Regular expression (RegExp)
How to find the content quickly according to certain rules, the designers of js provide us with a RegExp object, which is specially used to deal with similar problems.
RegExp objects represent regular expressions and are powerful tools for pattern matching of strings.
Regular Expressions--Basic Concepts
In computer science, it refers to a single string that describes or matches a series of strings that conform to a certain syntactic rule. In many text editors or other tools, regular expressions are often used to retrieve or replace text content that conforms to a pattern. Many programming languages support string manipulation using regular expressions.
Special emphasis: Regular expressions are not proprietary products of js, in fact, many programming languages support regular expressions for string manipulation!
A regular expression is a formula that matches a class of strings with a pattern. Many people are afraid to use them because they look weird and complex, but after a little practice, they feel that these complex expressions are actually quite simple to write, and once you understand them, you can shorten the hours of hard and error-prone text processing to a few minutes (or even seconds).
Quick Start Case
Give you a string (or an article). Can you find all four numbers in a string?
[01.html] introductory case
<html>
<head>
<title>dom Example--RegExp</title>
<script type="text/javascript" language="javascript">
<!--
function test(){
//Get the user's content
var con=content.innerText;
var myReg=/(\d){4}/gi;//This is a regular expression object that retrieves four consecutive numbers
while(res=myReg.exec(con)){ //Res is the retrieved result, but a result corresponds to an array whose res[0] is the text found.
alert("find"+res[0]);
}
}
//-->
</script>
</head>
<body>
<textarea id="content" rows="10" cols="20"></textarea><br>
<input type="button" value="test" onclick="test()"/>
</body>
</html>
There are two ways to create a RegExp object:
var regExp=/regular expression/gi; (implicitly created)
Var regExp = new RegExp (regular expression, "gi"; (display creation)
Specifically, g denotes that regular expressions perform global matching, i denotes case-insensitive matching of regular expressions, and m denotes multiline patterns.
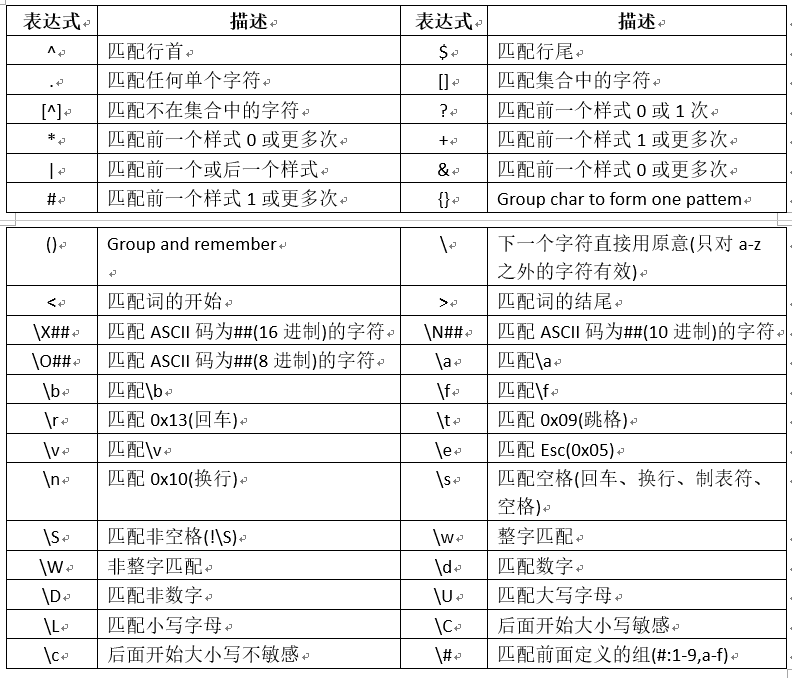
RegExp
RegExp objects represent regular expressions and are powerful tools for pattern matching of strings.
There are several ways to create RegExp objects:
1. Implicit creation of RegExp objects
It is created in the form of / pattern/[flag];
Note: Patterns are necessary and flag is optional.
Patterns are written according to the pattern of regular expressions, flag is optional, it has the following main identification
Character: g global flag, i ignores case, m is used as multi-line flag.
2. Creating RegExp Objects for Display
It is created in the form of new RegExp ("pattern"["flag"]).
Note: Patterns are necessary and flag is optional.
Patterns are written according to the pattern of regular expressions. Flag is optional. It has the following identifiers: g global flag, i ignoring case, m being used as multi-line flag.
Common methods for RegExp objects
1. Exc () retrieves the specified value in the string and returns the value (null cannot be found)
2. test() retrieves the value specified in the string and returns true or false
test() example
[02.html]
<html>
<head>
<title>RegExp</title>
<script type="text/javascript" language="javascript">
<!--
function test(){
var con=content.innerText;
var myreg=/abc/gi;
if(myreg.test(con)){
alert("Yes abc");
}else{
alert("No, abc");
}
}
//-->
</script>
</head>
<body>
<textarea id="content" rows="10" cols="20"></textarea><br>
<input type="button" value="test" onclick="test()"/>
</body>
</html>
The Method of string Object Relating to Regular Expressions
Common methods
1,match()
The grammatical format is match(reExp)
Similar to the exec method of RegExp objects, it uses regular expression patterns to search strings and returns an array containing search results.
2,search()
The grammatical format is: search(reExp)
It returns the position of the first matched string in the entire searched string when searching with regular expressions
3,replace()
The grammatical format is: replace (reExp, replace Text)
Use regular expression pattern to search for strings and replace the searched contents with specified characters. The return value is a string object containing the replaced contents.
4,split()
The grammatical format is split(regExp) or split (by what character)
Divide a string into an array of strings
Examples of use of search()/match()/replace()
[03.html]
<html>
<head>
<title>RegExp</title>
<script type="text/javascript" language="javascript">
<!--
//search() returns the location where the lookup string appears
var str="Visit W3School!";
alert(str.search(/W3School/));
//match() returns the search for the specified value
function test(){
var con=content.innerText;
var myreg=/abc/gi;
res=con.match(myreg);
for(var i=0;i<res.length;i++){
alert(i+" "+res[0]);
}
}
//replace() Find Replacement
function test2(){
var con1=content.innerText;
var newcon=con1.replace(/sel.value/gi,rec.value);
content2.innerText=newcon;
}
//-->
</script>
</head>
<body>
<textarea id="content" rows="10" cols="20"></textarea><br>
<input type="button" value="test" onclick="test()"/><br>
//Find content <input type="text" id="sel"/><br>
//Replace content <input type="text" id="rec"/><br>
<input type="button" value="replace" onclick="test2()"/>
<textarea id="content2" rows="10" cols="20"></textarea><br>
</body>
</html>
RegExp object attributes are divided into static attributes and instance attributes, so-called static attributes refer to: can be accessed through RegExp. The so-called instance attributes refer to the fact that only the RegExp object instance can be accessed and used.
What are the static properties of RegExp
1. Index is the starting position of the first matching content of the current expression pattern. It counts from 0 and its initial value is -1. The index attribute changes with each successful match.
2. lastindex is the next position of the last character in the first matching content of the current expression pattern, counting from 0
3. input returns the string currently in use
4. leftContext is everything on the left of the last matching string in the current expression pattern
5. Right Context is everything on the right of the last matching string in the current expression pattern
Examples of using static attribute index/leftContext/rightContext
[04.html]
<html>
<head>
<title>RegExp</title>
<script type="text/javascript" language="javascript">
<!--
//Static attribute index/leftContext/rightContext
function test(){
var con=content.innerText;
var myReg=/(\d){4}/gi;
while(res=myReg.exec(con)){
alert("index="+RegExp.index);//index is the value to retrieve the matching location of the retrieved content
alert("lefttext="+RegExp.leftContext);//The leftContext is the content on the left of the matching location of the retrieved content.
alert("righttext="+RegExp.rightContext);//Right Context is the content to the right of the matching location of the retrieved content.
}
}
//-->
</script>
</head>
<body>
<textarea id="content" rows="10" cols="20"></textarea><br>
<input type="button" value="test" onclick="test()"/><br>
</body>
</html>
Special note: RegExp static attributes are used in RegExp. attribute names
*******************************************************************************
Instance properties of RegExp objects
1. Global returns the state (true,false) of the global flag (g) specified when creating the RegExp object instance
2. ignoreCase returns the state (true,false) of the ignreCase flag (i) specified when creating an instance of the RegExp object.
3. MultLine returns the status (true,false) of the multiLine flag (m) specified when creating the RegExp object instance
4. Sorce returns the expression text string specified when creating the RegExp object instance
Syntax of Regular Expressions -- Subexpressions, Captures, Reverse References
Subexpressions, Capture, Reverse Reference
If you think that regular expressions can only retrieve fixed strings or a few consecutive numbers, then you underestimate regular expressions.
Case study:
Give you a string (or an article), please find all four numbers connected together in a substring, and these four numbers.
To satisfy 1, the first is the same as the fourth; 2, the second is the same as the third, such as 1221, 5775,...

[05.html]
<html>
<head>
<title>RegExp</title>
<script type="text/javascript"language="javascript">
<!--
function test(){
var con=content.innerText;
varmyReg=/(\d)(\d)\2\1/gi;//() wrap it up as a sub-expression, 2 refers back to the second sub-expression, 1 refers back to the first sub-expression
while(res=myReg.exec(con)){
alert(res[0]);
}
}
//-->
</script>
</head>
<body>
<textarea id="content" rows="10"cols="20"></textarea><br>
<input type="button" value="test"onclick="test()"/><br>
</body>
</html>
*******************************************************************************
Case: Find the number in aabbccdd format, and the sub-expression is the formula of ()
[06.html]
<html>
<head>
<title>RegExp</title>
<scripttype="text/javascript" language="javascript">
<!--
function test(){
var con=content.innerText;
varmyReg=/(\d)\1(\d)\2(\d)\3(\d)\4/gi;
while(res=myReg.exec(con)){
alert(res[0]);
}
}
//-->
</script>
</head>
<body>
<textarea id="content" rows="10"cols="20"></textarea><br>
<input type="button" value="test"onclick="test()"/><br>
</body>
</html>
*******************************************************************************
Case: Find out the number of abbba rules
[07.html]
<html>
<head>
<title>RegExp</title>
<scripttype="text/javascript" language="javascript">
<!--
function test(){
var con=content.innerText;
varmyReg=/(\d)(\d)\2\2\1/gi;
while(res=myReg.exec(con)){
alert(res[0]);
}
}
//-->
</script>
</head>
<body>
<textarea id="content" rows="10"cols="20"></textarea><br>
<input type="button" value="test"onclick="test()"/><br>
</body>
</html>
*******************************************************************************
Case: The first five arbitrary digits and the last nine digits of 12321-444999111 should be written in accordance with the rules.
[08.html]
<html>
<head>
<title>RegExp</title>
<scripttype="text/javascript" language="javascript">
<!--
function test(){
var con=content.innerText;
varmyReg=/(\d){5}\-(\d)\2\2(\d)\3\3(\d)\4\4/gi;
while(res=myReg.exec(con)){
alert(res[0]);
}
}
//-->
</script>
</head>
<body>
<textarea id="content" rows="10"cols="20"></textarea><br>
<input type="button" value="test"onclick="test()"/><br>
</body>
</html>Grammar of Regular Expressions--Detailed Explanation of Metacharacters
Meta character
If you want to use regular expressions flexibly, you need to understand the functions of various meta-characters, which can be roughly divided into:
1. Qualifiers; 2. Selection of matchers; 3. Grouping and backward references; 4. Special characters; 5. Character matchers; 6. Locator
Metacharacter -- Qualifier
Used to specify how many consecutive occurrences of characters and combinations preceding them occur
{n} Note: n denotes the number of occurrences. For example, a {3}, 1 {4}, (d) {2}
But here's a point to note: what would happen if 1 {3} matched 1111111111? 111111
Metacharacter -- Qualifier
{n,m} indicates that n represents at least n occurrences and at most M occurrences. For example, a {3,4}, 1 {4,5}, ( d) {2,5}
Let's look at 1 {3,4} to match 1111111111. What will happen? 1111111
js uses the principle of greedy matching in default matching, that is, matching as many strings as possible.
Metacharacter -- Qualifier
+ Description: +Represents the occurrence of one to any number of times. For example, / a+/gi, / 1+/gi, /(d)+/gi
Look at what happens if / 1+/gi matches 1111111111. One million one hundred and eleven thousand one hundred and eleven
Metacharacter -- Qualifier
* Description: * Represents zero to any number of occurrences. For example, / a*/gi,/1*/gi,/(\d)*/gi
See what happens if / a1*/gi matches a111? A111
Metacharacter -- Qualifier
Description: 0 to any number of occurrences. For example, / a?/ gi, / 1?/ gi, / ( d)?/ GI
Look at / a1?/gi to match a111, what will happen? A1
Meta Character -- Character Matching Character
[a-z] Description: [a-z] means that any character in A-Z can be matched. For example: /[a-z]/gi,/[a-z]{2}/gi
Look at what happens when /[A-Z]/gi matches allc8. a l l c
Meta Character -- Character Matching Character
[A-Z] means that any character in A-Z can be matched
[0-9] means that any character in 0-9 can be matched
Meta Character -- Character Matching Character
[^a-z] states: [^a-z] means that any character that is not A-Z can be matched.
For example, /[^a-z]/gi,/[^a-z]{2}/gi
Look at the results of /[a-z]/gi matching allc8. a l l c
What will happen with /[^a-z]{2}/gi? No result
What will happen with /[^ a-z]/gi? Eight
Meta Character -- Character Matching Character
[^A-Z] indicates that it can match any character other than A-Z.
[^ 0-9] means that any character other than 0-9 can be matched
Meta Character -- Character Matching Character
[abcd] means that any character in ABCD can be matched.
[^ abcd] means that any character that is not ABCD can be matched.
Of course, the abcd above can be modified according to the actual situation to meet your needs.
Meta Character -- Character Matching Character
\ d means any number that can match 0-9, equivalent to [0-9]
\ D means that any number other than 0-9 can be matched, equivalent to [^ 0-9]
\ w matches any English character, number and underscore five, equivalent to [a-zA-Z0-9_]
\ w equals [^ a-zA-Z0-9] and w is just the opposite.
\ s matches any blank characters (spaces, tabs, etc.)
\ s matches any non-blank character, as opposed tos
Match all characters except n, and use if you want to match yourself.
Think: Write a regular expression that matches any three consecutive characters /([ d D]) 1 {2}/ GI
Metacharacters -- Special Character Matching
In character, you may encounter special characters. In this case, regular expressions match the X of x n by x n is fixed and N is a hexadecimal number. For example, x 21 is to match the character of ascii code table, hexadecimal is 21. Look up the table.
Metacharacter -- locator
Locator is also useful for specifying the location of the string to be matched, such as at the beginning or end of the string, which must be mastered.
^ Symbol Description: Matches the Starting Position of the Target String
For example /^ han/gi to match "hanshunping han", see what the results will be? Han
A matching string appears at the beginning to get the value
Symbol Description: Matches the end position of the target string.
For example, / han$/gi matches "hanshunping han" to see what happens? Han
A matching string appears at the end to get the value
Metacharacter -- locator
\ b symbol description: matching the boundaries of the target string.
The boundary of this string is a little hard to understand, for example:
For example, / han B / GI matches "hanshunping sphan nnhan" and we will match "hanshunping sphan nnhan", so the boundary of the string here refers to the space between the substrings or the end position of the target string, with special attention to: there is no starting position of the target string.
\ Symbol B: Matches the non-boundary of the target string.
This is just the opposite of b, and it will not be repeated. Look at the case:
For example, / han B / GI to match "hanshunping sphan nnhan" will match "hanshunping sphan nnhan"
Metacharacters -- escape symbols\
\ Symbol Description: When we use regular expressions to retrieve some special characters, we need to use escape symbols, otherwise we can not retrieve the results, or even report errors.
Case study:
How about matching "abc $(" with /$/ gi? Return empty
What happens when /(/ gi) matches "abc$("? Report errors
Metacharacters -- escape symbols\
The characters requiring escape symbols are as follows:
. * + ( ) $ / \ ? [ ] ^ { }
Metacharacters -- Select matchers
Sometimes, when matching a string, it is selective, that is, it can match either this or that, which requires the use of selection matching symbols.|
The choice of matching symbols is more understandable. The case illustrates that:
What will happen if /(han | Han) / gi is used to match "hanshunping Han Shunping"? Han Han
Case study: Give you a string. Would you please verify that the string is an e-mail?
[09.html]
<html>
<head>
<title>RegExp--Verify mail format</title>
<script type="text/javascript" language="javascript">
<!--
function test(){
var con=content.value;
alert(con);
var myReg=/^[a-zA-Z0-9_-]+@([a-zA-Z0-9]+\.)+([a-zA-Z]){2,3}$/;
if(myReg.test(con)){
alert("Correct format!");
}else{
alert("Format error!");
}
}
//-->
</script>
</head>
<body>
<input id="content" type="text" />
<input type="button" value="Verify mail format" onclick="test()"/><br>
</body>
</html>*******************************************************************************
Case study: Give you a string. Would you please verify that the string is an ID card?
[10.html] Second Generation Identity Card Verification
<!DOCTYPE html>
<html>
<head>
<title>RegExp--Second Generation Identity Card Verification.html</title>
<meta name="keywords" content="keyword1,keyword2,keyword3">
<meta name="description" content="this is my page">
<meta name="content-type" content="text/html; charset=">
<!--<link rel="stylesheet" type="text/css" href="./styles.css">-->
<script type="text/javascript" language="javascript">
<!--
function idCard(){
area={11:"Beijing",12:"Tianjin",13:"Hebei",14:"Shanxi",15:"Inner Mongolia",21:"Liaoning",22:"Jilin",23:"Heilongjiang",31:"Shanghai",32:"Jiangsu",33:"Zhejiang",34:"Anhui",35:"Fujian",36:"Jiangxi",37:"Shandong",41:"Henan",42:"Hubei",43:"Hunan",44:"Guangdong",45:"Guangxi",46:"Hainan",50:"Chongqing",51:"Sichuan",52:"Guizhou",53:"Yunnan",54:"Tibet",61:"Shaanxi",62:"Gansu",63:"Qinghai",64:"Ningxia",65:"Xinjiang",71:"Taiwan",81:"Hong Kong",82:"Macao",91:"abroad"}
var idInfo=idNumber.value;
var idReg=/^[1-9]\d{5}[1-2](9|0)\d\d[0-1]\d[0-3]\d{4}(\d|x)$/;
//Determine whether the length and format of the input ID are correct
if(!idReg.test(idInfo)||idInfo==""){
alert("Cannot be empty or input incorrect!Please check and re-enter!");
}else{
//Judging the Illegality of ID Number by Area Number
var myArea=idInfo.substring(0,2);//Only the first two provinces are judged. Interested friends can add city and county judgements.
if(area[parseInt(myArea)]==null){
alert("Illegal Second Generation Identity Card!");
}
//Remove sex
var mySex=idInfo.substring(16,17);
//Remove birthday
var myDate=idInfo.substring(6,14);
alert("ID card No."+idInfo+" Place of origin:"+area[parseInt(myArea)]+" Gender:"+(mySex%2?"male":"female")+" Birthday:"+myDate);
}
}
//-->
</script>
</head>
<body>
<input id="idNumber" type="text" />
<input type="button" value="Second Generation Identity Card Verification" onclick="idCard()"/>
</body>
</html>