8. Sequence labeling
Task08 text classification
This study refers to Datawhale open source learning: https://github.com/datawhalechina/learn-nlp-with-transformers
The content is generally derived from the original text and adjusted in combination with their own learning ideas.
Personal summary: first, the structure of sequence annotation task is similar to text classification, including loading data, preprocessing data and fine tuning the pre training model. 2, When fine tuning the pre training model, the sequence annotation task has one more data_ The collator step, which is a data collector that feeds data to the model.
Sequence tagging can also be regarded as a token level classification problem: the token level classification task usually refers to predicting a tag result for each token in the text. The following figure shows a NER entity noun recognition task.
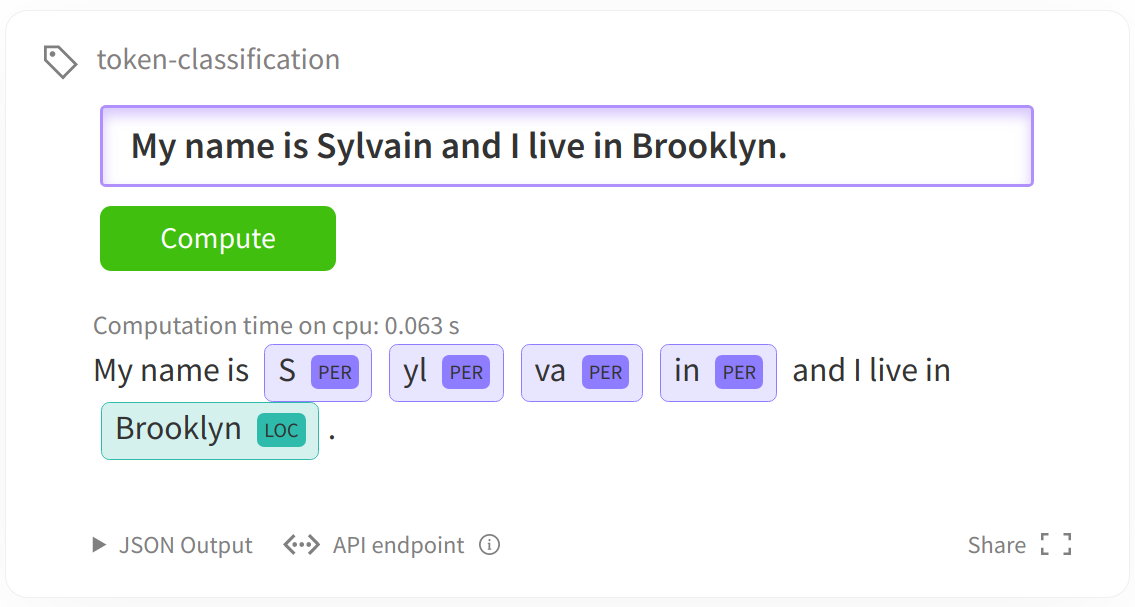
The most common token level classification tasks:
- Ner (named entity recognition) distinguishes nouns and entities in the text (person name, organization name, location point name...)
- POS (part of speech tagging) tagging token according to Grammar (noun, verb, adjective...)
- Chunk (Chunking phrase chunk) puts the tokens chunks of the same phrase together.
For the above tasks, we will show how to load datasets using a simple Dataset library and fine tune the pre training model using the Trainer interface in transformer. As long as the top layer of the pre trained transformer model has a neural network layer for token classification (such as BertForTokenClassification mentioned in the previous chapter) (in addition, due to the new tokenizer feature of the transformer library, the corresponding pre training model may also need to have the function of fast tokenizer, see This watch),
task = "ner" #Expected 'ner', 'pos' or' chunk ' model_checkpoint = "distilbert-base-uncased" batch_size = 16
8.1 loading data
We will use Datasets Library to load data and the corresponding evaluation method. Data loading and evaluation method loading only need to simply use load_dataset and load_metric.
from datasets import load_dataset, load_metric
This example uses CONLL 2003 dataset Dataset. If you are using a json/csv file dataset that you have customized, you need to view it Dataset document To learn how to load. Custom datasets may need to make some adjustments in the name of the load attribute.
datasets = load_dataset("conll2003")
The datasets object itself is a DatasetDict Data structure. For training set, verification set and test set, you only need to use the corresponding key (train, validation, test) to get the corresponding data.
datasets
DatasetDict({
train: Dataset({
features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],
num_rows: 14041
})
validation: Dataset({
features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],
num_rows: 3250
})
test: Dataset({
features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],
num_rows: 3453
})
})
Whether in the training set, verification machine or test set, datasets contains a column named tokens (generally, the text is divided into many words) and a column named label, which corresponds to the annotation of the tokens.
Given a key (train, validation or test) and subscript of data segmentation, you can view the data.
datasets["train"][0]
{'chunk_tags': [11, 21, 11, 12, 21, 22, 11, 12, 0],
'id': '0',
'ner_tags': [3, 0, 7, 0, 0, 0, 7, 0, 0],
'pos_tags': [22, 42, 16, 21, 35, 37, 16, 21, 7],
'tokens': ['EU',
'rejects',
'German',
'call',
'to',
'boycott',
'British',
'lamb',
'.']}
All data labels have been encoded into integers and can be directly used by the pre trained transformer model. The actual categories corresponding to the encoding of these integers are stored in features.
datasets["train"].features[f"ner_tags"]
Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)
Therefore, take NER as an example, 0 corresponds to "O", 1 corresponds to "B-PER", etc. "O" means no special entity. This example includes four entity categories (PER, ORG, LOC, MISC), and each entity category has a B - (token at the beginning of the entity) prefix and an I - (token in the middle of the entity) prefix.
- 'PER' for person
- 'ORG' for organization
- 'LOC' for location
- 'MISC' for miscellaneous
label_list = datasets["train"].features[f"{task}_tags"].feature.names
label_list
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
In order to further understand what the data looks like, the following function will randomly select several examples from the data set.
from datasets import ClassLabel, Sequence
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
for column, typ in dataset.features.items():
if isinstance(typ, ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
elif isinstance(typ, Sequence) and isinstance(typ.feature, ClassLabel):
df[column] = df[column].transform(lambda x: [typ.feature.names[i] for i in x])
display(HTML(df.to_html()))
show_random_elements(datasets["train"])
| id | tokens | pos_tags | chunk_tags | ner_tags | |
|---|---|---|---|---|---|
| 0 | 2227 | [Result, of, a, French, first, division, match, on, Friday, .] | [NN, IN, DT, JJ, JJ, NN, NN, IN, NNP, .] | [B-NP, B-PP, B-NP, I-NP, I-NP, I-NP, I-NP, B-PP, B-NP, O] | [O, O, O, B-MISC, O, O, O, O, O, O] |
| 1 | 2615 | [Mid-tier, golds, up, in, heavy, trading, .] | [NN, NNS, IN, IN, JJ, NN, .] | [B-NP, I-NP, B-PP, B-PP, B-NP, I-NP, O] | [O, O, O, O, O, O, O] |
| 2 | 10256 | [Neagle, (, 14-6, ), beat, the, Braves, for, the, third, time, this, season, ,, allowing, two, runs, and, six, hits, in, eight, innings, .] | [NNP, (, CD, ), VB, DT, NNPS, IN, DT, JJ, NN, DT, NN, ,, VBG, CD, NNS, CC, CD, NNS, IN, CD, NN, .] | [B-NP, O, B-NP, O, B-VP, B-NP, I-NP, B-PP, B-NP, I-NP, I-NP, B-NP, I-NP, O, B-VP, B-NP, I-NP, O, B-NP, I-NP, B-PP, B-NP, I-NP, O] | [B-PER, O, O, O, O, O, B-ORG, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O] |
| 3 | 10720 | [Hansa, Rostock, 4, 1, 2, 1, 5, 4, 5] | [NNP, NNP, CD, CD, CD, CD, CD, CD, CD] | [B-NP, I-NP, I-NP, I-NP, I-NP, I-NP, I-NP, I-NP, I-NP] | [B-ORG, I-ORG, O, O, O, O, O, O, O] |
| 4 | 7125 | [MONTREAL, 70, 59, .543, 11] | [NNP, CD, CD, CD, CD] | [B-NP, I-NP, I-NP, I-NP, I-NP] | [B-ORG, O, O, O, O] |
| 5 | 3316 | [Softbank, Corp, said, on, Friday, that, it, would, procure, $, 900, million, through, the, foreign, exchange, market, by, September, 5, as, part, of, its, acquisition, of, U.S., firm, ,, Kingston, Technology, Co, .] | [NNP, NNP, VBD, IN, NNP, IN, PRP, MD, NN, $, CD, CD, IN, DT, JJ, NN, NN, IN, NNP, CD, IN, NN, IN, PRP$, NN, IN, NNP, NN, ,, NNP, NNP, NNP, .] | [B-NP, I-NP, B-VP, B-PP, B-NP, B-SBAR, B-NP, B-VP, B-NP, I-NP, I-NP, I-NP, B-PP, B-NP, I-NP, I-NP, I-NP, B-PP, B-NP, I-NP, B-PP, B-NP, B-PP, B-NP, I-NP, B-PP, B-NP, I-NP, O, B-NP, I-NP, I-NP, O] | [B-ORG, I-ORG, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O, B-LOC, O, O, B-ORG, I-ORG, I-ORG, O] |
| 6 | 3923 | [Ghent, 3, Aalst, 2] | [NN, CD, NNP, CD] | [B-NP, I-NP, I-NP, I-NP] | [B-ORG, O, B-ORG, O] |
| 7 | 2776 | [The, separatists, ,, who, swept, into, Grozny, on, August, 6, ,, still, control, large, areas, of, the, centre, of, town, ,, and, Russian, soldiers, are, based, at, checkpoints, on, the, approach, roads, .] | [DT, NNS, ,, WP, VBD, IN, NNP, IN, NNP, CD, ,, RB, VBP, JJ, NNS, IN, DT, NN, IN, NN, ,, CC, JJ, NNS, VBP, VBN, IN, NNS, IN, DT, NN, NNS, .] | [B-NP, I-NP, O, B-NP, B-VP, B-PP, B-NP, B-PP, B-NP, I-NP, O, B-ADVP, B-VP, B-NP, I-NP, B-PP, B-NP, I-NP, B-PP, B-NP, O, O, B-NP, I-NP, B-VP, I-VP, B-PP, B-NP, B-PP, B-NP, I-NP, I-NP, O] | [O, O, O, O, O, O, B-LOC, O, O, O, O, O, O, O, O, O, O, O, O, O, O, O, B-MISC, O, O, O, O, O, O, O, O, O, O] |
| 8 | 1178 | [Doctor, Masserigne, Ndiaye, said, medical, staff, were, overwhelmed, with, work, ., "] | [NNP, NNP, NNP, VBD, JJ, NN, VBD, VBN, IN, NN, ., "] | [B-NP, I-NP, I-NP, B-VP, B-NP, I-NP, B-VP, I-VP, B-PP, B-NP, O, O] | [O, B-PER, I-PER, O, O, O, O, O, O, O, O, O] |
| 9 | 10988 | [Reuters, historical, calendar, -, September, 4, .] | [NNP, JJ, NN, :, NNP, CD, .] | [B-NP, I-NP, I-NP, O, B-NP, I-NP, O] | [B-ORG, O, O, O, O, O, O] |
8.2 preprocessing data
Before feeding the data into the model, we need to preprocess the data. The preprocessing tool is tokenizer. Tokenizer first tokenizes the input, then converts the tokens into the corresponding token ID in the pre model, and then into the input format required by the model.
In order to achieve the purpose of data preprocessing, we instantiate our tokenizer using the autotokenizer.from_pre trained method, which can ensure that:
- We get a tokenizer corresponding to the pre training model one by one.
- When using the tokenizer corresponding to the specified model checkpoint, we also downloaded the thesaurus vocabulary required by the model, which is exactly tokens vocabulary.
The downloaded tokens volatile will be cached so that they will not be downloaded again when they are used again.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
Note: the following code requires that the tokenizer must be of type transformers.pretrained tokenizer fast, because we need to use some special features of fast tokenizer (such as multi-threaded fast tokenizer) during preprocessing.
Almost all tokenizers corresponding to models have corresponding fast tokenizer s. We can Model tokenizer correspondence table Check the characteristics of tokenizer corresponding to all pre training models.
import transformers assert isinstance(tokenizer, transformers.PreTrainedTokenizerFast)
stay big table of models Check whether the model has a fast tokenizer.
Tokenizer can preprocess either a single text or a pair of text. The data obtained by tokenizer after preprocessing meets the input format of pre training model
tokenizer("Hello, this is one sentence!")
{'input_ids': [101, 7592, 1010, 2023, 2003, 2028, 6251, 999, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
tokenizer(["Hello", ",", "this", "is", "one", "sentence", "split", "into", "words", "."], is_split_into_words=True)
{'input_ids': [101, 7592, 1010, 2023, 2003, 2028, 6251, 3975, 2046, 2616, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
Note that the transformer pre training model usually uses subword s during pre training. If our text input has been segmented into words, these words will continue to be segmented by our tokenizer. For example:
example = datasets["train"][4] print(example["tokens"])
['Germany', "'s", 'representative', 'to', 'the', 'European', 'Union', "'s", 'veterinary', 'committee', 'Werner', 'Zwingmann', 'said', 'on', 'Wednesday', 'consumers', 'should', 'buy', 'sheepmeat', 'from', 'countries', 'other', 'than', 'Britain', 'until', 'the', 'scientific', 'advice', 'was', 'clearer', '.']
tokenized_input = tokenizer(example["tokens"], is_split_into_words=True) tokens = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"]) print(tokens)
['[CLS]', 'germany', "'", 's', 'representative', 'to', 'the', 'european', 'union', "'", 's', 'veterinary', 'committee', 'werner', 'z', '##wing', '##mann', 'said', 'on', 'wednesday', 'consumers', 'should', 'buy', 'sheep', '##me', '##at', 'from', 'countries', 'other', 'than', 'britain', 'until', 'the', 'scientific', 'advice', 'was', 'clearer', '.', '[SEP]']
The words "Zwingmann" and "sheetmeat" continue to be segmented into three subtokens.
Since the labeled data is usually labeled at the word level, since word will also be segmented into subtokens, it means that we also need to align the labeled data with subtokens. At the same time, due to the requirements of the input format of the pre training model, we often need to add some special symbols, such as: [CLS] and [SEP].
len(example[f"{task}_tags"]), len(tokenized_input["input_ids"])
(31, 39)
tokenizer has a word_ids ` method that can help us solve this problem.
print(tokenized_input.word_ids())
[None, 0, 1, 1, 2, 3, 4, 5, 6, 7, 7, 8, 9, 10, 11, 11, 11, 12, 13, 14, 15, 16, 17, 18, 18, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, None]
We can see that word_ids matches each subtokens position with a word subscript. For example, the first position corresponds to the 0 word, and then the second and third positions correspond to the 1 word. The special characters correspond to None. With this list, we can align subtokens with words and labels marked with words.
word_ids = tokenized_input.word_ids()
aligned_labels = [-100 if i is None else example[f"{task}_tags"][i] for i in word_ids]
print(len(aligned_labels), len(tokenized_input["input_ids"]))
39 39
We usually set the label of special characters to - 100. In the model, - 100 is usually ignored and loss is not calculated.
We have two ways to align label s:
- Multiple subtokens align a word and a label
- The first subtoken of multiple subtokens is aligned with word and a label, and other subtokens are directly assigned - 100
We provide these two ways to switch through label_all_tokens = True.
label_all_tokens = True
Finally, we combine all the contents into our preprocessing function. is_split_into_words=True is over.
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
labels = []
for i, label in enumerate(examples[f"{task}_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
# Special tokens have a word id that is None. We set the label to -100 so they are automatically
# ignored in the loss function.
if word_idx is None:
label_ids.append(-100)
# We set the label for the first token of each word.
elif word_idx != previous_word_idx:
label_ids.append(label[word_idx])
# For the other tokens in a word, we set the label to either the current label or -100, depending on
# the label_all_tokens flag.
else:
label_ids.append(label[word_idx] if label_all_tokens else -100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
The above preprocessing function can process one sample or multiple samples exapmles. If multiple samples are processed, the result list after multiple samples are preprocessed will be returned.
tokenize_and_align_labels(datasets['train'][:5])
{'input_ids': [[101, 7327, 19164, 2446, 2655, 2000, 17757, 2329, 12559, 1012, 102], [101, 2848, 13934, 102], [101, 9371, 2727, 1011, 5511, 1011, 2570, 102], [101, 1996, 2647, 3222, 2056, 2006, 9432, 2009, 18335, 2007, 2446, 6040, 2000, 10390, 2000, 18454, 2078, 2329, 12559, 2127, 6529, 5646, 3251, 5506, 11190, 4295, 2064, 2022, 11860, 2000, 8351, 1012, 102], [101, 2762, 1005, 1055, 4387, 2000, 1996, 2647, 2586, 1005, 1055, 15651, 2837, 14121, 1062, 9328, 5804, 2056, 2006, 9317, 10390, 2323, 4965, 8351, 4168, 4017, 2013, 3032, 2060, 2084, 3725, 2127, 1996, 4045, 6040, 2001, 24509, 1012, 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'labels': [[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, -100], [-100, 1, 2, -100], [-100, 5, 0, 0, 0, 0, 0, -100], [-100, 0, 3, 4, 0, 0, 0, 0, 0, 0, 7, 0, 0, 0, 0, 0, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -100], [-100, 5, 0, 0, 0, 0, 0, 3, 4, 0, 0, 0, 0, 1, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5, 0, 0, 0, 0, 0, 0, 0, -100]]}
Next, preprocess all samples in the dataset datasets by using the map function to prepare the preprocessing function_ train_ Features are applied to all samples.
tokenized_datasets = datasets.map(tokenize_and_align_labels, batched=True)
Even better, the returned results will be automatically cached to avoid recalculation during the next processing (but also note that if the input is changed, it may be affected by the cache!) . the datasets library function will detect the input parameters to determine whether there is any change. If there is no change, the cached data will be used, and if there is any change, it will be reprocessed. However, if the input parameters remain unchanged, it is best to clean up the cache when you want to change the input. The cleaning method is to use the load_from_cache_file=False parameter. In addition, the parameter batched=True used above Number is a feature of tokenizer because it uses multiple threads to process input in parallel at the same time.
8.3 fine tuning the pre training model
Now that the data is ready, we need to download and load our pre training model, and then fine tune the pre training model. Since we are doing the seq2seq task, we need a model class that can solve this task. We use the AutoModelForTokenClassification class. Similar to tokenizer, the from_pre trained method can also help us download and update Loading the model will also cache the model, so the model will not be downloaded repeatedly.
from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer model = AutoModelForTokenClassification.from_pretrained(model_checkpoint, num_labels=len(label_list))
Downloading: 0%| | 0.00/268M [00:00<?, ?B/s] Some weights of the model checkpoint at distilbert-base-uncased were not used when initializing DistilBertForTokenClassification: ['vocab_transform.weight', 'vocab_layer_norm.bias', 'vocab_projector.bias', 'vocab_projector.weight', 'vocab_transform.bias', 'vocab_layer_norm.weight'] - This IS expected if you are initializing DistilBertForTokenClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model). - This IS NOT expected if you are initializing DistilBertForTokenClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model). Some weights of DistilBertForTokenClassification were not initialized from the model checkpoint at distilbert-base-uncased and are newly initialized: ['classifier.bias', 'classifier.weight'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Since our fine-tuning task is the token classification task, and we load the pre-trained language model, we will be prompted to throw away some mismatched neural network parameters when loading the model (for example, the neural network head of the pre-trained language model is thrown away, and the neural network head of token classification is initialized randomly at the same time).
In order to get a Trainer training tool, we also need three elements, the most important of which is the setting / parameters of training TrainingArguments . this training setting contains all the attributes that can define the training process.
args = TrainingArguments(
f"test-{task}",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=3,
weight_decay=0.01,
)
The above evaluation_strategy = "epoch" parameter tells the training code that we will do a verification evaluation for each epcoh.
The above batch_size is defined before the notebook.
Finally, we need a data collector data collator to feed the processed input to the model.
from transformers import DataCollatorForTokenClassification data_collator = DataCollatorForTokenClassification(tokenizer)
The last thing left to set up the Trainer is that we need to define the evaluation method seqeval metric to complete the evaluation. Before sending the model prediction to the evaluation, we will also do some data post-processing:
metric = load_metric("seqeval")
The input to the evaluation is the list of forecasts and label s
labels = [label_list[i] for i in example[f"{task}_tags"]]
metric.compute(predictions=[labels], references=[labels])
{'LOC': {'f1': 1.0, 'number': 2, 'precision': 1.0, 'recall': 1.0},
'ORG': {'f1': 1.0, 'number': 1, 'precision': 1.0, 'recall': 1.0},
'PER': {'f1': 1.0, 'number': 1, 'precision': 1.0, 'recall': 1.0},
'overall_accuracy': 1.0,
'overall_f1': 1.0,
'overall_precision': 1.0,
'overall_recall': 1.0}
Post process the model prediction results:
- Select the subscript of the maximum probability of prediction classification
- Convert subscript to label
- Ignore - 100 location
The following function combines the above steps.
import numpy as np
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
We calculate the total precision/recall/f1 of all categories, so we will throw away the precision/recall/f1 of a single category
Just pass the data / model / parameters into the Trainer
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
Call the train method to start training
trainer.train()
<div>
<style>
/* Turns off some styling */
progress {
/* gets rid of default border in Firefox and Opera. */
border: none;
/* Needs to be in here for Safari polyfill so background images work as expected. */
background-size: auto;
}
</style>
<progress value='2634' max='2634' style='width:300px; height:20px; vertical-align: middle;'></progress>
[2634/2634 01:45, Epoch 3/3]
</div>
<table border="1" class="dataframe">
TrainOutput(global_step=2634, training_loss=0.08569671253227518)
We can use the evaluate method again to evaluate other data sets.
trainer.evaluate()
[204/204 00:05]
{'eval_loss': 0.05934586375951767,
'eval_precision': 0.9292672127518264,
'eval_recall': 0.9391430808815304,
'eval_f1': 0.9341790463472988,
'eval_accuracy': 0.9842565968195466,
'epoch': 3.0}
If you want to get the precision/recall/f1 of a single category, we can directly enter the results into the same evaluation function:
predictions, labels, _ = trainer.predict(tokenized_datasets["validation"])
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
results
{'LOC': {'precision': 0.949718574108818,
'recall': 0.966768525592055,
'f1': 0.9581677077418134,
'number': 2618},
'MISC': {'precision': 0.8132387706855791,
'recall': 0.8383428107229894,
'f1': 0.8255999999999999,
'number': 1231},
'ORG': {'precision': 0.9055232558139535,
'recall': 0.9090466926070039,
'f1': 0.9072815533980583,
'number': 2056},
'PER': {'precision': 0.9759552042160737,
'recall': 0.9765985497692815,
'f1': 0.9762767710049424,
'number': 3034},
'overall_precision': 0.9292672127518264,
'overall_recall': 0.9391430808815304,
'overall_f1': 0.9341790463472988,
'overall_accuracy': 0.9842565968195466}
Finally, don't forget to upload the model to Model Hub (click) here To see how to upload).