
The growth notes will not introduce too much basic knowledge of Kafka. If necessary, there will be a special "Xiaobai starting camp" later. The default of growth notes is that we are familiar with some concepts of Kafka, and the default will be the basic deployment of Kafka. Of course, in order to take care of some Xiaobai, I will briefly introduce and explain the knowledge involved for the first time. Those familiar with it should be reviewed. Doing simple things over and over again is sometimes a good thing.
Kafka's growth story will be explored directly from three aspects: Producer, Broker and consumer. In the process, according to the scenario, the previous ZK and JDK growth notes will be used to introduce the source code analysis method. Without much to say, let's start the first section directly!
We studied ZK mainly by using the scenario method and found some core entries to start analysis. When studying the source code of Kafka, we can also refer to the previous method. However, this time we will not start with the Broker server node directly, but start with Producer. Will use some new ideas and methods to analyze the source code.
To analyze the source code principle of Kafka Producer, there must be an entrance or place to start. Many people use Kafka from a Demo. Deploy a Kafka by yourself, then send a message, and then consume a message by yourself.
KafkaProducerHelloWorld
So let's start with the simplest Demo of Kafka Producer and explore the principle of Kafka source code from an example of Kafka Producer HelloWorld.
The code of HelloWorld is as follows:
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
/**
* @author fanmao
*/
public class KafkaProducerHelloWorld {
public static void main(String[] args) throws Exception {
//Configure some parameters of Kafka
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.30.1:9092");
// Create a Producer instance
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// Encapsulate a message
ProducerRecord<String, String> record = new ProducerRecord<>(
"test-topic", "test-key", "test-value");
// Sending messages in synchronous mode will block here until the sending is completed
// producer.send(record).get();
// Send messages asynchronously without blocking. Just set a listening callback function
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null) {
System.out.println("Message sent successfully");
} else {
System.out.println("Message sending exception");
}
}
});
Thread.sleep(5 * 1000);
// Exit producer
producer.close();
}
}
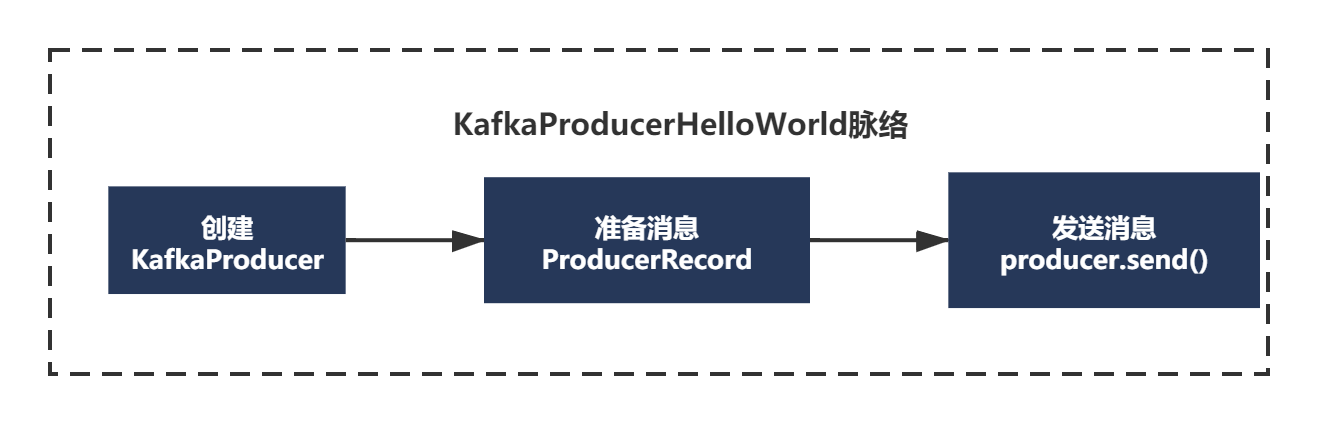
The above code example, although very simple, also has its own context.
1) Create KafkaProducer
2) Prepare message ProducerRecord
3) Send message producer.send()
Simply draw a picture:
Let's say more here. I mentioned the selection of source code version and the way to look at the source code in Zookeeper growth 5. I won't repeat it here. I will tell you the result directly. I chose kafka-0.10.0.1.
Therefore, the dependent GAV (group artifactid version) used by the client is org.apache.kafka-kafka-clients-0.10.0.1. POM is as follows:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.mfm.learn</groupId>
<artifactId>learn-kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>learn-kafka</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.0.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.72</version>
</dependency>
</dependencies>
<build>
</build>
</project>
Creation of KafkaProducer
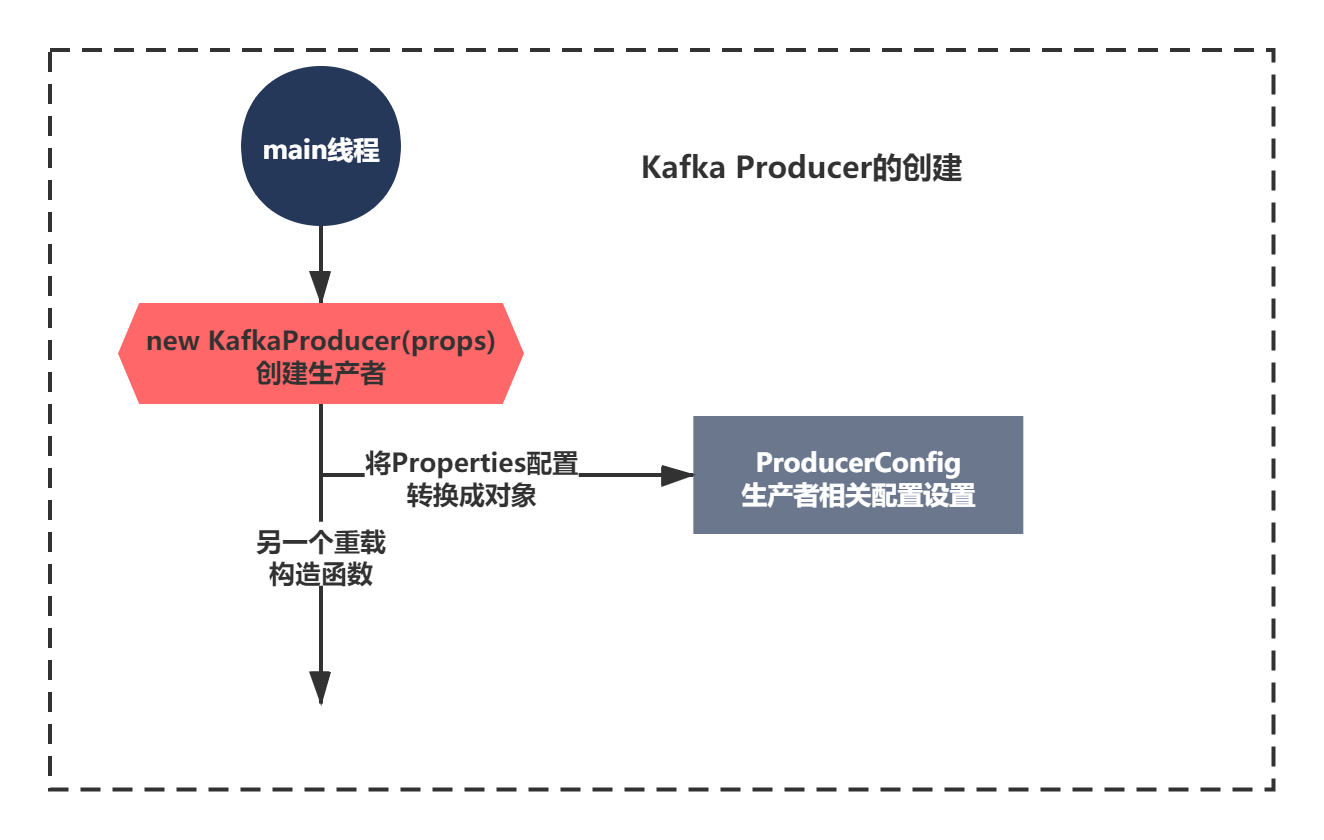
Since the above KafkaProducerHelloWorld context is mainly divided into three steps, let's look at it step by step. The first is the creation of KafkaProducer. Let's see what it initializes?
Here's a question for you. The source code principle of this construction method. What method will be better for the results of general analysis?
Yes, component diagram or source code context diagram analysis is the easiest to understand. We just need to have a general impression. With the method, what ideas will you use in general? Lian mengdai guesses, looks at the comments, and guesses the role of the component, isn't it?
All right, let's try!
The code of new KafkaProducer is as follows:
/**
* A producer is instantiated by providing a set of key-value pairs as configuration. Valid configuration strings
* are documented <a href="http://kafka.apache.org/documentation.html#producerconfigs">here</a>.
* @param properties The producer configs
*/
public KafkaProducer(Properties properties) {
this(new ProducerConfig(properties), null, null);
}The constructor calls a constructor which is overloaded. Let's look at the annotation first. Generally speaking, the parameters of this constructor can be set through Properties. Later, it must be that this parameter is converted into a ProducerConfig object for encapsulation, and there must be a certain conversion method. Do you remember that there is a similar operation in Zookeeper's growth story, which encapsulates a QuorumPeerConfig object. In fact, if you analyze a lot of source code, you will gradually have experience and be better able to analyze any source code principle with ease. This is what I want you to learn, not how to parse and encapsulate it into configuration objects.
Let's continue the analysis. Then there are two ways to see how the overloaded construction method or ProducerConfig is parsed. As follows:
How is the configuration of Kafka Producer resolved?
In this section, let's take a look at how ProducerConfig parses the configuration file. The code of new ProducerConfig() is as follows:
/*
* NOTE: DO NOT CHANGE EITHER CONFIG STRINGS OR THEIR JAVA VARIABLE NAMES AS THESE ARE PART OF THE PUBLIC API AND
* CHANGE WILL BREAK USER CODE.
* Note: do not change any configuration strings or their JAVA variable names, as they are part of the public API, and changing them will destroy user code.
*/
private static final ConfigDef CONFIG;
ProducerConfig(Map<?, ?> props) {
super(CONFIG, props);
}The context of this constructor calls a super and has a parent class. It seems more encapsulated than Zookeeper's configuration resolution, not a simple QuorumPeerConfig.
And there is a static variable ConfigDef CONFIG. You must want to know what it is.
We can take a look at the source code context of the ConfigDef class to see if we can see anything:

It seems that there are a lot of define methods and validate methods. Several key variables, such as a Map configKeys. It seems that it is configured with key value
For example, key = bootstrap.servers, value192.168.30.: 9092.
I really can't guess. We can take another look at the comments of the ConfigDef class.
/**
/**
* This class is used for specifying the set of expected configurations. For each configuration, you can specify
* the name, the type, the default value, the documentation, the group information, the order in the group,
* the width of the configuration value and the name suitable for display in the UI.
* This class is used to specify the desired configuration set. For each configuration, you can specify name, type, default value, document, group information, order in group, width of configuration value and name suitable for display in UI.
*
* You can provide special validation logic used for single configuration validation by overriding {@link Validator}.
* You can provide special validation logic for individual configuration validation by overriding {@ link Validator}.
*
* Moreover, you can specify the dependents of a configuration. The valid values and visibility of a configuration
* may change according to the values of other configurations. You can override {@link Recommender} to get valid
* values and set visibility of a configuration given the current configuration values.
* In addition, you can specify the dependents of the configuration. The valid values and visibility of the configuration may change depending on the values of other configurations. You can override {@ link Recommender} to get valid values,
* And set the visibility of the configuration given the current configuration value.
* Omit other
* This class can be used standalone or in combination with {@link AbstractConfig} which provides some additional
* functionality for accessing configs.
* This class can be used alone or in combination with {@ link AbstractConfig} to provide some additional functions to access the configured functions.
*/
Through the above words, you should not be difficult to see its function. In short, it encapsulates the key value configuration. You can set and verify the key value, which can be used alone to access the configuration
After you know the function of this static variable, click the super of ProducerConfig to enter the constructor of the parent class:
public AbstractConfig(ConfigDef definition, Map<?, ?> originals, boolean doLog) {
/* check that all the keys are really strings */
for (Object key : originals.keySet())
if (!(key instanceof String))
throw new ConfigException(key.toString(), originals.get(key), "Key must be a string.");
this.originals = (Map<String, ?>) originals;
this.values = definition.parse(this.originals);
this.used = Collections.synchronizedSet(new HashSet<String>());
if (doLog)
logAll();
}The core context of the above code is just one sentence: definition. Parse (this. Origins); That is, the parrse method of ConfigDef is executed.
Here, you don't have to think about it. This method is to convert Properties to ProducerConfig configuration. As shown in the figure below:

Next, let's take a brief look at the parse method. The code is as follows:
private final Map<String, ConfigKey> configKeys = new HashMap<>();
public Map<String, Object> parse(Map<?, ?> props) {
// Check all configurations are defined
List<String> undefinedConfigKeys = undefinedDependentConfigs();
if (!undefinedConfigKeys.isEmpty()) {
String joined = Utils.join(undefinedConfigKeys, ",");
throw new ConfigException("Some configurations in are referred in the dependents, but not defined: " + joined);
}
// parse all known keys
Map<String, Object> values = new HashMap<>();
for (ConfigKey key : configKeys.values()) {
Object value;
// props map contains setting - assign ConfigKey value
if (props.containsKey(key.name)) {
value = parseType(key.name, props.get(key.name), key.type);
// props map doesn't contain setting, the key is required because no default value specified - its an error
} else if (key.defaultValue == NO_DEFAULT_VALUE) {
throw new ConfigException("Missing required configuration \"" + key.name + "\" which has no default value.");
} else {
// otherwise assign setting its default value
value = key.defaultValue;
}
if (key.validator != null) {
key.validator.ensureValid(key.name, value);
}
values.put(key.name, value);
}
return values;
}
This code looks a little confused directly. It doesn't matter. It's still the core context.
The core context is a for loop, which mainly traverses the map < string, configkey > configkey. The core logic is as follows:
1) First, confirm the type of value through parseType, and then according to the configuration name defined by ConfigKey, that is, key
2) Finally, the prepared key value configuration is put into map < string, Object > values and returned to AbstractConfig
Here we know that the Producer parameters we configured will be put into a map < string, Object > of AbstractConfig, and the object indicates that the configured value is distinguished from integers and strings. such as
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.30.:9092");As shown in the figure below:

In fact, it is the whole process of parsing Properties. You'll find that it's not much complicated, just a little more complicated than Zookeeper packaging.
However, if you are careful, there is a problem here. When did the map < string, configkey > configkey of the for loop of the above parse method initialize?
We can go back and have a look.
private static final ConfigDef CONFIG;
ProducerConfig(Map<?, ?> props) {
super(CONFIG, props);
}Remember that this ConfigDef is passed from the child class to the parent class before calling the parent class method. This variable is static again. To initialize, there must be a static initialization code in ProducerConfig. You can find the following code:
/** <code>retries</code> */
public static final String RETRIES_CONFIG = "retries";
private static final String RETRIES_DOC = "Setting a value greater than zero will cause the client to resend any record whose send fails with a potentially transient error."
+ " Note that this retry is no different than if the client resent the record upon receiving the error."
+ " Allowing retries without setting <code>" + MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION + "</code> to 1 will potentially change the"
+ " ordering of records because if two batches are sent to a single partition, and the first fails and is retried but the second"
+ " succeeds, then the records in the second batch may appear first.";
static {
CONFIG = new ConfigDef()
.define(BOOTSTRAP_SERVERS_CONFIG, Type.LIST, Importance.HIGH, CommonClientConfigs.BOOSTRAP_SERVERS_DOC)
.define(BUFFER_MEMORY_CONFIG, Type.LONG, 32 * 1024 * 1024L, atLeast(0L), Importance.HIGH, BUFFER_MEMORY_DOC)
.define(RETRIES_CONFIG, Type.INT, 0, between(0, Integer.MAX_VALUE), Importance.HIGH, RETRIES_DOC)
.define(ACKS_CONFIG,
Type.STRING,
"1",
in("all", "-1", "0", "1"),
Importance.HIGH,
ACKS_DOC)
.define(COMPRESSION_TYPE_CONFIG, Type.STRING, "none", Importance.HIGH, COMPRESSION_TYPE_DOC)
.define(BATCH_SIZE_CONFIG, Type.INT, 16384, atLeast(0), Importance.MEDIUM, BATCH_SIZE_DOC)
.define(TIMEOUT_CONFIG, Type.INT, 30 * 1000, atLeast(0), Importance.MEDIUM, TIMEOUT_DOC)
.define(LINGER_MS_CONFIG, Type.LONG, 0, atLeast(0L), Importance.MEDIUM, LINGER_MS_DOC)
.define(CLIENT_ID_CONFIG, Type.STRING, "", Importance.MEDIUM, CommonClientConfigs.CLIENT_ID_DOC)
.define(SEND_BUFFER_CONFIG, Type.INT, 128 * 1024, atLeast(0), Importance.MEDIUM,
// Omit other definitions
.withClientSslSupport()
.withClientSaslSupport();
}The of this static method is actually to call the define method to initialize each configuration name, default value and documentation of Producer. Finally, it is encapsulated into a map, value is ConfigKey, and ConfigDef is initialized.
private final Map<String, ConfigKey> configKeys = new HashMap<>();
public static class ConfigKey {
public final String name;
public final Type type;
public final String documentation;
public final Object defaultValue;
public final Validator validator;
public final Importance importance;
public final String group;
public final int orderInGroup;
public final Width width;
public final String displayName;
public final List<String> dependents;
public final Recommender recommender;
}This process is nothing, but the point is, the default value. That is to say, the default values of KafkaProducer configuration are initialized here. If you want to know the default value of Producer, you can see here.
These parameters are introduced in detail before the official account of the Kafka introductory series. I can't remember you here. Later, when we analyze the source code, you are slowly understanding it. Below, I have excerpted some core configurations for you to recall:
Producer core parameters:
metadata.max.age.ms metadata is refreshed every 5 minutes by default
max.request.size maximum size of each request (1mb)
Memory size of buffer.memory buffer (32mb)
max.block.ms maximum blocking time after buffer is filled or metadata is pulled (60s)
request.timeout.ms request timeout (30s)
batch.size the default size of each batch (16kb)
Linker.ms defaults to 0 and does not delay sending.
It can be configured as 10ms. If a batch has not been sent in 10ms, it must be sent immediately
......
Summary
Well, let's stop here today. In the next section, we will continue to analyze the creation of Producer and see what the overloaded constructor does after configuration resolution through component diagram and flow chart?
This article is composed of blog one article multi posting platform OpenWrite release!