Hello, I'm brother Tu.
At present, he works as a big data algorithm engineer in a large Internet factory.
Today, a fan sent a message in the group asking if there is any information about Flink DDL, saying that he is a new learner.
In order to let this fan quickly learn how to use Flink DDL, I will explain the principle and attach the actual combat code through the case of Kafka - Flink -Hive.
1. Flink hive theory
1.1 introduction to Flink hive
In version 1.11 of Flink, a new function of the community is the real-time data warehouse, which can write the data of kafka sink to Hive in real time through kafka.
In order to realize this function, the following changes have been made in version 1.11 of Flink:
- The FlieSystemStreaming Sink is modified to add partition submission and scrolling policy mechanisms.
- Let HiveStreaming sink reuse the file system stream as the sink.
You can view the design idea of FLIP-85 Filesystem connector in Table through Flink community.
1.2 Flink hive integration principle
The schematic diagram of Flink and Hive integration is as follows:
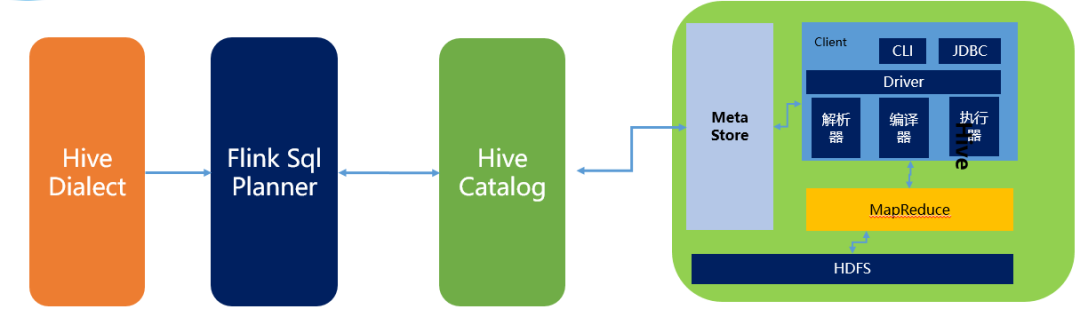
It mainly includes three parts:
- HiveDialect. The Hive Dialect is newly introduced in Flink 1.1, so the hive syntax, Hive Dialect, can be written in Flink SQL.
- After writing HIve SQL, FlinkSQL Planner will parse, verify and convert the SQL into logical plan and physical plan, and finally into Jobgraph.
- HiveCatalog. As the persistent medium of Flink and Hive, hivecatalog will store the Flink metadata of different sessions in the Hive Metastore.
1.3. Flink hive version support
Flink currently supports Hive's 1. X, 2. X and 3. X. each large version depends on Flink as follows:

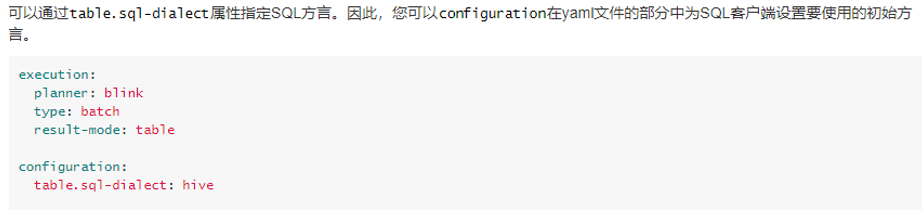
1.4. Flink SQL supports Hive language
Flink SQL supports two SQL languages, default and hive.
There are also two configuration methods, as shown in the figure below:
- Through client configuration.
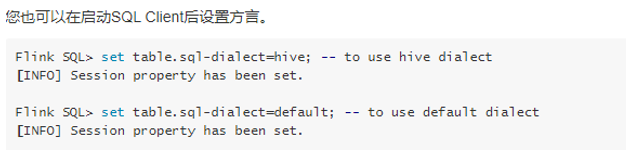
- Configure through SQL.
2. Kafka Flink hive cluster configuration
Requirement: store the data in kafka in real time in hive data warehouse through flink Sql calculation.
2.1 cluster deployment
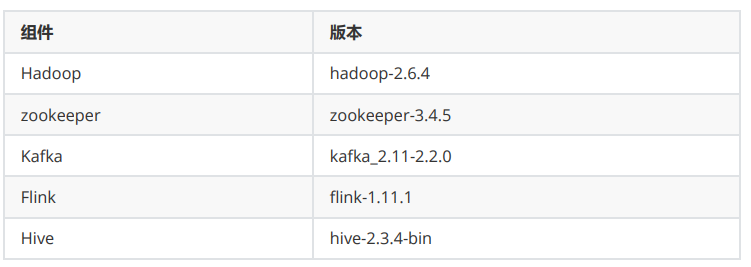
The configuration information is as follows:
- Hadoop: hadoop2.6.4
- Kafka: kafka_2.11-2.2.0
- Flink: flink1.13.0
- Hive: hive-2.3.4-bin
- Zookeeper: zookeeper-3.4.5
2.2 query result requirements
- The table structure of the data you want Flink Sql to query kafka is as follows:
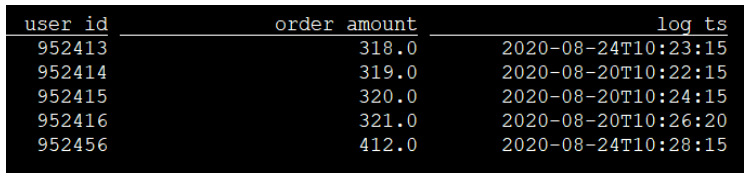
- You want FlinkSQL to insert the data in kafka into Hive query in real time. The query results are as follows according to the partition:

2.3 kafka start command
- kafka start
nohup ./kafka-server-start.sh ../config/server.properties &
- View kafka Topic
./kafka-topics.sh --list --bootstrap-server 192.168.244.161:9092 //Check whether there is a topic topic that needs to be used
- Create kafka Topic
kafka-topics.sh --create --bootstrap-server 192.168.244.161:9092 --topic test --partitions 10 --replication-factor 1
- Start kafka producer to transfer data in batches
kafka-console-producer.sh --broker-list 192.168.244.161:9092 --topic test
- Batch incoming data source to kafka
{"user_id": "1", "order_amount":"124.5", "log_ts": "2020-08-24 10:20:15"}
{"user_id": "2", "order_amount":"38.4", "log_ts": "2020-08-24 11:20:15"}
{"user_id": "3", "order_amount":"176.9", "log_ts": "2020-08-25 13:20:15"}
{"user_id": "4", "order_amount":"302", "log_ts": "2020-08-25 14:20:15"}
{"user_id": "5", "order_amount":"124.5", "log_ts": "2020-08-26 14:26:15"}
{"user_id": "6", "order_amount":"38.4", "log_ts": "2020-08-26 15:20:15"}
{"user_id": "7", "order_amount":"176.9", "log_ts": "2020-08-27 16:20:15"}
{"user_id": "8", "order_amount":"302", "log_ts": "2020-08-27 17:20:15"}
{"user_id": "9", "order_amount":"124.5", "log_ts": "2020-08-24 10:20:15"}
{"user_id": "10", "order_amount":"124.6", "log_ts": "2020-08-24 10:21:15"}
{"user_id": "11", "order_amount":"124.7", "log_ts": "2020-08-24 10:22:15"}
{"user_id": "12", "order_amount":"124.8", "log_ts": "2020-08-24 10:23:15"}
{"user_id": "13", "order_amount":"124.9", "log_ts": "2020-08-24 10:24:15"}
{"user_id": "14", "order_amount":"125.5", "log_ts": "2020-08-24 10:25:15"}
{"user_id": "15", "order_amount":"126.5", "log_ts": "2020-08-24 10:26:15"}
2.4 Hive integrated Flink
- HIV install modify hiv-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directory HADOOP_HOME=/root/sd/hadoop-2.6.4 # Hive Configuration Directory can be controlled by: export HIVE_CONF_DIR=/root/sd/apache-hive-2.3.4-bin/conf # Folder containing extra libraries required for hive compilation/execution can be controlled by: export HIVE_AUX_JARS_PATH=/root/sd/apache-hive-2.3.4-bin/lib
Since the hive file itself is saved in hdfs, Hadoop needs to be specified_ The path to home, specifying both the path to the configuration file and the path to the dependent package.
- Modify hive-site.xml file
<!--appoint mysql Database connected database-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.244.161:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hlink163:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/root/sd/apache-hive-2.3.4-bin/tmp/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/root/sd/apache-hive-2.3.4-bin/tmp/hive</value>
<description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}. </description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/root/sd/apache-hive-2.3.4-bin/tmp/hive/local</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/root/sd/apache-hive-2.3.4-bin/tmp/hive/resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
- Add the dependency between Flink and Hadoop. Add Hadoop dependency in flick-conf.yaml

2.5 Hive cluster startup
- Start hive server
hive --service metastore //Port number 9083
You can use the command to query to see whether it is started successfully
netstat -ntpl | grep 9083netstat -ntpl | grep 9083
2.6 Flink cluster startup
- Start Flink SQL (under bin directory)
./sql-client.sh embedded -d ../conf/sql-client-defaults.yaml
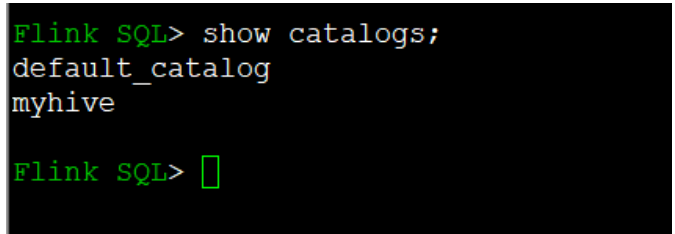
- View hive's catalogs under flick SQL
show catalogs
The results are as follows:
- Using myhive catalog
use catalog myhive; show tables;
3,kafka-Flink-Hive DDL
3.1. Create a flink to read kafka's table (source)
# Specifies that the default language for using flink sql is used SET table.sql-dialect=default; CREATE TABLE log_kafka ( user_id STRING, order_amount DOUBLE, log_ts TIMESTAMP(3), WATERMARK FOR log_ts AS log_ts - INTERVAL '5' SECOND ) WITH ( 'connector' = 'kafka', 'topic' = 'test', 'properties.bootstrap.servers' = '192.168.244.161:9092', 'scan.startup.mode' = 'earliest-offset', 'format' = 'json', 'json.ignore-parse-errors' = 'true', 'json.fail-on-missing-field' = 'false', 'properties.group.id' = 'flink1' );
The starting modes of kafka consumption are
'earliest-offset',
'latest-offset',
'group-offsets',
'timestamp',
'specific offsets' etc
3.2. Create a flick and write it into the hive table (sink)
SET table.sql-dialect=hive; CREATE TABLE log_hive ( user_id STRING, order_amount DOUBLE ) PARTITIONED BY (dt STRING, hr STRING) STORED AS parquet TBLPROPERTIES ( 'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00', 'sink.partition-commit.trigger'='partition-time', 'sink.partition-commit.delay'='1min', 'sink.semantic' = 'exactly-once', 'sink.rolling-policy.file-size'='128MB', 'sink.rolling-policy.rollover-interval' ='1min', 'sink.rolling-policy.check-interval'='1min', 'sink.partition-commit.policy.kind'='metastore,success-file' );
Configuration explanation:
-
'sink.partition-commit.trigger'='partition-time',
– use the time extracted from the partition and watermark to determine the time of partition commit -
'partition.time-extractor.timestamp-pattern'='dt hour:00:00',
– configure the partition time extraction policy at the hour level. In this example, the dt field is days in yyyy MM DD format and the hour is 0-23 hours. The timestamp pattern defines how to deduce the complete timestamp from these two partition fields -
'sink.partition-commit.delay'='1 h',
– configure dalay as hour level. When watermark > partition time + 1 hour, the partition will be commit ted -
'sink.partition-commit.policy.kind'='metastore,success-file'
– the strategy of partition commit is to update the metastore(addPartition) first, and then write the SUCCESS file
3.3. Insert data into hive
INSERT INTO TABLE log_hive SELECT user_id, order_amount,DATE_FORMAT(log_ts, 'yyyy-MM-dd'), DATE_FORMAT(log_ts, 'HH') FROM log_kafka;
3.4 query results
-- batch sql, select with partition pruning SELECT * FROM hive_table WHERE dt='2020-08-25' and hr='16';

4. Written by Kafka Flink hive table API
4.1 pom.xml configuration
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.flink</groupId>
<artifactId>flinkhive</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.bin.version>2.11</scala.bin.version>
<flink.version>1.11.1</flink.version>
<hadoop.version>2.6.4</hadoop.version>
<hive.version>2.3.4</hive.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.bin.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.bin.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_${scala.bin.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.bin.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_${scala.bin.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_${scala.bin.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
</dependencies>
</project>
4.2 screenshot of code storage path
Scala version code:
import java.time.Duration
import org.apache.flink.streaming.api.{CheckpointingMode, TimeCharacteristic}
import org.apache.flink.streaming.api.environment.ExecutionCheckpointingOptions
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.{EnvironmentSettings, SqlDialect}
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.table.catalog.hive.HiveCatalog
object KafkaToHive {
def main(args: Array[String]): Unit = {
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
streamEnv.setParallelism(3)
val tableEnvSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val tableEnv = StreamTableEnvironment.create(streamEnv, tableEnvSettings)
tableEnv.getConfig.getConfiguration.set(ExecutionCheckpointingOptions.CHECKPOINTING_MODE, CheckpointingMode.EXACTLY_ONCE)
tableEnv.getConfig.getConfiguration.set(ExecutionCheckpointingOptions.CHECKPOINTING_INTERVAL, Duration.ofSeconds(20))
val catalogName = "my_catalog"
val catalog = new HiveCatalog(
catalogName, // catalog name
"default", // default database
"./src/main/resources", // Hive config (hive-site.xml) directory
"2.3.4" // Hive version
)
tableEnv.registerCatalog(catalogName, catalog)
tableEnv.useCatalog(catalogName)
tableEnv.executeSql("CREATE DATABASE IF NOT EXISTS stream_tmp")
tableEnv.executeSql("DROP TABLE IF EXISTS stream_tmp.log_kafka")
tableEnv.executeSql(
"""
|CREATE TABLE stream_tmp.log_kafka (
| user_id STRING,
| order_amount DOUBLE,
| log_ts TIMESTAMP(3),
| WATERMARK FOR log_ts AS log_ts - INTERVAL '5' SECOND
|) WITH (
| 'connector' = 'kafka',
| 'topic' = 'test',
| 'properties.bootstrap.servers' = 'hlink163:9092',
| 'properties.group.id' = 'flink1',
| 'scan.startup.mode' = 'earliest-offset',
| 'format' = 'json',
| 'json.fail-on-missing-field' = 'false',
| 'json.ignore-parse-errors' = 'true'
|)
""".stripMargin
)
tableEnv.getConfig.setSqlDialect(SqlDialect.HIVE)
tableEnv.executeSql("CREATE DATABASE IF NOT EXISTS hive_tmp")
tableEnv.executeSql("DROP TABLE IF EXISTS hive_tmp.log_hive")
tableEnv.executeSql(
"""
|CREATE TABLE hive_tmp.log_hive (
| user_id STRING,
| order_amount DOUBLE
|) PARTITIONED BY (
| dt STRING,
| hr STRING
|) STORED AS PARQUET
|TBLPROPERTIES (
| 'sink.partition-commit.trigger' = 'partition-time',
| 'sink.partition-commit.delay' = '1 min',
| 'format' = 'json',
| 'sink.partition-commit.policy.kind' = 'metastore,success-file',
| 'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00'
|)
""".stripMargin
)
tableEnv.getConfig.setSqlDialect(SqlDialect.DEFAULT)
tableEnv.executeSql(
"""
|INSERT INTO hive_tmp.log_hive
|SELECT
| user_id,
| order_amount,
| DATE_FORMAT(log_ts, 'yyyy-MM-dd'), DATE_FORMAT(log_ts, 'HH')
| FROM stream_tmp.log_kafka
""".stripMargin
)
}
}
java version code:
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.environment.ExecutionCheckpointingOptions;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import java.time.Duration;
/**
* Class description:
*
* @ClassName KafkaToHive
* @Description:
* @Author: lyz
* @Date: 2021/9/6 9:50 PM
*/
public class KafkaToHive {
public static void main(String[] args) {
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
senv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
senv.setParallelism(3);
EnvironmentSettings tableEnvSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode()
.build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(senv, tableEnvSettings);
//
tableEnv.getConfig().getConfiguration().set(ExecutionCheckpointingOptions.CHECKPOINTING_MODE, CheckpointingMode.EXACTLY_ONCE);
tableEnv.getConfig().getConfiguration().set(ExecutionCheckpointingOptions.CHECKPOINTING_INTERVAL, Duration.ofSeconds(20));
String catalogName = "my_catalog";
HiveCatalog catalog = new HiveCatalog(
catalogName, // catalog name
"default", // default database
"./src/main/resources", // Hive config (hive-site.xml) directory
"2.3.4" // Hive version
);
tableEnv.registerCatalog(catalogName, catalog);
tableEnv.useCatalog(catalogName);
tableEnv.executeSql("CREATE DATABASE IF NOT EXISTS stream_tmp");
tableEnv.executeSql("DROP TABLE IF EXISTS stream_tmp.log_kafka");
tableEnv.executeSql("create table stream_tmp.log_kafka(" +
"user_id String,\n" +
"order_amount Double,\n" +
"log_ts Timestamp(3),\n" +
"WATERMARK FOR log_ts AS log_ts -INTERVAL '5' SECOND" +
")WITH(" +
" 'connector' = 'kafka',\n" +
"'topic' = 'test',\n" +
" 'properties.bootstrap.servers' = 'hlink163:9092',\n" +
"'properties.group.id' = 'flink1',\n" +
"'scan.startup.mode' = 'earliest-offset',\n" +
"'format' = 'json',\n" +
"'json.fail-on-missing-field' = 'false',\n" +
"'json.ignore-parse-errors' = 'true'" +
")");
tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
tableEnv.executeSql("CREATE DATABASE IF NOT EXISTS hive_tmp");
tableEnv.executeSql("DROP TABLE IF EXISTS hive_tmp.log_hive");
tableEnv.executeSql(" CREATE TABLE hive_tmp.log_hive (\n" +
" user_id STRING,\n" +
" order_amount DOUBLE\n" +
" ) PARTITIONED BY (\n" +
" dt STRING,\n" +
" hr STRING\n" +
" ) STORED AS PARQUET\n" +
" TBLPROPERTIES (\n" +
" 'sink.partition-commit.trigger' = 'partition-time',\n" +
" 'sink.partition-commit.delay' = '1 min',\n" +
" 'format' = 'json',\n" +
" 'sink.partition-commit.policy.kind' = 'metastore,success-file',\n" +
" 'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00'" +
" )");
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
tableEnv.executeSql("" +
" INSERT INTO hive_tmp.log_hive\n" +
" SELECT\n" +
" user_id,\n" +
" order_amount,\n" +
" DATE_FORMAT(log_ts, 'yyyy-MM-dd'), DATE_FORMAT(log_ts, 'HH')\n" +
" FROM stream_tmp.log_kafka");
}
}
The above is all the explanation. I think it's good. I like it. I'm watching it. Let's go!