Java -- collection, IO stream
1. Set (java.util. *)
(1) 1. Overview
I. a set is actually a container (carrier) that can store multiple objects; (array is the simplest set);
II. The basic data type and java object cannot be stored in the collection, but the memory address of the java object is stored;
III. the bottom layer of each different set corresponds to different data structures (array, binary tree, linked list, hash table...);
(2) . classification and structure diagram of collection
<1> . collection interface:
Super parent interface: java.util.Collection
a.Collection inheritance structure diagram:
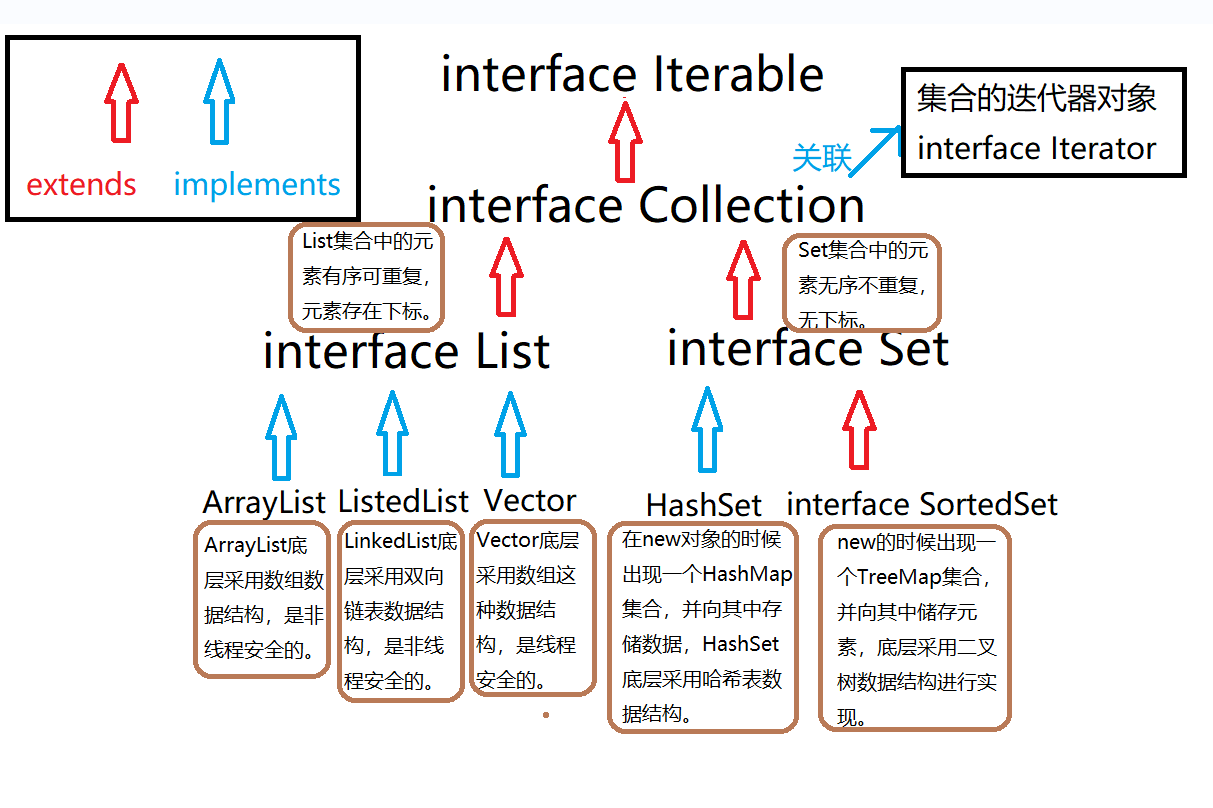
summary:
① . Collection can store all subclass objects of Object;
② . because Collection is an interface and cannot be instantiated, the new object applies the polymorphic mechanism to create the implementation class object of the subclass.
b. Common methods
A. Add an element to the collection
//Add an element to the collection public boolean add(Object e);
B. Gets the number of elements in the collection
//Gets the number of elements in the collection public int size();
C. Empty elements in collection
//Empty elements in collection public void clear();
D. Determine whether the collection contains an element
Tips:
The bottom layer of this method calls the equals method, and the elements placed in the collection should override the equals method.
//Determine whether the collection contains an element public boolean contains(Object e);
E. Remove an element from the collection
//Remove an element from the collection public boolean remove(Object e);
F. Determine whether the collection is empty
//Determine whether the collection is empty public boolean isEmpty();
G. Convert collection to array
//Convert collection to array public Object[] toArray();
<2> . iterator iterator interface:
a. Get iterator object:
Collection c = new ArrayList(); Iterator it = c.iterator(); //The iterator() method is a method in Iterable, the parent interface of the Collection interface
b. Methods in iterators:
A. Determine whether the set can be iterated
//Determine whether the set can be iterated public boolean hasNext();
B. Returns the next element of the iteration
//Returns the next element of the iteration public Object next();
C. Deletes the currently pointed element
//Deletes the currently pointed element public void remove();
c. Precautions for using iterators:
A. For the iterator, when the set structure changes, the iterator must get it again;
B. Use the remove() method of the iterator to delete the iterator that can be updated automatically.
<3> . list interface: storage elements have subscripts, which are orderly and repeatable
a. Common methods:
A. Adds an element at the specified location i
//Adds an element at the specified location i public void add(int index,Object element);
B. Get element by subscript
//Get element by subscript public Object get(int index);
C. Gets the index of the first occurrence of the specified object
//Gets the index of the first occurrence of the specified object public int indexOf(Object element);
D. Gets the index of the last occurrence of the specified object
//Gets the index of the last occurrence of the specified object public int lastIndexOf(Object element);
E. Deletes the element at the specified location
//Deletes the element at the specified location public void remove(int index);
F. Modify the element value at the specified location
//Modify the element value at the specified location public void set(int index,Object Element);
b.ArrayList class details:
A. Initial capacity
The bottom layer of ArrayList set is realized by array, and the initial capacity is 10. You can also construct new ArrayList(int capacity); Specifies the initialization capacity.
B. Capacity expansion
When the storage space is insufficient, the collection will be automatically expanded by 1.5 times.
In essence, it is a bit operator binary, shift right by one bit 1010 > > 1 = 0101 - > 5, and shift left by the same reason.
C. Advantages and disadvantages
Advantages: high retrieval efficiency and high efficiency of final elements;
Disadvantages: low efficiency of addition and deletion.
c.LinkedList class details:
A. Linked list data structure
Node node is the basic unit in the linked list.
One way linked list:
Each Node has two attributes: the stored data and the memory address of the next Node.
Bidirectional linked list:
Each Node has three attributes: the stored data, the memory address of the next and previous nodes.
B. Advantages and disadvantages
Advantages: the efficiency of randomly adding and deleting elements is high;
Disadvantages: the query efficiency is low, and the search elements need to be traversed from the beginning to the bottom.
d. Detailed explanation of vector class:
A. Initial capacity
The bottom layer of Vector set is realized by array, and the initialization capacity is 10. You can also construct new Vector(int initialCapacity); Set the initialization capacity.
B. Capacity expansion
When the Vector storage space is full, it will be automatically expanded by 2 times.
C. Method characteristics
The methods in the Vector collection are thread safe (with the synchronized keyword).
e. Generic mechanism:
A. Function
Specify that the element types stored in the collection are fixed, and the data types in the collection are more uniform.
B. Grammatical mechanism
//Specifies that only String type data examples can be stored in the List method //Method 1: List<String> l = new ArrayList<>(); //Method 2: List l = new ArrayList<String>(); //Method 3: List<String> l = new ArrayList();
C. Advantages and disadvantages
advantage:
① The element types stored in the collection are unified;
② The data taken from the collection is a generic specified type, and no more downward transformation is required.
Disadvantages:
This leads to a lack of diversity of element types in the collection.
f. Summarize the iteration and traversal of sets
//Create collections and add elements
List<String> l1 = new ArrayList <>();
l1.add(0,"Spicy beef moon cake");
l1.add(1,"lotus seed paste mooncake");
l1.add(2,"olive nut moon-cake");
A. Iterator traversal
//Iterator traverses collection
Iterator <String> it = l1.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
B. Subscript of List set
//Subscript traversal
for (int i = 0;i < l1.size();i++){
System.out.println(l1.get(i));
}
C. Traversal with enhanced for
//foreach traversal
for (String s:l1){
System.out.println(s);
}
<4> Map interface: elements have no subscripts, are out of order and cannot be repeated
Super parent interface: java.util.Map
a. Data storage characteristics
The Map set stores data in the form of key and value, that is, in the form of [key value pair].
Both key and value are reference data types, and both store the memory address of the object.
Map inheritance structure diagram
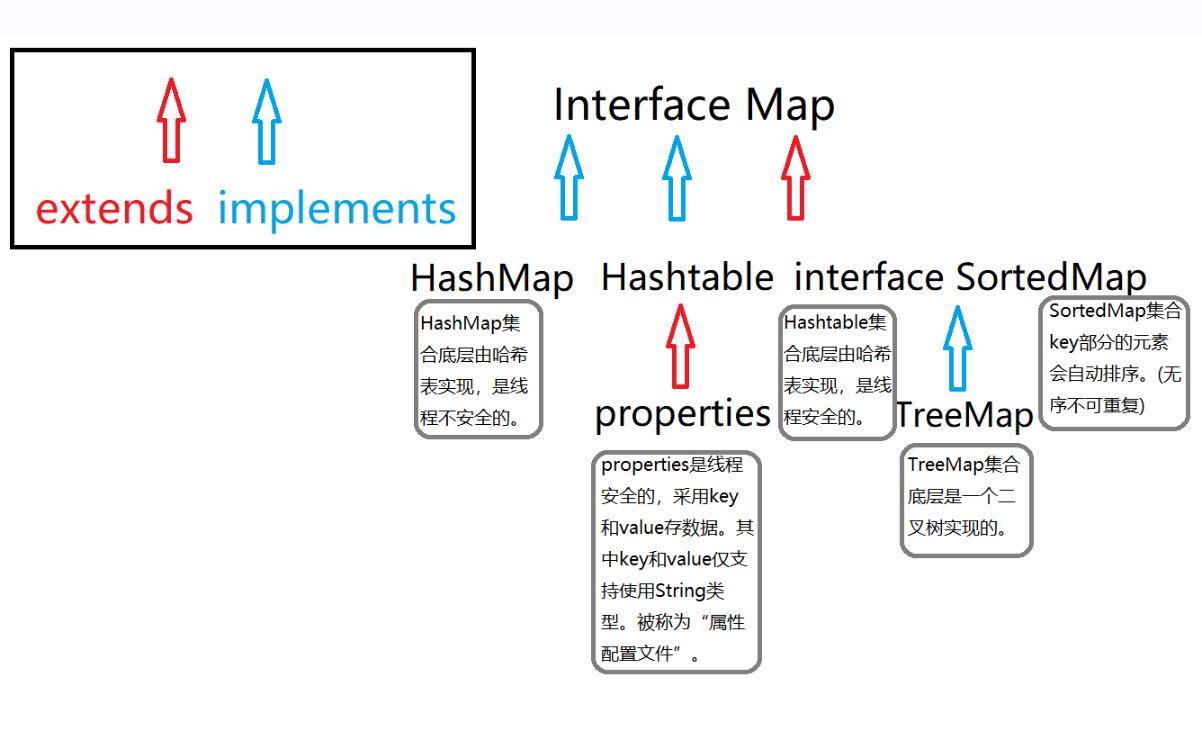
c. Common methods
A. Adds a key value pair to the Map collection
Map<K,V> map = new TreeMap<>();
//Adds a key value pair to the Map collection public V put(K key,V value);
B. Get the value value through the key value
//Get the value value through the key value public V get(K key);
C. Empty Map collection
//Empty Map collection public void clear();
D. Judge whether a key or value is included in the Map set
//Judge whether a key or value is included in the Map set public boolean containsValue(Object value); public boolean containsKey(Object key);
E. Judge whether the Map collection is empty
//Judge whether the Map collection is empty public boolean isEmpty();
F. Get all the keys in the Map collection and store them in a Set collection
//Get all the keys in the Map collection and store them in a Set collection public Set<K> keySet();
G. Delete key value pairs by key value
//Delete key value pairs by key value public V remove(Object key);
H. Gets the number of key value pairs in the Map collection
//Gets the number of key value pairs in the Map collection public int size();
1. Get all the values in the Map and store them in a Collection
//Get all the values in the Map and store them in a Collection public Collection<V> values();
J. Convert Map Set to Set set Set
//Convert Map Set to Set set Set public Set<Map.Entry<K,V>> entrySet();
d. Traversal method of map collection
//Create collections and add elements
TreeMap map = new TreeMap<Integer,String>();
map.put(1,"hamburger");
map.put(2,"French fries");
map.put(3,"Hot Wing");
A. Get all the keys and traverse through the get method and iterator
//Get all the key s, and then get the value value through the get method
Set<Integer> set = map.keySet();
Iterator <Integer> it = set.iterator();
while(it.hasNext()){
Integer key = it.next();
System.out.println(key+"="+map.get(key));
}
B. The key value pair is converted into a Set set through the entrySet method, and then traversed by the iterator
//The map is converted into a set set through the entrySet, and then traversed by the iterator
Set<Integer> set = map.entrySet();
Iterator <Integer> it = set.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
e.HashMap class details:
A. Overview of hash table data structure
definition:
Hash table is a combination of array and one-way linked list, which combines the advantages of the above two.
Hash subscript:
① . the node hash values on the same one-way linked list are the same because their array subscripts are the same;
② The hashCode() and equals() methods should be overridden when the key of the. HashMap collection is used.
Implementation principle of put(K key,V value) method:
① . encapsulate key and value into Node object;
② . call the hashCode() method of key to get the Hash value.
③ . the Hash value is converted into an array subscript through a Hash algorithm.
If there is no element in the subscript position, add the Node;
If there is an element (linked list), compare the key with the key of each node on the linked list with equals():
If all returns are false, the node is added to the end;
If true is returned, the value value of the node is overwritten.
Implementation principle of get(K key) method:
① . call hashCode() of key to get the hash value;
② . convert the hash value into array subscript through hash algorithm;
③ . lock the position by subscript.
If the subscript element has no element, a null is returned;
If there is an element (linked list), take the parameter key and compare equals with each node on the one-way linked list:
If all returns are false, the method returns null;
If true is returned, the value of the node is returned.
B.HashMap collection details:
Initial capacity
The initialization capacity of the HashMap collection is 16.
You can also initialize capacity through new HashCode(int capacity), but the set capacity must be an integer power of 2.
(that is, when the capacity reaches [16x0.75=12], the set automatic capacity expansion value is 32.)
Default load factor
Definition: when the storage element capacity of the collection reaches the default loading factor, the collection will be automatically expanded.
HashMap: the default load factor for this collection is 0.75.
Store element information
The [key] value in the HashMap set can be null, and the [value] value can also be null.
f.Hashtable class details:
A.Hashtable class overview:
Initial capacity
The initial capacity of Hashtable set is 11;
Default loading factor and expansion capacity
The default loading factor of Hashtable is 0.75, and the capacity expansion is [original capacity * 2 + 1].
Store element information
① Neither the [key] value nor the [value] value in the. Hashtable set can be null.
② . the collection is thread safe.
B. Detailed description of properties class:
Storage data type:
Both key and value types should be String types.
Common methods:
Storing data into a collection
//Storing data into a collection public synchronized Object setProperty(String key,String value);
Get the elements in the collection
//Get the elements in the collection public synchronized String getProperty(String key);
g. Detailed explanation of TreeSet and TreeMap classes
A. Overview:
① The bottom layer of the. TreeSet set is a TreeMap set, and the bottom layer of the TreeMap is a binary tree data structure.
② The elements in the. TreeSet collection are equal to the key part in the TreeMap collection.
③ The. Map collection is out of order and cannot be repeated. The TreeMap collection can be sorted automatically.
B. Collation:
① . TreeSet for custom classes, TreeSet cannot be sorted;
② . if you add [sort rule] to a user-defined class, you can implement the Comparable interface and the internal comparedTo() method, and write [sort rule] in it.
③ The sorting rules of. TreeMap and TreeSet adopt [middle order traversal] in the binary tree.
C. Two methods for sorting:
① . implement the java.util.Comparable interface, which is usually used for sorting rules that will not change;
② When building a collection object, pass in a comparator object comparator interface, which is usually used for frequent changes in sorting rules.
Method 1 test:
Preparation: prepare a Student class to implement the Comparable interface, and rewrite the comparedTo() method. The sorting rules are as follows:
//When students make key s, first let them compare the student numbers. If the student numbers are equal, then compare the student names
public int compareTo(Student o) {
if (this.no < o.no){
return -1;
}else if (this.no > o.no){
return 1;
}else{
return this.name.compareTo(o.name);
}
}
Writing test class:
public static void main(String[] args) {
Map<Student,Integer> map = new TreeMap <>();
map.put(new Student("shawn",5),5);
map.put(new Student("Alice",6),6);
map.put(new Student("James",7),7);
map.put(new Student("Jane",8),8);
map.put(new Student("Alice",7),7);
System.out.println(map);
}
Test results and summary:
{Student{name='shawn', no=5}=5,
Student{name='Alice', no=6}=6,
Student{name='Alice', no=7}=7,
Student{name='James', no=7}=7,
Student{name='Jane', no=8}=8}
Summary: it can be seen from the above results that the smaller student number no is listed above, and when the middle student number no is equal, the names will be compared, so as to achieve the sorting function of user-defined classes.
Method 2 test:
Preparation: prepare a Student class to implement the Comparable interface, and rewrite the comparedTo() method. The sorting rules are the same as above
Test writing:
public static void main(String[] args) {
Map<Student,Integer> map = new TreeMap <>(new Comparator <Student>() {
@Override
public int compare(Student o1, Student o2) {
if (o1.getNo()<o2.getNo()){
return -1;
}else if (o1.getNo()>o2.getNo()){
return 1;
}else{
return o1.getName().compareTo(o2.getName());
}
}
});
map.put(new Student("shawn",5),5);
map.put(new Student("Alice",6),6);
map.put(new Student("James",7),7);
map.put(new Student("Jane",8),8);
map.put(new Student("Alice",7),7);
System.out.println(map);
}
Output results:
(same as above!)
h. Collection's tool class Collections:
Common methods:
A. Change collection from non thread safe to thread safe
//Change collection from non thread safe to thread safe public static List<T> synchronizedList(list l);
B. Sort the elements in the collection
//Sort the elements in the collection public static List<T> sort(List l);
2.IO stream (Input/Output Stream)
(1) 1. Overview
effect:
[read and write of hard disk file] can be completed through IO stream.
Distinction between reading and writing:
·Enter [read] when reading into memory;
·Write out memory is output [write].
Package:
All streams in java are under java.io. *.
Classification:
I. java.io.InputStream: byte input stream;
II. java.io.OutputStream: byte output stream;
III. java.io.Reader:: character input stream;
Ⅳ. java.io.Writer: character output stream.
Implemented interfaces:
※ ① all [output streams] implement the java.io.Flushable interface, and there is a flush() method to refresh the stream.
※ ② [ all streams ] implements the java.io.Closeable interface, and there is a close() method to [ close streams ].
(2) . detailed explanation of document class flow:
Classification:
Ⅰ.java.io.FileInputStream
Ⅱ.java.io.FileOutputStream
Ⅲ.java.io.FileReader
Ⅳ.java.io.FileWriter
<1> . FileInputStream class details:
definition:
[file byte output stream] can read files of any format.
Construction method:
Source code:
/*
*@param name:file name
*/
public FileInputStream(String name) throws FileNotFoundException {
this(name != null ? new File(name) : null);
}
/*
*@param file:Read file object
*/
public FileInputStream(File file);
read() method and read(byte[] bytes) method:
/* *This method can read one byte in the target file at a time, and its efficiency is low. *@return If there is a read value, return the read byte itself. If there is no read value, take - 1 */ public int read();
In order to reduce the interaction between hard disk and memory, the read(byte[] bytes) method is introduced
/* *This method reads [bytes.length] bytes of the target file at a time, with high efficiency. *@return Returns the number of bytes read. If there is no read value, - 1 is returned */ public int read(byte[] b);
※ when using the read(byte[] b) method, the output byte itself can use the String construction method
//Convert the byte array into a string for output new String(byte[] bytes,int offset,int readCount);
Thus, the optimal solution for reading files is obtained:
Tips: stored as "Hello IOStream!" in [io test text]
//Create a stream object: (expand the scope of the fis object and read the object in the finally chunk)
FileInputStream fis = null;
try {
//Specifies the file to read
fis = new FileInputStream("io Test text.txt");
int readCount = 0;
byte[] bytes = new byte[4];
while((readCount = fis.read(bytes)) != -1){
System.out.print(new String(bytes,0,readCount));
}
} catch (IOException e) {
e.printStackTrace();
} finally{
//Finally, the flow must be closed: (add judgment to prevent [null pointer exception])
if (fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
The output result is:
[Hello IOStream!]
Other methods:
available()
//Use this method to read the data at one time /* *@return Returns the number of bytes that can be read */ public int available();
skip()
/* *@param l:bytes Total number of bytes the array needs to skip *@return Bytes actually skipped */ public long skip(long l);
<2> . fileoutputstream class details:
definition:
[file byte output stream].
Construction method:
/* *@param name:File name to write *@param append:Is the written data spliced on the original basis */ new FileOutputStream(String name,boolean append);
write(byte[] bytes) method:
/* *Write data to the original file *@param bytes byte array of written data */ public void wirte(byte[] bytes);
※: when adding a String, you can call the getByte(String s) method in the String to convert the String into a byte array.
Example of writing data:
//Define output stream
FileOutputStream fos = null;
try {
fos = new FileOutputStream("io Test text.txt",true);
String str = "I am Chinese, I am proud";
//Convert string to byte array
byte[] bytes = str.getBytes();
fos.write(bytes);
//Output stream needs to brush new stream:
fos.flush();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
//The stream needs to be closed at the end
if (fos != null){
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
<3> Introduction to. FileReader class:
definition:
[file character input stream] can only read [normal text].
<4> Introduction to. Filewriter class:
definition:
[file character output stream] can only read [normal text].
<5> . file copy function:
Source code:
package IO flow;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileCopy {
public static void main(String[] args) {
//Definition of input stream
FileInputStream fis = null;
//Definition of output stream
FileOutputStream fos = null;
try {
fis = new FileInputStream("E:\\highlights\\Running robot.mp4");
fos = new FileOutputStream("E:\\Bubble robot.mp4");
//Initialize count variable readCount and array byte []
int readCount = 0;
byte[] bytes = new byte[1024*1024];//One time copy of 1M files
//Read while writing
while((readCount = fis.read(bytes))!= -1){
fos.write(bytes,0,bytes.length);
}
//Refresh output stream
fos.flush();
} catch (IOException e) {
e.printStackTrace();
}finally{
//Close input and output streams
if (fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
result:
[E:/highlights / running robot. mp4] the video file was successfully copied to
[E: / bubble robot. mp4], renaming is performed at the same time.
(3) . detailed explanation of buffer class flow:
Buffer class streams include:
Ⅰ.java.io.BufferedReader
Ⅱ.java.io.BufferedWriter
Ⅲ.java.io.BufferedInputStream
Ⅳ.java.io.BufferedOutputStream
BufferedReader class (the same applies to BufferedWriter class):
Definition: character input stream with buffer;
Construction method:
new BufferedReader(Reader reader);
method:
readLine() method:
//Read one line of the file at a time. public String readLine();
read() method:
//Read one character at a time, and the return value is ASCII value. public int read();
read(char[] chars) method:
//Read chars.length at a time and store it in the chars array. The return value is the number of characters read public int read(char[] chars);
Convert stream InputStreamReader: convert byte stream to character stream:
InputStreamReader I = new InputStreamReader(new FileInputStream("io Test text"));
(4) . detailed explanation of standard output flow:
<1>.PrintStream
Package: java.io.PrintStream
① . the standard [byte output stream] is output to the console by default.
② . the flow does not need to be closed manually.
③ . manually change the output direction: (under System class)
public static void setOut(PrintStream ps);
<2>.PrintWriter
Package: java.io.PrintWriter
① . standard [character output stream], the same as above;
(5) . detailed explanation of object class flow:
summary:
[serialize,deserialize]
① [(deserialization): (deserialization) put the java object in memory into the hard disk file.
② . objects participating in serialization and deserialization must implement the Serializable interface.
③ . add the [transient] keyword before the attribute to indicate that the variable does not participate in (DE) serialization.
④ . IDEA automatically generates a serialized version number.
⑤ The load() method in the Properties class in the. Map collection loads the hard disk file into memory.
public synchronized void load(InputStream inStream); public synchronized void load(Reader reader);
(6).java.io.File class details:
summary:
The file class cannot read and write objects. File is an abstract representation of path names.
Construction method:
//Pathname of the file new File(String pathname);
method:
exists() method:
//Determine whether the target file exists public boolean exists()
createNewFile() method:
//Create a file in the current directory public void createNewFile();
mkdir() method:
//Create a subdirectory under the current directory public void mkdir();
getParent():
//Get file parent path public String getParent();
getAbsolutePath():
//Gets the absolute path of the file public String getAbsolutePath();
listFiles();
//Get all sub files in the current directory public File[] listFiles();
(7) . copy directory programming:
/*
*This method is used for copying directories
*@param srcFile:Copy source file object
*@param deskFile:Copy target file object
*@param src:Copy source file address
*@param desk:Copy destination file address
*/
public static void copy(File srcFile,File deskFile,String src,String desk){
//List all subdirectories under the source directory:
File[] files = srcFile.listFiles();
//Traverse the files array to get all subdirectories and sub files:
//When you get a file:
if (srcFile.isFile()){
//Copy with FOS and FIS:
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(src);
fos = new FileOutputStream(desk);
int readCount = 0;
byte[] bytes = new byte[1024*1024];//Primary transmission 1MB
while((readCount = fis.read(bytes))!=-1){
fos.write(bytes,0,readCount);
}
//Output stream refresh:
fos.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
//I / O flow off:
if (fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return;
}
//When you get the directory:
for (File file : files){
if (file.isDirectory()){
String srcDir = file.getAbsolutePath();
String deskDir = (deskFile.getAbsolutePath().
endsWith("\\")?deskFile.getAbsolutePath()
:deskFile.getAbsolutePath()+"\\")+srcDir.substring(3);
System.out.println(srcDir);
System.out.println(deskDir);
File newFile = new File(deskDir);
if (newFile.exists()){
newFile.mkdirs();
}
}
// Recursive call
copy(file,deskFile,src,desk);
}
}
}