
In the previous section, we analyzed the core components of Producer and obtained a key component diagram. Do you remember?
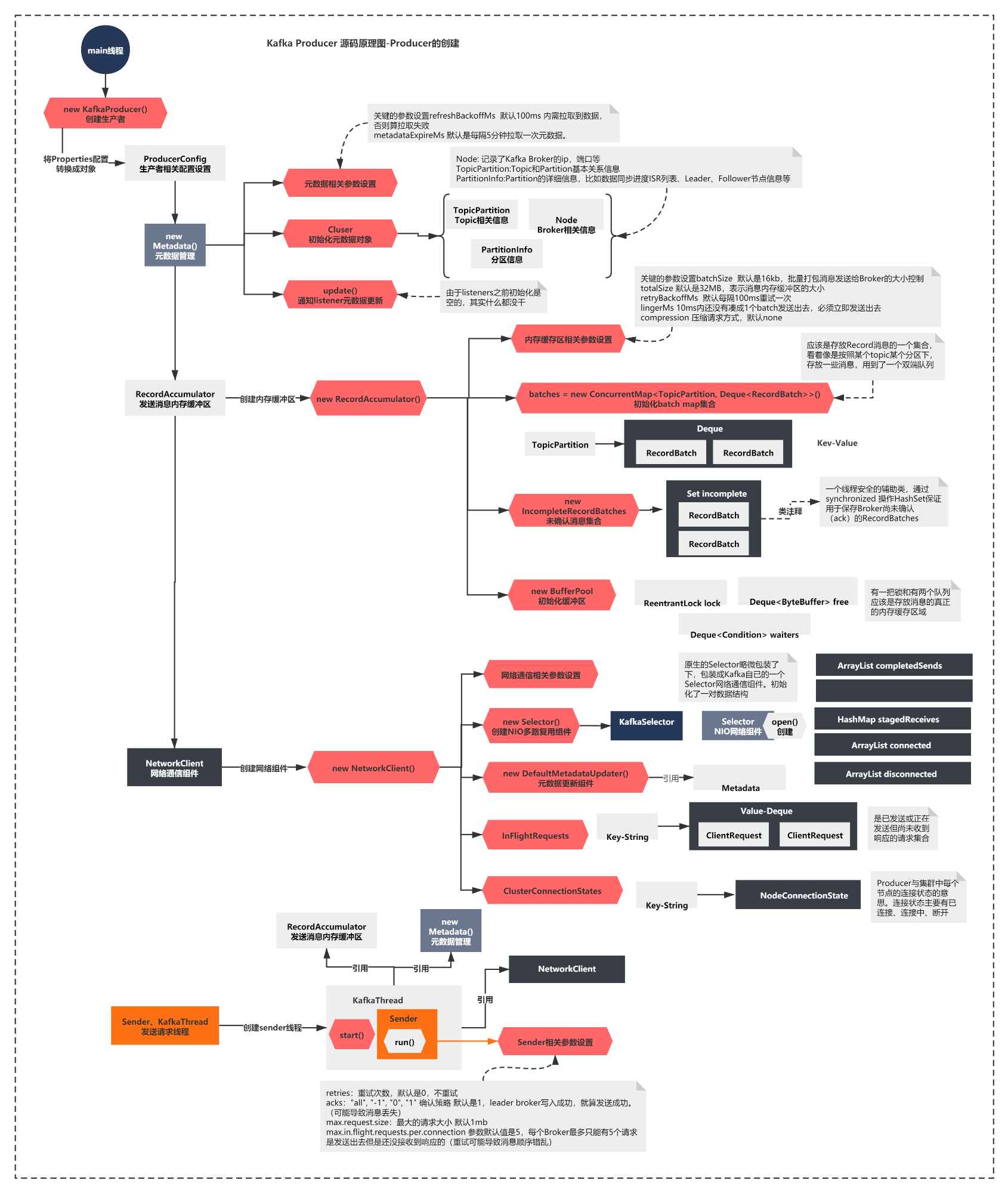
To sum up, the above figure is:
The Metadata component is created, and the Metadata is maintained internally through the Cluster
The memory buffer RecordAccumulator that sent the message was initialized
The NetworkClient is created, and the most important thing is to create the Selector component of NIO
A Sender thread is started. The Sender references all the above components and starts to execute the run method.
At the bottom of the figure, we can see that the last section ends with the execution of the run method. In this section, we will first look at what the core context of the run method does. Then analyze the first core process of Producer: the source code principle of metadata pull.
Let's start!
What is the Sender's run method doing?
In this section, we will continue to analyze what the sender's run method will do when it starts executing.
public void run() {
log.debug("Starting Kafka producer I/O thread.");
// main loop, runs until close is called
while (running) {
try {
run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
log.debug("Beginning shutdown of Kafka producer I/O thread, sending remaining records.");
// okay we stopped accepting requests but there may still be
// requests in the accumulator or waiting for acknowledgment,
// wait until these are completed.
while (!forceClose && (this.accumulator.hasUnsent() || this.client.inFlightRequestCount() > 0)) {
try {
run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
if (forceClose) {
// We need to fail all the incomplete batches and wake up the threads waiting on
// the futures.
this.accumulator.abortIncompleteBatches();
}
try {
this.client.close();
} catch (Exception e) {
log.error("Failed to close network client", e);
}
log.debug("Shutdown of Kafka producer I/O thread has completed.");
}The core context of this run method is simple. It is mainly the two while loops + thread close. For the two while loops, they all call the run(long time) method.
You can see from the comments that the second while handles special situations. After the first while exits, there are still unsent requests. The thread will not be closed until the second while loop processing is completed.
The overall context is shown in the figure below:
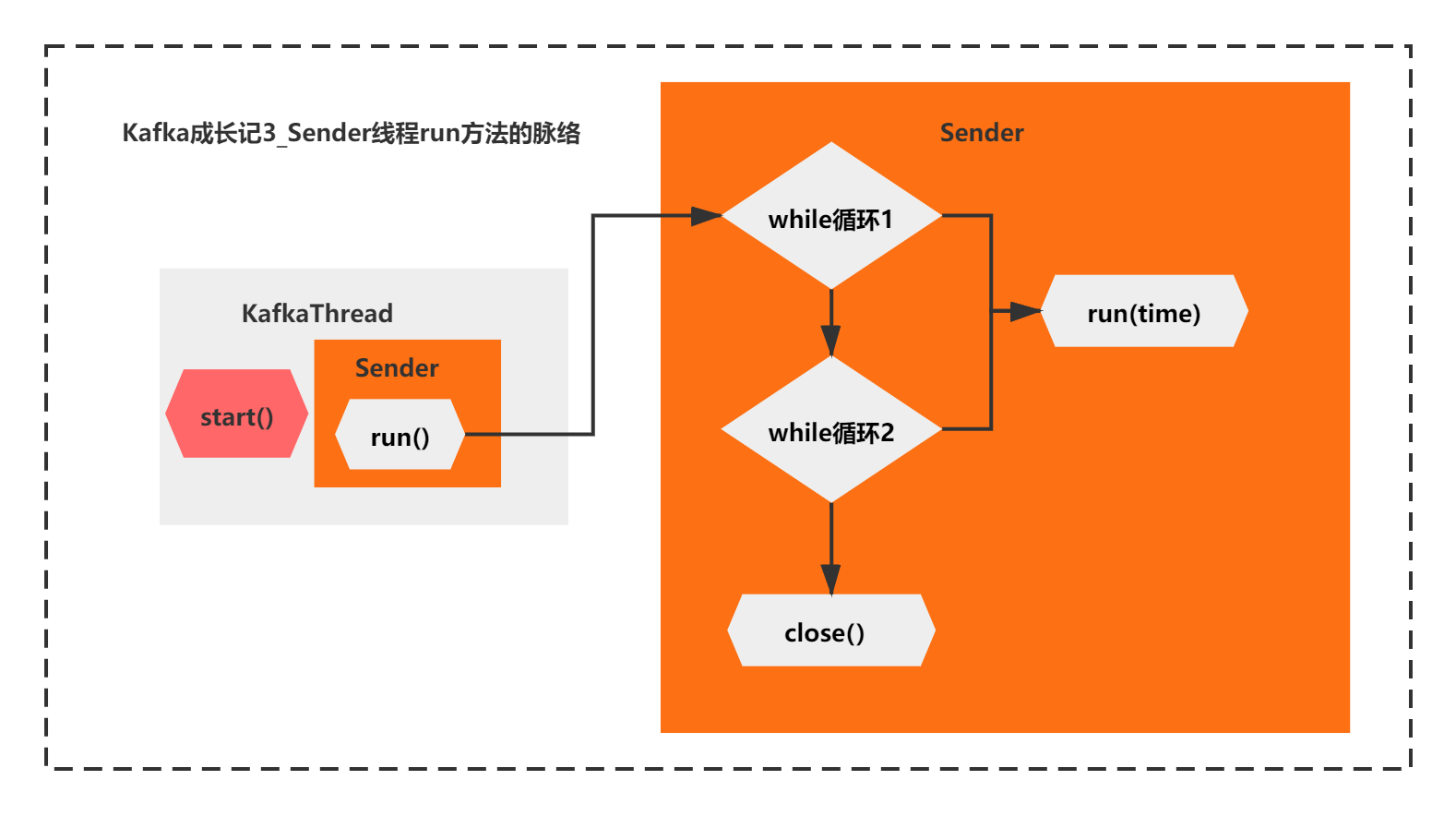
Then it's time to see what the run method is mainly doing?
/**
* Run a single iteration of sending
*
* @param now
* The current POSIX time in milliseconds
*/
void run(long now) {
Cluster cluster = metadata.fetch();
// get the list of partitions with data ready to send
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// if there are any partitions whose leaders are not known yet, force metadata update
if (result.unknownLeadersExist)
this.metadata.requestUpdate();
// remove any nodes we aren't ready to send to
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.connectionDelay(node, now));
}
}
// create produce requests
Map<Integer, List<RecordBatch>> batches = this.accumulator.drain(cluster,
result.readyNodes,
this.maxRequestSize,
now);
if (guaranteeMessageOrder) {
// Mute all the partitions drained
for (List<RecordBatch> batchList : batches.values()) {
for (RecordBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
List<RecordBatch> expiredBatches = this.accumulator.abortExpiredBatches(this.requestTimeout, now);
// update sensors
for (RecordBatch expiredBatch : expiredBatches)
this.sensors.recordErrors(expiredBatch.topicPartition.topic(), expiredBatch.recordCount);
sensors.updateProduceRequestMetrics(batches);
List<ClientRequest> requests = createProduceRequests(batches, now);
// If we have any nodes that are ready to send + have sendable data, poll with 0 timeout so this can immediately
// loop and try sending more data. Otherwise, the timeout is determined by nodes that have partitions with data
// that isn't yet sendable (e.g. lingering, backing off). Note that this specifically does not include nodes
// with sendable data that aren't ready to send since they would cause busy looping.
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
if (result.readyNodes.size() > 0) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
log.trace("Created {} produce requests: {}", requests.size(), requests);
pollTimeout = 0;
}
for (ClientRequest request : requests)
client.send(request, now);
// if some partitions are already ready to be sent, the select time would be 0;
// otherwise if some partition already has some data accumulated but not ready yet,
// the select time will be the time difference between now and its linger expiry time;
// otherwise the select time will be the time difference between now and the metadata expiry time;
this.client.poll(pollTimeout, now);
}If you look at the above code for the first time, you will feel that the context is very unclear and you don't know where the focus is. But fortunately, there are some notes. You can roughly guess what he's doing.
Calculator ready, networkclient ready, networkclient send, networkclient poll
These seem to mean preparing memory area, preparing node nodes for network connection, sending data and pulling response results.
But what if you can't guess?
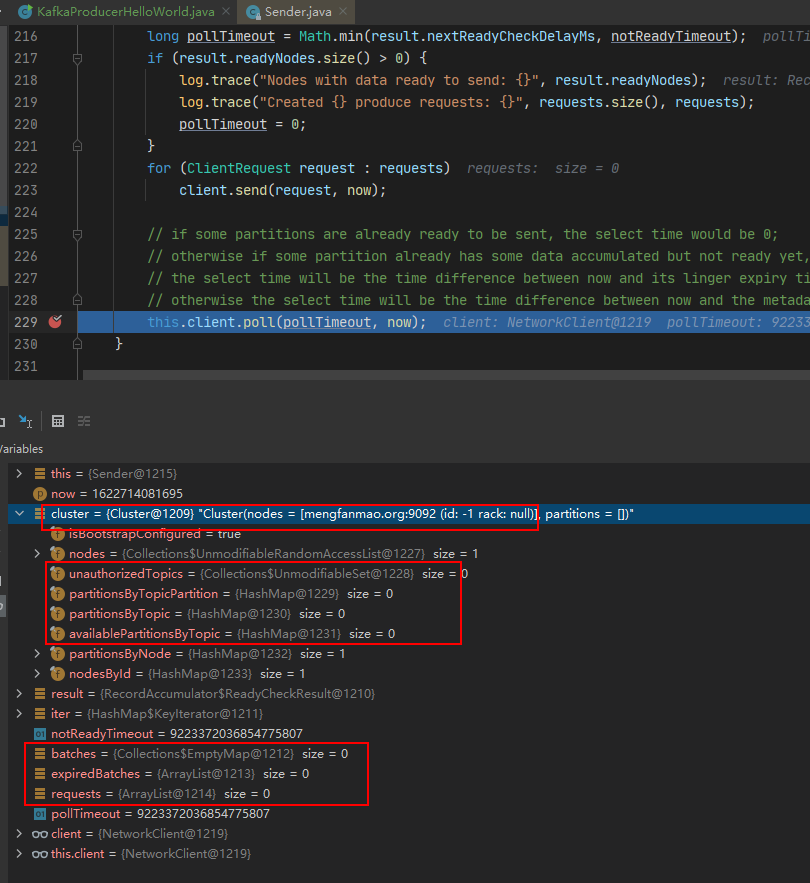
At this time, you can sacrifice the killer debug. Because it is a producer, we can take a step-by-step look at the client interruption point of Hellowolrd.
After you break the run method step by step, you will find:
Almost none of the logic of calculator ready, networkclient ready and networkclient send is executed. All of them initialize empty objects or return directly inside the method.
Directly execute the client.poll method all the way. As shown in the figure below:
Well, you can draw a conclusion that the core logic of the run method of while loop for the first time actually has only one sentence:
client.poll(pollTimeout, now)
The overall context is as follows:
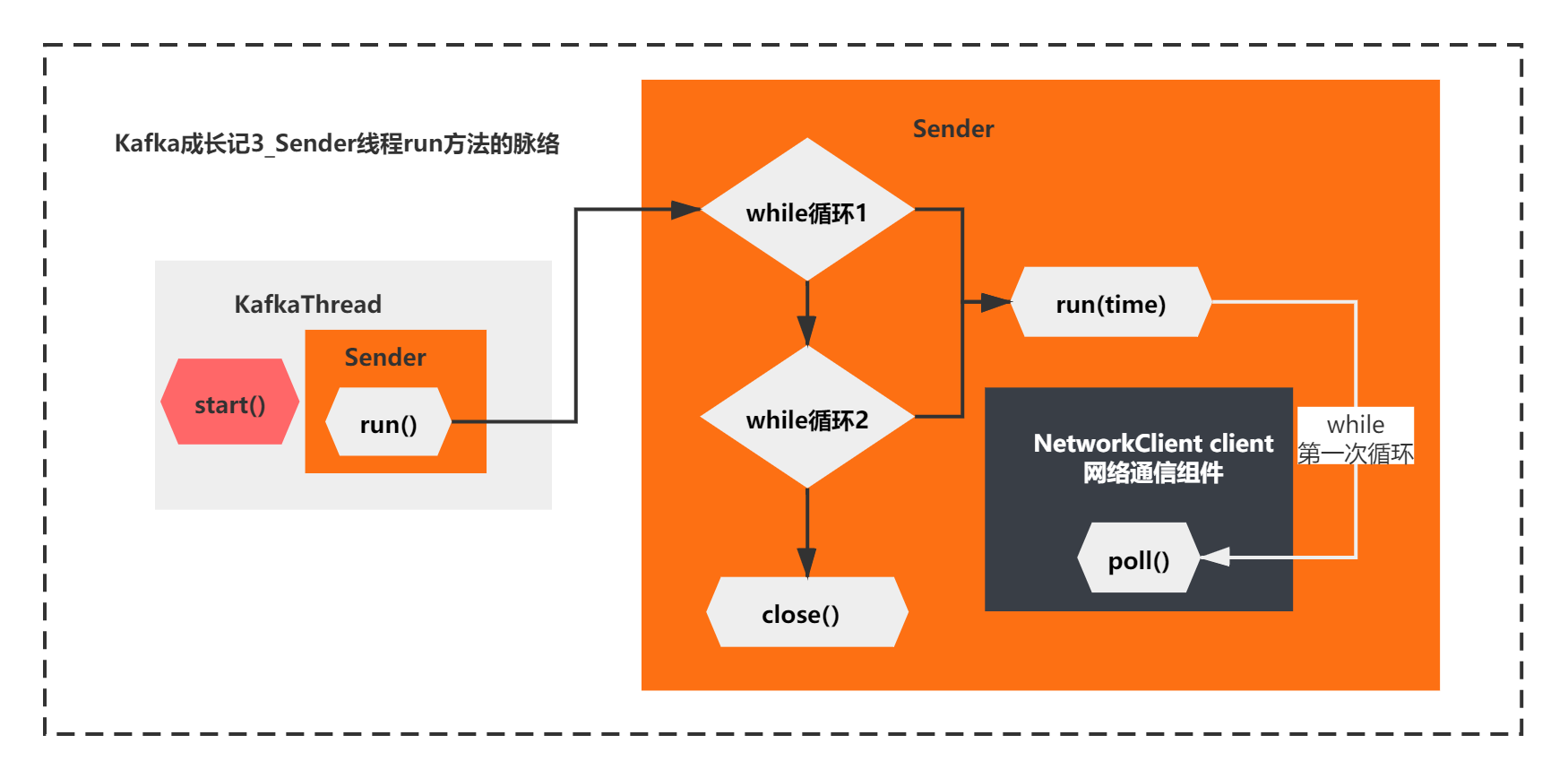
It seems that the poll method of NetworkClient is the key:
/**
* Do actual reads and writes to sockets.
* Actual reads and writes to the socket
*
* @param timeout The maximum amount of time to wait (in ms) for responses if there are none immediately,
* must be non-negative. The actual timeout will be the minimum of timeout, request timeout and
* metadata timeout
* @param now The current time in milliseconds
* @return The list of responses received
*/
@Override
public List<ClientResponse> poll(long timeout, long now) {
long metadataTimeout = metadataUpdater.maybeUpdate(now);
try {
this.selector.poll(Utils.min(timeout, metadataTimeout, requestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
// process completed actions
long updatedNow = this.time.milliseconds();
List<ClientResponse> responses = new ArrayList<>();
handleCompletedSends(responses, updatedNow);
handleCompletedReceives(responses, updatedNow);
handleDisconnections(responses, updatedNow);
handleConnections();
handleTimedOutRequests(responses, updatedNow);
// invoke callbacks
for (ClientResponse response : responses) {
if (response.request().hasCallback()) {
try {
response.request().callback().onComplete(response);
} catch (Exception e) {
log.error("Uncaught error in request completion:", e);
}
}
}
return responses;
}The context of this method is much clearer. Through the method name and comments, we can almost guess some of its functions, mainly including:
1) Note: the socket is actually read and written
2) metadataUpdater.maybeUpdate(), do you remember the component DefaultMetadataUpdater of NetworkClient? The method name means that metadata update may be performed. This seems to be crucial
3) Then the poll method of the Selector is executed. This is another component of the NetworkClient, Selector. Remember? It encapsulates the native NIO Selector at the bottom. This method should also be key.
4) Subsequently, a series of methods are executed for the response. In terms of name, handleCompletedSends handles the requests sent, handleCompletedReceives handles the requests accepted, handleDisconnections handles the requests disconnected, handleConnections handles the requests connected successfully, and handleTimedOutRequests handles the requests timed out. There are different treatments according to different situations.
5) Finally, there is a callback processing related to response. If the callback function is registered, it will be executed. This should not be a very critical logic
In other words, the NetworkClient executes the poll method, mainly through the selector to process the read and write of the request, and to process the response results differently.
As shown in the figure below:
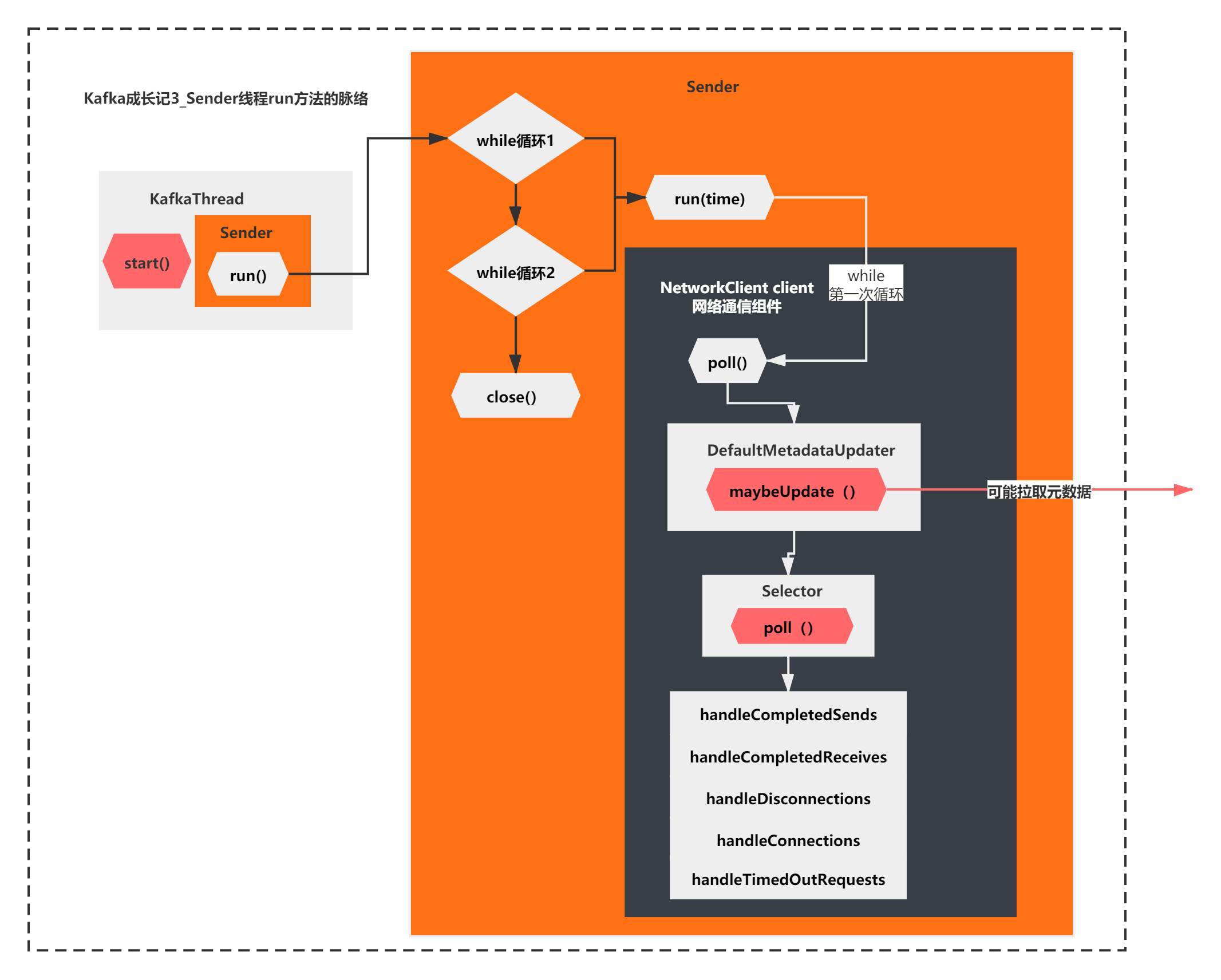
In fact, we have basically found out one thing that the run method is mainly doing. Because it is the first loop, the previous calculator ready, networkclient ready and networkclient send do nothing. For the first while loop, the core of the run method is the networkclient.poll method. The main logic of the poll method is shown in the figure above.
maybeUpdate may be pulling metadata?
We just analyzed that the poll method first executes the maybeUpdate method of DefaultMetadataUpdater, which means possible update. Let's take a look at his logic.
public long maybeUpdate(long now) {
// should we update our metadata?
long timeToNextMetadataUpdate = metadata.timeToNextUpdate(now);
long timeToNextReconnectAttempt = Math.max(this.lastNoNodeAvailableMs + metadata.refreshBackoff() - now, 0);
long waitForMetadataFetch = this.metadataFetchInProgress ? Integer.MAX_VALUE : 0;
// if there is no node available to connect, back off refreshing metadata
long metadataTimeout = Math.max(Math.max(timeToNextMetadataUpdate, timeToNextReconnectAttempt),
waitForMetadataFetch);
if (metadataTimeout == 0) {
// Beware that the behavior of this method and the computation of timeouts for poll() are
// highly dependent on the behavior of leastLoadedNode.
Node node = leastLoadedNode(now);
maybeUpdate(now, node);
}
return metadataTimeout;
}
/**
* The next time to update the cluster info is the maximum of the time the current info will expire and the time the
* current info can be updated (i.e. backoff time has elapsed); If an update has been request then the expiry time
* is now
*/
public synchronized long timeToNextUpdate(long nowMs) {
long timeToExpire = needUpdate ? 0 : Math.max(this.lastSuccessfulRefreshMs + this.metadataExpireMs - nowMs, 0);
long timeToAllowUpdate = this.lastRefreshMs + this.refreshBackoffMs - nowMs;
return Math.max(timeToExpire, timeToAllowUpdate);
}It turns out that there is a time judgment here. maybeUpdate will be executed only when the judgment is satisfied.
This time calculation seems to be complicated, but it can be seen that the metadataTimeout is determined according to the comprehensive judgment of three times. If it is 0, the real maybeUpdate() will be executed.
In this case, we can directly make a breakpoint in the metadata timeout to see how its value is calculated, such as the following figure:
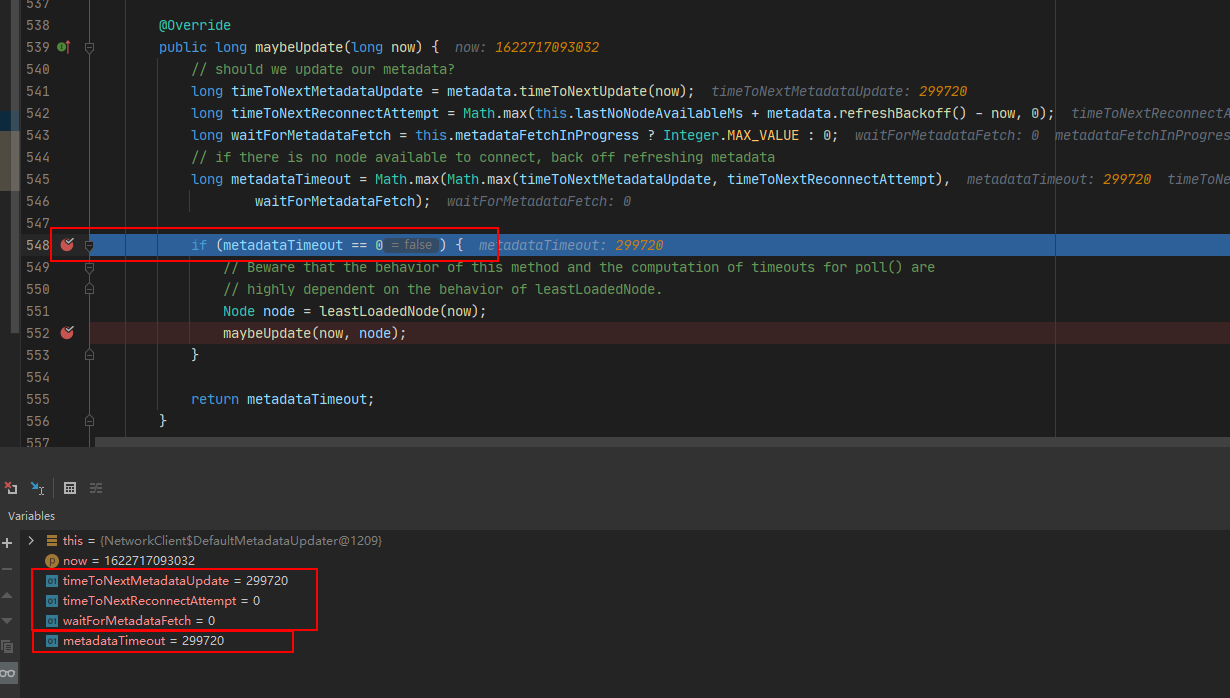
You will find that when the while loop is executed for the first time, the poll method is executed, and the maybeUpdate is executed, the three values of the metadata timeout are determined, two of which are 0, one of which is non-0, which is a value of 299720. The final result is that the metadata timeout is also non-0, 299720.
That is, the first while loop does not execute any logic of maybeUpdate.
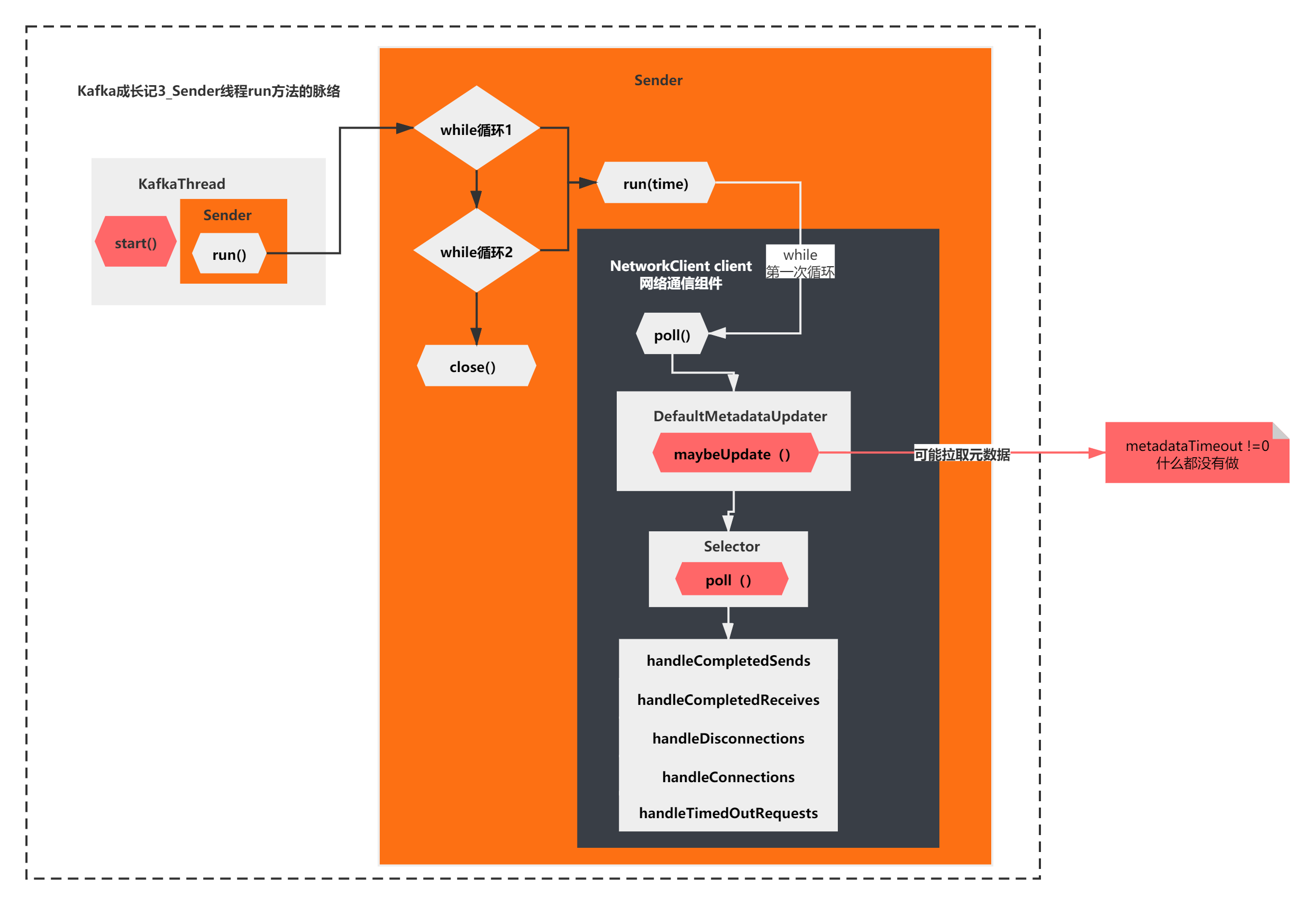
Then execute the poll() method of the Selector downward.
/**
* Do whatever I/O can be done on each connection without blocking. This includes completing connections, completing
* disconnections, initiating new sends, or making progress on in-progress sends or receives.
* Do whatever I/O you can on each connection without blocking. This includes completing a connection, disconnecting, starting a new send, or sending or receiving a request in progress
*/
@Override
public void poll(long timeout) throws IOException {
if (timeout < 0)
throw new IllegalArgumentException("timeout should be >= 0");
clear();
if (hasStagedReceives() || !immediatelyConnectedKeys.isEmpty())
timeout = 0;
/* check ready keys */
long startSelect = time.nanoseconds();
//This method is NIO underlying Selector.select(), which will block listening
int readyKeys = select(timeout);
long endSelect = time.nanoseconds();
currentTimeNanos = endSelect;
this.sensors.selectTime.record(endSelect - startSelect, time.milliseconds());
//If you listen to SelectionKeys with operations, that is, readykeys > 0 < some operations will be performed
if (readyKeys > 0 || !immediatelyConnectedKeys.isEmpty()) {
pollSelectionKeys(this.nioSelector.selectedKeys(), false);
pollSelectionKeys(immediatelyConnectedKeys, true);
}
addToCompletedReceives();
long endIo = time.nanoseconds();
this.sensors.ioTime.record(endIo - endSelect, time.milliseconds());
maybeCloseOldestConnection();
}
private int select(long ms) throws IOException {
if (ms < 0L)
throw new IllegalArgumentException("timeout should be >= 0");
if (ms == 0L)
return this.nioSelector.selectNow();
else
return this.nioSelector.select(ms);
}The above context mainly includes 2 steps:
1) select(timeout): NIO underlying selector.select() will block listening
2) pollSelectionKeys(): listens to the SelectionKeys with operations and performs some operations
In other words, in the end, the run method of the Sender thread executes the poll method in the while loop for the first time. In the end, it does nothing and will be blocked by selector.select().
As shown in the figure below:
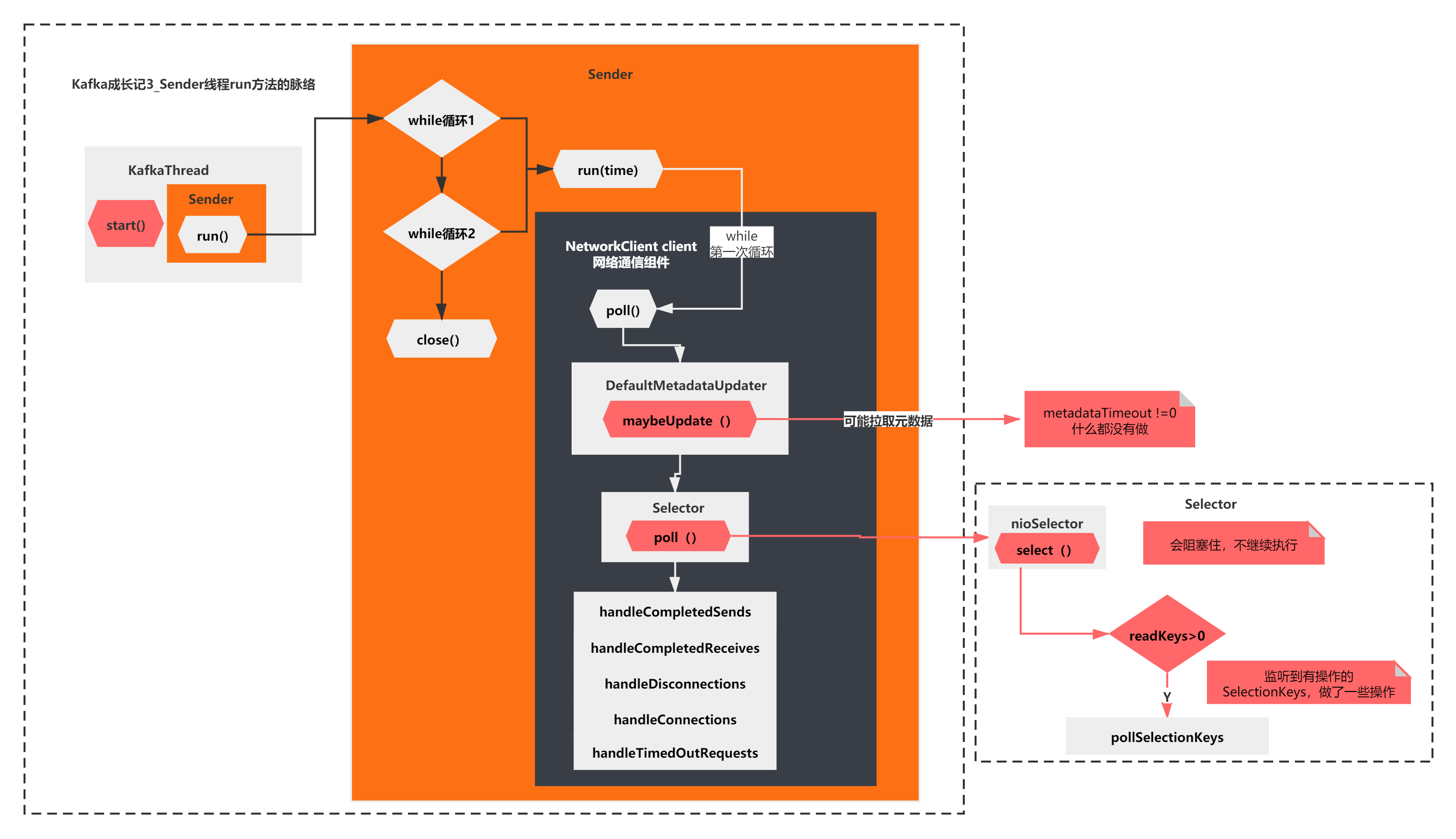
After new KafkaProducer
After analyzing the execution of the run method, the first step of new KafkaProducer() of kafkaproducerworld we analyzed is basically completed.
After a period and a half, we finally analyzed the principle of Kafka Producer. I wonder if you have a deeper understanding of Kafka's Producer.
What happens after analyzing new KafkaProducer()?
Let's continue to analyze Kafka producer HelloWorld. Do you remember the code of Kafka producer HelloWorld?
public class KafkaProducerHelloWorld {
public static void main(String[] args) throws Exception {
//Configure some parameters of Kafka
Properties props = new Properties();
props.put("bootstrap.servers", "mengfanmao.org:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Create a Producer instance
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// Encapsulate a message
ProducerRecord<String, String> record = new ProducerRecord<>(
"test-topic", "test-key", "test-value");
// Sending messages in synchronous mode will block here until the sending is completed
// producer.send(record).get();
// Send messages asynchronously without blocking. Just set a listening callback function
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null) {
System.out.println("Message sent successfully");
} else {
exception.printStackTrace();
}
}
});
Thread.sleep(5 * 1000);
// Exit producer
producer.close();
}Kafka producer HelloWorld focuses on three steps:
1) We have analyzed the new KafkaProducer, which mainly analyzes the parsing of the configuration file, what the components are and what they have, and what the first loop of the run thread just analyzed executes.
2) new ProducerRecord creates a message to be sent
3) producer.send() sends a message
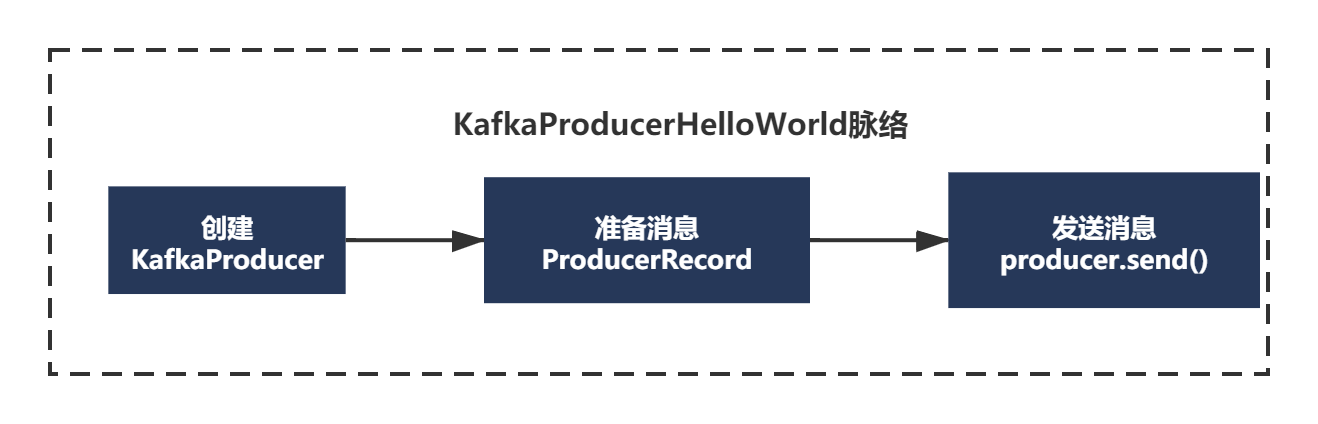
First create the message to be sent:
ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "test-key", "test-value");
public ProducerRecord(String topic, K key, V value) {
this(topic, null, null, key, value);
}
/**
* Creates a record with a specified timestamp to be sent to a specified topic and partition
* Creates a record with the specified timestamp to send to the specified subject and partition
* @param topic The topic the record will be appended to
* @param partition The partition to which the record should be sent
* @param timestamp The timestamp of the record
* @param key The key that will be included in the record
* @param value The record contents
*/
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) {
if (topic == null)
throw new IllegalArgumentException("Topic cannot be null");
if (timestamp != null && timestamp < 0)
throw new IllegalArgumentException("Invalid timestamp " + timestamp);
this.topic = topic;
this.partition = partition;
this.key = key;
this.value = value;
this.timestamp = timestamp;
}As we mentioned earlier, Record represents the abstract encapsulation of a message. The producer Record actually represents a message.
It can be seen from the comments of the constructor that the producer record can specify which topic and partition to go to, and the message can be set with a timestamp. Partition and timestamp can not be specified by default
In fact, looking at this source code, the main information we get is this. These are relatively simple. Don't draw.
Metadata pull trigger when sending message
After the Producer and Record are created, messages can be sent synchronously or asynchronously.
// Sending messages in synchronous mode will block here until the sending is completed
// producer.send(record).get();
// Send messages asynchronously without blocking. Just set a listening callback function
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null) {
System.out.println("Message sent successfully");
} else {
exception.printStackTrace();
}
}
});
//Synchronous transmission
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return send(record, null);
}
//Asynchronous transmission
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors == null ? record : this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
The whole sending logic of synchronization and asynchrony is shown in the figure below:
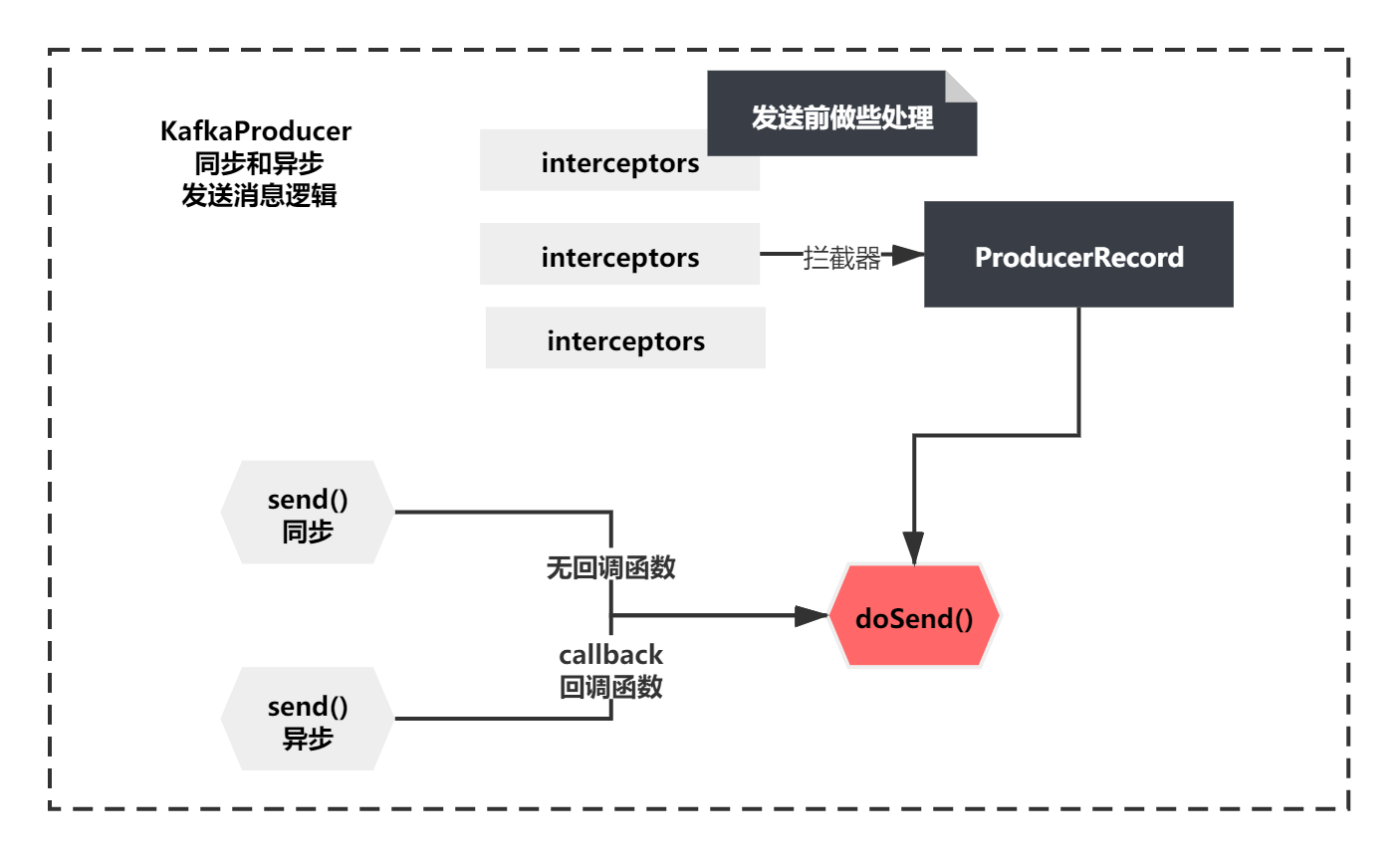
As you can see from the above figure, the same method doSend() will be called at the bottom of both synchronous sending and asynchronous sending. The difference is whether there is a callBack callback function. They also register some interceptors before calling. Here, we focus on the doSend method.
The doSend method is as follows:
/**
* Implementation of asynchronously send a record to a topic. Equivalent to <code>send(record, null)</code>.
* See {@link #send(ProducerRecord, Callback)} for details.
*/
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
// first make sure the metadata for the topic is available
long waitedOnMetadataMs = waitOnMetadata(record.topic(), this.maxBlockTimeMs);
long remainingWaitMs = Math.max(0, this.maxBlockTimeMs - waitedOnMetadataMs);
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer");
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer");
}
int partition = partition(record, serializedKey, serializedValue, metadata.fetch());
int serializedSize = Records.LOG_OVERHEAD + Record.recordSize(serializedKey, serializedValue);
ensureValidRecordSize(serializedSize);
tp = new TopicPartition(record.topic(), partition);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
// producer callback will make sure to call both 'callback' and interceptor callback
Callback interceptCallback = this.interceptors == null ? callback : new InterceptorCallback<>(callback, this.interceptors, tp);
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null)
callback.onCompletion(null, e);
this.errors.record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
throw new InterruptException(e);
} catch (BufferExhaustedException e) {
this.errors.record();
this.metrics.sensor("buffer-exhausted-records").record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (KafkaException e) {
this.errors.record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (Exception e) {
// we notify interceptor about all exceptions, since onSend is called before anything else in this method
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
throw e;
}
}Although the context of this method is relatively long, the context is still relatively clear. It is mainly implemented first:
1) waitOnMetadata should be waiting for metadata pull
2) keySerializer.serialize and valueSerializer.serialize are obviously to serialize records into byte byte arrays
3) Route partition through partition, and select a partition under Topic according to a certain routing policy
4) accumulator.append puts the message into the buffer
5) Wake up the blocking of selector.select() of the Sender thread and start processing the data in the memory buffer.
It is shown as follows:
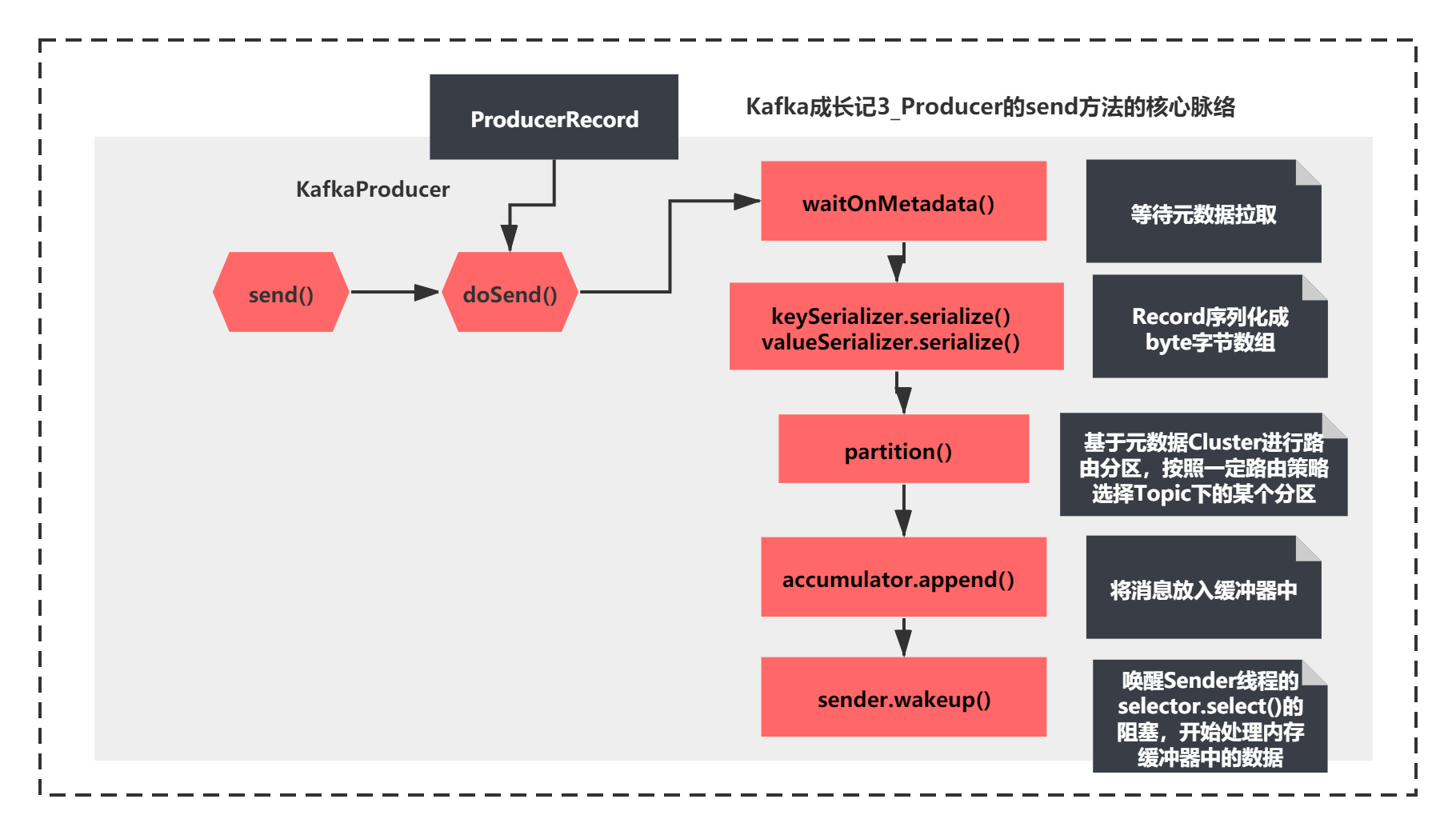
In these two sections, we focus on the source code principle of the scenario of metadata pull.
So here we will focus on step 1 and the next four steps we will analyze later.
How does waitOnMetadata wait for metadata pull?
Since the first step of send is to execute the waitOnMetadata method, first look at its code:
/**
* Wait for cluster metadata including partitions for the given topic to be available.
* @param topic The topic we want metadata for
* @param maxWaitMs The maximum time in ms for waiting on the metadata
* @return The amount of time we waited in ms
*/
private long waitOnMetadata(String topic, long maxWaitMs) throws InterruptedException {
// add topic to metadata topic list if it is not there already.
if (!this.metadata.containsTopic(topic))
this.metadata.add(topic);
if (metadata.fetch().partitionsForTopic(topic) != null)
return 0;
long begin = time.milliseconds();
long remainingWaitMs = maxWaitMs;
while (metadata.fetch().partitionsForTopic(topic) == null) {
log.trace("Requesting metadata update for topic {}.", topic);
int version = metadata.requestUpdate();
sender.wakeup();
metadata.awaitUpdate(version, remainingWaitMs);
long elapsed = time.milliseconds() - begin;
if (elapsed >= maxWaitMs)
throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms.");
if (metadata.fetch().unauthorizedTopics().contains(topic))
throw new TopicAuthorizationException(topic);
remainingWaitMs = maxWaitMs - elapsed;
}
return time.milliseconds() - begin;
}
/**
* Get the current cluster info without blocking
*/
public synchronized Cluster fetch() {
return this.cluster;
}
public synchronized int requestUpdate() {
this.needUpdate = true;
return this.version;
}
/**
* Wait for metadata update until the current version is larger than the last version we know of
*/
public synchronized void awaitUpdate(final int lastVersion, final long maxWaitMs) throws InterruptedException {
if (maxWaitMs < 0) {
throw new IllegalArgumentException("Max time to wait for metadata updates should not be < 0 milli seconds");
}
long begin = System.currentTimeMillis();
long remainingWaitMs = maxWaitMs;
while (this.version <= lastVersion) {
if (remainingWaitMs != 0)
wait(remainingWaitMs);
long elapsed = System.currentTimeMillis() - begin;
if (elapsed >= maxWaitMs)
throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms.");
remainingWaitMs = maxWaitMs - elapsed;
}
}The core of this method is to judge whether there is Cluster metadata information. If not, the following operations are carried out:
1)metadata.requestUpdate(); A needUpdate tag is updated. This value will affect the calculation of the previous maybeUpdate metadata timeout. You can make the metadata timeout 0
2)sender.wakeup(); Wake up the blocking of nioSelector.select() before and continue execution
3)metadata.awaitUpdate(version, remainingWaitMs); It mainly compares the versions. If it is not the latest version, it calls the Metadata.wait() method (the wait method is a method that every Object will have, which is generally used in combination with notify or notifyAll)
I'll show you the whole process directly in a diagram, as follows:
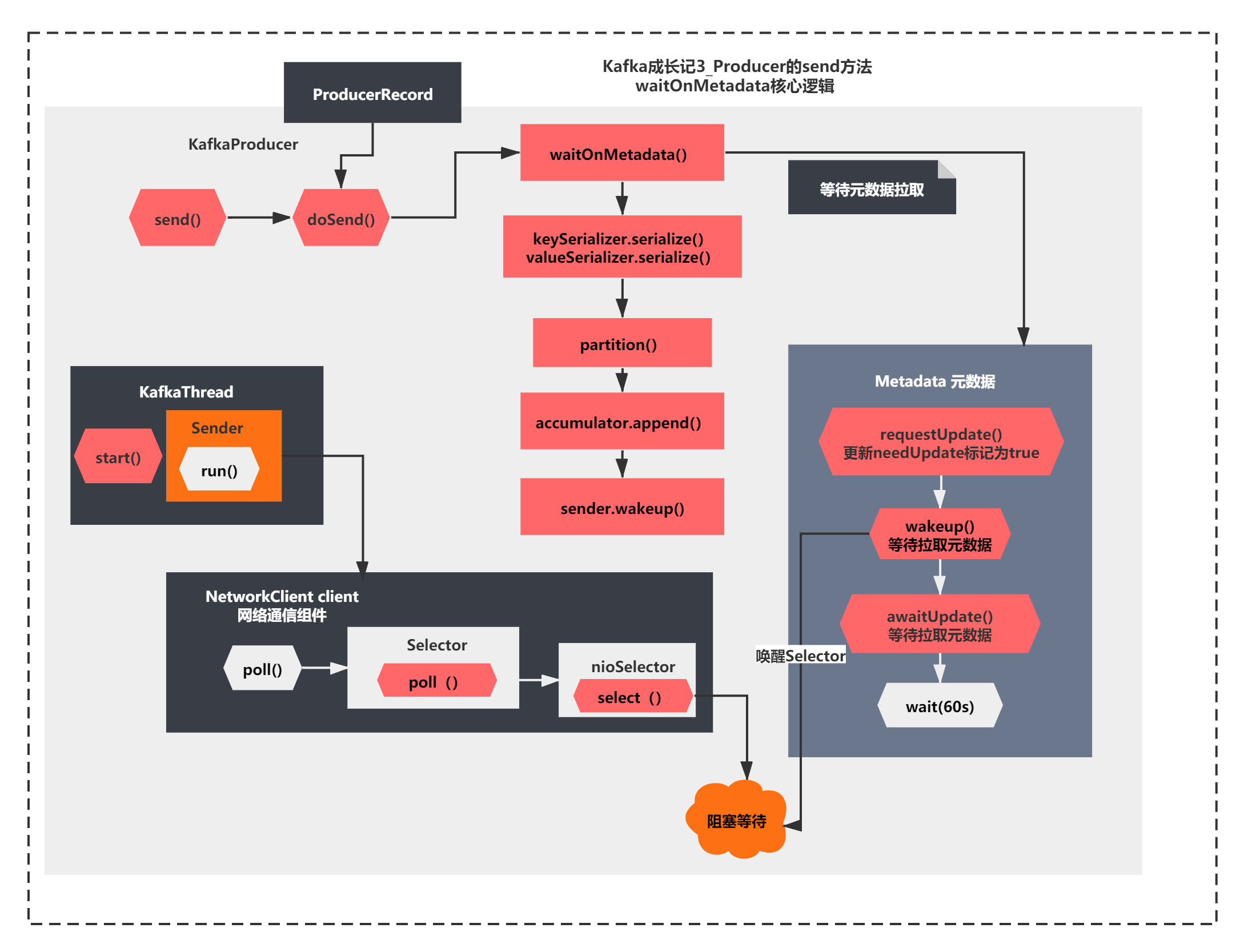
The whole figure is the key result of our analysis today. There are two blocking and wake-up mechanisms, one is the select() and wakeUp() of the Selector in NIO, and the other is the wait() and notifyAll() mechanisms of the MetaData object. Therefore, this should be understood in combination with the previous blocking logic of the Sender thread.
Isn't it interesting to use the join, sleep, wait, park, unpark and notify methods of any thread.
Summary
Finally, let's make a brief summary. In this section, we mainly analyze the source code principle of the following Producer:
When initializing KafkaProducer, the metadata is not pulled, but the Selector component is created, the Sender thread is started, and the select block waits for the request response. Since no request has been sent, metadata is not really pulled during initialization.
When the send method is called for the first time, it will wake up the select() blocked before waking up the Selector and enter the second while loop to send the metadata pull request. It will wait for 60s through the Obejct.wait mechanism. After the metadata pull from the Broker is successful, it will continue to execute the request for the real production message. Otherwise, it will report a metadata pull timeout exception.
In this section, we just saw how to wait for metadata pull after waiting.
After waking up the select of the Selector, it should enter the second while loop
How does the second while loop send a request to pull metadata and notify all() wakes up after success?
Let's continue our analysis in the next section. Please look forward to it! I'll see you next time!
This article is composed of blog one article multi posting platform OpenWrite release!