Article directory
Preface
In zone, the file object data of zone is organized in the form of Block, similar to HDFS. However, when Ozone actually stores the Block, it stores it in the form of a more fine-grained chunk file. In short, multiple chunks will be divided under the Block. Each chunk file corresponds to a relative offset of the Block. The author of this article will talk about the layout of Ozone chunk, that is, the storage mode of chunk files on Datanode. In the original implementation, the separation of multiple chunk files also leads to the generation of a large number of chunk files, which is not efficient in efficiency. In the latest community optimization, Block can support a chunk for storage. Next, we will talk about these two layout methods.
Original layout of zone datanode chunk file
First of all, let's talk about the original layout of the Ozone Chunk file. What is the process?
1) First, a file is divided into multiple Block blocks according to block size
2) BlockOutputStream splits multiple chunk files according to chunk size to write out
There are some disadvantages in this way:
- If the Block setting is large, there will be many chunk files generated
- Each Block read / write operation involves the read / write of multiple chunk files. The read / write efficiency is not high enough
- In the process of reading and writing, we need to check many files, which also affects the efficiency
Therefore, the community implements a file layout method based on a Block by chunk to improve the efficiency of reading and writing Ozone files. The layout method of the original chunk is called file per chunk in name, and the new one is file per Block.
Ozone Datanode Chunk Layout: File > per > chunk and file > per > block
In essence, the above Chunk layout pattern correspondence is controlled by FilePerChunkStrategy and FilePerBlockStrategy in the Ozone Datanode.
The essential difference between the above two policies lies in the processing method of ChunkBuffer data sent from BlockOutputStream in Datanode:
How FilePerChunkStrategy is handled (old way): write it out as a new chunk file
How to handle FilePerBlockStrategy: append write at the current offset of the original chunk file
Use a more intuitive graphical process as follows: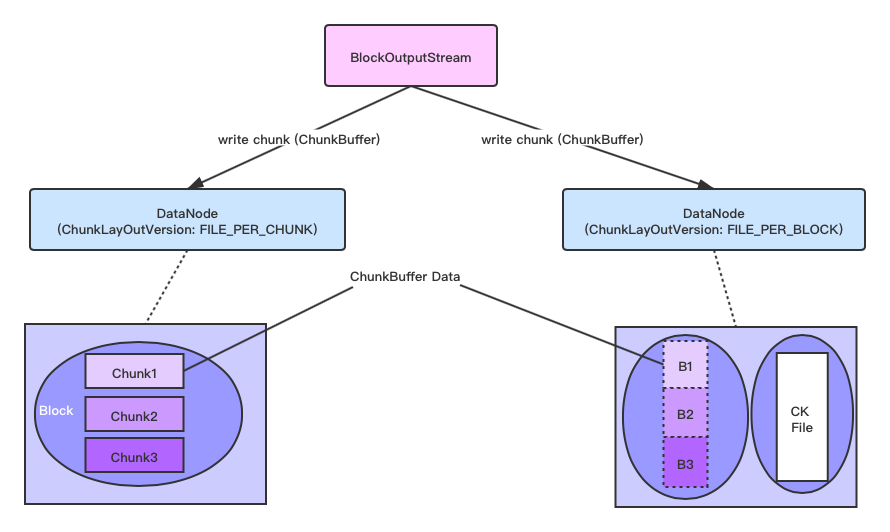
In the above figure, the chunk1, 2 and 3 files on the left of File > per > chunk correspond to different segments in a chunk file. In the file > per > Block mode, a chunk file has only one chunk file.
Let's look at the specific implementation logic, mainly in the file method of write chunk:
FilePerChunkStrategy (FilePerChunkStrategy.java):
public void writeChunk(Container container, BlockID blockID, ChunkInfo info, ChunkBuffer data, DispatcherContext dispatcherContext) throws StorageContainerException { checkLayoutVersion(container); Preconditions.checkNotNull(dispatcherContext); DispatcherContext.WriteChunkStage stage = dispatcherContext.getStage(); try { KeyValueContainerData containerData = (KeyValueContainerData) container .getContainerData(); HddsVolume volume = containerData.getVolume(); VolumeIOStats volumeIOStats = volume.getVolumeIOStats(); // 1) Get the path to this chunk file File chunkFile = ChunkUtils.getChunkFile(containerData, info); boolean isOverwrite = ChunkUtils.validateChunkForOverwrite( chunkFile, info); // 2) Get the temporary file path for this chunk File tmpChunkFile = getTmpChunkFile(chunkFile, dispatcherContext); if (LOG.isDebugEnabled()) { LOG.debug( "writing chunk:{} chunk stage:{} chunk file:{} tmp chunk file:{}", info.getChunkName(), stage, chunkFile, tmpChunkFile); } long len = info.getLen(); // Ignore offset value because it is a new standalone file long offset = 0; // ignore offset in chunk info switch (stage) { case WRITE_DATA: if (isOverwrite) { // if the actual chunk file already exists here while writing the temp // chunk file, then it means the same ozone client request has // generated two raft log entries. This can happen either because // retryCache expired in Ratis (or log index mismatch/corruption in // Ratis). This can be solved by two approaches as of now: // 1. Read the complete data in the actual chunk file , // verify the data integrity and in case it mismatches , either // 2. Delete the chunk File and write the chunk again. For now, // let's rewrite the chunk file // TODO: once the checksum support for write chunks gets plugged in, // the checksum needs to be verified for the actual chunk file and // the data to be written here which should be efficient and // it matches we can safely return without rewriting. LOG.warn("ChunkFile already exists {}. Deleting it.", chunkFile); FileUtil.fullyDelete(chunkFile); } if (tmpChunkFile.exists()) { // If the tmp chunk file already exists it means the raft log got // appended, but later on the log entry got truncated in Ratis leaving // behind garbage. // TODO: once the checksum support for data chunks gets plugged in, // instead of rewriting the chunk here, let's compare the checkSums LOG.warn("tmpChunkFile already exists {}. Overwriting it.", tmpChunkFile); } // 3) If it is in the stage of writing chunk file data, write temporary file ChunkUtils.writeData(tmpChunkFile, data, offset, len, volumeIOStats, doSyncWrite); // No need to increment container stats here, as still data is not // committed here. break; case COMMIT_DATA: ... // 4) If it is the end stage of the chunk file, rename the temporary file to the final official file commitChunk(tmpChunkFile, chunkFile); // Increment container stats here, as we commit the data. containerData.updateWriteStats(len, isOverwrite); break; case COMBINED: // directly write to the chunk file ChunkUtils.writeData(chunkFile, data, offset, len, volumeIOStats, doSyncWrite); containerData.updateWriteStats(len, isOverwrite); break; default: throw new IOException("Can not identify write operation."); } } catch (StorageContainerException ex) { throw ex; } catch (IOException ex) { throw new StorageContainerException("Internal error: ", ex, IO_EXCEPTION); } }
Let's look at another implementation of the policy policy of the chunk layout:
FilePerBlockStrategy.java
@Override public void writeChunk(Container container, BlockID blockID, ChunkInfo info, ChunkBuffer data, DispatcherContext dispatcherContext) throws StorageContainerException { checkLayoutVersion(container); Preconditions.checkNotNull(dispatcherContext); DispatcherContext.WriteChunkStage stage = dispatcherContext.getStage(); ... KeyValueContainerData containerData = (KeyValueContainerData) container .getContainerData(); // 1) Also get the path name of the chunk file File chunkFile = getChunkFile(containerData, blockID); boolean overwrite = validateChunkForOverwrite(chunkFile, info); long len = info.getLen(); // 2) Get the offset of chunk data corresponding to the block data, that is, the offset of the chunk file written by the block long offset = info.getOffset(); if (LOG.isDebugEnabled()) { LOG.debug("Writing chunk {} (overwrite: {}) in stage {} to file {}", info, overwrite, stage, chunkFile); } HddsVolume volume = containerData.getVolume(); VolumeIOStats volumeIOStats = volume.getVolumeIOStats(); // 3) Get the FileChannel corresponding to the chunk file from the open file cache FileChannel channel = files.getChannel(chunkFile, doSyncWrite); // 4) Read and write data at the specified offset location ChunkUtils.writeData(channel, chunkFile.getName(), data, offset, len, volumeIOStats); containerData.updateWriteStats(len, overwrite); }
Because a Block file may be written in a continuous period of time in the FILE_PER_BLOCK mode, the FileChannel cache is implemented here to avoid multiple file close and re open operations in a short period of time.
private static final class OpenFiles { private static final RemovalListener<String, OpenFile> ON_REMOVE = event -> close(event.getKey(), event.getValue()); // File cache of OpenFile private final Cache<String, OpenFile> files = CacheBuilder.newBuilder() .expireAfterAccess(Duration.ofMinutes(10)) .removalListener(ON_REMOVE) .build(); /** * Chunk Obtain the FileChannel of the file and open the file */ public FileChannel getChannel(File file, boolean sync) throws StorageContainerException { try { return files.get(file.getAbsolutePath(), () -> open(file, sync)).getChannel(); } catch (ExecutionException e) { if (e.getCause() instanceof IOException) { throw new UncheckedIOException((IOException) e.getCause()); } throw new StorageContainerException(e.getCause(), ContainerProtos.Result.CONTAINER_INTERNAL_ERROR); } } private static OpenFile open(File file, boolean sync) { try { return new OpenFile(file, sync); } catch (FileNotFoundException e) { throw new UncheckedIOException(e); } } /** * When the file in Open expires in the cache, clear the cache and close the file */ public void close(File file) { if (file != null) { files.invalidate(file.getAbsolutePath()); } } ... }
According to the test results of the above two methods written by the community, the new chunk layout method is much more efficient than the original file per chunk method, and has changed the file per block method to the default chunk layout. The configuration is as follows:
<property> <name>ozone.scm.chunk.layout</name> <value>FILE_PER_BLOCK</value> <tag>OZONE, SCM, CONTAINER, PERFORMANCE</tag> <description> Chunk layout defines how chunks, blocks and containers are stored on disk. Each chunk is stored separately with FILE_PER_CHUNK. All chunks of a block are stored in the same file with FILE_PER_BLOCK. The default is FILE_PER_BLOCK. </description> </property>
The actual storage comparison between the old and new layout s of Chunk
The author tests these two kinds of chunk layout methods in the actual test cluster to see how the actual chunk is stored. The following are the test results:
File per block layout mode:
[hdfs@lyq containerDir0]$ cd 11/chunks/ [hdfs@lyq chunks]$ ll total 16384 -rw-rw-r-- 1 hdfs hdfs 16777216 Mar 14 08:32 103822128652419072.block
File per chunk layout mode:
[hdfs@lyq ~]$ ls -l /tmp/hadoop-hdfs/dfs/data/hdds/762187f8-3d8d-4c2c-8659-9ca66987c829/current/containerDir0/4/chunks/103363337595977729_chunk_1 -rw-r--r-- 1 hdfs hdfs 12 Dec 24 07:56 /tmp/hadoop-hdfs/dfs/data/hdds/762187f8-3d8d-4c2c-8659-9ca66987c829/current/containerDir0/4/chunks/103363337595977729_chunk_1
Quote
[1].https://issues.apache.org/jira/browse/HDDS-2717

