From: month https://www.lixueduan.com
Original text: https://www.lixueduan.com/post/kafka/06-sarama-producer/
This paper mainly analyzes the implementation principle of Kafka Go sarama client producer through the source code, including the specific steps of message distribution process, message packaging processing, and finally sending to Kafka. Finally, it summarizes the common performance optimization methods through analysis.
This paper is based on sarama v1.29.1
1. General
See for Kafka series related codes Github
The specific process is as follows:
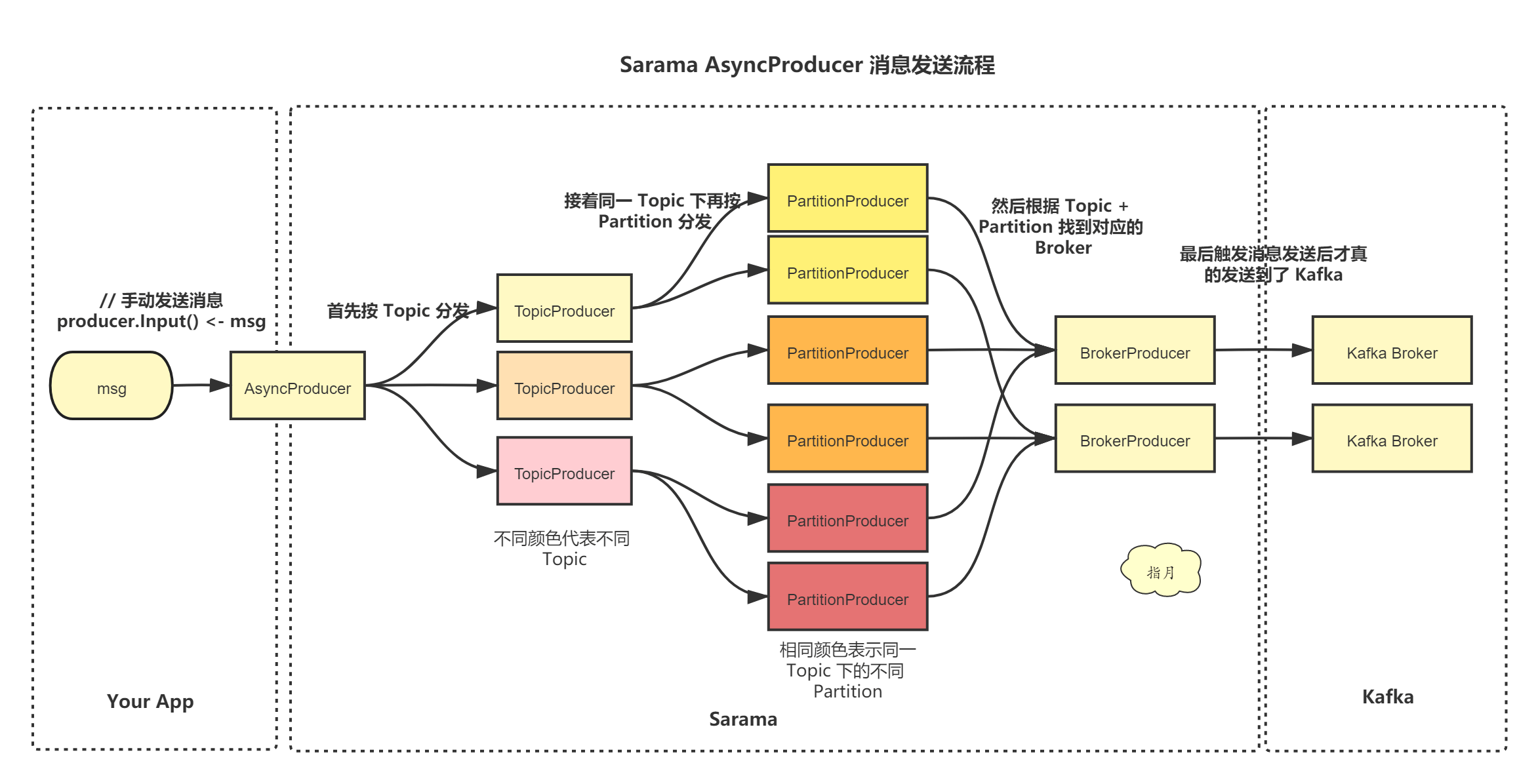
Sarama has two types of producers, synchronous producers and asynchronous producers.
To produce messages, use either the AsyncProducer or the SyncProducer. The AsyncProducer accepts messages on a channel and produces them asynchronously in the background as efficiently as possible; it is preferred in most cases. The SyncProducer provides a method which will block until Kafka acknowledges the message as produced. This can be useful but comes with two caveats: it will generally be less efficient, and the actual durability guarantees depend on the configured value of Producer.RequiredAcks. There are configurations where a message acknowledged by the SyncProducer can still sometimes be lost.
It roughly means that asynchronous producers use channel to receive messages (production success or failure) and also send messages through channel. This is usually the highest performance. The synchronization producer needs to block until acks are received. But this also brings two problems. One is that the performance becomes worse, but the reliability depends on the parameter acks.
The asynchronous producer Demo is as follows:
func Producer(topic string, limit int) {
config := sarama.NewConfig()
// Asynchronous producers do not recommend enabling both Errors and Successes. Generally, it is OK to enable Errors
// Synchronization producers must all be enabled, because the synchronization will return the success or failure of sending
config.Producer.Return.Errors = false // Setting the error message to be returned
config.Producer.Return.Successes = true // Setting needs to return success information
producer, err := sarama.NewAsyncProducer([]string{kafka.HOST}, config)
if err != nil {
log.Fatal("NewSyncProducer err:", err)
}
defer producer.AsyncClose()
go func() {
// [! important] after sending, the asynchronous producer must read the return value from Errors or Successes. Otherwise, the internal processing logic of sarama will be blocked and only one message can be sent
select {
case _ = <-producer.Successes():
case e := <-producer.Errors():
if e != nil {
log.Printf("[Producer] err:%v msg:%+v \n", e.Msg, e.Err)
}
}
}()
// Asynchronous transmission
for i := 0; i < limit; i++ {
str := strconv.Itoa(int(time.Now().UnixNano()))
msg := &sarama.ProducerMessage{Topic: topic, Key: nil, Value: sarama.StringEncoder(str)}
// Asynchronous sending only returns after writing to memory, but it is not really sent out
// The sarama library uses a channel to receive messages. The background goroutine asynchronously takes messages from the channel and sends them
producer.Input() <- msg
atomic.AddInt64(&count, 1)
if atomic.LoadInt64(&count)%1000 == 0 {
log.Printf("Number of messages sent:%v\n", count)
}
}
log.Printf("Total messages sent after sending:%v\n", limit)
}
You can see that the whole API is still very simple to use:
- 1) NewAsyncProducer(): create a producer object
- 2) Producer. Input() < - MSG: send message
- 3) S = < - producer. Successes(), e: = < - producer. Errors(): obtain success or failure information asynchronously
2. Source code analysis of sending process
For ease of reading, some irrelevant code is omitted.
In addition, because the logic of synchronous producer and asynchronous producer is consistent, only one layer is encapsulated on the basis of asynchronous producer, so this paper mainly analyzes asynchronous producer.
// We can see that the synchronous producer actually encapsulates the asynchronous producer
type syncProducer struct {
producer *asyncProducer
wg sync.WaitGroup
}
NewAsyncProducer
The first is to build an asynchronous producer object
func NewAsyncProducer(addrs []string, conf *Config) (AsyncProducer, error) {
client, err := NewClient(addrs, conf)
if err != nil {
return nil, err
}
return newAsyncProducer(client)
}
func newAsyncProducer(client Client) (AsyncProducer, error) {
// ...
p := &asyncProducer{
client: client,
conf: client.Config(),
errors: make(chan *ProducerError),
input: make(chan *ProducerMessage),
successes: make(chan *ProducerMessage),
retries: make(chan *ProducerMessage),
brokers: make(map[*Broker]*brokerProducer),
brokerRefs: make(map[*brokerProducer]int),
txnmgr: txnmgr,
}
go withRecover(p.dispatcher)
go withRecover(p.retryHandler)
}
You can see that two goroutine s are opened at the end of newAsyncProducer, one is dispatcher and the other is retryHandler.
retryHandler is mainly used to handle retry logic, which is ignored for the time being.
dispatcher
Mainly distribute messages to corresponding channel s according to topic.
func (p *asyncProducer) dispatcher() {
handlers := make(map[string]chan<- *ProducerMessage)
// ...
for msg := range p.input {
// Interceptor logic
for _, interceptor := range p.conf.Producer.Interceptors {
msg.safelyApplyInterceptor(interceptor)
}
// Find the Handler corresponding to this Topic
handler := handlers[msg.Topic]
if handler == nil {
// If there is no Handler corresponding to this Topic, create one
handler = p.newTopicProducer(msg.Topic)
handlers[msg.Topic] = handler
}
// Then write the message into the Handler
handler <- msg
}
}
Specific logic: take out the message from p.input and write it to the handler. If the handler corresponding to topic does not exist, call newTopicProducer() to create it.
The handler here is an unbuffered channel
Then let's look at the line handler = p.newtopic producer (MSG. Topic).
func (p *asyncProducer) newTopicProducer(topic string) chan<- *ProducerMessage {
input := make(chan *ProducerMessage, p.conf.ChannelBufferSize)
tp := &topicProducer{
parent: p,
topic: topic,
input: input,
breaker: breaker.New(3, 1, 10*time.Second),
handlers: make(map[int32]chan<- *ProducerMessage),
partitioner: p.conf.Producer.Partitioner(topic),
}
go withRecover(tp.dispatch)
return input
}
Here, a channel with a buffer size of ChannelBufferSize is created to store messages sent to this topic, and then a topicProducer is created.
At this time, you can think that the message has been delivered to the topicProducer corresponding to each topic.
Another thing to note is the writing method of newTopicProducer, which creates a chan internally and returns to the outer layer, and then processes the messages in the chan by opening a goroutine internally. This writing method will be encountered several times later.
In contrast, it may be easier to understand what is passed to this function after the external display creates a chan.
topicDispatch
In the last line of the new Topic producer, go withRecover(tp.dispatch) starts a goroutine to process messages. That is, at this stage, there is a coroutine for each Topic to process messages.
The details of dispatch are as follows:
func (tp *topicProducer) dispatch() {
for msg := range tp.input {
handler := tp.handlers[msg.Partition]
if handler == nil {
handler = tp.parent.newPartitionProducer(msg.Topic, msg.Partition)
tp.handlers[msg.Partition] = handler
}
handler <- msg
}
}
You can see the same routine again:
- 1) Find the channel corresponding to the partition where the message is located, and then throw the message in
- 2) If it does not exist, create a new chan
PartitionDispatch
The new chan is returned through newPartitionProducer, which is the same routine as the previous newTopicProducer. Click to see:
func (p *asyncProducer) newPartitionProducer(topic string, partition int32) chan<- *ProducerMessage {
input := make(chan *ProducerMessage, p.conf.ChannelBufferSize)
pp := &partitionProducer{
parent: p,
topic: topic,
partition: partition,
input: input,
breaker: breaker.New(3, 1, 10*time.Second),
retryState: make([]partitionRetryState, p.conf.Producer.Retry.Max+1),
}
go withRecover(pp.dispatch)
return input
}
Sure enough, there is no sense of deja vu.
TopicProducer is distributed according to Topic. Here, PartitionProducer is distributed according to partition.
It can be considered that the message has been delivered to the corresponding partition under the corresponding topic.
Each partition will have a goroutine to handle the messages distributed to itself.
PartitionProducer
At this point, let's take a look at how the message is processed after it reaches the channel where each partition is located.
In fact, in this step, we mainly do some error handling, and then throw the message into the broker producer.
It can be understood that this step is the transformation from the business logic layer to the network IO layer. Before that, we only care about which partition the message goes to. After that, we need to find the address of the broker where the partition is located and send the message using the previously established TCP connection.
The specific pp.dispatch code is as follows
func (pp *partitionProducer) dispatch() {
// Find the broker where the leader of this topic and partition is located
pp.leader, _ = pp.parent.client.Leader(pp.topic, pp.partition)
if pp.leader != nil {
// Create a BrokerProducer object based on the leader information
pp.brokerProducer = pp.parent.getBrokerProducer(pp.leader)
pp.parent.inFlight.Add(1)
pp.brokerProducer.input <- &ProducerMessage{Topic: pp.topic, Partition: pp.partition, flags: syn}
}
// Then throw the message into the broker producer
for msg := range pp.input {
pp.brokerProducer.input <- msg
}
}
According to the previous routine, we know that the real logic must be in the method pp.parent.getBrokerProducer(pp.leader).
BrokerProducer
Here, it is probably the last step in the whole sending process.
Let's follow up on the line pp.parent.getBrokerProducer(pp.leader). In fact, it is to find the brokerProducer in asyncProducer. If it does not exist, create one.
func (p *asyncProducer) getBrokerProducer(broker *Broker) *brokerProducer { p.brokerLock.Lock() defer p.brokerLock.Unlock() bp := p.brokers[broker] if bp == nil { bp = p.newBrokerProducer(broker) p.brokers[broker] = bp p.brokerRefs[bp] = 0 } p.brokerRefs[bp]++ return bp}
newBrokerProducer() is called again to continue tracing:
func (p *asyncProducer) newBrokerProducer(broker *Broker) *brokerProducer { var ( input = make(chan *ProducerMessage) bridge = make(chan *produceSet) responses = make(chan *brokerProducerResponse) ) bp := &brokerProducer{ parent: p, broker: broker, input: input, output: bridge, responses: responses, stopchan: make(chan struct{}), buffer: newProduceSet(p), currentRetries: make(map[string]map[int32]error), } go withRecover(bp.run) // minimal bridge to make the network response `select`able go withRecover(func() { for set := range bridge { request := set.buildRequest() response, err := broker.Produce(request) responses <- &brokerProducerResponse{ set: set, err: err, res: response, } } close(responses) }) if p.conf.Producer.Retry.Max <= 0 { bp.abandoned = make(chan struct{}) } return bp}
Here, two goroutine s are started, one is run, and the other is an anonymous function, which is called bridge for the moment.
bridge seems to be the real sending logic, so the batch handle logic should be in the run method.
Here we first analyze the bridge function, and run will analyze it in the next chapter.
buildRequest
The buildRequest method is mainly to build a standard Kafka Request message.
Additional processing is done according to different versions and whether the compression information is configured. Ignore it here and only look at the core code:
func (ps *produceSet) buildRequest() *ProduceRequest { req := &ProduceRequest{ RequiredAcks: ps.parent.conf.Producer.RequiredAcks, Timeout: int32(ps.parent.conf.Producer.Timeout / time.Millisecond), } for topic, partitionSets := range ps.msgs { for partition, set := range partitionSets { rb := set.recordsToSend.RecordBatch if len(rb.Records) > 0 { rb.LastOffsetDelta = int32(len(rb.Records) - 1) for i, record := range rb.Records { record.OffsetDelta = int64(i) } } req.AddBatch(topic, partition, rb) continue } }}
First, build a req object, then traverse the messages in ps.msg and write them into req according to topic and partition.
Produce
func (b *Broker) Produce(request *ProduceRequest) (*ProduceResponse, error) { var ( response *ProduceResponse err error ) if request.RequiredAcks == NoResponse { err = b.sendAndReceive(request, nil) } else { response = new(ProduceResponse) err = b.sendAndReceive(request, response) } if err != nil { return nil, err } return response, nil}
Finally, the sendAndReceive() method is called to send the message.
If we set the need for Acks, we will send a response to receive the return value; If it is not set, it will be ignored after the message is sent.
func (b *Broker) sendAndReceive(req protocolBody, res protocolBody) error { promise, err := b.send(req, res != nil, responseHeaderVersion) if err != nil { return err } select { case buf := <-promise.packets: return versionedDecode(buf, res, req.version()) case err = <-promise.errors: return err }}
func (b *Broker) send(rb protocolBody, promiseResponse bool, responseHeaderVersion int16) (*responsePromise, error) { req := &request{correlationID: b.correlationID, clientID: b.conf.ClientID, body: rb} buf, err := encode(req, b.conf.MetricRegistry) if err != nil { return nil, err } bytes, err := b.write(buf)}
Finally, it is sent through bytes, err: = b.write (buf).
func (b *Broker) write(buf []byte) (n int, err error) { if err := b.conn.SetWriteDeadline(time.Now().Add(b.conf.Net.WriteTimeout)); err != nil { return 0, err } // Here is the logic in the. net package.. return b.conn.Write(buf)}
So far, the relevant contents of Sarama producer have been introduced.
There is also a more important logic of message packaging and batch sending, which will be discussed in the next chapter.
3. Message packaging source code analysis
Previously, two goroutine s were started in the broker producer logic, in which the bridge took messages from chan and actually sent them.
So where did the news in chan come from?
In fact, this is another goroutine's job.
func (p *asyncProducer) newBrokerProducer(broker *Broker) *brokerProducer { var ( input = make(chan *ProducerMessage) bridge = make(chan *produceSet) responses = make(chan *brokerProducerResponse) ) bp := &brokerProducer{ parent: p, broker: broker, input: input, output: bridge, responses: responses, stopchan: make(chan struct{}), buffer: newProduceSet(p), currentRetries: make(map[string]map[int32]error), } go withRecover(bp.run) // minimal bridge to make the network response `select`able go withRecover(func() { for set := range bridge { request := set.buildRequest() response, err := broker.Produce(request) responses <- &brokerProducerResponse{ set: set, err: err, res: response, } } close(responses) }) if p.conf.Producer.Retry.Max <= 0 { bp.abandoned = make(chan struct{}) } return bp}
run
func (bp *brokerProducer) run() { var output chan<- *produceSet for { select { case msg, ok := <-bp.input: // 1. Check whether the buffer space is enough to store the current MSG if bp.buffer.wouldOverflow(msg) { if err := bp.waitForSpace(msg, false); err != nil { bp.parent.retryMessage(msg, err) continue } } // 2. Store MSG in buffer if err := bp.buffer.add(msg); err != nil { bp.parent.returnError(msg, err) continue } // 3. If the interval expires, the message will also be sent case <-bp.timer: Bp.timerfired = true / / 4. Send the data in the buffer to the local variable output chan case output <- bp.buffer: bp.rollOver() case response, ok := <-bp.responses: if ok { bp.handleResponse(response) } } // 5. If the sending time is up or the message size or number reaches the threshold, it indicates that the message can be sent. Assign bp.output chan to the local variable output if bp.timerFired || bp.buffer.readyToFlush() { output = bp.output } else { output = nil } }}
- 1) First, the buffer space is detected
- 2) Write msg to buffer
- 3) The next 3, 4 and 5 steps are to send messages or prepare for sending messages
wouldOverflow
if bp.buffer.wouldOverflow(msg) { if err := bp.waitForSpace(msg, false); err != nil { bp.parent.retryMessage(msg, err) continue }}
Before add ing, call the bp.buffer.wouldOverflow(msg) method to check whether there is enough space in the buffer to store the current message.
wouldOverflow is relatively simple, which is to judge whether the current message size or message quantity exceeds the set value:
func (ps *produceSet) wouldOverflow(msg *ProducerMessage) bool { switch { case ps.bufferBytes+msg.byteSize(version) >= int(MaxRequestSize-(10*1024)): return true case ps.msgs[msg.Topic] != nil && ps.msgs[msg.Topic][msg.Partition] != nil && ps.msgs[msg.Topic][msg.Partition].bufferBytes+msg.byteSize(version) >= ps.parent.conf.Producer.MaxMessageBytes: return true case ps.parent.conf.Producer.Flush.MaxMessages > 0 && ps.bufferCount >= ps.parent.conf.Producer.Flush.MaxMessages: return true default: return false }}
If it is not enough, call bp.waitForSpace() to wait for the buffer to make room. In fact, it is to send the messages in the buffer to output chan.
The output chan is the bridge in the anonymous function above.
func (bp *brokerProducer) waitForSpace(msg *ProducerMessage, forceRollover bool) error { for { select { case response := <-bp.responses: bp.handleResponse(response) if reason := bp.needsRetry(msg); reason != nil { return reason } else if !bp.buffer.wouldOverflow(msg) && !forceRollover { return nil } case bp.output <- bp.buffer: bp.rollOver() return nil } }}
add
Next, call bp.buffer.add() to add the message to the buffer. The function is relatively simple, and add the message to be sent to the buffer.
func (ps *produceSet) add(msg *ProducerMessage) error { // 1. Message coding key, err = msg.Key.Encode() val, err = msg.Value.Encode() // 2. Add message to set.msgs array set.msgs = append(set.msgs, msg) // 3. Add to set.recordstosend msgToSend := &Message{Codec: CompressionNone, Key: key, Value: val} if ps.parent.conf.Version.IsAtLeast(V0_10_0_0) { msgToSend.Timestamp = timestamp msgToSend.Version = 1 } set.recordsToSend.MsgSet.addMessage(msgToSend) // 4. Increase the buffer size and the number of messages in the buffer ps.bufferBytes += size ps.bufferCount++}
set.recordsToSend.MsgSet.addMessage is also very simple:
func (ms *MessageSet) addMessage(msg *Message) { block := new(MessageBlock) block.Msg = msg ms.Messages = append(ms.Messages, block)}
Timing transmission
Because the asynchronous sender will trigger a transmission when the number of messages or message size reaches the threshold. In addition, it will also trigger a transmission at a certain time. The specific logic is also in this run method. This place is more interesting.
func (bp *brokerProducer) run() { var output chan<- *produceSet for { select { case msg, ok := <-bp.input: // 1. When the time is up, set bp.timerfired to true case <-bp.timer: Bp.timerfired = true / / 3. Send the messages in the buffer directly to the local variable output case output <- bp.buffer: bp.rollOver() } // 2. If the time is up or the message in the buffer reaches the threshold, the real sending logic will be triggered. The implementation here is more interesting. When it needs to be sent, assign bp.output, that is, the chan storing the batch messages that really need to be sent, to the local variable output. If it does not need to be sent, clear the local variable output if bp.timerFired || bp.buffer.readyToFlush() { output = bp.output } else { output = nil } }}
According to steps 1, 2 and 3 in the note, if the second step needs to be sent, the output will be assigned. In this way, the case output < - BP. Buffer: this case may be executed in the next round of select ion, and the message will be sent to output, which is actually sent to bp.output
If there is no need to send a message in the second step, the output will be set to null, and the corresponding case in select will not be executed.
The normal writing method is to start a goroutine to handle the function of timing transmission, but in this way, there will be competition between the two goroutines, which will affect the performance. In this way, the addition and unlocking process is omitted, and the performance will be higher, but with the increase of code complexity.
The author's ability is really limited, and there may be some wrong understanding in the article. So when you find some violations, please don't hesitate to give advice, thank you!
Thank you again for seeing here!
4. Summary
1) Specific process: see the opening figure
2) Common optimization means: batch processing.
The asynchronous consumer Go implementation optimizes the batch sending of messages. When enough messages are accumulated, they are sent at one time to reduce the number of network requests to improve performance.
Similar to Redis Pipeline, multiple commands are sent at one time to reduce RTT.
Of course, in order to avoid not collecting enough messages for a long time when there are few messages, which leads to failure to send, a regular sending threshold is generally set and will be sent every other period of time.
This is a common optimization method. For example, there must be some bufferio libraries in IO related places. When writing, write the buffer first, and then write it to the disk at one time when the buffer is full. The same is true for reading. First read it to the buffer, and then the application reads it out line by line from the buffer.
3) Code complexity and performance tradeoffs
In the last paragraph of the analysis of Sarama Proudcer, we can see that there is an operation that can improve the performance, but the following is the increase of code complexity.
Recently, I've been looking at the Go runtime. There are many operations. There's no problem with writing this kind of underlying library and middleware, but we try not to hype our business code as much as possible.
"The performance improvement does not materialize from the air,it comes with code complexity increase."
Performance will not improve out of thin air, followed by an increase in code complexity.
See for Kafka series related codes Github
5. Reference
https://github.com/Shopify/sarama
https://cs50mu.github.io/post/2021/01/22/source-code-of-sarama-part-i/
https://www.jianshu.com/p/138e0ac2e1f0
https://juejin.cn/post/6866316565348876296