Redis Cluster provides a method to run redis installation, in which data Automatically partition between multiple redis nodes.
Redis Cluster also provides a certain degree of availability during partitioning, which is actually the ability to continue operation when some nodes fail or fail to communicate. However, if a major failure occurs (for example, when most primary nodes are unavailable), the cluster will stop running.
In practice, what do you get from Redis Cluster?
- The ability to automatically split datasets between multiple nodes.
- The ability to continue operation when some nodes fail or cannot communicate with the rest of the cluster.
For reprint, please attach the original link address at the beginning of the article: https://www.cnblogs.com/Sunzz/p/15237497.html
Redis cluster TCP port
Each Redis Cluster node needs to open two TCP connections. The common Redis TCP port used to provide services to clients, such as 6379, and the second port called cluster bus port. The cluster bus port will be derived by adding 10000 to the data port (16379 in this example) or by overriding it with the cluster port configuration.
The second high port is used for the cluster bus, that is, the node to node communication channel using binary protocol. The node uses the cluster bus for fault detection, configuration update, failover authorization, etc. The client should never attempt to communicate with the cluster bus port, but should always communicate with the ordinary Redis command port, but please ensure that these two ports are opened in the firewall, otherwise the Redis cluster node will not be able to communicate.
Please note that to make the Redis cluster work normally, you need to:
- The common client communication port (usually 6379) used to communicate with clients is open to all clients that need to access the cluster and all other cluster nodes (using the client port for key migration).
- The cluster bus port must be accessible from all other cluster nodes.
If you do not open two TCP ports at the same time, your cluster will not work as expected.
Cluster bus uses different binary protocols for node to node data exchange, which is more suitable for exchanging information between nodes with little bandwidth and processing time.
Redis cluster and Docker
At present, Redis Cluster does not support NATted environment, nor does it support the general environment of remapping IP address or TCP port.
Docker uses a technology called port mapping: programs running in the docker container may use different ports than the ports that the program thinks are being used. This is useful for running multiple containers on the same server using the same port at the same time.
In order to make Docker compatible with Redis Cluster, the host networking mode of Docker needs to be used. Please check the official Docker documentation: https://docs.docker.com/engine/userguide/networking/dockernetworks/ The -- net=host option for more information.
Redis Cluster data fragmentation
Redis Cluster does not use consistent hashing, but a different form of fragmentation, in which each key is conceptually a part of what we call a hash slot.
There are 16384 hash slots in the Redis cluster. To calculate the hash slot of a given key, we only need to take the CRC16 modulus 16384 of the key.
Each node in the Redis cluster is responsible for a subset of hash slots. For example, you may have a cluster with three nodes, including:
- Node A contains hash slots from 0 to 5500.
- Node B contains hash slots from 5501 to 11000.
- Node C contains hash slots from 11001 to 16383.
This allows nodes to be easily added and removed from the cluster. For example, if I want to add A new node D, I need to move some hash slots from nodes A, B, C to d. Similarly, if I want to delete node A from the cluster, I can move the hash slot provided by A to B and C. When node A is empty, I can completely delete it from the cluster.
Since moving hashing slots from one node to another does not require stopping operations, adding and deleting nodes or changing the percentage of hash slots held by nodes does not require any downtime.
Redis Cluster supports multi key operation, as long as all keys involving single command execution (or the whole transaction, or Lua script execution) belong to the same hash slot. Users can use a concept called hash tags to force multiple keys to be part of the same hash slot.
The Redis Cluster specification records the hash tag, but the important point is that if there is a substring between the {} brackets in the key, only the contents in the string will be hashed, such as this{foo}key and another{foo}key It is guaranteed to be in the same hash slot and can be used together in commands with multiple keys as parameters.
Redis Cluster primary replica model
In order to remain available when the primary node subset fails or cannot communicate with most nodes, the Redis cluster uses the primary replica model, where each hash slot has from 1 (the primary node itself) to N replicas (N -1 additional replica nodes).
In our example cluster containing nodes A, B and C, if node B fails, the cluster cannot continue because we no longer have A way to serve hash slots in the range of 5501-11000.
However, when the cluster is created (or later), we add a replica node for each master node, so that the final cluster consists of master nodes a, B, C and replica nodes A1, B1, C1 In this way, if node B fails, the system can continue to operate.
If node B1 replicates B and B fails, the cluster will promote node B1 to a new master and continue to operate normally.
However, it should be noted that if nodes B and B1 fail at the same time, Redis Cluster will not continue to operate.
Redis cluster consistency assurance
Redis Cluster cannot guarantee strong consistency. In fact, this means that in some cases, Redis Cluster may lose the writes confirmed by the system to the client.
The first reason Redis Cluster loses writes is because it uses asynchronous replication. This means that the following occurs during writing:
- Your client writes to master B.
- Master B replies OK to your client.
- Master B propagates writes to its copies B1, B2, and B3.
As you can see, B will not wait for confirmation from B1, B2 and B3 before replying to the client, because this is a prohibitive delay penalty for Redis. Therefore, if your client writes some content, B will confirm the write, but will crash before that. B can send the write in to its replica, and one of the replicas (no write received) can be promoted to the master, Write is lost forever.
This is very similar to what happens with most databases configured to flush data to disk per second, so you can infer this because of past experience with traditional database systems that do not involve distributed systems. Similarly, you can improve consistency by forcing the database to flush data to disk before replying to the client, but this usually leads to prohibitively low performance. In the case of Redis Cluster, this is equivalent to synchronous replication.
Basically, there is a trade-off between performance and consistency.
Redis cluster supports synchronous writing when absolutely necessary WAIT Command implementation. This greatly reduces the possibility of lost writes. However, please note that even if synchronous replication is used, Redis Cluster does not achieve strong consistency: in more complex failure scenarios, it is always possible to select the replica that cannot receive writes as the master.
Another noteworthy scenario is that the Redis cluster will lose writes. This happens during network partition, and the client is isolated from a few instances (including at least one primary instance).
Taking our six node cluster as an example, it is composed of a, B, C, A1, B1 and C1, with three master nodes and three replica nodes. There is also a client, which we call Z1.
After the partition occurs, there may be a, C, A1, B1 and C1 on one side of the partition and B and Z1 on the other side.
Z1 can still write to B, and B will accept its writing. If the partition heals in a short time, the cluster will continue normally. However, if the partition lasts long enough for B1 to be promoted to master on most sides of the partition, the writes sent by Z1 to B at the same time will be lost.
Note that there is a maximum window for the amount of writes that Z1 can send to B: if the majority of the partition has enough time to elect a replica as the master node, each master node of the minority will stop accepting writes.
This amount of time is a very important configuration instruction of Redis Cluster, which is called node timeout.
After the node times out, the primary node is considered to have failed and can be replaced by one of its replicas. Similarly, after the node times out, the master node cannot perceive most other master nodes, and it enters an error state and stops accepting writes.
2, Finally available yaml file
Redis cluster clusters with three master s and three slave are deployed
1. redis-cluster.yaml
(1) If the cluster section is larger than 6, you can release the comments in lines 116-127.
(2)redis cluster password modification
Line 63-64163 "PASSWORD", which can be modified according to your own situation.
(3) Storage class modification
Modify line 192 storageClassName: YOU-K8S-SC Create your own storage class
The storage size of 195 rows is determined according to your own situation.
The redis-cluster.yaml file is as follows
1 --- 2 apiVersion: v1 3 kind: ConfigMap 4 metadata: 5 name: init-cluster 6 data: 7 init_cluster.sh: | 8 #!/bin/bash 9 ns=$NAMESPACE 10 RedisPwd=$1 11 cluster_domain=`awk '/search/{print $NF}' /etc/resolv.conf` 12 13 function cluster_init(){ 14 sleep 3 15 n0=`/usr/bin/dig +short redis-cluster-0.redis-service.${ns}.svc.${cluster_domain}` 16 n1=$(/usr/bin/dig +short redis-cluster-1.redis-service.${ns}.svc.${cluster_domain}) 17 n2=$(/usr/bin/dig +short redis-cluster-2.redis-service.${ns}.svc.${cluster_domain}) 18 n3=$(/usr/bin/dig +short redis-cluster-3.redis-service.${ns}.svc.${cluster_domain}) 19 n4=$(/usr/bin/dig +short redis-cluster-4.redis-service.${ns}.svc.${cluster_domain}) 20 n5=`ip a|grep inet|tail -1|awk '{print $2}'|awk -F "/" '{print $1}'` 21 #n5=`/usr/bin/dig +short redis-cluster-5.redis-service.${ns}.svc.cluster.local` 22 #n5=$(/usr/bin/dig +short redis-cluster-5.redis-service.${ns}.svc.cluster.local) 23 echo "0:$n0 1:$n1 2:$n2 3:$n3 4:$n4 5:$n5" 24 echo yes | /usr/local/bin/redis-cli -a $RedisPwd --cluster create ${n0}:6379 ${n1}:6379 ${n2}:6379 ${n3}:6379 ${n4}:6379 ${n5}:6379 --cluster-replicas 1 && echo "redis-cluster init finshed" || echo "xxxx.... " 25 } 26 27 function set_password(){ 28 sleep 5 29 echo "start save cluster password" 30 /usr/local/bin/redis-cli -h redis-cluster -p 6379 config set masterauth $RedisPwd && \ 31 /usr/local/bin/redis-cli -h redis-cluster config set requirepass $RedisPwd 32 echo "end save cluster password" 33 sleep 1 34 35 # for i in $(seq 0 5) 36 # do 37 # redis_host=redis-cluster-${i}.redis-service.${ns}.svc.${cluster_domain} 38 # /usr/local/bin/redis-cli -h ${redis_host} -a $RedisPwd config set masterauth $RedisPwd 39 # /usr/local/bin/redis-cli -h ${redis_host} config set requirepass $RedisPwd 40 # /usr/local/bin/redis-cli -h ${redis_host} -a $RedisPwd config rewrite 41 # done 42 } 43 cluster_init && set_password 44 echo "ok......" 45 46 --- 47 apiVersion: v1 48 kind: ConfigMap 49 metadata: 50 name: redis-cluster-config 51 data: 52 redis.conf: | 53 bind 0.0.0.0 54 appendonly yes 55 cluster-enabled yes 56 cluster-config-file nodes.conf 57 cluster-node-timeout 5000 58 dir /data/ 59 port 6379 60 pidfile /var/run/redis.pid 61 logfile "redis.log" 62 protected-mode no 63 masterauth "PASSWORD" 64 requirepass "PASSWORD" 65 66 --- 67 apiVersion: v1 68 kind: Service 69 metadata: 70 name: redis-service 71 labels: 72 app: redis-cluster 73 spec: 74 ports: 75 - name: redis-port 76 port: 6379 77 clusterIP: None 78 selector: 79 app: redis-cluster 80 appCluster: redis-cluster 81 --- 82 apiVersion: v1 83 kind: Service 84 metadata: 85 name: redis-cluster 86 labels: 87 app: redis-cluster 88 spec: 89 ports: 90 - name: redis-port 91 protocol: "TCP" 92 port: 6379 93 targetPort: 6379 94 selector: 95 app: redis-cluster 96 appCluster: redis-cluster 97 98 --- 99 apiVersion: apps/v1 100 kind: StatefulSet 101 metadata: 102 name: redis-cluster 103 spec: 104 serviceName: "redis-service" 105 replicas: 6 106 selector: 107 matchLabels: 108 app: redis-cluster 109 template: 110 metadata: 111 labels: 112 app: redis-cluster 113 appCluster: redis-cluster 114 spec: 115 terminationGracePeriodSeconds: 20 116 # affinity: 117 # podAntiAffinity: 118 # preferredDuringSchedulingIgnoredDuringExecution: 119 # - weight: 100 120 # podAffinityTerm: 121 # labelSelector: 122 # matchExpressions: 123 # - key: app 124 # operator: In 125 # values: 126 # - redis-cluster 127 # topologyKey: kubernetes.io/hostname 128 containers: 129 - name: redis 130 image: linuxpy/redis:cluster-v3 131 imagePullPolicy: Always 132 env: 133 - name: NAMESPACE 134 valueFrom: 135 fieldRef: 136 fieldPath: metadata.namespace 137 - name: POD_NAME 138 valueFrom: 139 fieldRef: 140 fieldPath: metadata.name 141 - name: MY_POD_IP 142 valueFrom: 143 fieldRef: 144 fieldPath: status.podIP 145 command: 146 - "redis-server" 147 args: 148 - /usr/local/etc/redis.conf 149 - --cluster-announce-ip 150 - "$(MY_POD_IP)" 151 resources: 152 requests: 153 cpu: "100m" 154 memory: "100Mi" 155 lifecycle: 156 postStart: 157 exec: 158 command: 159 - /bin/bash 160 - -c 161 - > 162 if [ `hostname` = "redis-cluster-5" ]; then 163 bash /opt/init_cluster.sh "PASSWORD" 1>/tmp/init.log 2>&1; 164 fi; 165 ports: 166 - name: redis 167 containerPort: 6379 168 protocol: "TCP" 169 - name: cluster 170 containerPort: 16379 171 protocol: "TCP" 172 volumeMounts: 173 - name: "data" 174 mountPath: "/data/" 175 - name: redis-cluster-config 176 mountPath: /usr/local/etc/ 177 - name: init-cluster 178 mountPath: /opt/ 179 volumes: 180 - name: redis-cluster-config 181 configMap: 182 name: redis-cluster-config 183 - name: init-cluster 184 configMap: 185 name: init-cluster 186 187 volumeClaimTemplates: 188 - metadata: 189 name: data 190 spec: 191 accessModes: [ "ReadWriteOnce" ] 192 storageClassName: YOU-K8S-SC 193 resources: 194 requests: 195 storage: 1Gi
2. Deploy redis cluster
kubectl -n xxxx apply -f redis-cluster.yaml
3. Verification
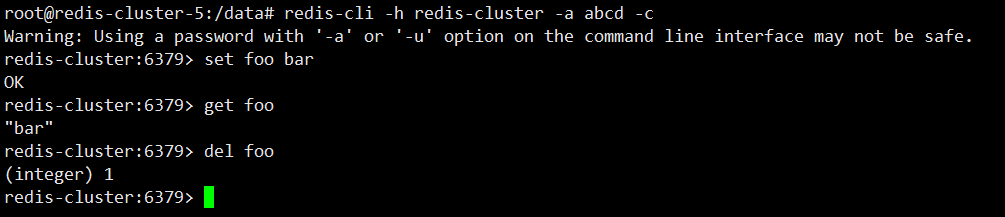
To connect to the cluster, you must use - c to indicate that you are connecting to the redis cluster, and - a is the specified password.
redis-cli -h redis-cluster -a abcd -c
2, Detailed process
If you are not interested in the specific process and just want to find a yaml file that can be used, you don't have to look down.
1. Cluster initialization script init_cluster.sh
$NAMESPACE k8s is passed in through the environment variable, and the redis cluster password is passed in through the variable
#!/bin/bash ns=$NAMESPACE RedisPwd=$1 cluster_domain=`awk '/search/{print $NF}' /etc/resolv.conf` function cluster_init(){ sleep 3 n0=`/usr/bin/dig +short redis-cluster-0.redis-service.${ns}.svc.${cluster_domain}` n1=$(/usr/bin/dig +short redis-cluster-1.redis-service.${ns}.svc.${cluster_domain}) n2=$(/usr/bin/dig +short redis-cluster-2.redis-service.${ns}.svc.${cluster_domain}) n3=$(/usr/bin/dig +short redis-cluster-3.redis-service.${ns}.svc.${cluster_domain}) n4=$(/usr/bin/dig +short redis-cluster-4.redis-service.${ns}.svc.${cluster_domain}) n5=`ip a|grep inet|tail -1|awk '{print $2}'|awk -F "/" '{print $1}'` #n5=`/usr/bin/dig +short redis-cluster-5.redis-service.${ns}.svc.cluster.local` #n5=$(/usr/bin/dig +short redis-cluster-5.redis-service.${ns}.svc.cluster.local) echo "0:$n0 1:$n1 2:$n2 3:$n3 4:$n4 5:$n5" echo yes | /usr/local/bin/redis-cli -a $RedisPwd --cluster create ${n0}:6379 ${n1}:6379 ${n2}:6379 ${n3}:6379 ${n4}:6379 ${n5}:6379 --cluster-replicas 1 && echo "redis-cluster init finshed" || echo "xxxx.... " } function set_password(){ sleep 5 echo "start save cluster password" /usr/local/bin/redis-cli -h redis-cluster -p 6379 config set masterauth $RedisPwd && \ /usr/local/bin/redis-cli -h redis-cluster config set requirepass $RedisPwd echo "end save cluster password" sleep 1 # for i in $(seq 0 5) # do # redis_host=redis-cluster-${i}.redis-service.${ns}.svc.${cluster_domain} # /usr/local/bin/redis-cli -h ${redis_host} -a $RedisPwd config set masterauth $RedisPwd # /usr/local/bin/redis-cli -h ${redis_host} config set requirepass $RedisPwd # /usr/local/bin/redis-cli -h ${redis_host} -a $RedisPwd config rewrite # done } cluster_init && set_password echo "ok......"
2.sources.list file
Alibaba cloud image is used here to install software, so that the image has a dig command to obtain the IP address of each node.
deb http://mirrors.aliyun.com/debian/ buster main non-free contrib deb-src http://mirrors.aliyun.com/debian/ buster main non-free contrib deb http://mirrors.aliyun.com/debian-security buster/updates main deb-src http://mirrors.aliyun.com/debian-security buster/updates main deb http://mirrors.aliyun.com/debian/ buster-updates main non-free contrib deb-src http://mirrors.aliyun.com/debian/ buster-updates main non-free contrib deb http://mirrors.aliyun.com/debian/ buster-backports main non-free contrib deb-src http://mirrors.aliyun.com/debian/ buster-backports main non-free contrib
3. Create an image Dockerfile
FROM redis:5.0 ADD sources.list /etc/apt/sources.list ADD redis.conf init_cluster.sh /usr/local/etc/ RUN apt-get update && apt-get install dnsutils iproute2 -y && apt-get clean && rm -rf /var/lib/apt/lists/*
4. Make image
docker build -t you-redis:cluster-v3 .
5. Problems encountered
init_ Get the ip address of the last pod in the cluster.sh file. I don't know why the latter method is dead or alive
n5=`ip a|grep inet|tail -1|awk '{print $2}'|awk -F "/" '{print $1}'` #n5=`/usr/bin/dig +short redis-cluster-5.redis-service.${ns}.svc.cluster.local` #n5=$(/usr/bin/dig +short redis-cluster-5.redis-service.${ns}.svc.cluster.local)
reference resources: https://redis.io/topics/cluster-tutorial