preface
Java thread pool is one of the foundations that must be mastered in interview and work. Using thread pool can better plan the CPU utilization of applications and improve the fluency of application operation. This article will explore the application and principle of thread pool in the future.
Through this article, you will learn:
1. Why do I need a thread pool
2. Implement a simple thread pool yourself
3. Thread pool principle
4. Summary
1. Why do I need a thread pool
Origin of nouns
Pool, as its name implies: it is a place to hold a pile of things. When necessary, take things from the pool. When not in use, put them in the pool. It can be seen that the storage and access are very convenient.
Thread pool analogy
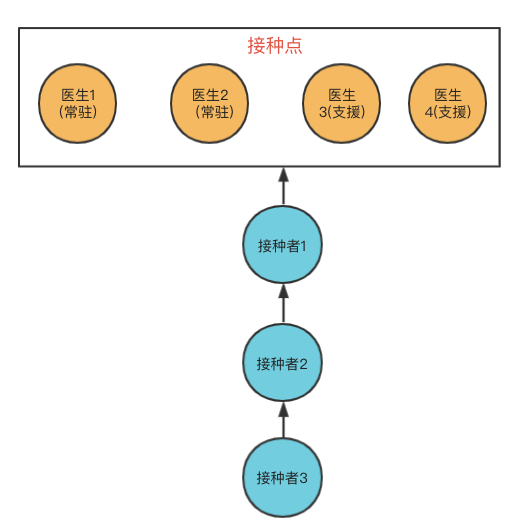
When we are vaccinating, if we want to vaccinate at any time, when we go to the hospital, the doctor needs to change into protective clothing, wear gloves, prepare the vaccine, prepare computer records, etc.
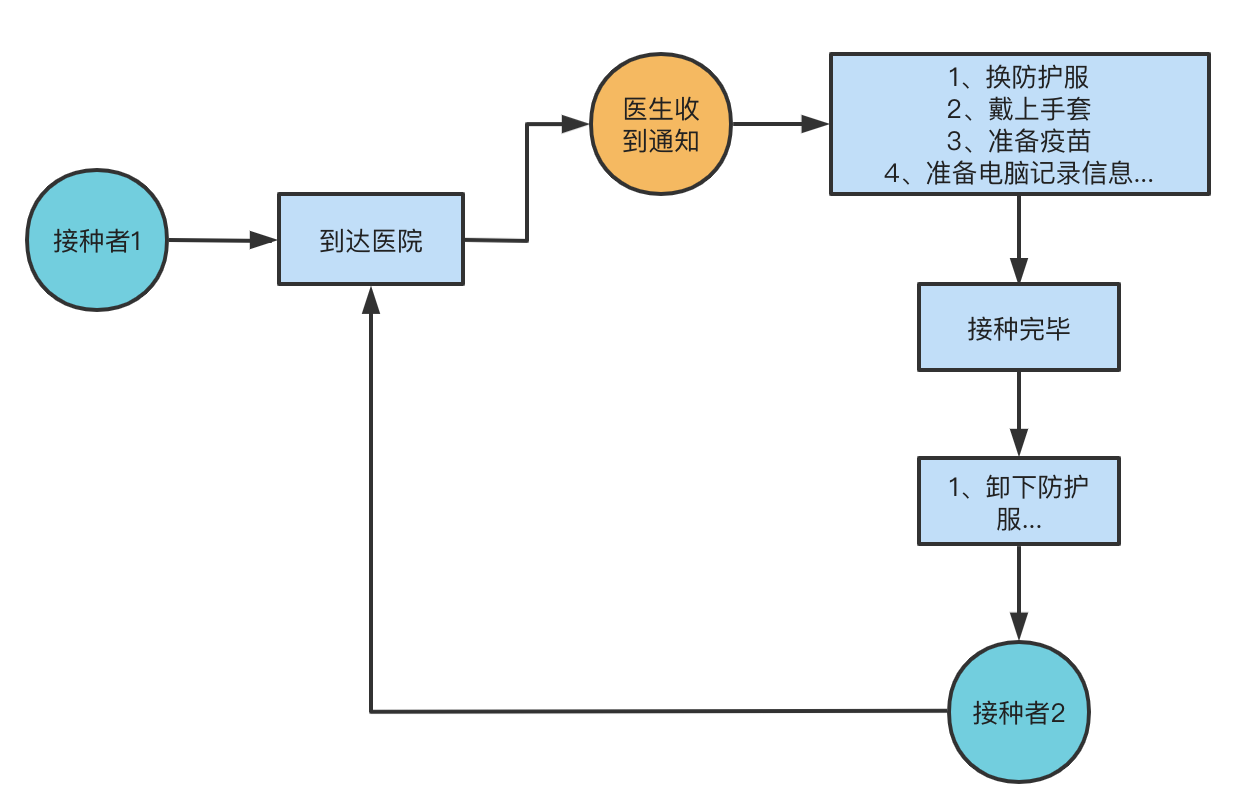
When vaccinator 1 arrives at the hospital, the doctor carries out various preparations. Finally, after vaccinator 1 is vaccinated, remove the equipment. At this time, vaccinator 2 also arrived at the hospital, and the doctor needed to change his equipment. It can be seen that the preparation work of doctors is time-consuming and laborious. If vaccinated at a fixed time, doctors do not need to change equipment frequently, which not only saves doctors' time, but also shortens the waiting time of vaccinators. As shown below:
Why do I need a thread pool
As can be seen from the above example, because the preparation of doctors is time-consuming and laborious, they should focus on playing for a period of time before changing equipment. The same is true for threads in computers:
1. Thread switching requires context switching, which involves system calls and occupies system resources.
2. Thread switching takes time. You can't really do anything until you successfully create a thread.
3. Unable to effectively manage threads after threads are turned on.
For the above reasons, thread pool needs to be introduced.
2. Implement a simple thread pool yourself
Simple Demo
private void createThread() {
Thread thread = new Thread(() -> {
System.out.println("thread running...");
});
thread.start();
}
The thread ends after execution. Now you want it not to end:
private void createThread() {
Thread thread = new Thread(() -> {
while (true) {
System.out.println("thread running...");
}
});
thread.start();
}
The thread is running all the time. If an external wants to submit Runnable to it for operation, it needs to have a shared variable. Select the queue as the shared variable:
class ThreadPool {
public static void main(String args[]) {
ThreadPool threadPool = new ThreadPool();
threadPool.createThread();
threadPool.startRunnable();
}
BlockingQueue<Runnable> shareQueue = new LinkedBlockingQueue<>();
private void createThread() {
Thread thread = new Thread(() -> {
while (true) {
try {
Runnable targetRunnable = shareQueue.take();
targetRunnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread.start();
}
public void startRunnable() {
for (int i = 0; i < 10; i++) {
int finalI = i;
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("implement runnable " + finalI);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
System.out.println("Put in queue runnable " + i);
shareQueue.offer(runnable);
}
}
}
Only one thread is opened in the above Demo, which is an endless loop. In the thread body, take out the Runnable from the shared queue shareQueue. If there are elements, take them out for execution. If there are no elements, block and wait.
The external caller can store the Runnable in the shared queue and wait for the thread to execute the Runnable.
Thus, only one thread is running, but different tasks can be executed, and the situation that each task needs to be started for execution is avoided.
3. Thread pool principle
Basic composition of thread pool
Although the above implements thread pool, it is a beggar version, which obviously shows many defects:
1. The thread has been running and cannot be stopped.
2. Only one thread is executing tasks, and other tasks need to be queued.
3. The queue expands infinitely and consumes memory.
4. Other disadvantages
As a general tool library, let's see how Java thread pool is implemented.
The core of the thread pool revolves around an atomic variable: ctl
#ThreadPoolExecutor.java
//Initialization status: the thread pool is running, and the current number of threads is 0
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
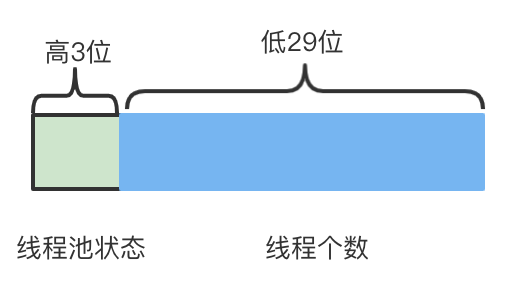
//The number of bits used to represent the number of threads, which is 29
private static final int COUNT_BITS = Integer.SIZE - 3;
//Maximum number of threads in thread pool, (1 < < 29) - 1
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// Five states of thread pool
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
//ctl is an int type with 32 bits in total, including two values. The upper 3 bits represent the thread pool status, and the lower 29 bits represent the number of threads
//Extract thread pool status
private static int runStateOf(int c) { return c & ~CAPACITY; }
//Get the number of threads
private static int workerCountOf(int c) { return c & CAPACITY; }
//Store the status and the number of threads in int
private static int ctlOf(int rs, int wc) { return rs | wc; }
Why 29 bits are required to represent the number of threads? Because there are five thread pool States, and three bits are required to distinguish these five states.
Thread pool execution task
ThreadPoolExecutor is the core class of thread pool. It implements the Executor interface and rewrites the execute(Runnable) method.
When the external caller needs the thread pool to execute a task, he only needs to call the ThreadPoolExecutor.execute(Runnable) method. Runnable will be executed in a thread body in the thread pool, that is, the task has been executed once.
#ThreadPoolExecutor.java
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//Get ctl variable value
int c = ctl.get();
//The number of threads currently running does not exceed the number of core threads
if (workerCountOf(c) < corePoolSize) {
//The newly added task will create a new core thread to execute it
if (addWorker(command, true))
return;
c = ctl.get();
}
//If the thread pool is still running, add tasks to the waiting queue
if (isRunning(c) && workQueue.offer(command)) {
//Get the ctl variable value again
int recheck = ctl.get();
//Check again if the thread pool is running
if (! isRunning(recheck) && remove(command))
//If it is not running, the task will be removed from the queue. If the removal is successful, the reject policy (similar to the defined callback) will be executed
reject(command);
//If no thread is currently running
else if (workerCountOf(recheck) == 0)
//Add a new non core thread to execute a new task. Note that the task is placed in the queue at this time, so
//The first parameter here is null
addWorker(null, false);
}
//After joining the queue fails, try to directly create a new non core thread to execute the task
else if (!addWorker(command, false))
//Execute reject task
reject(command);
}
It can be seen that ctl values are judged many times because multiple threads may operate ctl values at the same time. ctl is of AtomicInteger type and CAS is used at the bottom. We know that CAS is unlocked, so we need to judge its state circularly.
Thread pools rely on CAS in many places. It can be said that if you understand CAS, most of you can understand thread pools.
CAS can be viewed step by step: Application and principle of Java Unsafe/CAS/LockSupport
The above codes are shown in the flow chart as follows:
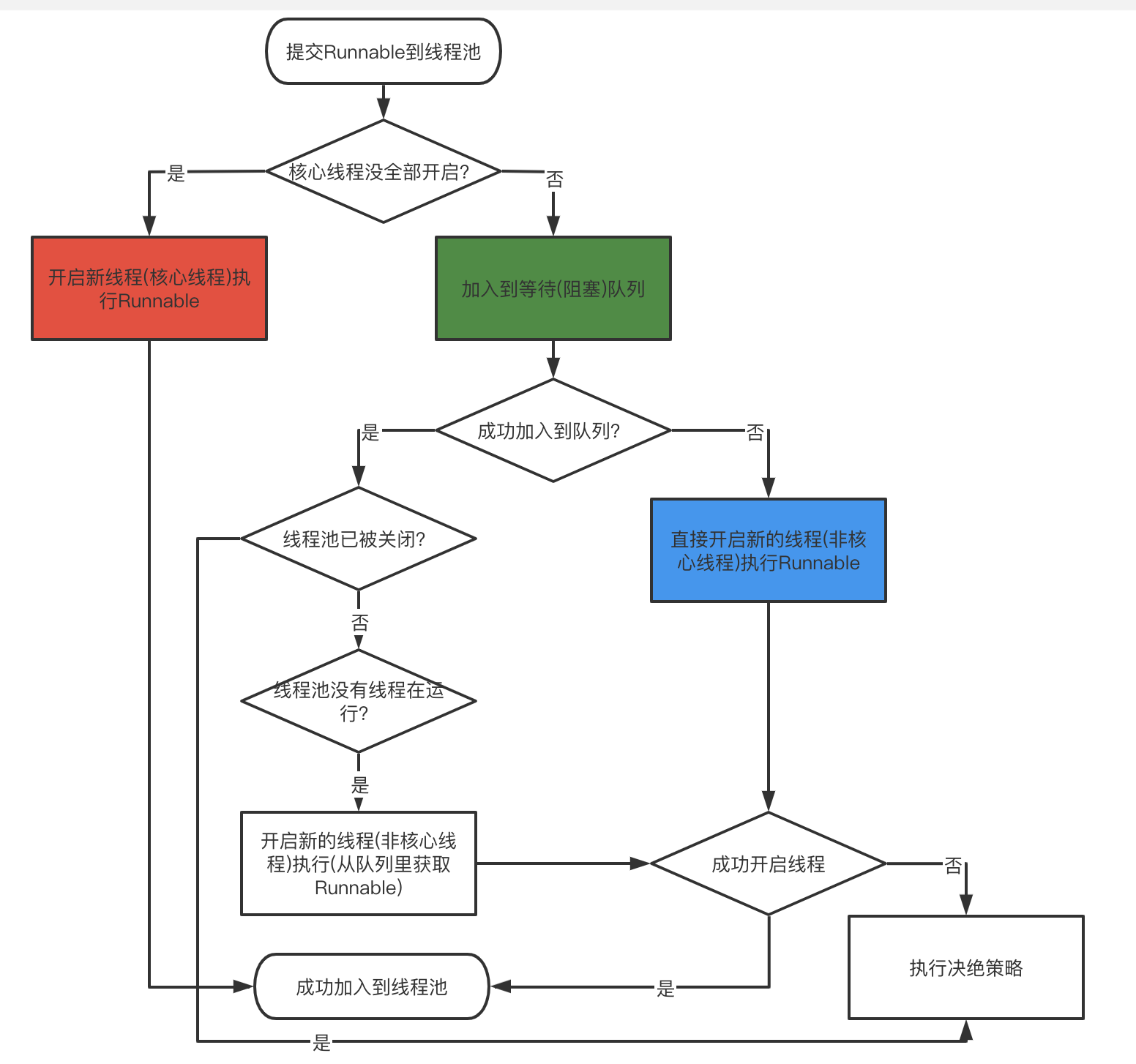
Several concepts of thread pool
The above process involves several concepts:
1. Core threads, number of core threads
2. Non core thread
3. Maximum number of threads
3. Waiting queue
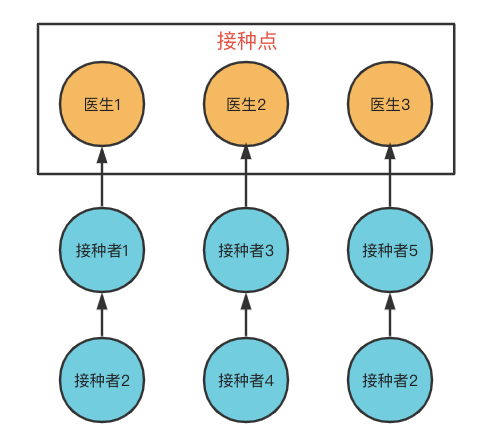
In the computer world, analogies can often be found in the real world, or take vaccination as an example:
1. Only four doctors at an inoculation site can vaccinate. These four doctors can be compared with four threads, because they are resident at the inoculation site, so core doctors – > core threads.
2. Four doctors can only vaccinate four people at the same time. When the number of vaccinations at the same time exceeds four, they need to wait in order. This waiting queue is called waiting queue.
3. One day, a lot of people to be vaccinated suddenly came to the vaccination site. The queue was very long, so they really couldn't wait, so they needed the support of doctors from other places. These doctors who come here are not resident here. They will go back after the support is completed, so they can be compared to non core threads.
4. Core thread + non core thread = = maximum number of threads (similar to the maximum number of vaccinated doctors in the vaccination point).
5. Of course, some vaccination sites are short of doctors' resources. The team is too long and there is no doctor from other places to support. They can't finish the fight in a day. Therefore, the remaining vaccinators are told that they can't fight today. Go back. This process can be compared with the rejection strategy. Even if there are other doctors to support, there are still many people waiting for vaccination, which exceeds the vaccination capacity of the vaccination site. At this time, new people waiting for vaccination cannot be vaccinated and will still be rejected.
What is the difference between core threads and non core threads?
1. When the maximum number of core threads is not reached, a new task will try to create a new core thread to execute a new task.
2. The core thread resides in the thread pool and waits for new tasks to be executed unless timeout destruction is set.
3. After the execution of the non core thread, no matter whether the timeout destruction is set or not, as long as there is no task execution, the thread execution will exit.
In fact, the thread pool plays down the concept of thread itself, focusing only on whether the task is executed, rather than which thread the task is executed by. Therefore, the main difference between core threads and non core threads is whether they are resident in the thread pool.
Task execution sequence of core thread, waiting queue and non core thread:

Thread pool management thread
An important method mentioned above: addWorker(xx).
#ThreadPoolExecutor.java
private boolean addWorker(Runnable firstTask, boolean core) {
//Jump marks are rarely used in java, and c/c + + is used more
retry://--------------------(1)
for (;;) {
//Dead loop is mainly used to judge the status of thread pool and the number of threads
int c = ctl.get();
//Fetch thread pool status
int rs = runStateOf(c);
//If the thread pool is already closed / closing, there is no need to add it
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
//Number of fetched threads
int wc = workerCountOf(c);
//At present, the number of core threads needs to be started, and the number of core threads is full (other threads have successfully added tasks to the core thread)
//Or you need to start non core threads, but the total number of threads is exceeded
//In both cases, you will no longer be able to add tasks to the thread pool
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//CAS modifies ctl and increases the count of threads
//If it is not successful (changed by others), continue the cycle
if (compareAndIncrementWorkerCount(c))
break retry;
//Successfully increased count
c = ctl.get(); // Re-read ctl
//If the status has changed, try again
if (runStateOf(c) != rs)
//Jump to the beginning tag
continue retry;
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//Create a Worker, add tasks to the Worker, and create a new thread
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//Thread created successfully
final ReentrantLock mainLock = this.mainLock;//-----------------(2)
//Lock
mainLock.lock();
try {
//Get thread pool status
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
//Add worker to HashSet
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
//Tag added successfully
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
//Officially open thread
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
//Add task success flag to thread pool
return workerStarted;
}
This method has two parameters. The first parameter is Runnable, and the second parameter indicates whether the thread to be added is a core thread.
The above marks two key points:
(1)
Why do you need an endless cycle? Since the ctl variable may be modified by multiple threads, and the ctl is AtomicInteger and the underlying is CAS, it needs to be judged multiple times until the conditions are met.
(2)
Why do I need a lock? Because the worker declares as follows:
private final HashSet<Worker> workers = new HashSet<>();
The collection may be operated by multiple threads, so its add and remove can only be safely operated after locking.
Worker inherits from AQS and uses AQS to implement its own set of locks (similar to ReentrantLock).
The main information stored is as follows:
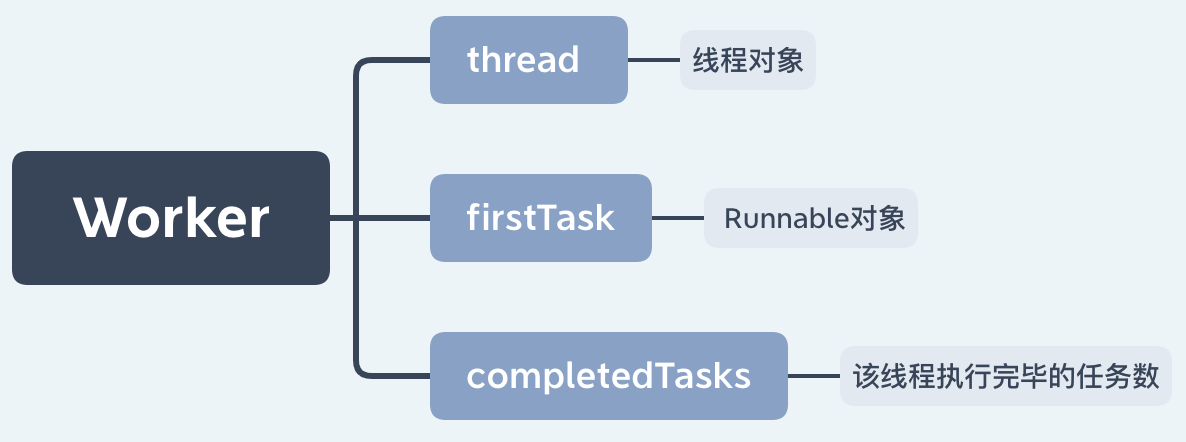
Thread objects are stored in workers, and the thread pool controls the number of core / non core threads by managing workers.
Thread pool management task
Now that the thread has been created, let's see how to execute the task.
The Worker implements the Runnable interface, so the run() method must be rewritten. When constructing the Thread object, the Worker is passed in as the Runnable of the Thread. Therefore, the Runnable actually executed after Thread.start() is the run() method in the Worker, and the method calls runWorker(xx).
Let's take a look at its source code:
#ThreadPoolExecutor.java
final void runWorker(Worker w) {
//Current thread
Thread wt = Thread.currentThread();
//Remove task
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//Two conditions --------- > (1)
while (task != null || (task = getTask()) != null) {
//worker lock
w.lock();------------>(2)
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
//If the thread pool has been stopped and the thread has not been interrupted
//Then interrupt the thread
wt.interrupt();
try {
//Callback before task execution (hook)
beforeExecute(wt, task);
Throwable thrown = null;
try {
//Really perform the task
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//Callback after task execution
afterExecute(task, thrown);
}
} finally {
//Empty
task = null;
//The number of tasks completed by this thread
w.completedTasks++;
//Release lock
w.unlock();
}
}
completedAbruptly = false;
} finally {
//Thread exit execution
processWorkerExit(w, completedAbruptly);
}
}
Two key points are marked on it:
(1)
In the first Demo of implementing thread pool ourselves, we demonstrated how to keep threads running. Here are two judgment conditions:
1. Whether the first task associated with the current worker exists. If so, it will be taken out and run. This judgment corresponds to the scenario of adding a core thread / non core thread (not stored in the queue). That is, when the thread is started, if the task is associated, it will be taken out and executed.
2. When the thread is not associated with the first task, this judgment corresponds to that the thread is not executing for the first time or the thread is executing for the first time (there are tasks in the queue). At this time, the task is taken out of the queue for execution.
The getTask() method is as follows:
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
//The loop is used to determine the thread pool state
for (;;) {
int c = ctl.get();
//Take out status
int rs = runStateOf(c);
//The thread pool is closed or no tasks are waiting
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
//Reduce thread count
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
//Determine whether timeout is required
//1. allowCoreThreadTimeOut externally sets whether to allow timeout to close the core thread
//2. Whether the current number of threads is greater than the number of core threads (that is, the number of non core threads is enabled)
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//There are four combined judgments
//timeout refers to getting whether the queue element has timed out
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
//If a timeout occurs or the queue is empty, try reducing the thread count
//If the count is modified successfully, null is returned
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
//Determines whether to time out to get elements
//If the timeout acquisition element is set, the poll method will return when the timeout is exhausted, and the underlying layer uses LockSupport
//If no timeout is set, the queue is blocked until there are elements in the queue
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
//It's too late to get here
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
It can be seen that:
1. With the help of the blocking queue feature, if the timeout is not set, the core thread will always block in the BlockingQueue.take() method, and then the thread will always be blocked here until a new task is put into the thread pool for execution. This is also why the core thread can reside in the thread pool.
2. When the number of threads exceeds the number of core threads, timed=true, that is, the thread sets a timeout when obtaining queue elements. If the timeout expires and no elements are obtained, the thread will exit execution. This is why non core threads cannot reside in the thread pool.
(2)
Why do I need a lock here?
As mentioned earlier, a lock is required to operate wokers collection: mainLock. Its purpose is to consider the security of adding / deleting collections by multiple threads. Each woker can only be operated by one thread at the same time. It seems that there is no need to lock. In fact, the more important functions of Worker lock are as follows:
Used to skillfully judge whether the thread is running (busy).
When a task is executed, the Runnable.run() method is locked, and the lock is released after execution. Therefore, when it is judged that Woker has not obtained the lock, it indicates that it is waiting to obtain the elements of the queue, and it is idle at this time.
Judging whether the thread is idle or not can be used to provide a basis for the execution of external interrupt thread pool.
4. Summary
So far, we understand the core advantage of thread pool: it does not create threads repeatedly. It relies on the blocking queue feature to make threads resident, as shown in the figure below:

Due to space reasons, the remaining thread pool shutdown, some important runtime states of thread pool, and several simple ways to create thread pool will be analyzed in the next article. Please pay attention!
Demo code If it's helpful, give github a compliment