1. Introduction to keepalived
Keepalived software was originally designed for LVS load balancing software to manage and monitor the status of each service node in LVS cluster system. Later, it added VRRP function that can realize high availability. Therefore, in addition to managing LVS software, keepalived can also be used as high availability solution software for other services (such as Nginx, Haproxy, MySQL, etc.).
Keepalived software mainly realizes high availability through VRRP protocol. VRRP is the abbreviation of virtual router redundancy protocol. The purpose of VRRP is to solve the problem of single point of failure of static routing. It can ensure that the whole network can run continuously when individual nodes are down.
Therefore, on the one hand, kept has the function of configuring and managing LVS, and also has the function of health inspection for the nodes under LVS. On the other hand, it can also realize the high availability of system network services.
Keepalived's official website: https://www.keepalived.org/
2. Important functions of kept:
keepalived has three important functions:
- Manage load balancing software
- Implement health check of lvs cluster nodes
- High availability as a system network service (failover)
3. Principle of keepalived high availability failover
Failover between Keepalived high availability services is realized through VRRP (Virtual Router Redundancy Protocol).
When the Keepalived service works normally, the primary Master node will continuously send messages to the standby node (multicast) The heartbeat message is used to tell the standby Backup node that it is still alive. When the primary Master node fails, it cannot send the heartbeat message, so the standby node cannot continue to detect the heartbeat from the primary Master node, so it calls its own takeover program to take over the IP resources and services of the primary Master node. When the primary Master node recovers, the standby Backup node returns The IP resources and services taken over by the primary node in case of failure will be released and restored to the original standby role.
So, what is VRRP?
VRRP, the full name of which is Virtual Router Redundancy Protocol, is called virtual routing redundancy protocol in Chinese. The emergence of VRRP is to solve the single point of failure problem of static routing. VRRP gives the routing task to a VRRP router through a campaign mechanism.
4. Kept principle
4.1 architecture diagram of keepalived high availability
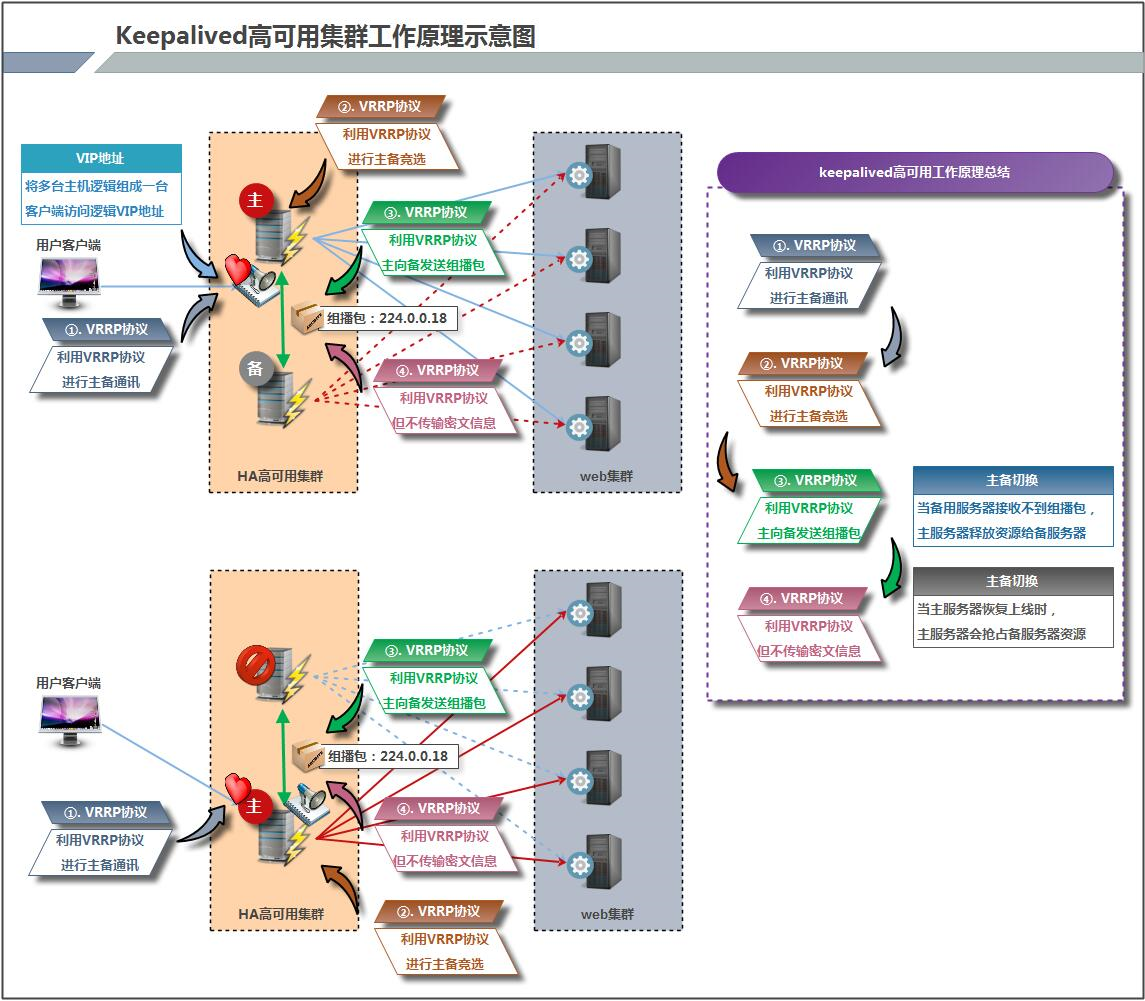
4.2 description of kept working principle
The communication between Keepalived high availability pairs is through VRRP. Therefore, we have learned from VRRP:
- VRRP, the full name of which is Virtual Router Redundancy Protocol, is called virtual routing redundancy protocol in Chinese. VRRP appears to solve the single point of failure of static routing.
- VRRP gives the routing task to a VRRP router through a competitive protocol mechanism.
- VRRP uses IP multicast to realize the communication between high availability pairs.
- During operation, the master node contracts and the standby node receives the packets. When the standby node cannot receive the data packets sent by the master node, it starts the takeover program to take over the open source of the master node. There can be multiple standby nodes competing through priority, but generally there are one pair in the operation and maintenance of the Keepalived system.
- VRRP uses encryption protocol to encrypt data, but Keepalived officials still recommend configuring authentication type and password in plaintext.
4.3 next, let's introduce the working principle of Keepalived service
Keepalived high availability communicates through VRRP. VRRP determines the active and standby through the election mechanism. The primary node has higher priority than the standby. Therefore, when working, the primary node will give priority to obtaining all resources, and the standby node is in the waiting state. When the primary node hangs up, the standby node will take over the resources of the primary node, and then provide services on behalf of the primary node.
Between Keepalived services, only the master server will always send VRRP broadcast packets and tell the standby server that it is still alive. At this time, the standby server will not occupy the master. When the master is unavailable, that is, the standby server cannot monitor the broadcast packets sent by the master, it will start relevant services to take over resources to ensure business continuity. The fastest takeover speed can be less than 1 second.
5. Explanation of keepalived configuration file
5.1 keepalived default profile
The main configuration file for keepalived is / etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs { //Global configuration
notification_email { //Define alarm recipient email address
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc //Define alarm sender mailbox
smtp_server 192.168.200.1 //Mailbox server address
smtp_connect_timeout 30 //Define mailbox timeout
router_id LVS_DEVEL //Define the routing identification information, which is unique in the LAN
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 { //Define instance
state MASTER //Specifies the initial state of the keepalived node. The optional value is master backup
interface eth0 //The network card interface bound to the VRRP instance, and the user sends VRRP packets
virtual_router_id 51 //The ID of the virtual route should be consistent in the same cluster
priority 100 //Define the priority and determine the active and standby roles according to the priority. The higher the priority, the higher the priority
nopreempt //Set no preemption
advert_int 1 //Time interval between active and standby communication
authentication { //Configuration authentication
auth_type PASS //Authentication method, password here
auth_pass 1111 //The keepalived configuration in the same cluster must be consistent here. It is recommended to use 8-bit random numbers
}
virtual_ipaddress { //Configure the VIP address to use
192.168.200.16
}
}
virtual_server 192.168.200.16 1358 { //Configure virtual server
delay_loop 6 //Health check interval
lb_algo rr //lvs scheduling algorithm
lb_kind NAT //lvs mode
persistence_timeout 50 //Persistence timeout in seconds
protocol TCP //Layer 4 protocol
sorry_server 192.168.200.200 1358 //Define the standby server. When all RS fail, use the sorry_server to respond to the client
real_server 192.168.200.2 1358 { //Define the server that actually handles the request
weight 1 //Assign a weight to the server. The default value is 1
HTTP_GET {
url {
path /testurl/test.jsp //Specify the URL path to check
digest 640205b7b0fc66c1ea91c463fac6334d //Summary information
}
url {
path /testurl2/test.jsp
digest 640205b7b0fc66c1ea91c463fac6334d
}
url {
path /testurl3/test.jsp
digest 640205b7b0fc66c1ea91c463fac6334d
}
connect_timeout 3 //Connection timeout
nb_get_retry 3 //get attempts
delay_before_retry 3 //How long is the delay before attempting
}
}
real_server 192.168.200.3 1358 {
weight 1
HTTP_GET {
url {
path /testurl/test.jsp
digest 640205b7b0fc66c1ea91c463fac6334c
}
url {
path /testurl2/test.jsp
digest 640205b7b0fc66c1ea91c463fac6334c
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
6. Customize the master profile
6.1 vrrp_instance section configuration
These two are mutually exclusive during setting. Only one configuration can exist nopreempt //Set to no preemption. The default is preemption. When the high priority machine recovers, it will preempt the low priority machine to become the MASTER. If not, the low priority machine is allowed to continue to become the MASTER, even if the high priority machine has been online. If you want to use this function, the initialization status must be BACKUP. preempt_delay //Set the preemption delay. The unit is seconds, the range is 0 --- 1000, and the default is 0. How many seconds do you start preemption after discovering a low priority MASTER.
6.2 vrrp#u script segment configuration
//Function: add a periodically executed script. The exit status code of the script will be called by all its VRRP Instance records.
//Note: at least one VRRP instance calls it and the priority cannot be 0. The priority range is 1-254
vrrp_script <SCRIPT_NAME> {
...
}
//Option Description:
script "/path/to/somewhere" //Specifies the path of the script to execute.
interval <INTEGER> //Specifies the interval between script execution. The unit is seconds. The default is 1s.
timeout <INTEGER> //Specifies the number of seconds after which the script is considered to have failed execution.
weight <-254 --- 254> //Adjust priority. The default is 2
rise <INTEGER> //How many times is it considered successful.
fall <INTEGER> //How many times does the execution fail before it is considered to fail.
user <USERNAME> [GROUPNAME] //Users and groups that run the script.
init_fail //Assume that the initial state of the script is the failed state.
//weight Description:
1. If the script executes successfully(Exit status code is 0),weight Greater than 0, then priority Increase.
2. If script execution fails(Exit status code is non-0),weight Less than 0, then priority Decrease.
3. In other cases, priority unchanged.
6.3 real_server segment configuration
weight <INT> //Assign weights to the server. The default is 1
inhibit_on_failure //When the server health check fails, set its weight to 0\
//Instead of removing from the Virtual Server
notify_up <STRING> //Script to execute when the server health check is successful
notify_down <STRING> //Script to execute when the server health check fails
uthreshold <INT> //Maximum number of connections to this server
lthreshold <INT> //Minimum number of connections to this server
6.4 tcp_check segment configuration
connect_ip <IP ADDRESS> //The IP address of the connection. The default is the IP address of the real server connect_port <PORT> //Connected port. The default is the port of the real server bindto <IP ADDRESS> //Address of the interface that initiated the connection. bind_port <PORT> //The source port that initiated the connection. connect_timeout <INT> //Connection timeout. The default is 5s. fwmark <INTEGER> //Use fwmark to mark all outgoing inspection packets. warmup <INT> //Specify a random delay of up to N seconds. Prevents network congestion. If 0, the function is turned off. retry <INIT> //Number of retries. The default is 1 time. delay_before_retry <INT> //The default is 1 second. How many seconds to delay before retrying.
7. Examples
global_defs {
router_id LVS_Server
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 150
nopreempt
advert_int 1
authentication {
auth_type PASS
auth_pass wangqing
}
virtual_ipaddress {
172.16.12.250 dev ens33
}
}
virtual_server 172.16.12.250 80 {
delay_loop 3
lvs_sched rr
lvs_method DR
protocol TCP
real_server 172.16.12.129 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 172.16.12.130 8080 {
weight 1
TCP_CHECK {
connect_port 8080
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
8. Keep alive to achieve high availability of httpd server
Environmental description
| system information | host name | IP |
|---|---|---|
| Redhat8.2 | master | 192.168.182.141 |
| Redhat8.2 | backup | 192.168.182.142 |
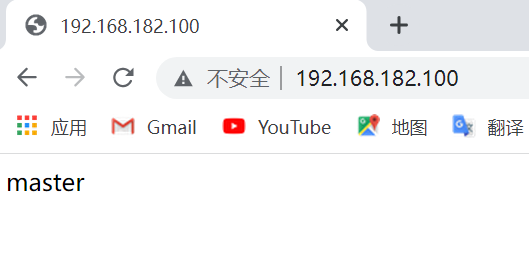
The VIP of this highly available service is 192.168.182.100
Configure keepalived on the master
Turn off the firewall and first selinux [root@master ~]# systemctl disable --now firewalld [root@master ~]# setenforce 0 setenforce: SELinux is disabled
Configure network source
[root@master ~]# curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-8.repo
Install epel source
[root@master ~]# yum -y install epel-release
Install keepalived
[root@master ~]# yum -y install keepalived
View files generated by installation
[root@master ~]# rpm -ql keepalived /etc/keepalived //configure directory /etc/keepalived/keepalived.conf //Master profile /etc/sysconfig/keepalived /usr/bin/genhash /usr/lib/systemd/system/keepalived.service //Service control document
Use the same method to install keepalived on the standby server
Turn off firewalls and selinux [root@backup ~]# systemctl disable --now firewalld [root@backup ~]# setenforce 0 setenforce: SELinux is disabled
Configure network source
[root@backup ~]# curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-8.repo
Install epel source
[root@backup ~]# yum -y install epel-release
Install keepalived
[root@backup ~]# yum -y install keepalived
8.1 install the httpd service on the active and standby machines respectively
[root@master ~]# yum -y install httpd Start the service and set the startup self startup [root@master ~]# systemctl enable --now httpd [root@master html]# pwd /var/www/html [root@master html]# cat index.html master
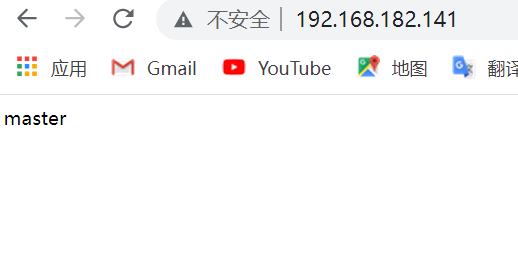
stay backup Upper operation [root@backup ~]# yum -y install httpd [root@backup html]# pwd /var/www/html [root@backup html]# cat index.html backup [root@backup ~]# systemctl enable --now httpd
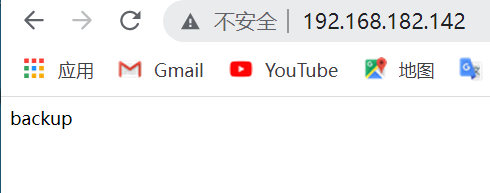
Configure keepalived on the master
[root@master keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb01
}
vrrp_instance VI_1 {
state MASTER
interface ens160
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 121388
}
virtual_ipaddress {
192.168.182.100
}
}
virtual_server 192.168.182.100 80 {
delay_loop 6
lb_algo rr
lb_kind DR
persistence_timeout 50
protocol TCP
real_server 192.168.182.141 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.182.142 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
[root@master keepalived]# systemctl enable --now keepalived.service
8.2 configuring standby keepalived
[root@backup keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb02
}
vrrp_instance VI_1 {
state BACKUP
interface ens160
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 121388
}
virtual_ipaddress {
192.168.182.100
}
}
virtual_server 192.168.182.100 80 {
delay_loop 6
lb_algo rr
lb_kind DR
persistence_timeout 50
protocol TCP
real_server 192.168.182.141 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.182.142 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
[root@backup keepalived]# systemctl enable --now keepalived.service
8.3 view VIP on MASTER
[root@master ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:18:28:7e brd ff:ff:ff:ff:ff:ff
inet 192.168.182.141/24 brd 192.168.182.255 scope global noprefixroute ens160
valid_lft forever preferred_lft forever
inet 192.168.182.100/32 scope global ens160
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe18:287e/64 scope link
valid_lft forever preferred_lft forever
####View VIP s on SLAVE
[root@backup keepalived]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:f4:b4:a9 brd ff:ff:ff:ff:ff:ff
inet 192.168.182.142/24 brd 192.168.182.255 scope global noprefixroute ens160
valid_lft forever preferred_lft forever
inet 192.168.182.100/32 scope global ens160
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fef4:b4a9/64 scope link
valid_lft forever preferred_lft forever
8.4 keepalived monitors the status of the httpd load balancer through scripts
[root@master ~]# mkdir /scripts
[root@master ~]# cd /scripts/
[root@master scripts]# vim check_ht.sh
[root@master scripts]# chmod +x check_ht.sh
[root@master scripts]# cat check_ht.sh
#!/bin/bash
httpd_status=$(ps -ef | grep -Ev "grep|$0" | grep -w httpd | wc -l)
if [ $httpd_status -lt 1 ];then
systemctl stop keepalived
fi
Configure the master keepalived file
[root@master scripts]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb01
}
vrrp_script httpd_check {
script "/scripts/check_h.sh"
interval 1
weight -20
}
vrrp_instance VI_1 {
state MASTER
interface ens160
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 121388
}
virtual_ipaddress {
192.168.182.100
}
track_script {
httpd_check
}
notify_master "/scripts/notify.sh master"
notify_backup "/scripts/notufy.sh backup"
}
virtual_server 192.168.182.100 80 {
delay_loop 6
lb_algo rr
lb_kind DR
persistence_timeout 50
protocol TCP
real_server 192.168.182.141 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.182.142 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
[root@master scripts]# systemctl restart keepalived.service
8.5 configuring standby keepalived
[root@backup scripts]# cat notify.sh
#!/bin/bash
VIP=$2
case "$1" in
master)
httpd_status=$(ps -ef | grep -Ev "grep|$0"|grep -w httpd | wc -l)
if [ $httpd_status -lt 1 ];then
systemctl start httpd
fi
sendmail
;;
backup)
httpd_status=$(ps -ef | grep -Ev "grep|$0" | grep -w httpd | wc -l)
if [ $httpd_status -gt 0 ];then
systemctl stop httpd
fi
;;
*)
echo "Usage:$0 master | backup VIP"
;;
esac
Configure the keepalived configuration of backup
[root@backup ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb02
}
vrrp_instance VI_1 {
state BACKUP
interface ens160
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 121388
}
virtual_ipaddress {
192.168.182.100
}
notify_master "/scripts/notify.sh master"
notify_backup "/scripts/notify.sh backup"
}
virtual_server 192.168.182.100 80 {
delay_loop 6
lb_algo rr
lb_kind DR
persistence_timeout 50
protocol TCP
real_server 192.168.182.141 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.182.142 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
[root@backup scripts]# systemctl restart keepalived.service
Simulate main service downtime
[root@master scripts]# systemctl stop httpd.service
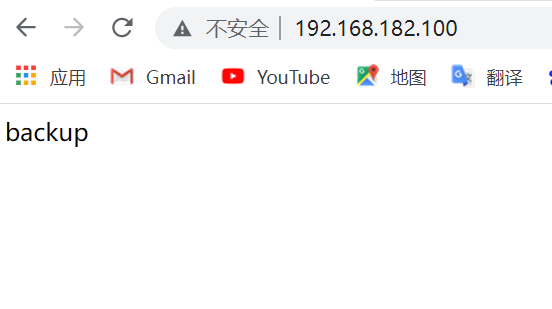
Shut down the service upgraded to the primary backup machine, and the primary machine returns to the master
[root@backup scripts]# systemctl stop httpd.service [root@master ~]# systemctl start keepalived