When using the ETL tool Kettle, in order to make the job or transformation universal, sometimes we need to separate the connection configuration of the database from the script or transformation. Here is a scheme, which mainly involves the following files:
# By default, these two files are in the user directory of the system. If you configure the environment variable of kettlehome, spoon will go to the directory of kettlehome to load these two files <USER_HOME>/.kettle/kettle.properties <USER_HOME>/.kettle/shared.xml
Shared database configuration
In the job, follow the DB connection wizard to establish a database connection and fill in the complete database connection information.
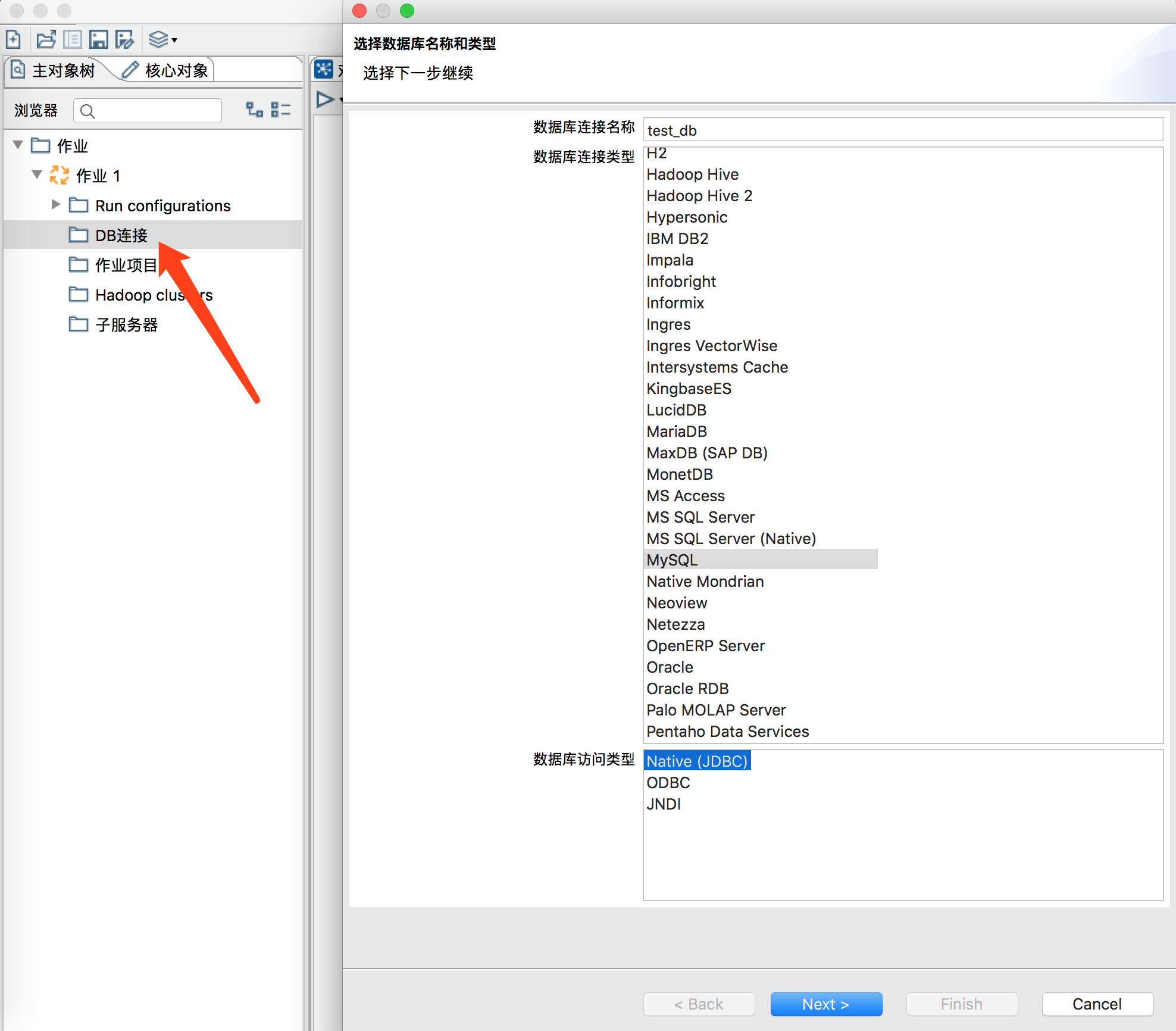
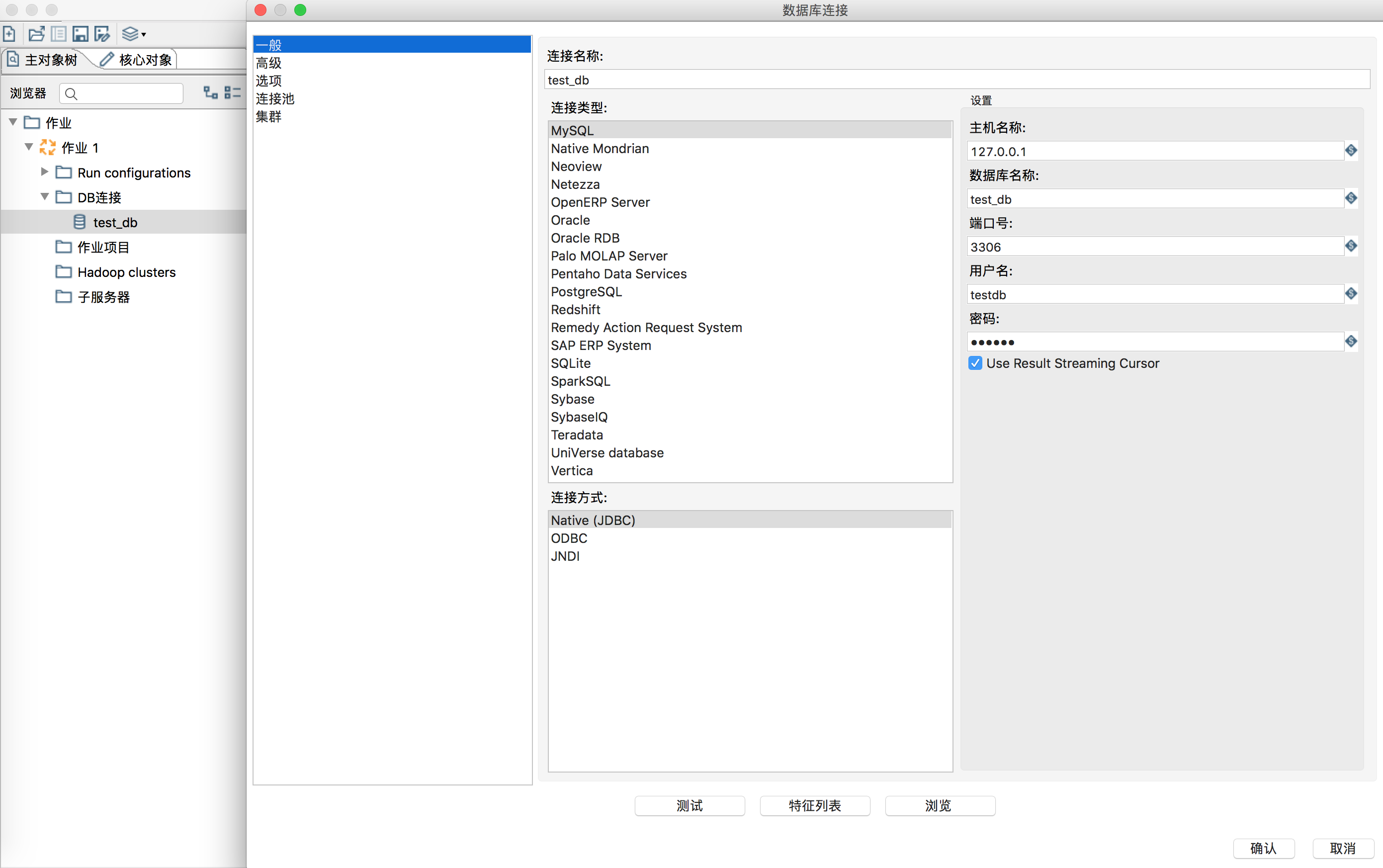
After the connection is established and the test connection is successful, right-click the DB connection and select share.
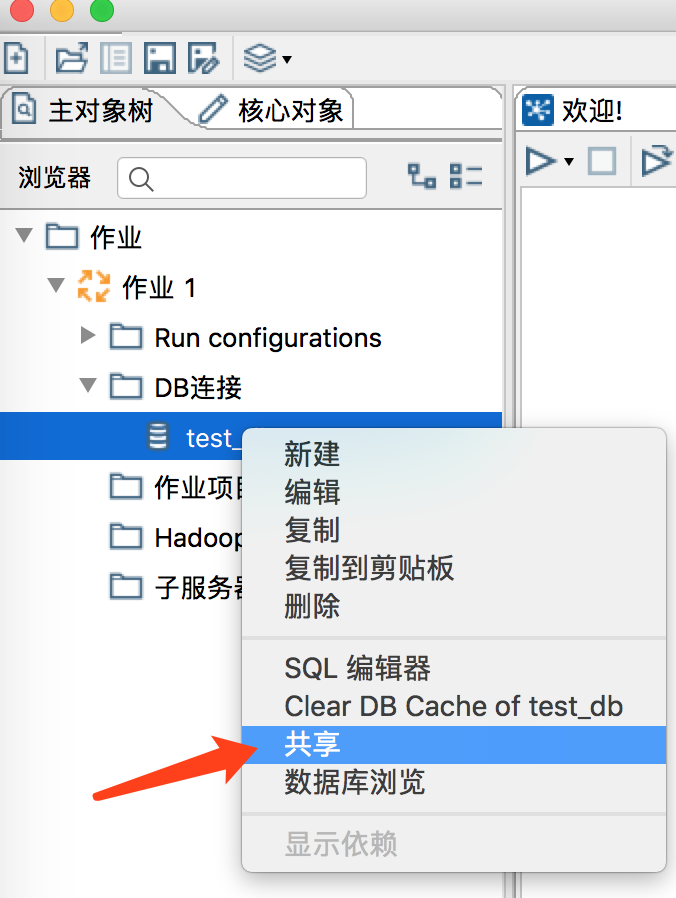
After the above sharing operation, you can find the configuration of the shared database link in the following files:
<USER_HOME>/.kettle/shared.xml
<?xml version="1.0" encoding="UTF-8"?> <sharedobjects> <connection> <name>test_db</name> <server>127.0.0.1</server> <type>MYSQL</type> <access>Native</access> <database>test_db</database> <port>3306</port> <username>testdb</username> <password>Encrypted 2be98afc86aa7f2e4cb79ff228dc6fa8c</password> <servername/> <data_tablespace/> <index_tablespace/> <attributes> <attribute><code>PORT_NUMBER</code><attribute>3306</attribute></attribute> </attributes> </connection> </sharedobjects>
After this setting, you can select the shared test? DB in subsequent jobs and transformations.
Although the DB connection is pulled out in this way, it is not optimized enough. Here is how to pull out some configurations in the DB connection again.
Extract DB configuration
For example, if we want to extract the database address, SID, username and password from shared.xml, we need to use
<USER_HOME>/.kettle/kettle.properties
We only need to define the relevant DB variables in this file, as follows:
test_db_host=127.0.0.1 test_db_port=3306 test_db_sid=test_db test_db_user=test_db test_db_password=Encrypted 2be98afc86aa7f2e4cb79ff228dc6fa8c
Then, we modify
<USER_HOME>/.kettle/shared.xml
<?xml version="1.0" encoding="UTF-8"?> <sharedobjects> <connection> <name>test_db</name> <server>${test_db_host}</server> <type>MYSQL</type> <access>Native</access> <database>${test_db_sid}</database> <port>${test_db_port}</port> <username>${test_db_user}</username> <password>${test_db_password}</password> <servername/> <data_tablespace/> <index_tablespace/> <attributes> <attribute><code>PORT_NUMBER</code><attribute>${test_db_port}</attribute></attribute> </attributes> </connection> </sharedobjects>
In this way, the configuration of the database is completely separated from the job and transformation.
Note that it is better to add the following database connection attributes in shared.xml, which can effectively avoid the problem of data transmission character and date conversion
<connection> <name>test_db</name> <server>${test_db_host}</server> <type>MYSQL</type> <access>Native</access> <database>${test_db_sid}</database> <port>${test_db_port}</port> <username>${test_db_user}</username> <password>${test_db_password}</password> <servername/> <data_tablespace/> <index_tablespace/> <attributes> <attribute> <code>EXTRA_OPTION_MYSQL.characterEncoding</code> <attribute>utf8</attribute> </attribute> <attribute> <code>FORCE_IDENTIFIERS_TO_LOWERCASE</code> <attribute>N</attribute> </attribute> <attribute> <code>FORCE_IDENTIFIERS_TO_UPPERCASE</code> <attribute>N</attribute> </attribute> <attribute> <code>IS_CLUSTERED</code> <attribute>N</attribute> </attribute> <attribute> <code>PORT_NUMBER</code> <attribute>${test_db_port}</attribute> </attribute> <attribute> <code>PRESERVE_RESERVED_WORD_CASE</code> <attribute>Y</attribute> </attribute> <attribute> <code>QUOTE_ALL_FIELDS</code> <attribute>N</attribute> </attribute> <attribute> <code>SQL_CONNECT</code> <attribute>set names utf8</attribute> </attribute> <attribute> <code>STREAM_RESULTS</code> <attribute>Y</attribute> </attribute> <attribute> <code>SUPPORTS_BOOLEAN_DATA_TYPE</code> <attribute>Y</attribute> </attribute> <attribute> <code>SUPPORTS_TIMESTAMP_DATA_TYPE</code> <attribute>Y</attribute> </attribute> <attribute> <code>USE_POOLING</code> <attribute>N</attribute> </attribute> </attributes> </connection>
After the above DB connection sharing and configuration is completed, and then the job and transformation are processed, if the shared DB connection is selected, in fact, Kettle will copy the database configuration in shared.xml to the specific job and transformation. After copying, the corresponding variables will be read from kettle.properties.
In other words, if you want to publish jobs and transformations to a formal environment, you can actually do without sharing.xml, which is more used in the development phase.
In addition, notice that the shared and kettle.properties are modified each time. Restart the development tools of Kettle, or it may not work normally.