The model implements the translation from English to Chinese. In order to better show the figure of model architecture borrowing Tycoon (embeddings are not used here):
The complete code of this article: Github
catalog
1. Get sentences before and after translation
2. Create a dictionary about character index and index character
3. One hot coding for Chinese and English sentences
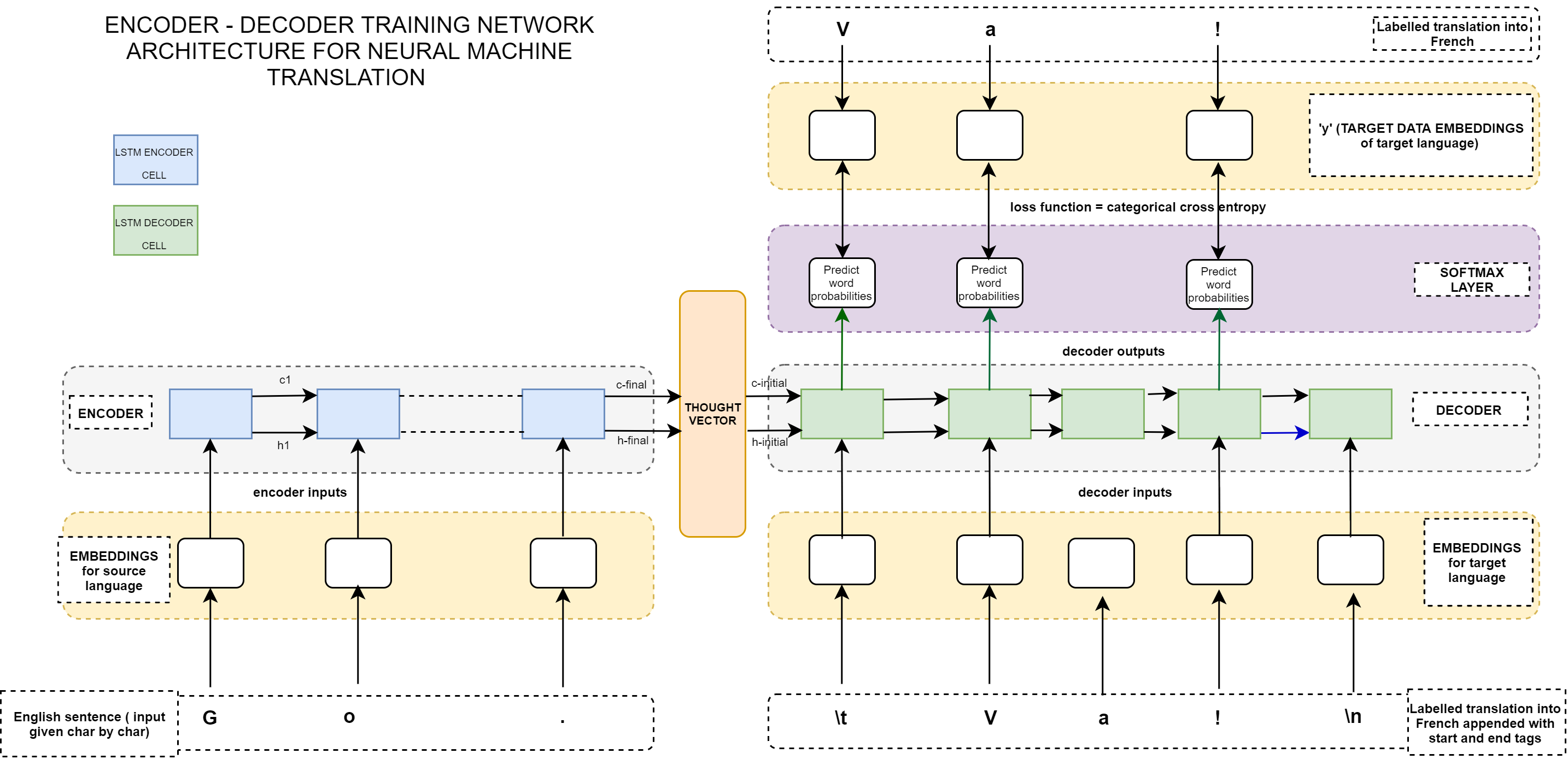
The whole system is composed of encoder and decoder. Each part has an LSTM network, in which encoder inputs the original sentence, decoder inputs the translated sentence with the start symbol, and the output is the target sentence with the end symbol Ford.
The specific steps are as follows:
1.encoder encodes the input sequence into state vector
2.decoder predicts from the first character
3. Feed the state vector to the decoder_ h,state_ c) And cumulatively contain the unique hot code of the previously predicted characters (the first state vector comes from encoder, and then the state vector comes from decoder and predict when predicting each character of each target sequence)
4. Use argmax to predict the position of the next character, and then find the corresponding character according to the dictionary
5. Add the characters in the previous step to the target sequence
6. End the loop until the prediction reaches the end character we specify
1, Processing text data
This step includes the segmentation of the original data to obtain the pre-translational and post translational sentences, the generation of character dictionary, and the one hot encoding of the pre-translational and post translational sentences to facilitate the processing of data.
1. Get sentences before and after translation
First, let's look at the style of the original data:
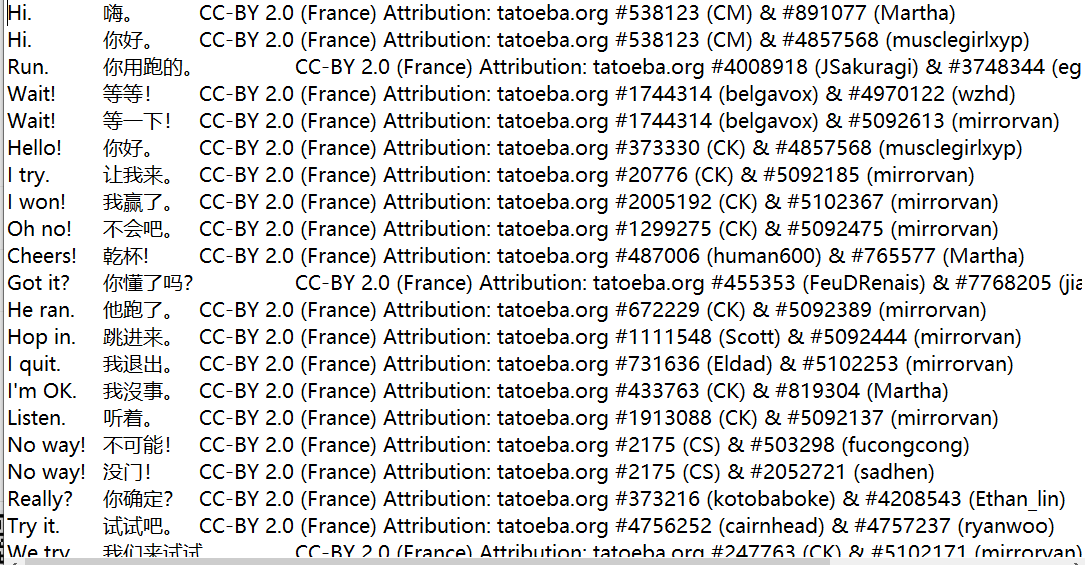
First import the required Library:
Code 1.1.1
import pandas as pd import numpy as np from keras.layers import Input, LSTM, Dense, merge,concatenate from keras.optimizers import Adam, SGD from keras.models import Model,load_model from keras.utils import plot_model from keras.models import Sequential #Defining parameters of neural network NUM_SAMPLES=3000 #Size of training sample batch_size = 64 #Number of samples selected in one training epochs = 100 #Number of training rounds latent_dim = 256 #Number of units of LSTM
Read the file with pandas, and then we just need the first two columns
Code 1.1.2
data_path='data/cmn.txt' df=pd.read_table(data_path,header=None).iloc[:NUM_SAMPLES,0:2] #Add title block df.columns=['inputs','targets'] #Raise your hand and add '\ t' as the start mark and '\ n' as the end mark in each Chinese sentence df['targets']=df['targets'].apply(lambda x:'\t'+x+'\n')
Finally, it is in the form of:
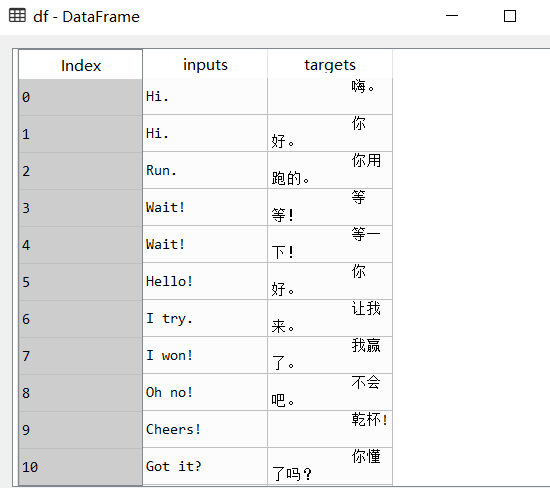
Then the data in English and Chinese are transformed into list form respectively
Code 1.1.3
#Get English and Chinese lists input_texts=df.inputs.values.tolist() target_texts=df.targets.values.tolist() #Determine the characters in Chinese and English. df.unique() take sum directly to splice each sentence in the unique array into a long sentence input_characters = sorted(list(set(df.inputs.unique().sum()))) target_characters = sorted(list(set(df.targets.unique().sum()))) #The number of different characters in English characters num_encoder_tokens = len(input_characters) #Number of different characters in Chinese characters num_decoder_tokens = len(target_characters) #Maximum input length INUPT_LENGTH = max([ len(txt) for txt in input_texts]) #Maximum output length OUTPUT_LENGTH = max([ len(txt) for txt in target_texts])
2. Create a dictionary about character index and index character
Code 1.2.1
input_token_index = dict( [(char, i)for i, char in enumerate(input_characters)] ) target_token_index = dict( [(char, i) for i, char in enumerate(target_characters)] ) reverse_input_char_index = dict([(i, char) for i, char in enumerate(input_characters)]) reverse_target_char_index = dict([(i, char) for i, char in enumerate(target_characters)])
3. One hot coding for Chinese and English sentences
Code 1.3.1
#Each corpus needs to be converted into three-dimensional data input required by LSTM [n_ Samples, timestamp, one hot feature] into the model
encoder_input_data =np.zeros((NUM_SAMPLES,INUPT_LENGTH,num_encoder_tokens))
decoder_input_data =np.zeros((NUM_SAMPLES,OUTPUT_LENGTH,num_decoder_tokens))
decoder_target_data = np.zeros((NUM_SAMPLES,OUTPUT_LENGTH,num_decoder_tokens))
for i,(input_text,target_text) in enumerate(zip(input_texts,target_texts)):
for t,char in enumerate(input_text):
encoder_input_data[i,t,input_token_index[char]]=1.0
for t, char in enumerate(target_text):
decoder_input_data[i,t,target_token_index[char]]=1.0
if t > 0:
# decoder_target_data does not contain the start character, and is better than decoder_input_data one step ahead
decoder_target_data[i, t-1, target_token_index[char]] = 1.02, Model building
Code 2.1
#Define encoder input
encoder_inputs=Input(shape=(None,num_encoder_tokens))
#Define LSTM layer, latent_dim is the number of neurons in each gate of the LSTM unit, return_ When state is set to True, the last state h,c will be returned
encoder=LSTM(latent_dim,return_state=True)
# Call the encoder to get the output of the encoder (the input is not needed), and the status information state_h and state UC
encoder_outputs,state_h,state_c=encoder(encoder_inputs)
# Discard encoder_ Output, we only need the state of the encoder
encoder_state=[state_h,state_c]
#Define decoder input
decoder_inputs=Input(shape=(None,num_decoder_tokens))
decoder_lstm=LSTM(latent_dim,return_state=True,return_sequences=True)
# Take the state of the encoder output as the initial state of the initial decoder
decoder_outputs,_,_=decoder_lstm(decoder_inputs,initial_state=encoder_state)
#Add full connection layer
decoder_dense=Dense(num_decoder_tokens,activation='softmax')
decoder_outputs=decoder_dense(decoder_outputs)
#Define the entire model
model=Model([encoder_inputs,decoder_inputs],decoder_outputs)
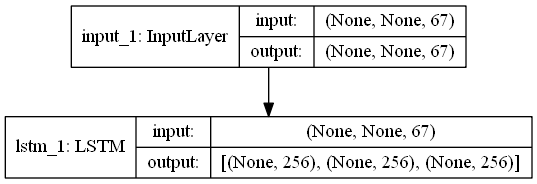
Model diagram of model:
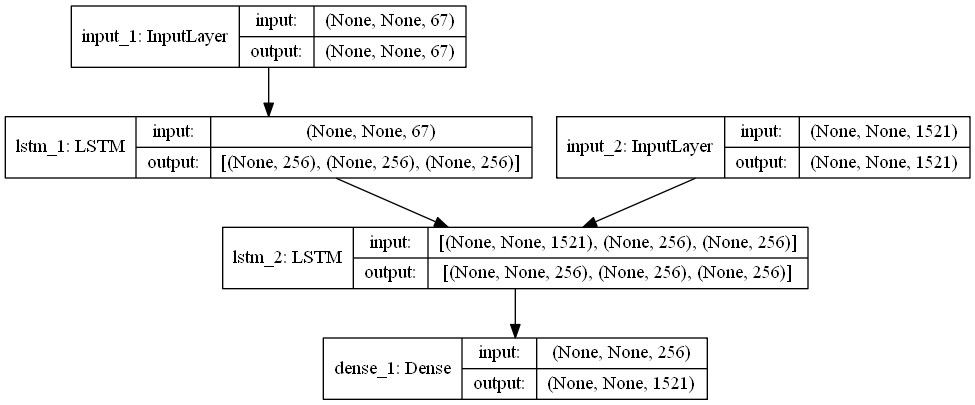
In each timestep, the decoder has three inputs: two state vectors from the encoder, state_h,state_c and one hot encoded Chinese sequence
Code 2.2
#Define the encoder model to get the output encoder_states
encoder_model=Model(encoder_inputs,encoder_state)
decoder_state_input_h=Input(shape=(latent_dim,))
decoder_state_input_c=Input(shape=(latent_dim,))
decoder_state_inputs=[decoder_state_input_h,decoder_state_input_c]
# Get the output and intermediate state of decoder
decoder_outputs,state_h,state_c=decoder_lstm(decoder_inputs,initial_state=decoder_state_inputs)
decoder_states=[state_h,state_c]
decoder_outputs=decoder_dense(decoder_outputs)
decoder_model=Model([decoder_inputs]+decoder_state_inputs,[decoder_outputs]+decoder_states)
plot_model(model=model,show_shapes=True)
plot_model(model=encoder_model,show_shapes=True)
plot_model(model=decoder_model,show_shapes=True)
return model,encoder_model,decoder_modelModel diagram of encoder:

Model diagram of decoder:
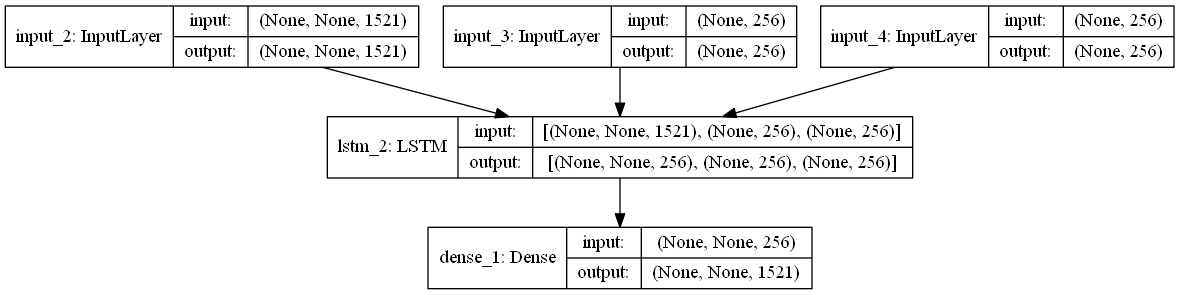
3. Coder predicts each character
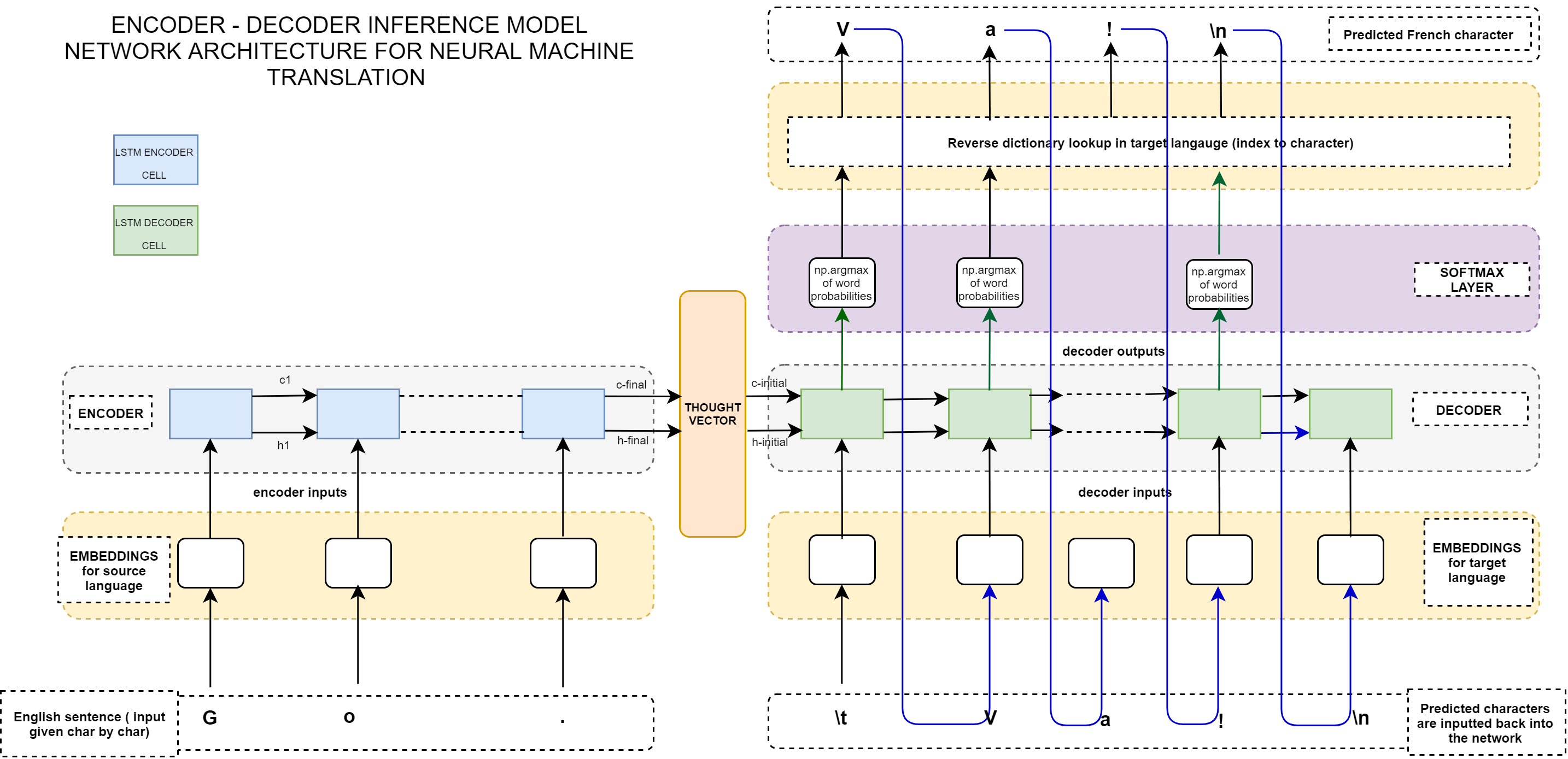
First, encoder generates the state vector states according to the input sequence_ Value is passed to the input layer of the decoder in combination with the code containing the start character "\ t", and the position of the next character is predicted_ token_ Index, add the new predicted character to target_ In SEQ, one hot coding is performed again, and the state vector generated by predicting the last character is used as the new state vector.
The above process continues to loop in while until the end character "\ n" is predicted. The loop ends and the translated sentence is returned. From the figure below, it can be seen that the decoder part is a sequence generated after translation. Note that the blue line points to the target_squence, it's constantly being filled.
Code 3.1
def decode_sequence(input_seq,encoder_model,decoder_model):
# Coding the input sequence to generate the state vector
states_value = encoder_model.predict(input_seq)
# Generate an empty sequence with size=1
target_seq = np.zeros((1, 1, num_decoder_tokens))
# Set the contents of this empty sequence to the start character
target_seq[0, 0, target_token_index['\t']] = 1.
# Character recovery
# For simplicity, suppose batch_size = 1
stop_condition = False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict([target_seq] + states_value)
# print(output_ The output here is the probability of the location of the next character
# Sample the next character_ token_ Index is to predict where the maximum probability of the next character will appear in the dictionary
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# Exit condition: generate or exceed the maximum sequence length
if sampled_char == '\n' or len(decoded_sentence) >INUPT_LENGTH :
stop_condition = True
# Update target_seq
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# Update intermediate status
states_value = [h, c]
return decoded_sentence
IV. training model
model,encoder_model,decoder_model=create_model()
#Compile model
model.compile(optimizer='rmsprop',loss='categorical_crossentropy')
#Training model
model.fit([encoder_input_data,decoder_input_data],decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
#Well trained models are saved for later testing
model.save('s2s.h5')
encoder_model.save('encoder_model.h5')
decoder_model.save('decoder_model.h5')Five. Exhibition
if __name__ == '__main__':
intro=input("select train model or test model:")
if intro=="train":
print("Training mode...........")
train()
else:
print("Test mode.........")
while(1):
test()


The training data used 3000 groups, most of which were short phrases or words. The effect is not so good, but it's better than English slag.

Reference:
https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
https://towardsdatascience.com/neural-machine-translation-using-seq2seq-with-keras-c23540453c74