The missing are back! Since I have been crawling, I have encountered many pits, so I will give a general report first
1. Access to all enterprises in the country
2. Supplement enterprise information through enterprise inspection
3. Direct employment of reptile boss to obtain company and position information
Let's talk about the direct employment of reptile boss

Objective:
Obtain the recruitment company and position information of the designated industry in the designated city
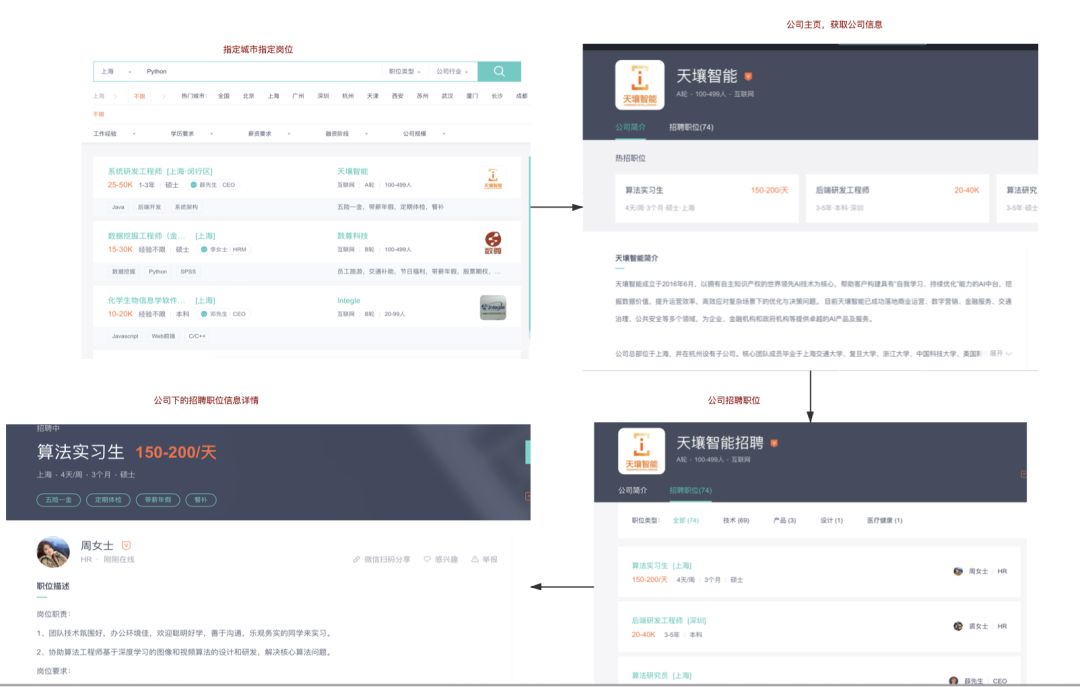
1, Trial and error stage
I tried to use requests, selenium, pyppeter, and found that I could not access boss direct employment normally, which made my boss worse!
Therefore, we can only use the puppeter. Because the first time we use the puppeter and the first time we use nodejs, there may be many defects in the code specification and operation. Please forgive me.
2, Reptile notice
1. Company name duplication (de duplication):
Search Python to find company A, java to find company A, then I only need to enter from one entry, and I will get all positions under the company, that is, get python, and I don't need to get Java's
Considering that the company name is the same and the location is different, it is the recruitment information of two companies,
Company A: company A in Beijing and company A in Shanghai
This is recorded by the URL that records the details of the company.
Originally, I wanted to record and de duplicate through redis. I found that redis is a callback function, which does not meet the needs. mysql is also an intelligent way to record files.
2. Page Jump question
The intention is to acquire information step by step through the click operation of the page, but in the process of practice, it is found that the page will always be stuck after the jump.
Finally, we choose to get the url step by step and simply load the url to get the information.
3, Get city code
https://www.zhipin.com/job_detail/?query=Python&city=101010100&industry=&position=
1. By visiting the url directly hired by boss, it is found that the city is located through citycode
// The conversion of city and city code
function main(city, job){
// Chinese character to Pinyin
// var pinyin = require('fast-pinyin');
// var output = pinyin(city);
// var firstChar = output[0][0]
// console.log("City:" + output[0][0]);
const originData = require('./city.json');
let city_code = null
if (city == "Whole country")
{
city_code = "100010000";
}
else
for (var province_info of originData){
var subLevelModelList = province_info["subLevelModelList"]
for (var city_info of subLevelModelList){
if (city_info["name"] == city)
city_code = city_info["code"];
}
}
console.log("City code found:" + city_code);
get_company(city_code, job)
}city.json: records the corresponding relationship between city and city code. The file is from the boss direct employment request file
4, Get all businesses
Get all enterprise names of the keyword in the region through search access
var next_page;
async function get_company(city_code, key_words){
console.log('crawler start to visit the target address');
/* Target link address of crawler: boss*/
var url = `https://www.zhipin.com/c${city_code}/?query=${key_words}&page=1&ka=page-1`;
/* dumpio Whether to import browser processes stdout and stderr into process.stdout and process.stderr */
const browser = await puppeteer.launch({
// headless:false,
args: ['--no-sandbox'],
dumpio: false,
// args:['--proxy-server=http://47.98.154.206:3008']
});
const page = await browser.newPage();
await page.evaluateOnNewDocument(() => {
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined,
});
});
// All companies in this category in the region
var company_info = []
while (url != null && url.length > 20){
await page.goto(url, {
waitUntil: 'networkidle2'
});
await sleep(0);
const result = await page.evaluate(() => {
let data = [];
let elements = document.querySelectorAll('#Main > div > div.job-list > UL > li '); / / get all li
for (var element of elements){ // loop
let title = element.querySelector('div > div.info-primary > div.info-company > div > h3 > a').innerHTML;
let url = element.querySelector('div > div.info-primary > div.info-company > div > h3 > a').href; //Grab link (href) attribute
data.push({title, url}); // Store array
}
return data;
});
for (var temp of result){ // loop
company_info.push(temp); // Store array
}
//next page
let next_page;
if (result.length < 30)
next_page = null;
else
var element_next_page = await page.$("#main > div > div.job-list > div.page > a.next");
if (element_next_page)
next_page = await page.$eval('#main > div > div.job-list > div.page > a.next', ele=>ele.href);
else
next_page = null
url = next_page
}
// page.close();
// Get all enterprise information found
// Array weight removal
let new_company_info = deduplication(company_info)5, Recruitment information of the company
After obtaining all company details, all recruitment information of the company is also obtained
Note: the recruitment position may be (0), but the corresponding position will be recommended below, which is not advisable
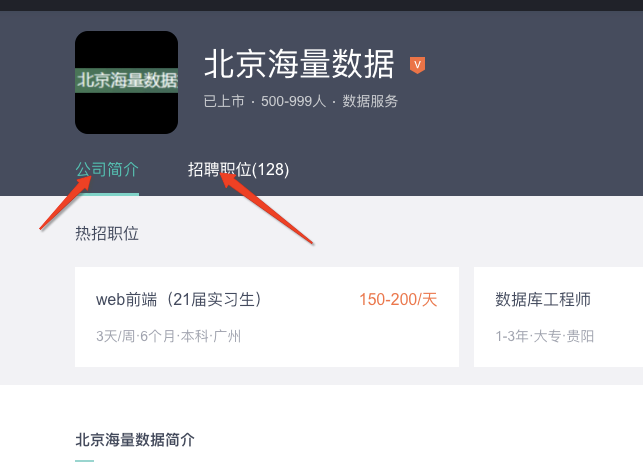
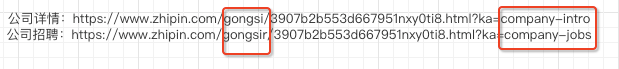
company_all_job = company_url_value.replace("gongsi", "gongsir")
company_all_job = company_all_job.split("?")[0] + "?ka=company-jobs"
var company_job_urls = []
while ( company_all_job != null && company_all_job.length > 19){
await page2.goto(company_all_job, {
waitUntil: 'networkidle2'
});
await sleep(0);
job_count = await page2.$eval('#main > div.company-banner > div > div.company-tab > a.cur', ele=>ele.innerText);
if (job_count.includes("(0)"))
{
console.log("Position in recruitment is 0")
company_all_job = null
}
else
{
const jobs_urls = await page2.evaluate(() => {
let data = [];
let elements = document.querySelectorAll('div.job-list >ul >li'); //Get all li
for (var element of elements){ // loop
let url = element.querySelector('a').href; //Grab link (href) attribute
data.push(url); // Store array
}
return data;
});
for (var temp of jobs_urls){ // loop
company_job_urls.push(temp); // Store array
}
//next page
let next_job;
var job_next_page = null;
job_next_page = await page2.$("#main > div.job-box.company-job > div.inner.home-inner > div.job-list > div > a.next");
if (job_next_page)
next_job = await page2.$eval('#main > div.job-box.company-job > div.inner.home-inner > div.job-list > div > a.next', ele=>ele.href);
else
next_job = null
company_all_job = next_job
}
}
console.log("Position information:\n", company_job_urls)
console.log("Number of position information:\n", company_job_urls.length)
page2.close()```
6, Obtaining position information and warehousing
After getting the specific post connection, you can get the post information directly through the access, and the code will not be attached
mysql is used for information warehousing. During the warehousing, the url of the position is also checked and re stored. If it already exists, it will not be stored again to avoid repeated storage.
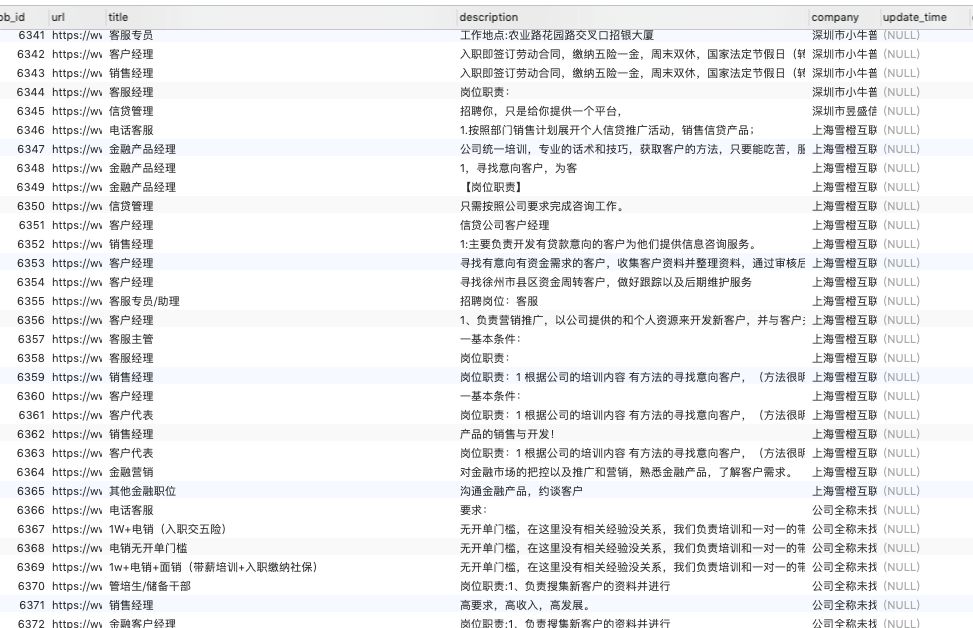
At last, we found that we can't get all the corresponding information, because the position search only displays the first 10 pages, and the company recruitment position only displays the first 30 pages. If there are solutions for children's shoes, please leave a message for discussion.
The above is to obtain the company information and position information, but the company information is simple and the key information is not available.
Next update: unlimited access to enterprise inspection information without account number


