True)
print(generator.get_num_samples())
generator = generator.generate(batch_size=10, num_classes=361)
x, y = next(generator)
print(x)
print("-------------------")
print(y)
generator.py
import numpy as np
import glob
from keras.utils import to_categorical
# Process data samples to provide data for training when it needs a batch of data
class DataGenerator:
def __init__(self,data_directory,samples):
self.data_directory = data_directory
self.samples = samples
self.files = set(file_name for file_name,index in samples)
self.num_samples = None
# Number of samples obtained
def get_num_samples(self,batch_size=128,num_classes=361):
if self.num_samples is not None:
return self.num_samples
else:
self.num_samples = 0
for x, y in self._generate(batch_size=batch_size, num_classes=num_classes):
self.num_samples += x.shape[0]
return self.num_samples
def _generate(self, batch_size, num_classes):
for zip_file_name in self.files:
file_name = zip_file_name.replace('.tar.gz', '') + 'train'
base = self.data_directory + '/' + file_name + '_features_*.npy'
for feature_file in glob.glob(base):
label_file = feature_file.replace('features', 'labels')
x = np.load(feature_file)
y = np.load(label_file)
x = x.astype('float32')
y = to_categorical(y.astype(int), num_classes)
while x.shape[0] >= batch_size:
x_batch, x = x[:batch_size], x[batch_size:]
y_batch, y = y[:batch_size], y[batch_size:]
yield x_batch, y_batch # Return a small batch
def generate(self, batch_size=128, num_classes=19 * 19):
while True:
for item in self._generate(batch_size, num_classes):
yield item7.3. Deep learning training with human data
Now you can access and process HighDan Go data to adapt to the mobile prediction model, let's connect these points and build a deep neural network for the data. In our GitHub repository, there is a module named network in our DLGO package. You will use it to provide an example architecture of neural network, which you can use as a baseline to build a strong mobile prediction model. In the network module, you will find three convolutional neural networks with different complexity, which are called small.py, media.py and size.py. Each file contains a list of layers returned that can be added to the sequential Keras model. You'll build a convolutional neural network of four convolution layers, followed by the last dense layer, all of which are ReLUactiv. In addition, you will use a new utility layer, zero patting2d layer, before each volume accumulation layer. Zero fill is an operation in which the input property is filled to 0. Let's do it together. You use your plane encoder from Chapter 6 as a 19 × 19 matrix. If you specify a fill of 2, this means that you add two columns 0, left and right, and two rows from 0 to the top and bottom of the matrix, resulting in an enlarged 23 × 23 matrix. In this case, zero filling is used to artificially increase the input of the convolution layer, so that the co convolution operation does not make the image shrink too much. Before we show you the code, we have to discuss a small technical problem. Recall that the input and output of the convolution layer are all sub International: we provide a small batch of filters, each of which is two-dimensional (that is, they have width and height). The order of these four dimensions (small batch size, number of filters, width and height) is a matter of convention. You will find two such orders in practice. Note that filters are also commonly referred to as channels (C) and small batch sizes are also referred to as number of examples (N). In addition, you can use shorthand width (W) and height (H). With this symbol, the two main orders are NWHC and NCWH. In Kalas, this command is for some obvious reasons. The lied data ﹐ Format and NWHC are called channel ﹐ last and NCWH channel ﹐ first. Now, the way you build the first Go board encoder, a plane encoder, is in the channel fir Saint Convention (the encoder board has shapes 1, 19, 19, which means that a single encoded plane is the first one). This means that you must first provide data_format=Channels_first as a parameter for all volume tiers. Let's see what this model looks like.
from keras.layers.core import Dense, Activation, Flatten
from keras.layers.convolutional import Conv2D, ZeroPadding2D
# The layer needed to deal with 9 * 9 chessboard
def layers(input_type):
return [
# Use ZeroPadding2D layer to enlarge the layer to avoid too small matrix after convolution
ZeroPadding2D(padding=3, input_shape=input_type, data_format='channels_first'),
Conv2D(48, (7, 7), data_format='channels_first'),
Activation('relu'),
# By using channels? First, you can specify that your feature input takes precedence in a flat dimension.
ZeroPadding2D(padding=2, data_format='channels_first'),
Conv2D(32, (5, 5), data_format='channels_first'),
Activation('relu'),
ZeroPadding2D(padding=2, data_format='channels_first'),
Conv2D(32, (5, 5), data_format='channels_first'),
Activation('relu'),
ZeroPadding2D(padding=2, data_format='channels_first'),
Conv2D(32, (5, 5), data_format='channels_first'),
Activation('relu'),
Flatten(),
Dense(512),
Activation('relu'),
]This layer function returns a list of Keras layers that you can add to the sequence model one by one. With these layers, you can now build an application that starts with t and performs the first five steps. He outlines an application in Figure 7.1 that downloads, extracts, and encodes Go data and uses it to train neural networks. For the training section, you will use the data generator you built. But first, let's import some basic components of your growing Go machine learning library. You need the Go data processor, encoder, and neural network architecture to build this application.
from dlgo.data.parallel_processor import GoDataProcessor from dlgo.Encoder.OnePlaneEncoder import OnePlaneEncoder from dlgo.network import SmallLayer as small from keras.models import Sequential from keras.layers.core import Dense from keras.callbacks import ModelCheckpoint # Storage progress.
Finally, we import the Keras tool named ModelCheckpoint. Because it can take hours or even days for you to access a lot of data for training to build a model. If such an experiment fails for some reason, you'd better have a backup. And that's what model checkpoint does for you: they save a model after each round of training. Even if something fails, you can resume training from the last checkpoint.
Next, let's define training and test data. To do this, first initialize OnePlaneEncoder to create the GoDataProcessor. With this processor, you can instantiate a training and a test data generator that will be used with the Keras model.
if __name__ == '__main__':
go_board_rows, go_board_cols = 19, 19
num_classes = go_board_rows * go_board_cols
num_games = 100
# Create OnePlane encoder
encoder = OnePlaneEncoder((go_board_rows, go_board_cols))
# Initialize go data process
processor = GoDataProcessor(encoder=encoder.name())
# Create training data generator
generator = processor.load_go_data('train', num_games, use_generator=True)
# Create test data generator
test_generator = processor.load_go_data('test', num_games, use_generator=True)Next, you can use the Layers function in dlgo.networks.small.py to define a neural network with Keras. You add the Layers of this small network to a new sequential network one by one, and then add a final Dense layer and Softmax activation. Then the model is compiled with the classification cross entropy loss and trained with SGD.
input_shape = (encoder.num_planes, go_board_rows, go_board_cols)
network_layers = small.layers(input_shape)
model = Sequential()
for layer in network_layers:
model.add(layer)
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])Using generators to train the Keras model works slightly differently than using datasets. Instead of calling fit on the model, you need to replace evaluate with evaluate. In addition, the characteristics of these methods are slightly different from what you saw before. Use the fit? Generator to specify a generator, the number of training rounds, and the step? Per? Epoch you provide. These three parameters provide the minimum value of the training model. You also want to validate the training process with test data. To do this, you can use the test data generator to provide validation_data and specify the number of validation steps per round as validation_steps. Finally, add a callback to the model to store the Keras model after each round. As an example, you train a five round model with a batch size of 128
input_shape = (encoder.num_planes, go_board_rows, go_board_cols)
network_layers = small.layers(input_shape)
model = Sequential()
for layer in network_layers:
model.add(layer)
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
# end::train_generator_model[]
# tag::train_generator_fit[]
epochs = 5
batch_size = 128
model.fit_generator(generator=generator.generate(batch_size, num_classes), # <1>
epochs=epochs,
steps_per_epoch=generator.get_num_samples() / batch_size, # <2>
validation_data=test_generator.generate(batch_size, num_classes), # <3>
validation_steps=test_generator.get_num_samples() / batch_size, # <4>
callbacks=[ModelCheckpoint('../checkpoints/small_model_epoch_{epoch}.h5')]) # <5>
model.evaluate_generator(generator=test_generator.generate(batch_size, num_classes),
steps=test_generator.get_num_samples() / batch_size) # <6>Note that if you run this code yourself, you should know the time required to complete this experiment. If you run this on the CPU, a round of training may take several hours. Just as it happens, the mathematics used in machine learning has a lot in common with the mathematics used in computer graphics. Therefore, in some cases, you can move your neural network computing to your GPU, so you can get a big acceleration.
If you want to use GPU for machine learning, NVIDIA chip with Windows or Linux operating system is the best support combination.
If you don't want to try this on your own, or just don't want to do it now, we have pre calculated the model for you. Take a look at our GitHub repository, and here's the output of the training run (calculated on the old CPU on your laptop to encourage you to get a fast GPU immediately)

As you can see, after three rounds, it has achieved 98% training accuracy and 84% test data. This is a huge step forward, in order to build a really strong opponent, you need to use a better go data encoder next step. In section 7.4, you will learn about two more complex encoders, which will improve your training performance.
7.4. Build a better go data code
Chapter 2 and Chapter 3 cover the rules of looting in go. Recall that this rule exists to prevent infinite loops in the game. If we give you a random chessboard situation, you have to decide whether there is a robbery. There is no way to know without seeing the sequence that led to this situation. In particular, you use a plane encoder, which encodes black pieces as 1, white pieces as - 1, and empty positions as 0. It is impossible to know any information about robbery. The oneplane encoder you built in Chapter 6 is a bit too simple to capture all the content you need to build a powerful go AI.
In this section, we will provide you with two more fine-grained encodings that can lead to relatively strong performance of the drop prediction. The first is called SevenPlaneEncoder, which consists of seven feature planes. Each plane is a 19 × 19 matrix, which describes a set of different characteristics:
- The first plane uses 1 to represent a white chess with only one tone, otherwise it is all 0.
- The second and the third feature planes represent the white chess with two or at least three tones with 1 respectively.
- The fourth to sixth planes are the same for black stones; they encode 1, 2 or at least 3 tones of black chess.
- The last plane is marked with a point that can't be dropped, because the robber is marked with 1.
In addition to the concept of explicitly encoding ko, using this set of functions, you can also simulate Qi and distinguish between black and white chess. Chess pieces with only one breath have extra meaning because they may be eaten in the next round. Because the model can directly "see" this property, it's easier for it to understand how this affects the game. By creating planes for concepts such as hijacking and Qi, you can give hints about models that are important without having to explain how or why they are important.
Let's see how this can be achieved by extending from the encoder. Save the following code in sevenplane.py.
import numpy as np
from dlgo.Encoder.Base import Encoder
from dlgo.gotypes import Point
from dlgo.agent.FastRandomAgent.goboard_fast import Move
class SevenPlaneEncoder(Encoder):
def __init__(self,board_width,board_height):
self.board_width = board_width
self.board_height = board_height
self.num_planes = 7
def name(self):
return "SevenPlanEncoder"The following implementation code:
def encode(self, game_state):
board_matrix = np.zeros(self.shape())
# White starts with 0 subscript plane, black starts with 3 subscript plane
base_plane = {
game_state.current_player: 0,
game_state.current_player.other: 3
}
for row in self.board_width:
for col in self.board_height:
point = Point(row+1, col+1)
point_string = game_state.board.get_go_string(point)
if point_string is None:
# Set robbery on the last layer: set the robbery that cannot be recalled to 1
if game_state.does_move_violate_ko(game_state.current_player, Move.play(point)):
board_matrix[6][row][col] = 1
else:
# Level 1-3 is reserved for white chess, with 1, 2 and at least 3 tones of white chess
# Level 4-6 is reserved for black chess, which saves 1, 2 and only kills 3 tones of white chess
liberty_plane = min(3, point_string.num_liberties)-1
liberty_plane += base_plane[point_string.color]
board_matrix[liberty_plane][row][col] = 1
def encode_point(self, point):
return self.board_width*(point.row-1)+(point.col-1)
def decode_point_index(self, index):
row = index // self.board_width + 1
col = index % self.board_width + 1
return Point(row, col)
def num_points(self):
return self.board_height*self.board_width
def shape(self):
return self.num_planes, self.board_width, self.board_height
def create(board_width, board_height):
return SevenPlaneEncoder(board_width, board_height)There is also an encoder that represents 11 feature planes, similar to the SevenPlaneEncoder, which is called SimpleEncoder. The feature planes are as follows:
- The first four feature planes describe black chess with 1, 2, 3 and 4 tone respectively.
- The last four feature planes describe the white chess with 1, 2, 3 and 4 tone respectively.
- If it's black chess's turn, set the ninth feature plane to 1. If it's white chess's turn, set the tenth feature plane to 1.
- The last feature plane also represents robbery.
import numpy as np
from dlgo.Encoder.Base import Encoder
from dlgo.gotypes import Point,Player
from dlgo.agent.FastRandomAgent.goboard_fast import Move
class ElevenPlaneEncoder(Encoder):
def __init__(self, board_width, board_height):
self.board_width = board_width
self.board_height = board_height
self.num_planes = 11
def name(self):
return "ElevenPlanEncoder"
def encode(self, game_state):
board_matrix = np.zeros(self.shape())
# White starts with 0 subscript plane, black starts with 3 subscript plane
base_plane = {
game_state.current_player: 0,
game_state.current_player.other: 4
}
# Turn black
if game_state.current_player == Player.black:
board_matrix[8] = 1
# Turn white
else:
board_matrix[9] = 1
for row in self.board_width:
for col in self.board_height:
point = Point(row+1, col+1)
point_string = game_state.board.get_go_string(point)
if point_string is None:
# Set robbery on the last layer: set the robbery that cannot be recalled to 1
if game_state.does_move_violate_ko(game_state.current_player, Move.play(point)):
board_matrix[10][row][col] = 1
else:
# Layers 1-4 are reserved for white chess, with 1, 2, 3 and 4 tones respectively
# Level 5-8 is reserved for black chess, with 1, 2, 3 and 4 tones of white chess
liberty_plane = min(4, point_string.num_liberties)-1
liberty_plane += base_plane[point_string.color]
board_matrix[liberty_plane][row][col] = 1
def encode_point(self, point):
return self.board_width*(point.row-1)+(point.col-1)
def decode_point_index(self, index):
row = index // self.board_width + 1
col = index % self.board_width + 1
return Point(row, col)
def num_points(self):
return self.board_height*self.board_width
def shape(self):
return self.num_planes, self.board_width, self.board_height
def create(board_width, board_height):
return ElevenPlaneEncoder(board_width, board_height)This 11 plane encoder is more specific to a string of chess pieces. Both of them are good coders, which will lead to significant improvement of model performance.
Throughout chapters 5 and 6, you learned a lot about deep learning techniques, but one of the important experimental elements is that you use random gradient descent (SGD) as the optimizer. Although SGD provides a good baseline, in the next section, we will teach you the Adagrad and Adadelta optimizers, which will greatly benefit your training process.
7.5. Adaptive training
In order to further improve the performance of go drop prediction model, we will introduce the optimizer other than the last set of tools, random gradient descent (SGD). Looking back at Chapter 5, SGD has a fairly simple update rule. If you receive a back propagation error of Δ W and a specific α learning rate for parameter W, updating this parameter with SGD is only a calculation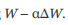 . In many cases, this update rule can lead to good results, but there are also some disadvantages. To solve these problems, you can use many other excellent optimizers
. In many cases, this update rule can lead to good results, but there are also some disadvantages. To solve these problems, you can use many other excellent optimizers
7.5.1.SGD decline and momentum
For example, a widely used idea is to let the learning rate decay over time; as you take each update step, the learning rate will decrease. This technology is usually very effective, because at the beginning, your network has not learned anything, so a large update step may cause the smallest loss, but when the training process reaches a certain level, you should make your update smaller, and only make appropriate improvements to the learning process that does not damage the progress. Usually, you specify a decay rate to represent the learning rate decay, and this percentage decline will make you reduce the next step.
Another popular technology is momentum technology, in which a small part of the last update step is added to the current update step. For example, if W is the parameter vector you want to update, and] W is the current gradient of W, if the last update you used was U, the next update step would be as follows:
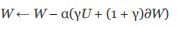
The fraction g retained from the last update is called the momentum term. If the two gradient terms point in roughly the same direction, the next update step will be enhanced (momentum received). If the gradients point in the opposite direction, they cancel each other and the gradients are suppressed. This technique is called momentum, because physical concepts have the same name, you can think of your loss function as a surface, and the parameters inside are like a ball rolling down the surface, and the parameters update as if the ball is moving. If you're doing a gradient descent, you can imagine the ball rolling down one by one. If the last steps (gradients) all point in the same direction, the ball will speed up to its destination. Momentum technology uses this analogy.
If you want to use decay, momentum, or both in SGD, provide the respective ratios. If the learning rate of SGD is 0.1, the attenuation rate is 1%, and the momentum is 90%, you will do the following work
from keras.optimizers import SGD sgd = SGD(lr=0.1, momentum=0.9, decay=0.01)
7.5.2. Using Adagrad to optimize neural network
Learning rate decay and momentum are both good at improving SGD, but there are still some weaknesses. For example, if you think about the go board, the professional players can only play in the third to fifth lines of the board in the first few steps, never in the first or second line, but at the end of the game, the situation is reversed, because many of the final pieces will fall on the border of the board. Of all the deep learning models you've used so far, the last layer is the Dense layer (19 by 19 here). Each neuron in this layer corresponds to a drop point on the chessboard. If you use SGD, whether there is momentum or attenuation or not, these neurons learn at the same rate, which can cause problems. Maybe you have bad data in training, and your learning rate has dropped so much that you don't get any important updates on the first and second lines, which means no learning. In general, you want to make sure that rarely observed patterns are still updated large enough, while frequently used patterns are getting smaller and smaller updates.
To solve the problem of setting up a global learning rate, you can use adaptive gradient technology. We're going to show you two ways: Adagrad and Adadelta
In Adagrad, there is no global learning rate, and you can adjust the learning rate for each parameter. When you have a lot of data, Adagrad works well, and the patterns in the data are rarely found. These standards are very suitable for our situation: Although you have a lot of data, professional go games are very complex, so that some drop combinations rarely appear in your data set.
Let's say you have a weight vector W with a length of l (it's easier to think of a vector here, but this technique is also more common for tensors), where the individual components are set to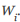 . Given the gradient] W for these parameters, in the general SGD with a learning rate, the updating rules for each Wi are as follows:
. Given the gradient] W for these parameters, in the general SGD with a learning rate, the updating rules for each Wi are as follows:
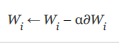
In Adagrad, you replace alpha with something that dynamically adapts to each index i by looking at how many Wi's you've updated in the past. In fact, in Adagrad, an individual's learning rate is proportional to previous updates. More precisely, in Adagrad, you update the parameters as follows:
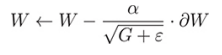
In this formula, ε is a small positive value to ensure that the denominator is not zero, and GI is the sum of the square gradient Wi to this point. We write this as GI because you can see that it is part of the square matrix G of length l, where all diagonal terms Gj have the form we just described, and all non diagonal terms are 0, so this form of matrix is called diagonal matrix. After each parameter update, update the G matrix by adding the latest gradient to the diagonal elements, but if you want to write this update rule in a concise form independent of index i, the formula is as follows
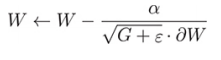
Note that since G is a matrix, you need to add ε to each component Gi and divide α by each component. In addition, G.]W is the matrix multiplication of G and W. Using this optimizer to create the model works as follows.
from keras.optimizers import Adagrad adagrad = Adagrad()
A key benefit of Adagrad over other SGD technologies is that you don't have to set the learning rate manually. In fact, you can change the initial learning rate of Keras by using Adagrad (lr=0.02), but this is not recommended
7.5.3. Refining adaptive gradient with Adadelta
An optimizer similar to Adagrad is Adadelta. In this optimizer, instead of accumulating all the past (square) gradients in the G matrix, we use our momentum technology to keep only a small part of the last update and add the current gradient to it:
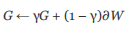
Although the idea is roughly what happened in Adadelta, the details of the optimizer's work are a little too complicated here. We suggest you check the original document for more details( https://arxiv.org/abs/1212.5701)
In keras, you use the Adadelta optimizer as follows:
from keras.optimizers import Adadelta adadelta = Adadelta()
Compared with SGD, Adagrad and Adadelta are very useful for the training of deep neural network on go data. In later chapters, you will often use one of these as the optimizer for the model.
7.6 run your own examples and evaluate performance
In Chapters 5, 6, and this chapter, we show you many deep learning techniques. We gave you some hints and sample architectures as a baseline, but now it's time to train your own model. In machine learning experiment, it is very important to try various Super parameter combinations, such as the number of layers, which layer to choose, the number of training rounds and so on. In particular, with deep neural networks, you may face a large number of choices, not always so clear how to adjust a specific parameter to affect the performance of the model. Deep learning researchers can rely on decades of experimental results and further theoretical arguments to have some intuition, but we can not provide you with such deep knowledge, but we can help you start to build your intuition.
One of the key factors for an experimental device like ours to achieve good results is to train a neural network as fast as possible to predict the fall of go. The time required to build the model architecture, start model training, observe and evaluate performance indicators, and then go back to adjust the model and restart the process must be short. When you look at the challenges of data science, like those on kaggle.com, it's the teams that try the most that win. You're lucky that keras can quickly build examples like that. This is one of the main reasons why we choose it as the deep learning framework of this book.
7.6.1. Guidelines for testing architecture and superparameters
Let's look at some practical considerations when building a sub prediction network:
- Convolution neural network is a good choice for Weiqi drop prediction network. Using only the Dense layer will result in lower prediction quality. It is usually necessary to build a network consisting of several convolution layers and one or two density layers. In later chapters, you'll see more complex architectures, but for now, convolutional networks are used.
- In your convolution layer, change the size of the convolution kernel to see how this change affects the performance of the model. Generally speaking, the convolution kernel size between 2 and 7 is appropriate, and you should not be much larger than this.
- If you use pooling layers, make sure you use both max and average pools, but more importantly, don't choose too large a pool size. In your case, an actual upper limit might be (3,3). You may also want to try to build a network without a pooling layer, which takes a lot of time to calculate, but can achieve good results.
- Use dropout layer for regularization. In Chapter 6, you saw how to use dropout to prevent the model from over fitting. If you don't use too many draw layers or set the Dropout rate too high, your network will usually benefit.
- Using softmax to activate the generation probability distribution in the last layer is beneficial, and if it is combined with the classification cross entropy loss, it will be very suitable for your use case.
- Experiments were carried out with different activation functions. We've introduced you to relu, which should be your default choice now, as well as Sigmoid activation. You can use a number of other activation functions in Keras, such as elu, selu, PReLU, and Leaky ReLU. We may not discuss these relu variants here, but their usage is https://keras.io/activations/ Good description found in
- The changing size of small training set will affect the performance of the model. For prediction problems, such as the prediction of MNIST handwritten numbers in Chapter 5, it is generally recommended to select a small training set size of the same order of magnitude as the class number. For MNIST, you often see training set sizes from 10 to 50. If the data is completely random, each gradient will receive information from each class, which makes SGD usually perform better. In our use case, some go drops are more frequent than others. For example, the four sharp corners of go are rarely played, especially when compared with star positions. We call it class imbalance in data. In this case, you can't expect a small training set. All classes should use training sets ranging from 16 to 256. The choice of optimizer will also have a great impact on your network, such as SGD with or without learning rate decay, and Adagrad and Adadelta. At h https://keras.io/optimizers/ Next you will find other optimizers.
- The number of rounds used to train the model must be selected appropriately. If you use model checkpoints and track various performance metrics for each round, you can effectively measure when the training stops. In the next and final section of this chapter, we will briefly discuss how to evaluate performance metrics. Generally speaking, with enough computing power, the number of set rounds is too high rather than too low. If the model training stops improving, it will even become worse due to over fitting
Weight initialization
Another key aspect of adjusting deep neural network is how to initialize weights before training. Because optimizing the network means finding the weight needed to minimize the loss on the loss surface, the weight you start with is important. In Chapter 5, we randomly assign the initial weight, which is usually a bad way.
Weight initialization is an interesting research topic, which is worth writing a chapter. There are many weight initialization schemes in keras, and each weighted layer can be initialized accordingly, but the default selection of keras is usually very good, so it is not worth worrying about changing them.
7.6.2. Evaluate performance indicators of training and test data
In Section 7.3, we show you the results of a training run on a small dataset. The network we use is a relatively small convolution network, and then we train the network for five rounds. Then we track the loss and accuracy of training data, and use test data to verify. Finally, we calculate the accuracy of the test data. This is the general workflow you should follow, but can you judge when to stop training or detect when to close training? Here are some guidelines:
- Your training accuracy and loss will usually improve every round. In the later stage, these indicators will gradually decrease and sometimes fluctuate. If you don't see improvement in a few rounds, you may want to stop.
- At the same time, you should see what your test loss and accuracy look like. In the early stage, the loss of verification will continue to decrease, but later, it will often start to increase, which means that the model has been over fitted to the training data.
- If you use model checkpoints, select a model with high precision and low loss.
- If training and testing losses are high, try choosing a deeper network architecture or other super parameters.
- When the training error of your model is low, but the verification error is high, it means that there has been a fitting. This scenario usually does not occur when you have a really large training dataset. It's not a big problem to learn to have 170000 go games and millions of losers.
- To select a training data size that meets the hardware requirements. If a round of training takes more than a few hours, it's not very interesting. Instead, try to find a model that performs well on many medium-sized datasets, and then train the model again on as large datasets as possible.
- If you don't have a good GPU, you may want to choose to train your model in the cloud. In Appendix D, we will show you how to use the GPU training model for Amazon Web services (AWS).
- When running the comparison, don't stop learning the model that seems to be poor at the initial stage, because some models adapt slowly, and may catch up or even surpass later.
You may ask yourself how strong an AI you can build using the methods described in this chapter. The theoretical upper limit is this: the network will never be better than the data you provide. In particular, AI will not surpass human beings when supervised learning is used. In practice, if there is enough computing power and time, it is absolutely possible to reach the level of about 2 segments.
To achieve game performance beyond humans, you need to use reinforcement learning technology, which is introduced in Chapter 9. You can then build stronger robots in chapters 13 and 14, combining tree search, reinforcement learning, and supervised deep learning in Chapter 4. In the next chapter, we'll show you how to deploy a robot and let it interact with its environment by interacting with human opponents or other robots.
7.7. summary
- The ubiquitous smart game format (SGF) can be used for go and other game records.
- Go data can be processed in parallel for faster and more efficient generators.
- With a strong game record close to your profession, you can build a deep learning model to predict the end of go.
- If you know the important attributes of your training data, you can explicitly code them on the feature plane. Then, the model can quickly learn the relationship between feature planes and your predicted results. For go robots, you can add a string of feature planes of Qi.
- By using adaptive gradient technology, you can train more effectively, such as Adagrad or Adadelta. With the development of training, these algorithms adjust the learning rate dynamically.
- The final model training can be implemented in a relatively small script that you can use as a template to train your own AI.

