Kettle implements cross-database index calculation
Background note
Business requires daily statistics of the current value of business indicators, as well as the calculation of the index's yesterday value, the same period last month value, and the cumulative monthly value/annual value.
Considering the convenience of using the table, the design index table produces an index record every day, at the same time, the field is used to record the index corresponding to yesterday's value and other values.
At the same time, the unnecessary statistical data is reduced. When calculating the cumulative value, the cumulative value of yesterday will be taken from the target and added to the cumulative value of that day to obtain the cumulative value of that day.
Because the target table is not in the same database when calculating the index value of that day, we can not use a single SQL to query, so we need to associate the result set across the database.
So the difficulty in developing this job is the association between databases.
Target table structure
| Column names | Column description | Remarks |
|---|---|---|
| day_id | date | |
| area_code | region | |
| kpi_code | index | |
| kpi_value | Indicators of the day | |
| kpi_value_ld | Yesterday indicators | |
| kpi_value_lm | Last month's same period value | |
| kpi_value_sm | Cumulative value of the month | |
| kpi_value_sy | Accumulated Value of the Year | |
Create test tables and test data
Source data table:
drop table if exists test_1; create table test_1 as ( select '001' as area_code ,to_date('20190906','yyyymmdd') as create_date ,100 as sum_amount union all select '001' as area_code ,to_date('20190906','yyyymmdd') as create_date ,200 as sum_amount )
Target data sheet:
drop table if exists test_target; create table test_target as ( select '20190806' as day_id ,'001' as area_code ,'001' as kpi_code,100 as kpi_value ,100 as kpi_value_ld,100 as kpi_value_lm ,100 as kpi_value_sm,100 as kpi_value_sy union all select '20190905' as day_id ,'001' as area_code ,'001' as kpi_code,100 as kpi_value ,100 as kpi_value_ld,100 as kpi_value_lm ,100 as kpi_value_sm,200 as kpi_value_sy union all select '20190906' as day_id ,'001' as area_code ,'001' as kpi_code,200 as kpi_value ,200 as kpi_value_ld,200 as kpi_value_lm ,200 as kpi_value_sm,200 as kpi_value_sy )
Query statement
The SQL statement of index query is not complicated. Only job variables need to be used in query, so it is convenient to schedule batches by day.
Date Indicator Value:
select '${day_id}' as day_id ,area_code as area_code ,'001' as kpi_code ,sum(sum_amount) as kpi_value from test_1 where create_date >= to_date('${day_id}','yyyymmdd') and create_date < to_date('${day_id}','yyyymmdd') + interval '1 day' group by area_code
Yesterday's Indicator Value:
select area_code ,kpi_code ,kpi_value as kpi_value_ld ,case when extract(day from to_date('${day_id}','yyyymmdd')) = 1 then 0 else kpi_value_sm end as kpi_value_ldsm ,case when extract(doy from to_date('${day_id}','yyyymmdd')) = 1 then 0 else kpi_value_sy end as kpi_value_ldsy from test_target where day_id = to_char(to_date('${day_id}','yyyymmdd') - interval '1 day','yyyymmdd')
The same period last month:
select area_code ,kpi_code ,kpi_value as kpi_value_lm from test_target where day_id = to_char(to_date('${day_id}','yyyymmdd') - interval '1 month','yyyymmdd')
Delete data
In order to allow jobs to run data repeatedly without duplication, it is necessary to delete the data of the day before inserting the data.
delete from test_target where day_id = '${day_id}'
Kettle transformation
Transform the overall view of the job: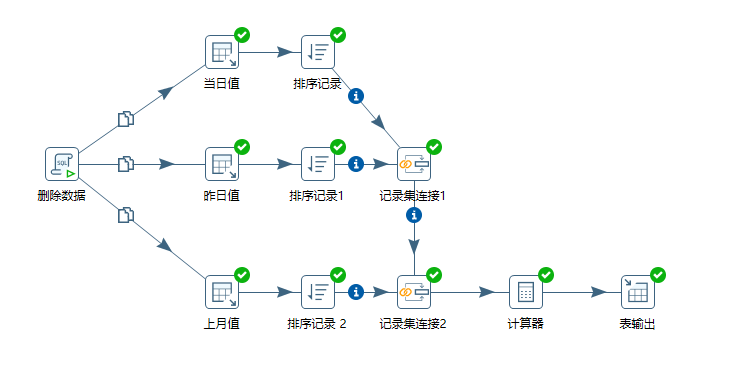
Delete data
- Control: Execute database scripts
Emphasis is laid on:
- Check variable substitution
Configuration diagram: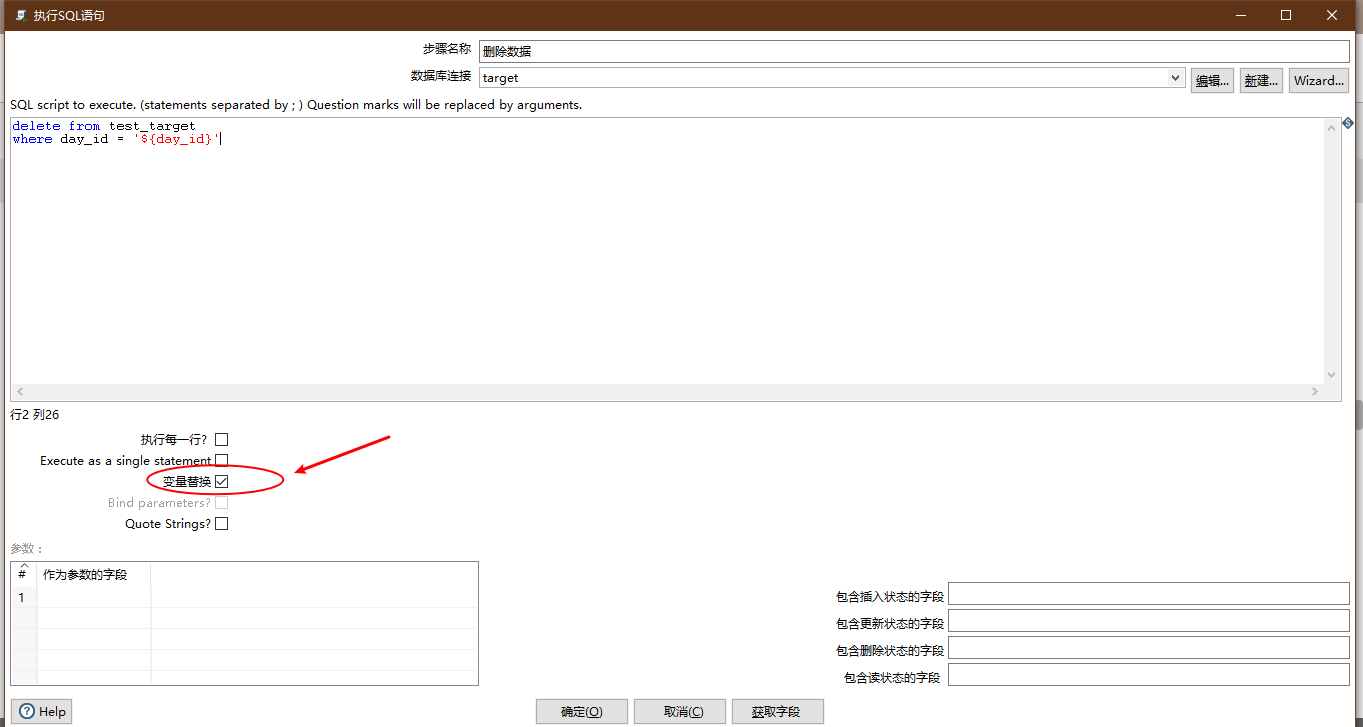
Daily value
- Control: Table input
Emphasis is laid on:
- Check variable substitution
- The data source is source.
Configuration diagram: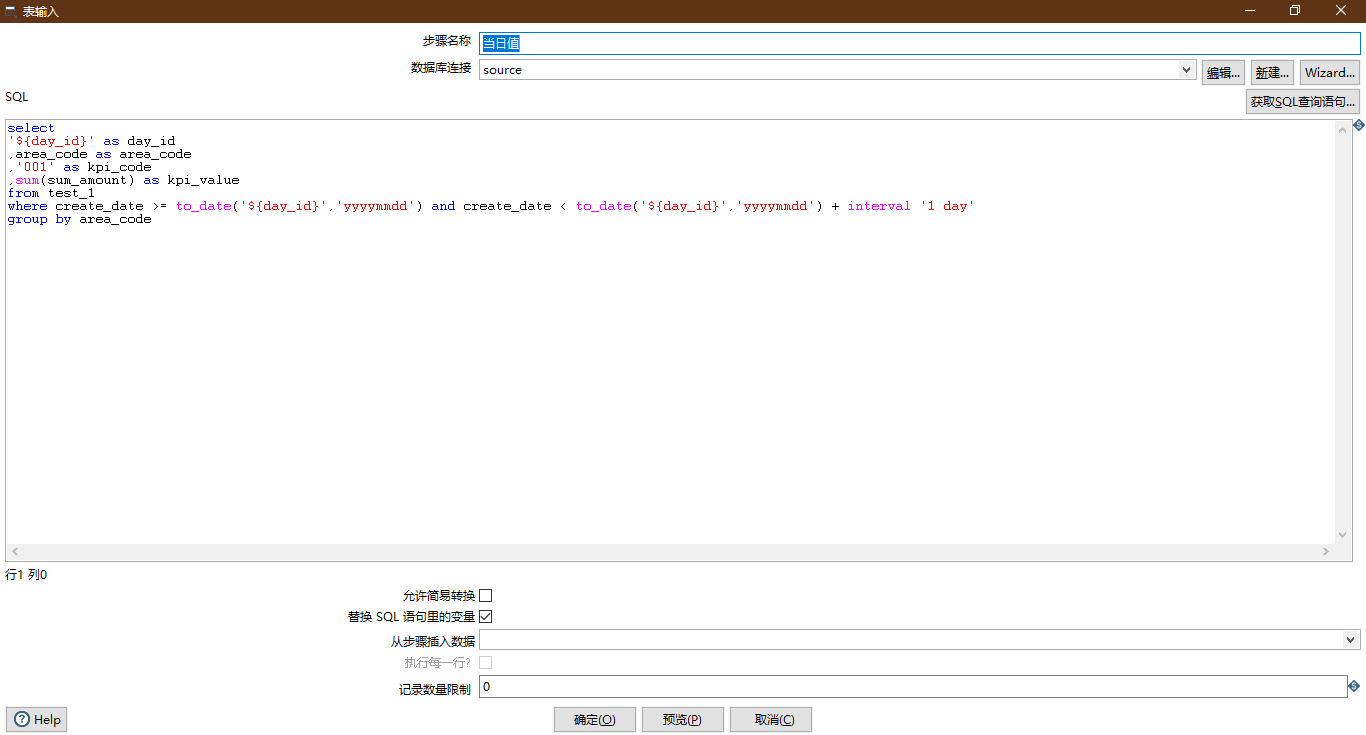
Yesterday value
- Control: Table input
Emphasis is laid on:
- Check variable substitution
- The data source is target
- Writing of Three Cumulative Fields in SQL Statements
Configuration diagram: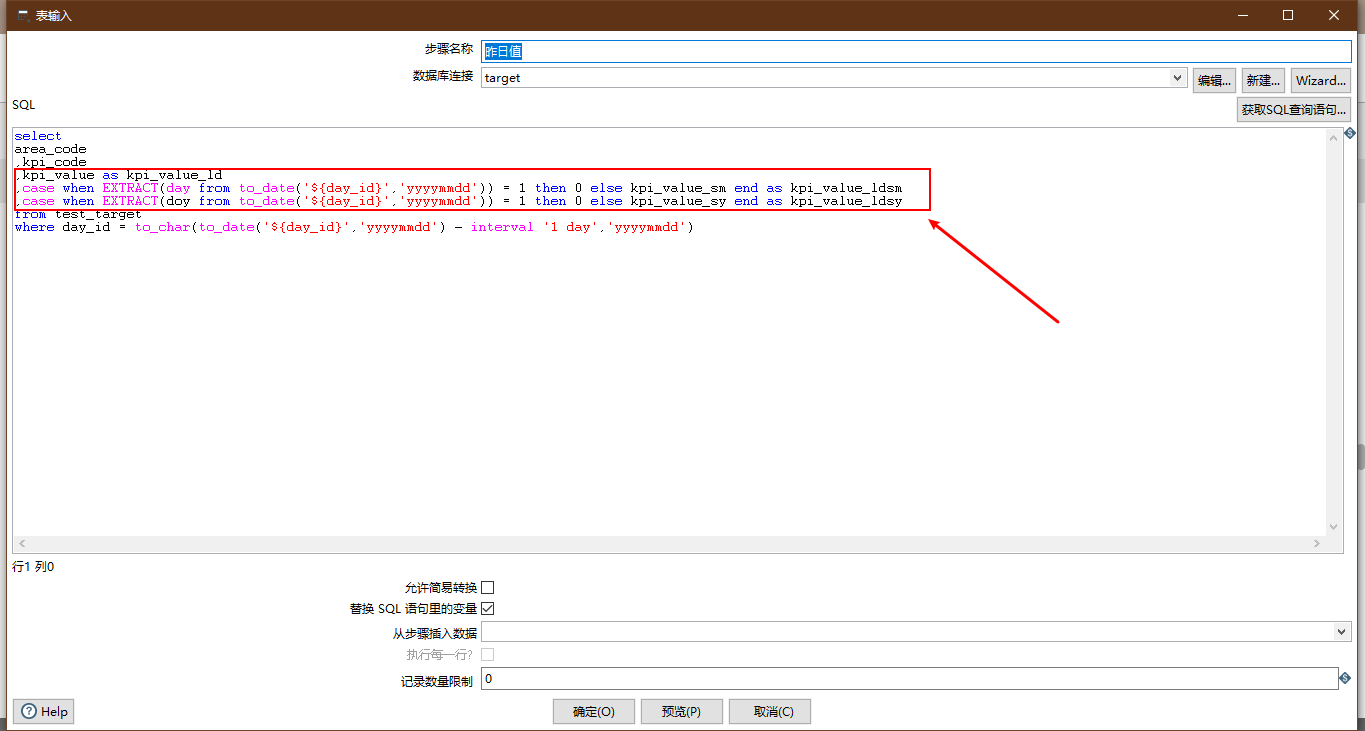
Last month's value
- Control: Table input
Emphasis is laid on:
- Check variable substitution
- The data source is target
Configuration diagram: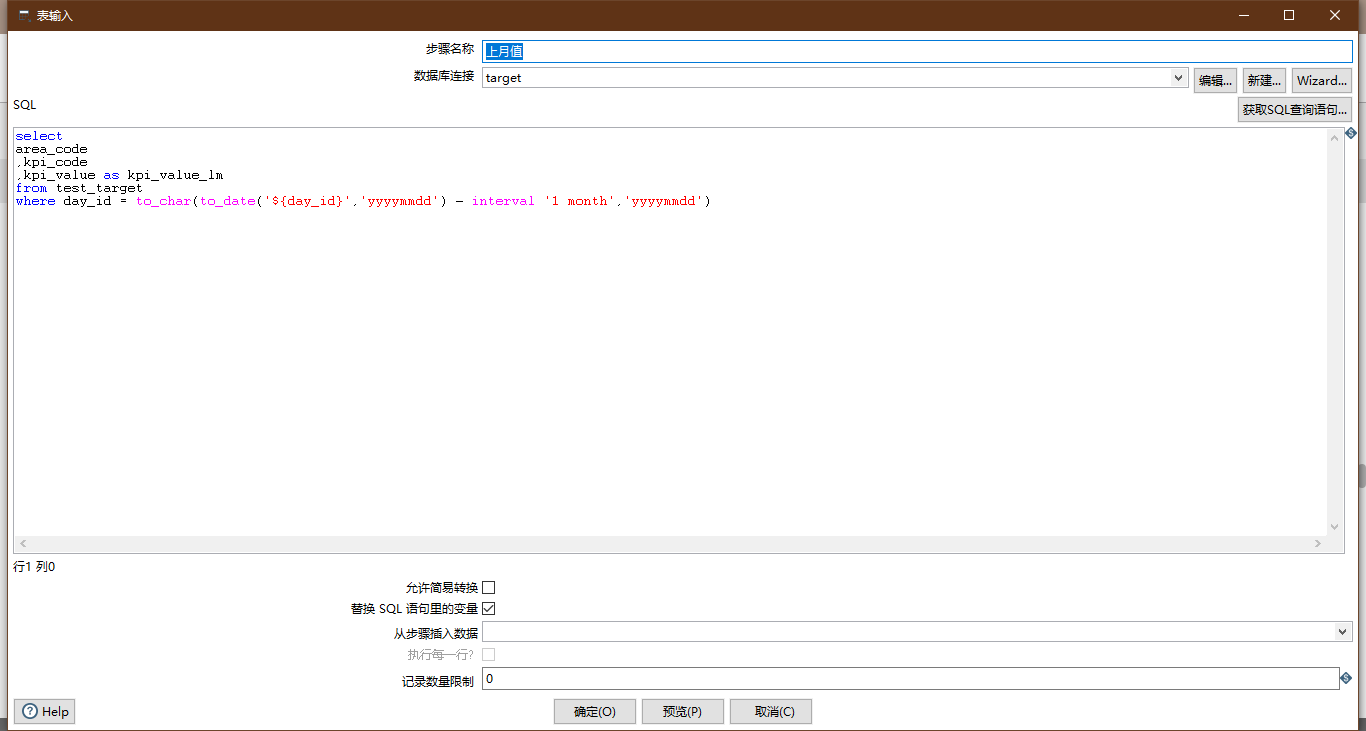
sort
Because the next step is data association connection, because merging is required before Association connection, this step is needed.
The three sorting steps are similar operations.
- Control: Sort Records
Emphasis is laid on:
- Specifies a sort as an associated column
- Pay attention to field order
Configuration diagram: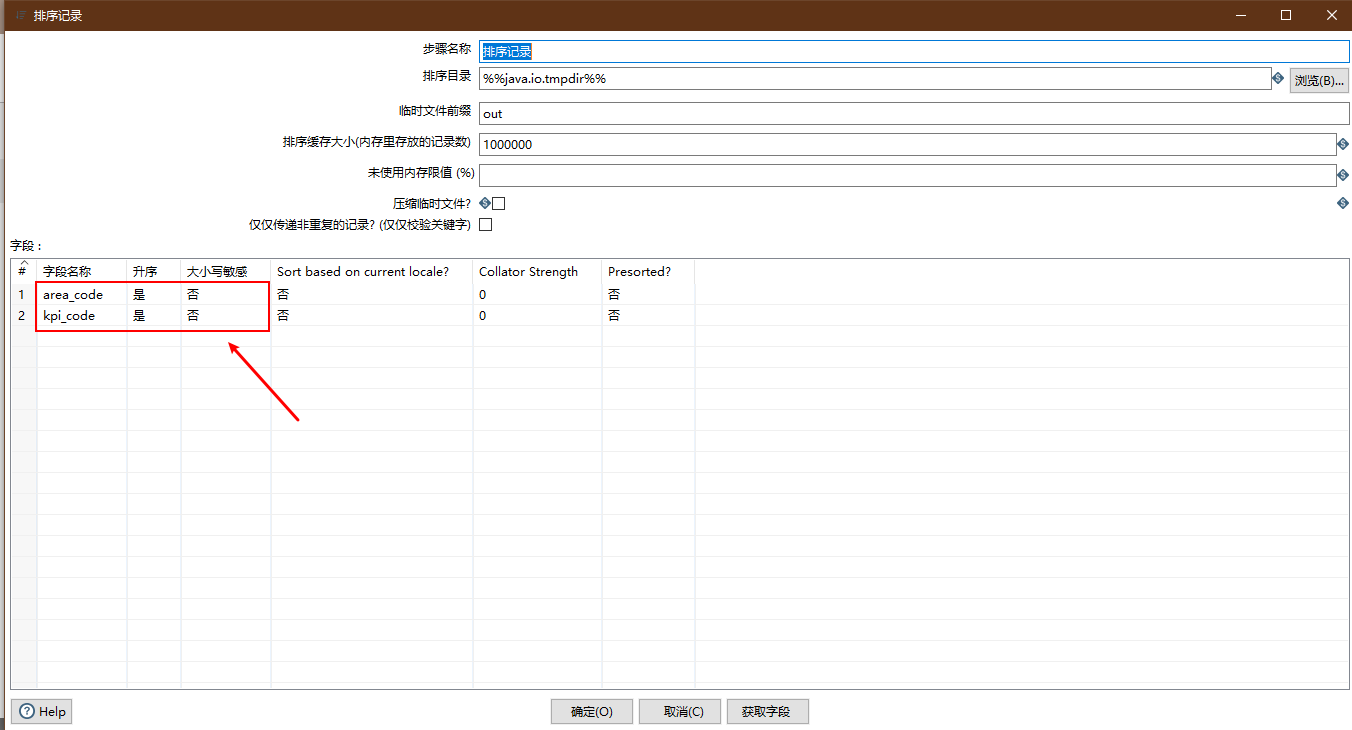
Relation
- Control: Recordset connection
Emphasis is laid on:
- Connection mode
- Connection field
Configuration diagram: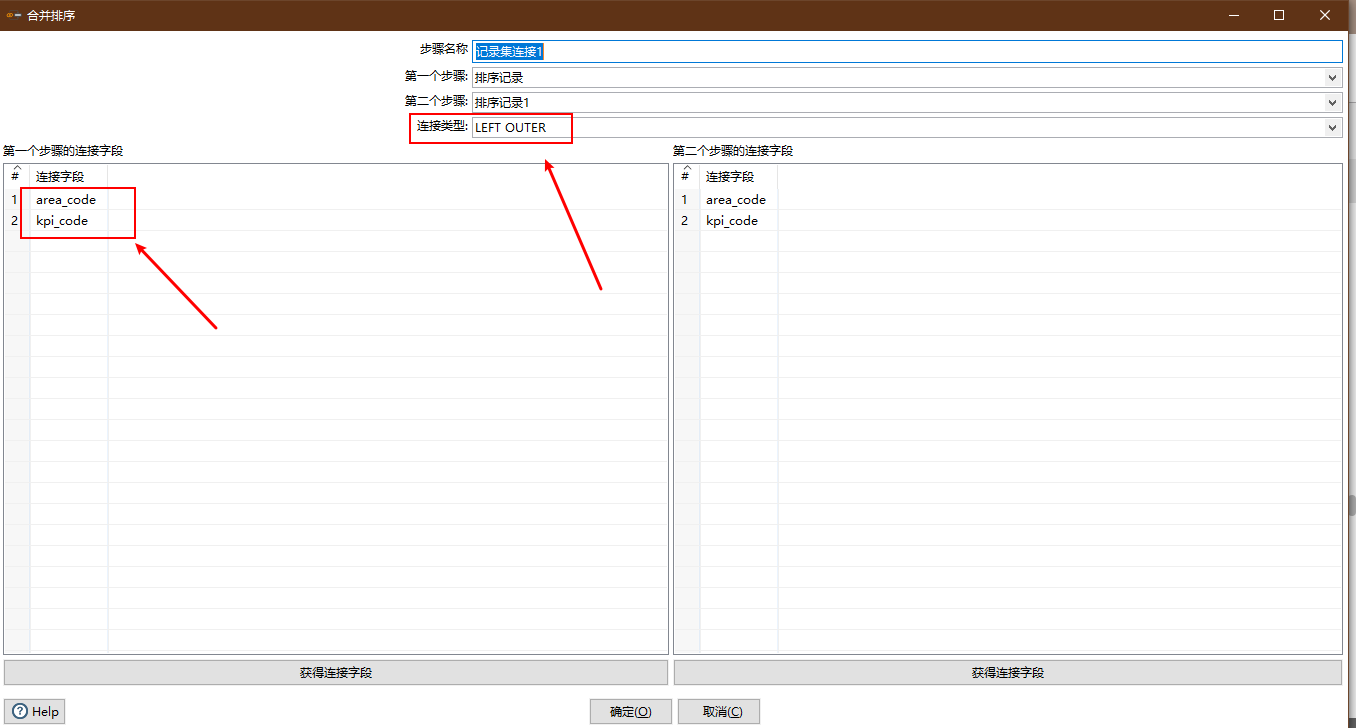
Cumulative calculation
The previous record set join operation only performed a left association operation between multiple data sets, and did not calculate the cumulative value of the month and the year we needed.
- Control: Calculator
Emphasis is laid on:
- Computational formulas
- Computational field
In actual development, it is found that:
Add the formula of the second line and drop down field A/field B to select only the result new field of the previous line. The other fields in the previous step cannot be selected.
So write the field name directly instead of selecting.
If you don't want to write directly, add another calculator step.
Configuration diagram: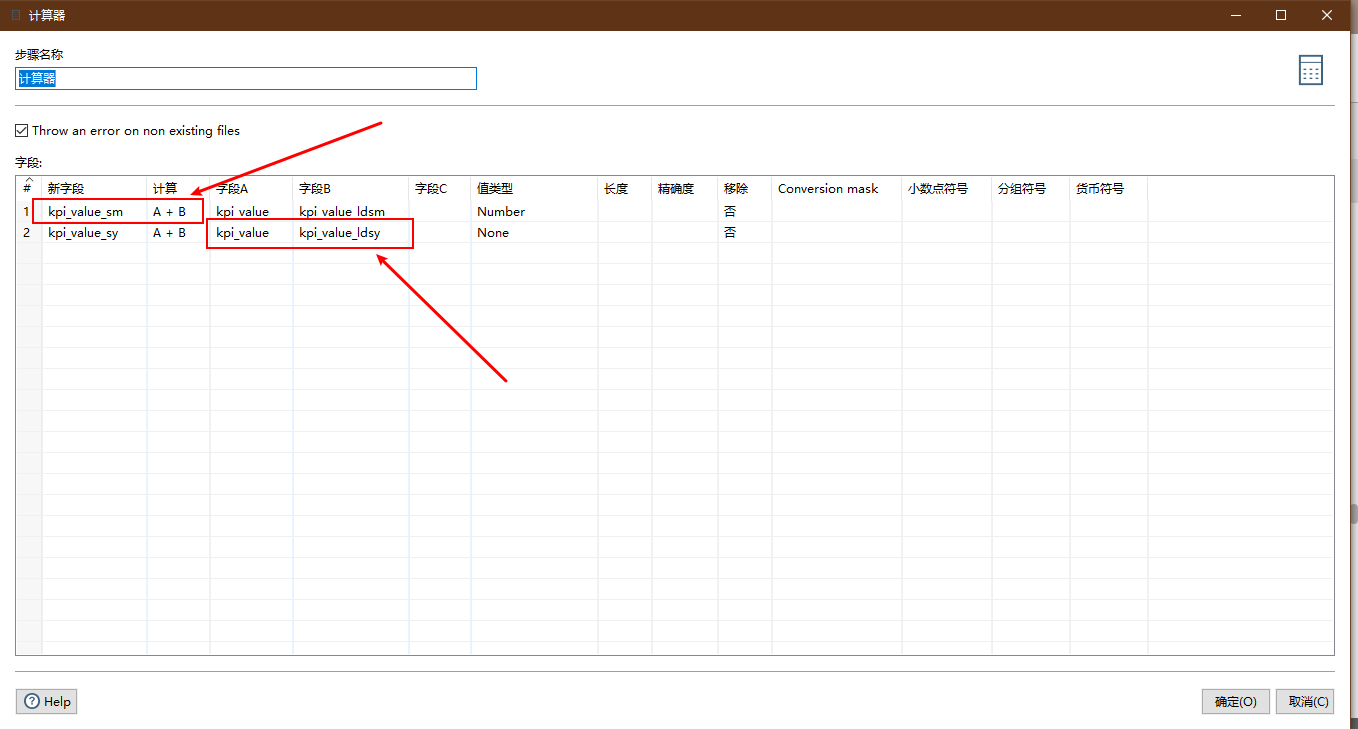
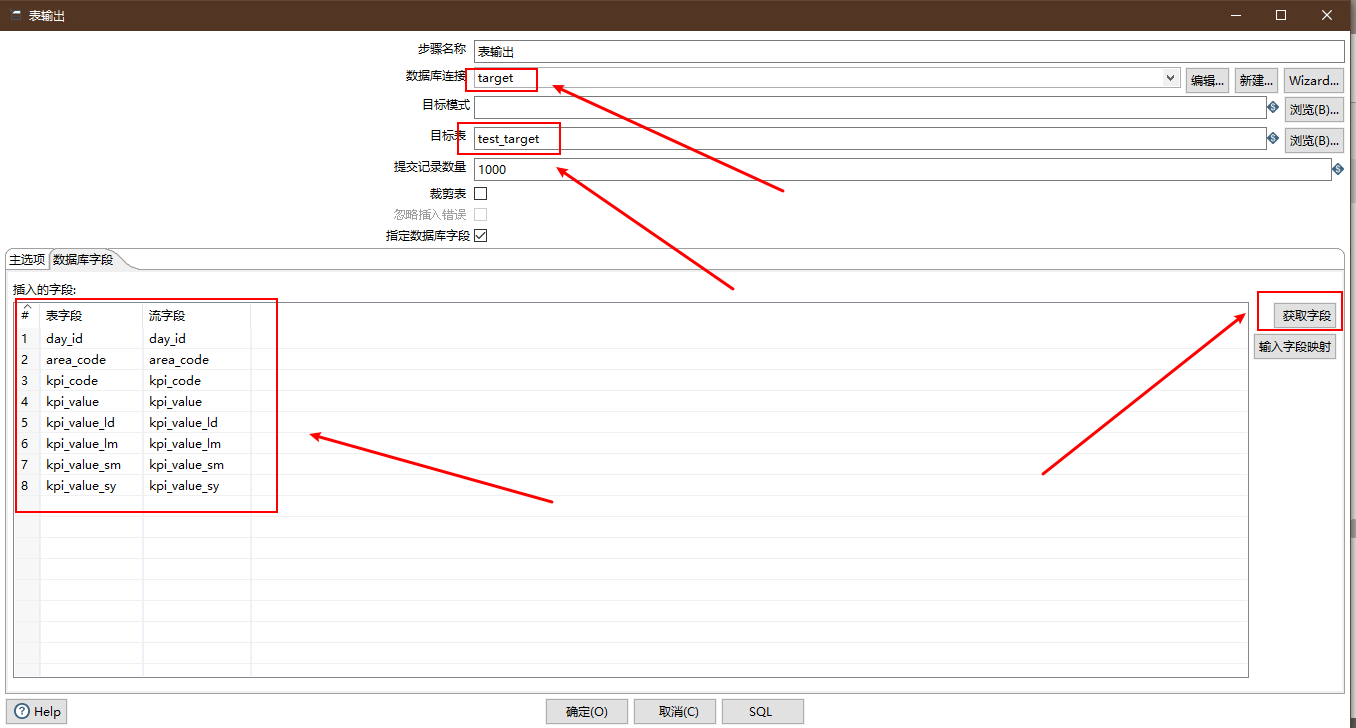
Output Target Table
- Control: Table output
Emphasis is laid on:
- Database Connection target
- Target table name
- Quickly add columns using fetch fields
- Delete redundant fields
summary
Through the above settings, we can achieve the single index cross-database association to generate index analysis records.
Implementation results:
You can see that a previous record of the day's error (20190906) has been corrected.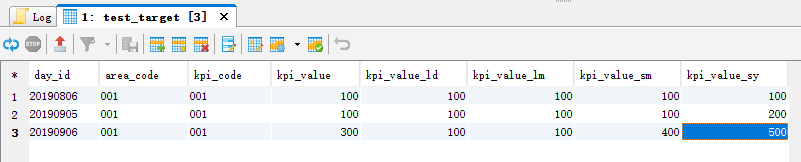 Of course, as a routine scheduling job, the following improvements can be made:
Of course, as a routine scheduling job, the following improvements can be made:
- Increase the Kettle job (kjb) as a loop control to call this job to achieve the number of cycles within the date range.
- Add a layer of index single-day value table, that is to say, remove the tables of various index analysis fields (cumulative value, synchronous value). So there is no need to associate data sets across databases. The associations between data sets are completely put into database SQL to operate. The development of kettle will be much simpler. This time, we do not want to increase the amount of table data and reduce the number of scheduling tasks. Therefore, the index daily value table is not used.