1. @KafkaListener message listening
springboot Kafka uses the @KafkaListener annotation to listen for consumer messages. Message listening can be divided into two types: single data consumption and batch consumption. The difference is the number of messages that the listener obtains at one time.
The main interfaces used in message listening include top-level interface for listeners, single data consumption Message Listener, batch consumption BatchMessage Listener, Acknowledging Message Listener and BatchAcknowledging Message Listener with ACK mechanism, etc. See the listener of spring-kafka-XXX.jar for details.
Notes to @KafkaListener
When kafka integrates SpringBoot, we use @KafkaListener to listen for messages.
@KafkaListener(topics = {"connect-test"})
public void listen(ConsumerRecord<?, ?> record) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
if (kafkaMessage.isPresent()) {
Object message = kafkaMessage.get();
log.info("----------------- record =" + record);
log.info("------------------ message =" + message);
}
}
Using the @KafkaListener annotation is not limited to whether the listening container consumes single data or batch data. To distinguish between single data and multi-data consumption, you only need to configure the containerFactory attribute to be single data or batch data.
Let's look at the @KafkaListener configuration's available properties:
public @interface KafkaListener {
String id() default "";
String containerFactory() default "";
String[] topics() default {};
String topicPattern() default "";
TopicPartition[] topicPartitions() default {};
String containerGroup() default "";
String errorHandler() default "";
String groupId() default "";
boolean idIsGroup() default true;
String clientIdPrefix() default "";
String beanRef() default "__listener";
String concurrency() default "";
String autoStartup() default "";
String[] properties() default {};
}
id: Consumer's id,When GroupId When not configured, default id by GroupId
containerFactory: @KafkaListener To distinguish between single data consumption and multiple data consumption, just configure annotations containerFactory Attribute is OK, which is configured to listen on the container factory, that is to say ConcurrentKafkaListenerContainerFactory,To configure BeanName
topics: Need to be monitored Topic,Can monitor multiple
topicPartitions: You can configure more detailed listening information, and you must listen to one Topic In the specified partition, or from offset Start listening for offset 2000
errorHandler: Listen for exception handlers, configure BeanName
groupId: Consumption group ID
idIsGroup: id Is it GroupId
clientIdPrefix: Consumer Id prefix
beanRef: True monitor container BeanName,Need BeanName preposed "__"
Look at the parameters that the listening method can receive:
public void listen_1(String data) public void listen_2(ConsumerRecord<K,V> data) public void listen_3(ConsumerRecord<K,V> data, Acknowledgment acknowledgment) public void listen_4(ConsumerRecord<K,V> data, Acknowledgment acknowledgment, Consumer<K,V> consumer) public void listen_5(List<String> data) public void listen_6(List<ConsumerRecord<K,V>> data) public void listen_7(List<ConsumerRecord<K,V>> data, Acknowledgment acknowledgment) public void listen_8(List<ConsumerRecord<K,V>> data, Acknowledgment acknowledgment, Consumer<K,V> consumer) data : about data The type of value is not limited, according to KafkaTemplate The type defined is determined. data by List Collection is used for mass consumption. ConsumerRecord: Specific consumer data classes, including Headers Information, partition information, timestamp, etc. Acknowledgment: Be used as Ack Interface of mechanism Consumer: Consumer class, with which we can manually submit offsets, control consumption rate and other functions
3. Various ways of using @KafkaListener
1. Consumption with ConsumerRecord
The ConsumerRecord class contains partition information, message headers, message bodies, and so on. If the business needs to get these parameters, using ConsumerRecord is a good choice. In the first example, ConsumerRecord is used, so we won't repeat the posting code here. Let's look at the output log information:
2019-08-20 17:50:00.051 INFO 8392 --- [ntainer#0-0-C-1] com.example.demo.service.KafkaReceiver : ----------------- record =ConsumerRecord(topic = mytopic, partition = 0, leaderEpoch = 0, offset = 7, CreateTime = 1566208368115, serialized key size = -1, serialized value size = 20, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = test producer listen) 2019-08-20 17:50:00.051 INFO 8392 --- [ntainer#0-0-C-1] com.example.demo.service.KafkaReceiver : ------------------ message =test producer listen 2019-08-20 17:50:00.362 INFO 8392 --- [ntainer#0-0-C-1] com.example.demo.service.Kafka Receiver: --------------------------------- record = ConsumerRecord (topic = mytopic, partition = 0, leaderEpoch = 0, offset = 8, CreateTime = 1566208628627, serialized key size = 1, serialized value = 27, headers = headers = [], isReadOnly = false), key = null, value = the message is coming) 2019-08-20 17:50:00.362 INFO 8392 --- [ntainer#0-0-C-1] com.example.demo.service.Kafka Receiver: ------------------------------------------------------------------- message = the message is coming.
2. Bulk Consumption News
-
Create a new consumer configuration, which is configured to pull five messages at a time.
-
Create a monitor container factory, set it to batch consumption and set concurrency to 5, which depends on the number of partitions, must be less than or equal to the number of partitions, otherwise threads will remain idle.
-
Create a Topic with 8 partitions
-
Create a listener method, set the consumption id to batch, the client id prefix to batch, listen on topic-batch, and use the batch Container Factory to create the listener container
@Component public class BatchListener { private static final Logger log= LoggerFactory.getLogger(BatchListener.class); private Map<String, Object> consumerProps() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.135.128.39:9092,10.135.128.39:9093"); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000"); //Number of interest cancelled at one time props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "5"); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return props; } /** * Configuration of Monitoring Container Factory * @return */ @Bean("batchContainerFactory") public ConcurrentKafkaListenerContainerFactory listenerContainer() { ConcurrentKafkaListenerContainerFactory container = new ConcurrentKafkaListenerContainerFactory(); container.setConsumerFactory(new DefaultKafkaConsumerFactory(consumerProps())); //Set concurrent quantities, less than or equal to the number of partitions in Topic. Do not set them here. // container.setConcurrency(5); //Set to batch monitoring container.setBatchListener(true); return container; } @Bean public NewTopic batchTopic() { return new NewTopic("topic-batch", 8, (short) 2); } @KafkaListener(id = "batch",clientIdPrefix = "batch",topics = {"topic-batch"},containerFactory = "batchContainerFactory") public void batchListener(List<String> data) { log.info("topic-batch receive : "); for (String s : data) { log.info("-------messsage-------" +s); } } }
Start the project, view the log information of the console, and you can see the partition allocation information of the listener container, batchListener. We set concurrency to 5, that is, we will start five threads to listen, and we will create a topic with eight partitions, which means that three threads will be allocated to two partitions and two threads to one partition. You can see the last few lines of this log, which is the partition allocated by each thread.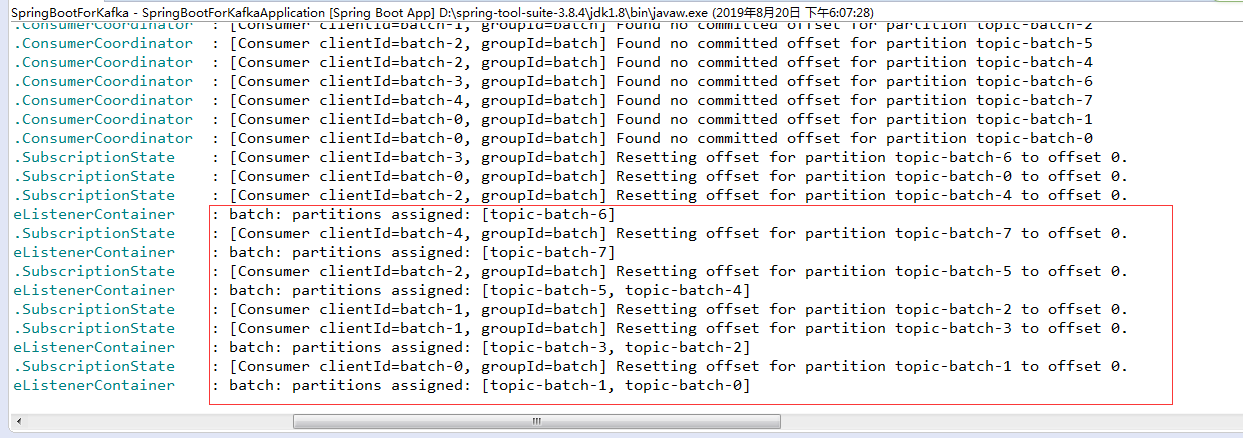
Write a test method, send 12 messages to topic in a short time, you can see the results of the operation, the corresponding monitoring method pulled three times, two of which are 5 data, one is 2 data, add up to 12 data we sent in the test method. This is in line with our set of 5 data for each batch consumption.
//KafkaSender.java adds test methods:
/**
* Bulk delivery
*/
public void batchSender(){
for (int i = 0; i < 50; i++) {
kafkaTemplate.send("topic-batch-new", "Haha, I'm No. 1" + i+"Message!");
}
}
//Main Start Class Call Test:
ConfigurableApplicationContext context = SpringApplication.run(SpringBootForKafkaApplication.class, args);
KafkaSender sender = context.getBean(KafkaSender.class);
sender.batchSender();
Look at the log to see the results
Note: container.setConcurrency(5); cannot be set, once set, the result will be completely different.
This setup refers to concurrency of the number of consumers to create. Here it is interpreted as starting five consumer threads. Five threads pull and cancel messages at the same time to pull up to five messages at a time. When the message data sent at the same time is large, you can see the effect again. There will be five pull-outs, some less than five pull-outs.
3. Listen for partitions specified in Topic
Use the topicPartitions property of the @KafkaListener annotation to listen for different partition partitions.
@ Topic Partition: topic -- the name of the Topic to listen on, partitions -- needs to listen on the partition id of the Topic.
partitionOffsets -- You can set up to listen from an offset
@ Partition Offset: partition -- partition Id, non-array, initial Offset -- initial offset
@Bean
public NewTopic batchTopic() {
return new NewTopic("topic-batch-partition", 8, (short) 2);
}
@KafkaListener(id = "batchWithPartition",clientIdPrefix = "bwp",containerFactory = "batchContainerFactory",
topicPartitions = {@TopicPartition(topic="topic-batch-partition",partitions={"0","1"}),
@TopicPartition(topic="topic-batch-partition",partitions={"4","5"},
partitionOffsets=@PartitionOffset(partition="2",initialOffset="2"))}
)
public void batchListenerWithPartition(@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partitionId,List<String> data) {
log.info("-----------topic-batch-partition received ---- partitionId="+ partitionId);
for (String s : data) {
log.info(s);
}
}
The above listener only listens to partition 0, 1, 4, 52 (the initial offset of 2 is 2). It uses the @Header annotation to get partitionId to write the test class to see the effect:
//KafkaSender.java adds test methods:
/**
* Batch sending partitions read a little more messages here, at least three or more messages per partition.
* It's good to see the initial migration of 2.
*/
public void batchSenderToPartition(){
for (int i = 0; i < 32; i++) {
kafkaTemplate.send("topic-batch-partition", "Haha, I'm No. 1" + i+"Message!");
}
}
//Main Start Class Call Test:
ConfigurableApplicationContext context = SpringApplication.run(SpringBootForKafkaApplication.class, args);
KafkaSender sender = context.getBean(KafkaSender.class);
sender.batchSenderToPartition();
Log information:
2019-08-21 14:58:28.296 INFO 9888 --- [Partition-4-C-1] com.example.demo.config.BatchListener : -----------topic-batch-partition received ---- partitionId=2 2019-08-21 14:58:28.296 INFO 9888 --- [Partition-4-C-1] com.example.demo.config.BatchListener : Haha, I'm the 22nd message! 2019-08-21 14:58:28.727 INFO 9888 --- [Partition-4-C-1] com.example.demo.config.BatchListener : -----------topic-batch-partition received ---- partitionId=2 2019-08-21 14:58:28.727 INFO 9888 --- [Partition-4-C-1] com.example.demo.config.BatchListener : Haha, I'm the first message! 2019-08-21 14:58:28.727 INFO 9888 --- [Partition-4-C-1] com.example.demo.config.BatchListener : Haha, I'm the ninth message! 2019-08-21 14:58:28.727 INFO 9888 --- [Partition-4-C-1] com.example.demo.config.BatchListener : Haha, I'm the seventeenth message! 2019-08-21 14:58:28.727 INFO 9888 --- [Partition-4-C-1] com.example.demo.config.BatchListener : Haha, I'm the 25th message! 2019-08-21 14:58:28.730 INFO 9888 --- [Partition-2-C-1] com.example.demo.config.BatchListener : -----------topic-batch-partition received ---- partitionId=4 2019-08-21 14:58:28.730 INFO 9888 --- [Partition-2-C-1] com.example.demo.config.BatchListener : Haha, I'm the sixth message! 2019-08-21 14:58:28.731 INFO 9888 --- [Partition-2-C-1] com.example.demo.config.BatchListener : Haha, I'm the 14th message! 2019-08-21 14:58:28.731 INFO 9888 --- [Partition-2-C-1] com.example.demo.config.BatchListener : Haha, I'm the 22nd message! 2019-08-21 14:58:28.731 INFO 9888 --- [Partition-2-C-1] com.example.demo.config.BatchListener : Haha, I'm the 30th message! 2019-08-21 14:58:28.735 INFO 9888 --- [Partition-1-C-1] com.example.demo.config.BatchListener : -----------topic-batch-partition received ---- partitionId=1 2019-08-21 14:58:28.735 INFO 9888 --- [Partition-1-C-1] com.example.demo.config.BatchListener : Haha, I'm the 0th message! 2019-08-21 14:58:28.735 INFO 9888 --- [Partition-1-C-1] com.example.demo.config.BatchListener : Haha, I'm the eighth message! 2019-08-21 14:58:28.735 INFO 9888 --- [Partition-1-C-1] com.example.demo.config.BatchListener : Haha, I'm the 16th message! 2019-08-21 14:58:28.735 INFO 9888 --- [Partition-1-C-1] com.example.demo.config.BatchListener : Haha, I'm the 24th message! 2019-08-21 14:58:28.736 INFO 9888 --- [Partition-3-C-1] com.example.demo.config.BatchListener : -----------topic-batch-partition received ---- partitionId=5 2019-08-21 14:58:28.736 INFO 9888 --- [Partition-3-C-1] com.example.demo.config.BatchListener : Haha, I'm the third message! 2019-08-21 14:58:28.736 INFO 9888 --- [Partition-3-C-1] com.example.demo.config.BatchListener : Haha, I'm the 11th message! 2019-08-21 14:58:28.736 INFO 9888 --- [Partition-3-C-1] com.example.demo.config.BatchListener : Haha, I'm the nineteenth message! 2019-08-21 14:58:28.736 INFO 9888 --- [Partition-3-C-1] com.example.demo.config.BatchListener : Haha, I'm the 27th message! 2019-08-21 14:58:28.739 INFO 9888 --- [Partition-0-C-1] com.example.demo.config.BatchListener : -----------topic-batch-partition received ---- partitionId=0 2019-08-21 14:58:28.739 INFO 9888 --- [Partition-0-C-1] com.example.demo.config.BatchListener : Haha, I'm the second message! 2019-08-21 14:58:28.739 INFO 9888 --- [Partition-0-C-1] com.example.demo.config.BatchListener : Haha, I'm the 10th message! 2019-08-21 14:58:28.739 INFO 9888 --- [Partition-0-C-1] com.example.demo.config.BatchListener : Haha, I'm the eighteenth message! 2019-08-21 14:58:28.739 INFO 9888 --- [Partition-0-C-1] com.example.demo.config.BatchListener : Haha, I'm the twenty-sixth message!
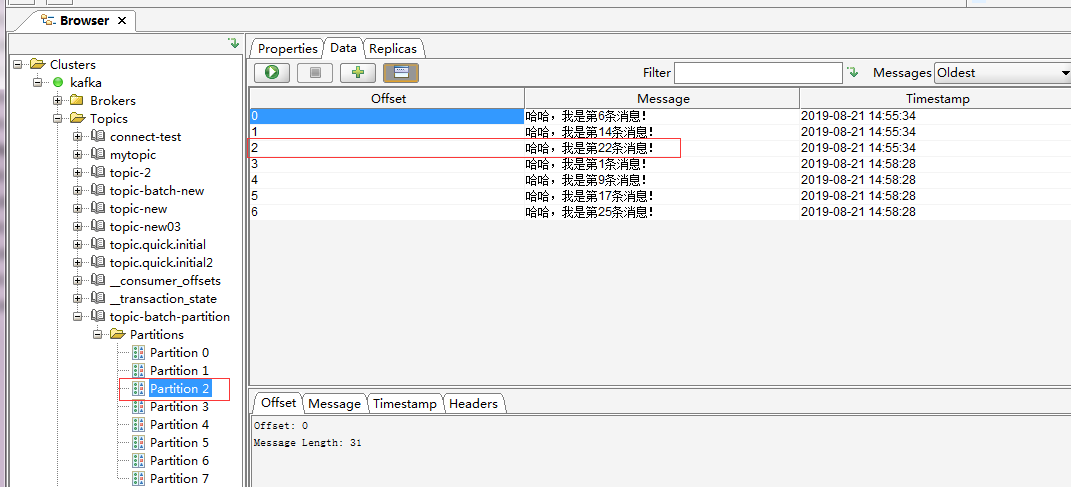
The test results only listen to the specified partition message and can specify that the message with a certain offset can be read.
4. Obtaining message header and body by annotation
When the received message contains a request header and the listening method needs to obtain a large number of fields of the message, the header and body can be obtained by annotation.
Let's look at the notes below.
@ Payload: What you get is the body of the message, which is what you send.
@ Header (Kafka Headers. RECEIVED_MESSAGE_KEY): Gets the key to send the message
@ Header (Kafka Headers. RECEIVED_PARTITION_ID): Get the current message from which partition to listen
@ Header (Kafka Headers. RECEIVED_TOPIC): Get the monitored TopicName
@ Header (Kafka Headers. RECEIVED_TIMESTAMP): Get the timestamp
/**
* Annotation header message body note: serialized deserialized type of key
* @param data
* @param keys
* @param partitions
* @param topics
* @param timestamp
*/
@KafkaListener(id = "head", topics = "topic-new")
public void annoListener(@Payload List<String> data,
@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) List<Integer> keys,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) List<Integer> partitions,
@Header(KafkaHeaders.RECEIVED_TOPIC) List<String> topics,
@Header(KafkaHeaders.RECEIVED_TIMESTAMP) List<Long> timestamp) {
for (int i=0;i<data.size();i++) {
log.info("topic-batch receive : \n"+
"data : "+data.get(i)+"\n"+
"key : "+keys.get(i)+"\n"+
"partitionId : "+partitions.get(i)+"\n"+
"topic : "+topics.get(i)+"\n"+
"timestamp : "+timestamp.get(i)+"\n"
);
}
}
Test methods:
/**
* Header header testing
* @throws InterruptedException
*/
public void senderHead(){
for(int i=0;i<5;i++){
Map map = new HashMap<>();
map.put(KafkaHeaders.TOPIC, "topic-new");
map.put(KafkaHeaders.MESSAGE_KEY, i);
map.put(KafkaHeaders.PARTITION_ID, i);
map.put(KafkaHeaders.TIMESTAMP, System.currentTimeMillis());
kafkaTemplate.send(new GenericMessage<>("test anno listener", map));
}
}
No specific test results will be posted here. Just execute as above.
5. Ack Message Consumption Confirmation Mechanism
Kafka consumes messages by the latest saved offset, and confirms that the consumed messages will not be deleted immediately, so we can repeatedly consume data that has not been deleted. When the first message is not confirmed and the second message is confirmed, Kafka will save the offset of the second message, that is to say, when the first message is not confirmed, Kafka will save the offset of the second message. A message will never be retrieved by the listener unless it is manually retrieved based on the offset of the first message.
Using Kafka's Ack mechanism requires the following settings:
-
Set ENABLE_AUTO_COMMIT_CONFIG=false to prohibit automatic submission of settings
-
AckMode=MANUAL_IMMEDIATE
-
The Acknowledgment ack parameter is added to the listening method
private Map<String, Object> consumerProps() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.135.128.39:9092,10.135.128.39:9093"); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); //Change from automatic submission to false requires manual confirmation of message consumption props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000"); //Number of interest cancelled at one time props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "5"); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return props; } /** * Configure ackContainerFactory to set ack validation mechanism * @return */ @Bean("ackContainerFactory") public ConcurrentKafkaListenerContainerFactory ackContainerFactory() { ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory(); factory.setConsumerFactory(new DefaultKafkaConsumerFactory(consumerProps())); factory.getContainerProperties().setAckMode(AckMode.MANUAL_IMMEDIATE); factory.setConsumerFactory(new DefaultKafkaConsumerFactory(consumerProps())); return factory; } @KafkaListener(id = "ack", topics = "topic-ack",containerFactory = "ackContainerFactory") public void ackListener(ConsumerRecord record, Acknowledgment ack) { log.info("topic-ack receive : " + record.value()); ack.acknowledge(); }
There is no specific test method here.