Introduction to Kafka
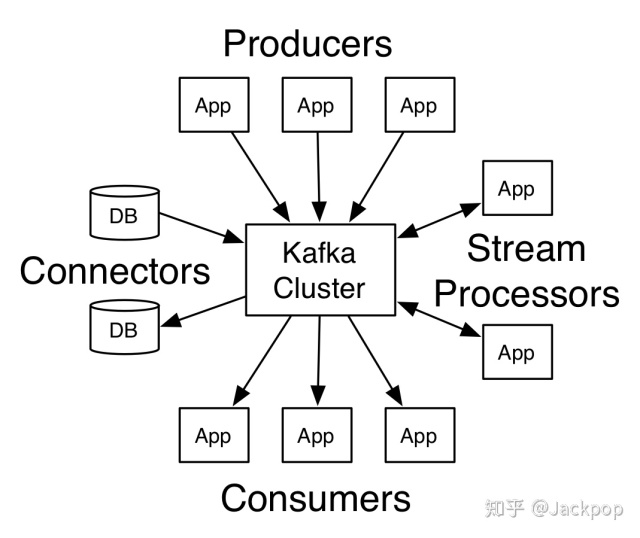
Kafka is a popular distributed message subscription system. In addition to Kafka, there are MQ, Redis, etc. We can regard the message queue as a pipeline. The two ends of the pipeline are the message producer and the message consumer respectively. After the message producer generates logs and other messages, it can be sent to the pipeline. At this time, the message queue can reside in memory or disk until the consumer reads it away.
The above is a summary of Kafka. We only need to understand Kafka's architecture and some professional terms. Let's introduce some professional terms in Kafka.
Producer: Message producer, responsible for sending the generated message to Kafka server.
Consumer: message consumer, reading messages from Kafka server.
Consumer Group: Consumer Group. Each message consumer can be divided into a specific group.
Topic: This is a very important term used by Kafka. It is equivalent to the "identity" of the message. When the message producer generates a message, it will attach a topic label to it. When the message consumer needs to read the message, he can read specific data according to this topic.
Broker: the server included in the Kafka cluster.
Kafka configuration
Download Kafka
Download kafka's tgz installation package,
Then unzip and enter the kafka path,
> tar -xzf kafka_2.12-2.4.0.tgz > cd kafka_2.12-2.4.0
Here we need to briefly introduce ZooKeeper, which is an open-source distributed coordination framework. It can encapsulate those error prone distributed consistency services to form an efficient, reliable and easy-to-use structure for users.
The reason why ZooKeeper is mentioned is that Kafka uses ZooKeeper as the coordination framework. Because the compressed package downloaded earlier already contains ZooKeeper, it is not necessary to download its installation package separately.
Start service
Before using Kafka, you need to start a ZooKeeper service. Here, you can directly use the script contained in Kafka,
> bin/zookeeper-server-start.sh config/zookeeper.properties
Start the ZooKeeper service before starting the Kafka service,
> bin/kafka-server-start.sh config/server.properties
It should be emphasized that config/server.properties is Kafka's configuration file, which can be used to configure the listening host, port, broker, etc.
The default ZooKeeper connection service is localhost:2181,
# Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=localhost:2181
In addition, the listening ports of producer and consumer are 9092. If you need to change the host and port ports of the server, you can configure them by modifying config/server.properties.
Kafka use
Here we mainly introduce two usage methods,
- command line
- Python
It should be noted that both the command line mode and Python mode are recommended based on the above, that is, you need to start ZooKeeper and Kafka services on the cluster first.
command line
The command line is relatively simple to use. After the Kafka configuration above, it can be used directly on the command line.
1. Create Topic
Using Kafka, we first need to create a Topic so that subsequent message producers and message consumers can send and consume data,
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
In this way, we create a Topic named test.
We can also view the topics we have created through the command,
> bin/kafka-topics.sh --list --zookeeper localhost:2181 test
2. Send message
As described in the professional terms of Kafka, Kafka needs to be used first Second hand mobile phone number purchase platform Only when the message producer sends the message can the consumer read the message.
Start a terminal A and execute the following command,
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test >hello world >
When the producer script is executed, a message input prompt will appear. We can enter a message (data), and then it will be sent to the corresponding server (Broker).
3. Consumption news
Now that there is data in the pipeline, I can use the consumer to read the data.
In addition, start a terminal B and execute the following command,
> ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning hello world
It can be seen that the message consumer is always listening. Whenever A message is input in terminal A, terminal B will also update A message.
Python-Kafka
Python is a popular programming language at present. Sometimes we need to call Kafka's interface directly in the project during the development process, so it is not convenient to use the command line method. Fortunately, Kafka provides a python toolkit. We only need to install the Kafka toolkit to directly call its API for use. Here is how to use Kafka in Python.
1. Install Kafka kit
> pip install kafka
2. Create Producer script
Import the Kafka Producer module and create a Producer script,
import json
from kafka import KafkaProducer
data = {"a": 1, "b": 2, "c":3}
producer = KafkaProducer(bootstrap_servers=["localhost:9092"],
api_version=(, 10, ),
value_serializer=lambda v: json.dumps(v).encode('utf-8'))
for i in range(1000):
producer.send("test", data, partition=)Here, data is the sample data used to send to the server, then the KafkaProducer interface is invoked and sent to server and api_ respectively. Version and other parameters.
3. Create a consumer script
By executing the Python script above, Producer can send messages to the specified server. Next, you can create a Consumer script to subscribe messages from the server,
from kafka import KafkaConsumer
consumer = KafkaConsumer('test',
group_id="group2",
bootstrap_servers=["localhost:9092"])
for msg in consumer:
print(msg.value)
# output
b'{"a": 1, "b": 2, "c": 3}'
b'{"a": 1, "b": 2, "c": 3}'
b'{"a": 1, "b": 2, "c": 3}'
b'{"a": 1, "b": 2, "c": 3}'
b'{"a": 1, "b": 2, "c": 3}'
b'{"a": 1, "b": 2, "c": 3}'
......In this way, the data read from the message queue can be output.
remarks
Kafka is positioned as a distributed message publish subscribe system. It can be imagined that its value can be maximized only in a multi node environment. The Kafka configuration methods described above are based on single node configuration. This paper is mainly to systematically sort out the configuration and use of Kafka, Therefore, it will not take much time to introduce the configuration in detail. If Kafka needs to configure multiple nodes, Kafka can consult other materials by itself.