Chapter 1 keepalived service description
1.1 What is keeping alived?
Keepalived software was originally designed for LVS load balancing software to manage and monitor the status of each service node in the LVS cluster system. Later, it added VRRP function to realize high availability. Therefore, besides managing LVS software, Keepalived can also be used as a highly available solution software for other services (such as Nginx, Haproxy, MySQL, etc.).
Keepalived software mainly achieves high availability through VRRP protocol. VRRP is the abbreviation of Virtual Router Redundancy Protocol (VRRP). The purpose of VRRP is to solve the single point failure problem of static routing. It can ensure that the whole network can run uninterruptedly when individual nodes are down.
Therefore, Keepalived not only has the function of configuring and managing LVS, but also has the function of checking the nodes under LVS. On the other hand, Keepalived can also realize the high availability of system network services.
Keeping alived official website http://www.keepalived.org
1.2 Three important functions of the keepalived service
Management of LVS Load Balancing Software
Implementing Health Check of LVS Cluster Nodes
High availability as a system network service
1.3 Keepalived High Availability Fault Handover Transfer Principle
The failover transfer between Keepalived high availability service pairs is realized by VRRP (Virtual Router Redundancy Protocol).
When the Keepalived service works properly, the master Master node sends heartbeat messages to the standby node to tell the standby Backup node that it is still alive. When the master Master node fails, it cannot send heartbeat messages. Therefore, the standby node can not continue to detect heartbeat from the master Master node, so it calls its own takeover process. Sequence takes over IP resources and services of the master Master node. When the master master node restores, the standby Backup node will release the IP resources and services it takes over when the master node fails, and restore to the original standby role.
So what is VRRP?
VRRP, full name Virtual Router Redundancy Protocol, Chinese name virtual routing redundancy protocol, VRRP appears to solve the static single point failure problem, VRRP is a campaign mechanism to assign routing tasks to a VRRP router.
1.4 Keeping Alive Principle
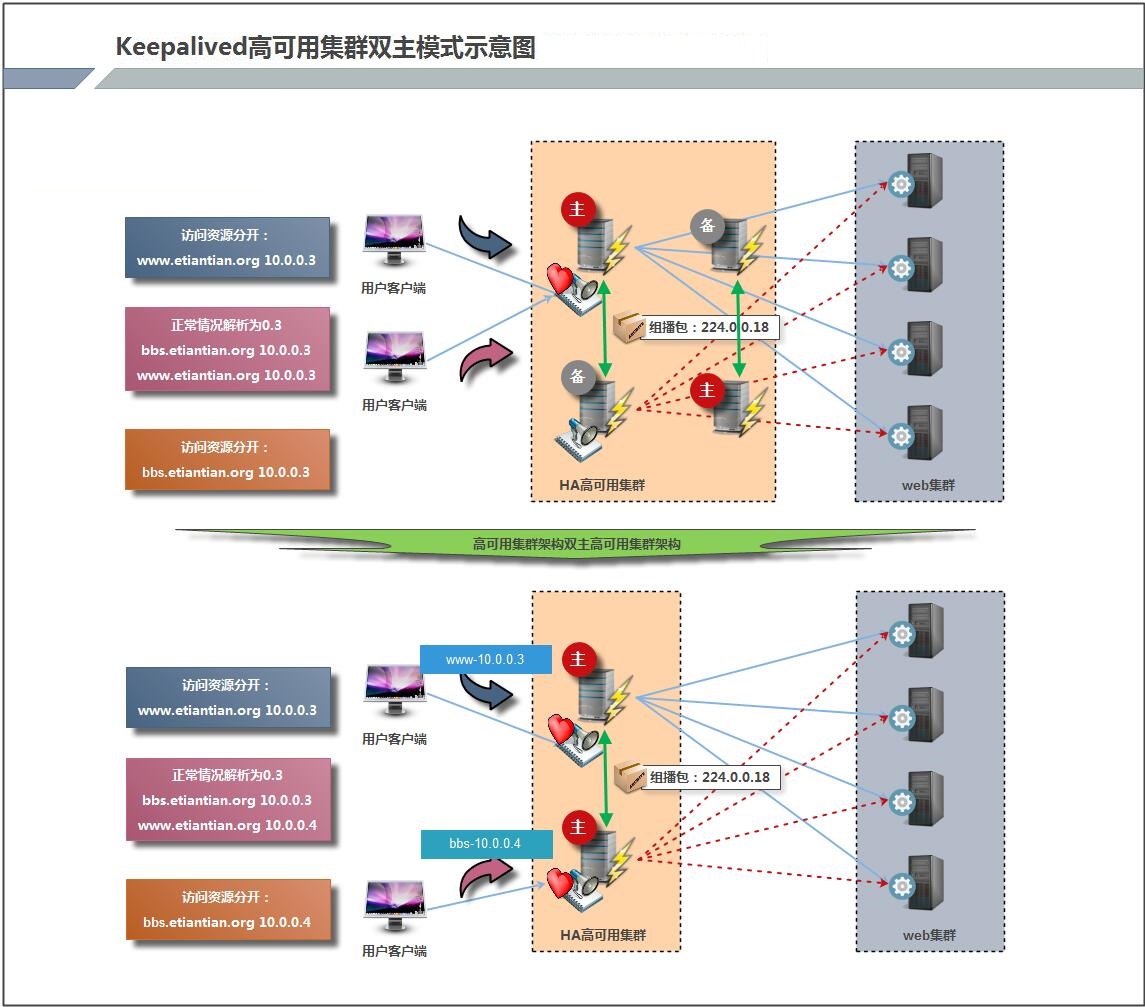
1.4.1 keepalived High Availability Architecture Diagram
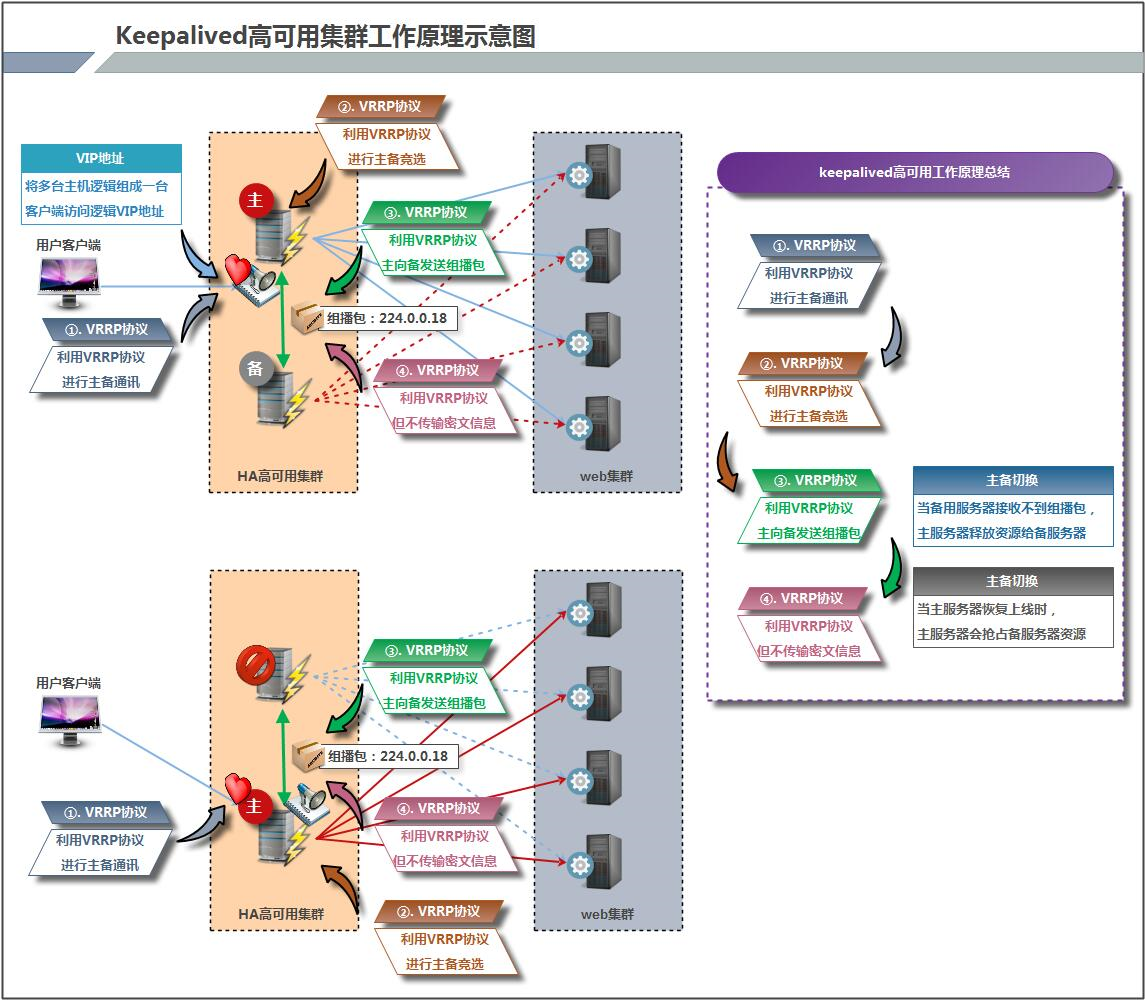
1.4.2 Texts, Expressions
How Keepalived works:
Keepalived high-availability pairs communicate with each other via VRRP, so we started with VRRP:
1) VRRP, full name Virtual Router Redundancy Protocol, Chinese name Virtual Routing Redundancy Protocol, the emergence of VRRP is to solve the single failure of static routing.
2) VRRP handed routing tasks to a VRRP router through an unexpected protocol mechanism.
3) VRRP uses IP multicast (default multicast address (224.0_0.18)) to achieve high-availability pair-to-pair communication.
4) At work, the primary node sends packets and the standby node receives packets. When the standby node can not receive the packets sent by the primary node, the takeover program starts to take over the open source of the primary node. Standby nodes can be multiple, through priority election, but the general Keepalived system operation and maintenance work is a pair.
5) VRRP uses encryption protocols to encrypt data, but Keepalived officials currently recommend plaintext to configure authentication types and passwords.
After introducing VRRP, let me introduce the working principle of Keepalived service.
Keepalived high-availability pairs communicate with each other through VRRP. VRRP defines the primary and standby through election mechanism, and the priority of the primary is higher than that of the standby. Therefore, when the primary hangs up, the standby node will take over the resources of the primary node, and then replace the primary node to provide services to the outside world.
Between Keepalived service pairs, only the main server will send VRRP broadcast packets all the time, telling the standby that it is still alive. At this time, the standby will not occupy the gun. When the main is unavailable, that is, when the standby can not listen to the broadcast packets sent by the main, it will start related services to take over resources to ensure business continuity. The fastest takeover speed can be less than 1 second.
Chapter 2 Keeping Alive Software Used
2.1 Software Deployment
2.1.1 First Milestone Keeping Alive Software Installation
yum install keepalived -y
/etc/keepalived /etc/keepalived/keepalived.conf #keepalived service master profile /etc/rc.d/init.d/keepalived #Service startup script /etc/sysconfig/keepalived /usr/bin/genhash /usr/libexec/keepalived /usr/sbin/keepalived
Second milestone: default configuration testing
2.1.2 Configuration File Description
Lines 1-13 represent global configuration
global_defs { #Global configuration
notification_email { Define alarm email address
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc #Define the address to send mail
smtp_server 192.168.200.1 #Mailbox Server
smtp_connect_timeout 30 #Define timeout time
router_id LVS_DEVEL #Define routing identification information that is unique to the same LAN
}
15-30 rows virtual ip configuration brrp
vrrp_instance VI_1 { #Defining examples
state MASTER #State parameters master/backup Just explain
interface eth0 #empty IP Location of Network Card in Address Placement
virtual_router_id 51 #The same family, the same cluster id Agreement
priority 100 # Priority decision is master or ready The bigger the priority
advert_int 1 #Time interval between primary and standby communication
authentication { # ↓
auth_type PASS #↓
auth_pass 1111 #Authentication
} #↑
virtual_ipaddress { #↓
192.168.200.16 Virtual use between devices ip address
192.168.200.17
192.168.200.18
}
}
Configuration Management LVS
Reference for details of LVS http://www.cnblogs.com/clsn/p/7920637.html#_label7
2.1.3 Final Profile
Master Load Balancing Server Configuration
[root@lb01 conf]# cat /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id lb01 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 150 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.3 } }
Standby Load Balancing Server Configuration
[root@lb02 ~]# cat /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id lb02 } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.3 } }
2.1.4 Start keepalived
[root@lb02 ~]# /etc/init.d/keepalived start Starting keepalived: [ OK ]
2.1.5 [Note] Make sure that the back-end nodes can be accessed independently before conducting access testing.
Testing connectivity. Backend nodes
[root@lb01 conf]# curl -H host:www.etiantian.org 10.0.0.8 web01 www [root@lb01 conf]# curl -H host:www.etiantian.org 10.0.0.7 web02 www [root@lb01 conf]# curl -H host:www.etiantian.org 10.0.0.9 web03 www [root@lb01 conf]# curl -H host:bbs.etiantian.org 10.0.0.9 web03 bbs [root@lb01 conf]# curl -H host:bbs.etiantian.org 10.0.0.8 web01 bbs [root@lb01 conf]# curl -H host:bbs.etiantian.org 10.0.0.7 web02 bbs
2.1.6 View virtual ip status
[root@lb01 conf]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:90:7f:0d brd ff:ff:ff:ff:ff:ff inet 10.0.0.5/24 brd 10.0.0.255 scope global eth0 inet 10.0.0.3/24 scope global secondary eth0:1 inet6 fe80::20c:29ff:fe90:7f0d/64 scope link valid_lft forever preferred_lft forever 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:90:7f:17 brd ff:ff:ff:ff:ff:ff inet 172.16.1.5/24 brd 172.16.1.255 scope global eth1 inet6 fe80::20c:29ff:fe90:7f17/64 scope link valid_lft forever preferred_lft forever
2.1.7 [Summary] Configuration File Modification
Keepalived Master and Standby Profile Differences:
Router_id information is inconsistent
02. state status description information is inconsistent
03. priority backup campaign priority values are inconsistent
2.2 cleft brain
In the high availability (HA) system, when the heartbeat of two nodes is disconnected, the HA system, which is a whole and coordinated action, is split into two independent individuals. Because they lost contact with each other, they all thought that the other party had broken down. HA software on two nodes, like "split-brain" people, competes for "shared resources" and "application services", and serious consequences will occur - or shared resources are divided, two "services" are not up; or both "services" are up, but at the same time read and write "shared storage", resulting in data damage (such as database polling online log error).
There are probably the following strategies to deal with HA system's "brain-splitting":
1) Adding redundant heartbeat lines, such as double lines (heartbeat lines are also HA), to minimize the occurrence of "brain cleavage";
2) Enable disk locks. While the server is locking the shared disk, when the "crack brain" occurs, the other party can not "rob" the shared disk resources completely. But there is also a big problem in using lock disk. If one side of the shared disk does not actively "unlock", the other side will never get the shared disk. In reality, unlocking commands cannot be executed if the service node suddenly crashes or crashes. The backup node can not take over the shared resources and application services. So someone designed an "intelligent" lock in HA. That is to say, only when the heartbeat is completely disconnected (the opposite end is not noticed) will the serving party activate the disk lock. Usually no locks.
3) Setting up arbitration mechanism. For example, setting a reference IP (such as gateway IP), when the heartbeat is completely disconnected, both nodes Ping the reference IP individually, otherwise the breakpoint is at the end. Not only the "heartbeat" but also the "service" of the external end of the network link is broken, even if it is useless to start (or continue) the application service, then take the initiative to abandon the competition, so that the end can ping reference IP to start the service. More safely, the party who does not refer to IP will simply restart itself to completely release the shared resources that may still be occupied.
2.2.1 Causes of cleft brain
Generally speaking, there are several reasons for the occurrence of schizophrenia:
(viii) Failure of heartbeat links between high-availability server pairs prevents normal communication.
Because the heartbeat is broken (including broken and aging).
ip configuration and conflict problems (network card direct connection) due to network card and related driver failure.
Fault of equipment (network card and switch) connected between heartbeats.
There is a problem with the arbitration mechanism (adopting the arbitration scheme).
(viii) Opening the iptables firewall on the high availability server blocked heartbeat message transmission.
(viii) Incorrect configuration of heartbeat network card address and other information on high-availability servers results in failure of sending heartbeat.
(viii) Other reasons such as inappropriate configuration of services, such as different heartbeat modes, heartbeat widespread interpolation conflicts, software Bug, etc.
Tip: The same VRRP instance in the Keepalived configuration may cause brain fissure if the parameters at both ends of virtual_router_id are not configured consistently.
2.2.2 Common Solutions
In the actual production environment, we can prevent the occurrence of brain fissure from the following aspects:
Use serial cable and Ethernet cable to connect at the same time, and use two heartbeat lines at the same time, so that one line is broken, the other is still good, still able to transmit heartbeat messages.
When brain fissure is detected, a heartbeat node is forcibly closed (this function requires special equipment support, such as Stonith, feyce). Equivalent to the standby node can not receive the heartbeat elimination, through a separate line to send the shutdown command to turn off the power supply of the main node.
Do a good job of monitoring and alarming cleft brain (e.g. email and short message on mobile phone or on duty). When the problem occurs, human intervention in arbitration is the first time to reduce losses. For example, Baidu's monitoring alarm has the difference between upstream and downstream in a short time. The alarm message is sent to the administrator's mobile phone. The administrator can return the corresponding number or simple string operation to the server through the mobile phone. The server can process the corresponding fault automatically according to the instructions, so that the time to solve the fault is shorter.
Of course, when implementing high availability solutions, it is necessary to determine whether such losses can be tolerated based on actual business needs. This loss is tolerable for normal website business.
2.3 How to monitor the condition of cleft brain
2.3.1 What servers are monitored?
For monitoring on standby servers, zabbix can be used for monitoring. http://www.cnblogs.com/clsn/p/7885990.html
2.3.2 What information is monitored?
Prepare for vip situation above:
1) The occurrence of cleft brain
2) Normal backup switching will also occur
2.3.3 Writing scripts to monitor cleft brain
[root@lb02 scripts]# vim check_keepalived.sh #!/bin/bash while true do if [ `ip a show eth0 |grep 10.0.0.3|wc -l` -ne 0 ] then echo "keepalived is error!" else echo "keepalived is OK !" fi done
Give execution privileges to scripts after they are written
2.3.4 Tests ensure that the two load balancers are able to load normally
[root@lb01 ~]# curl -H Host:www.etiantian.org 10.0.0.5 web01 www [root@lb01 ~]# curl -H Host:www.etiantian.org 10.0.0.6 web01 www [root@lb01 ~]# curl -H Host:bbs.etiantian.org 10.0.0.6 web02 bbs [root@lb01 ~]# curl -H Host:www.etiantian.org 10.0.0.5 web03 www
2.4 Row Missing
1) Using load balancing server, curl all node information on the server (web server configuration is problematic)
2) curl load balancing server address to achieve load balancing
3) Binding virtual IP on windows and testing on browsers
Keeping alived log file location/var/log/messages
2.5 Changing nginx reverse proxy configuration only listens for vip address
Modify nginx listening parameter listen 10.0.0.3:80;
Modify the kernel parameters to monitor ip that does not exist locally
echo 'net.ipv4.ip_nonlocal_bind = 1' >>/etc/sysctl.conf sysctl -p [root@lb02 conf]# cat /proc/sys/net/ipv4/ip_nonlocal_bind
2.6 Let keepalived monitor nginx
ps -ef |grep nginx |grep -v grep |wc -l
Write execution scripts
#!/bin/bash while true do if [ `ps -ef |grep nginx |grep -v grep |wc -l` -lt 2 ] then /etc/init.d/keepalived stop exit fi done
Note script authorization
[root@lb01 scripts]# chmod +x check_www.sh
2.6.1 Monitor script using keepalived
Explain that the script name to be executed should not be identical or similar to the service name as far as possible.
[root@lb01 scripts]# cat /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id lb01 } vrrp_script check { #Define script script ""/server/scripts/check_web.sh" --- Represents assigning a script information to a variable check_web interval 2 --- The interval between executing monitoring scripts weight 2 ---Use weights and priorities to perform operations, thereby reducing the priority of the primary service and making it a standby server (it is recommended to ignore it first) } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 150 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.3/24 dev eth0 label eth0:1 } track_script { #Call script check } }
2.7 Multi-instance Configuration
2.7.1 lb01 keepalived configuration file
[root@lb01 scripts]# cat /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id lb01 } vrrp_script check { script "/server/scripts/check_www.sh" interval 2 weight 2 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 150 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.3/24 dev eth0 label eth0:1 } track_script { check } } vrrp_instance VI_2 { state BACKUP interface eth0 virtual_router_id 52 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.4/24 dev eth0 label eth0:2 } }
2.7.2 Modify lb02's keepalived configuration file
[root@lb02 conf]# cat /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id lb02 } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.3 dev eth0 label eth0:1 } } vrrp_instance VI_2 { state MASTER interface eth0 virtual_router_id 52 priority 150 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.4 dev eth0 label eth0:2 } }
Modify the nginx configuration file to allow bbs and www to listen for different ip addresses, respectively
worker_processes 1; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; upstream server_pools { server 10.0.0.7:80; server 10.0.0.8:80; server 10.0.0.9:80; } server { listen 10.0.0.3:80; server_name www.etiantian.org; location / { proxy_pass http://server_pools; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $remote_addr; } } server { listen 10.0.0.4:80; server_name bbs.etiantian.org; location / { proxy_pass http://server_pools; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $remote_addr; } } }
lb01
[root@lb01 scripts]# netstat -lntup |grep nginx tcp 0 0 10.0.0.3:80 0.0.0.0:* LISTEN 84907/nginx tcp 0 0 10.0.0.4:80 0.0.0.0:* LISTEN 84907/nginx
lb02
[root@lb02 conf]# netstat -lntup |grep nginx tcp 0 0 10.0.0.3:80 0.0.0.0:* LISTEN 12258/nginx tcp 0 0 10.0.0.4:80 0.0.0.0:* LISTEN 12258/nginx