Previous Getting started with seq2seq Referring to two papers by cho and utskever, today we'll look at how to build seq2seq with keras.
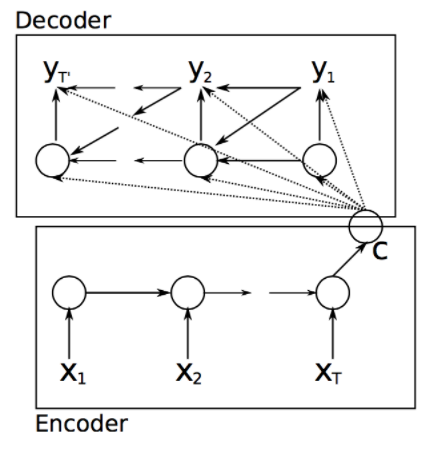
The first LSTM is Encoder and outputs only one semantic vector at the end of the sequence, so its "return_sequences" parameter is set to "False"
Use "RepeatVector" to copy N copies of Encoder's output (last time step) as Decoder's N inputs
The second LSTM is Decoder because it outputs every time step, so its "return_sequences" parameter is set to "True"
from keras.models import Sequential
from keras.layers.recurrent import LSTM
from keras.layers.wrappers import TimeDistributed
from keras.layers.core import Dense, RepeatVector
def build_model(input_size, max_out_seq_len, hidden_size):
model = Sequential()
# Encoder (first LSTM) model.add (LSTM (input_dim=input_size, output_dim=hidden_size, return_sequences=False)
model.add( Dense(hidden_size, activation="relu") )
# Use "RepeatVector" to copy N copies of Encoder's output (last time step) as Decoder's N inputs
model.add( RepeatVector(max_out_seq_len) )
# Decoder (second LSTM)
model.add( LSTM(hidden_size, return_sequences=True) )
# TimeDistributed is to ensure consistency between Dense and Decoder
model.add( TimeDistributed(Dense(output_dim=input_size, activation="linear")) )
model.compile(loss="mse", optimizer='adam')
return modelYou can also use GRU as the RNN unit, code as follows, the difference is to replace the LSTM with GRU:
from keras.layers.recurrent import GRU
from keras.layers.wrappers import TimeDistributed
from keras.models import Sequential, model_from_json
from keras.layers.core import Dense, RepeatVector
def build_model(input_size, seq_len, hidden_size):
"""Create a sequence to sequence Model"""
model = Sequential()
model.add(GRU(input_dim=input_size, output_dim=hidden_size, return_sequences=False))
model.add(Dense(hidden_size, activation="relu"))
model.add(RepeatVector(seq_len))
model.add(GRU(hidden_size, return_sequences=True))
model.add(TimeDistributed(Dense(output_dim=input_size, activation="linear")))
model.compile(loss="mse", optimizer='adam')
return modelThe above is the simplest seq2seq model, because the output from each moment of the Decoder is not used as input for the next moment.
Of course, we can use keras's seq2seq model directly:
https://github.com/farizrahman4u/seq2seq
Here are a few examples:
Simple seq2seq model:
import seq2seq
from seq2seq.models import SimpleSeq2Seq
model = SimpleSeq2Seq(input_dim=5, hidden_dim=10, output_length=8, output_dim=8)
model.compile(loss='mse', optimizer='rmsprop')Deep seq2seq model: encoding has three layers, decoding has three layers
import seq2seq
from seq2seq.models import SimpleSeq2Seq
model = SimpleSeq2Seq(input_dim=5, hidden_dim=10, output_length=8, output_dim=8, depth=3)
model.compile(loss='mse', optimizer='rmsprop')The number of layers of encoding and decoding can also be different: encoding has four layers and decoding has five layers
import seq2seq
from seq2seq.models import SimpleSeq2Seq
model = SimpleSeq2Seq(input_dim=5, hidden_dim=10, output_length=8, output_dim=20, depth=(4, 5))
model.compile(loss='mse', optimizer='rmsprop')The above are also the simplest applications of SimpleSeq2Seq.
In the seq2seq given in the paper Sequence to Sequence Learning with Neural Networks, the hidden layer state of encoder is passed to decoder, and the output of decoder at each moment is used as input for the next moment, and the hidden layer state is also passed through the entire LSTM in the built-in model here:
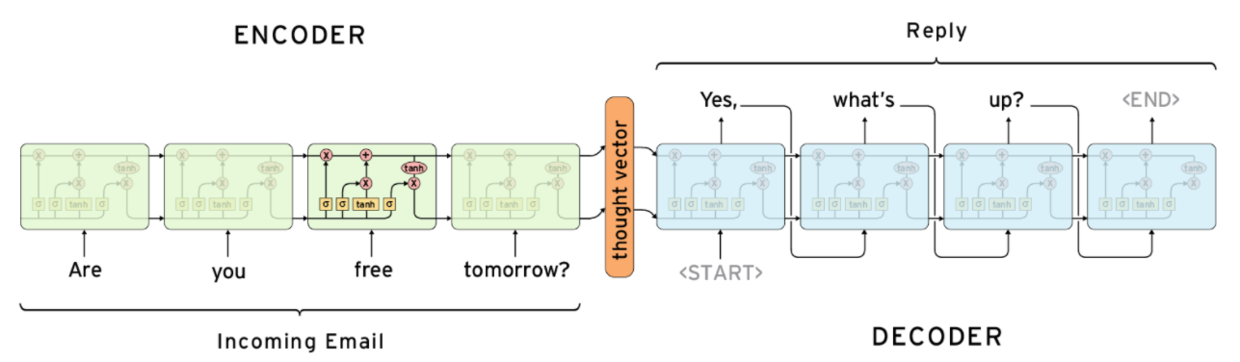
import seq2seq
from seq2seq.models import Seq2Seq
model = Seq2Seq(batch_input_shape=(16, 7, 5), hidden_dim=10, output_length=8, output_dim=20, depth=4)
model.compile(loss='mse', optimizer='rmsprop')This paper by cho, Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation s, implements the seq2seq model that decoder obtains a'peek'in the context vector at each point in time
import seq2seq
from seq2seq.models import Seq2Seq
model = Seq2Seq(batch_input_shape=(16, 7, 5), hidden_dim=10, output_length=8, output_dim=20, depth=4, peek=True)
model.compile(loss='mse', optimizer='rmsprop')seq2seq with attention mechanism in the article Neural Machine Translation by Jointly Learning to Align and Translate: there is no propagation of hidden state, and encoder is a two-way LSTM
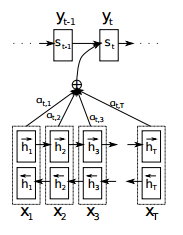
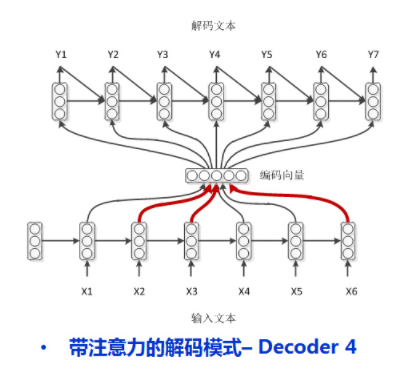
import seq2seq
from seq2seq.models import AttentionSeq2Seq
model = AttentionSeq2Seq(input_dim=5, input_length=7, hidden_dim=10, output_length=8, output_dim=20, depth=4)
model.compile(loss='mse', optimizer='rmsprop')Reference resources:
https://github.com/farizrahman4u/seq2seq
http://www.zmonster.me/2016/05/29/sequence_to_sequence_with_keras.html
http://jacoxu.com/encoder_decoder/
Recommended reading
Summary of historical technology blog links
Maybe you can find what you want