Article catalog
what's pseudo sharing
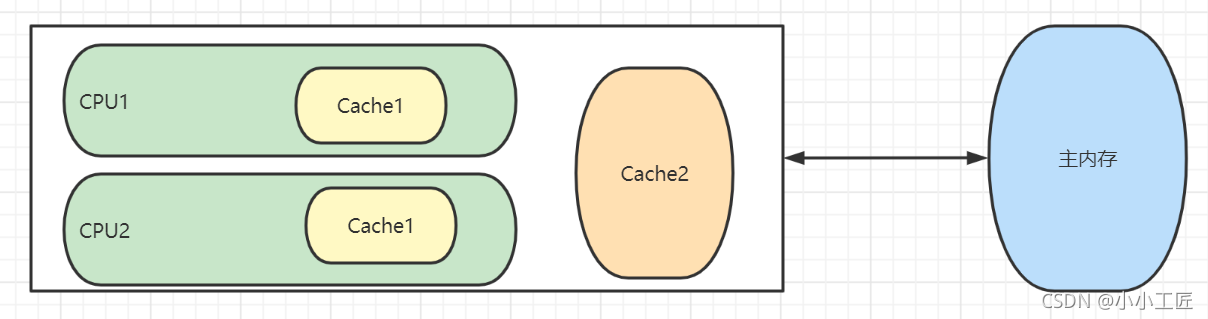
In order to solve the problem of running speed difference between main memory and CPU in computer system, one or more levels of Cache will be added between CPU and main memory. This Cache is generally integrated into the CPU, so it is also called CPU Cache
The following figure shows a two-level Cache structure
The internal cache is stored by rows, and each row is called a cache row. Cache line (as shown in the figure below) is the unit of data exchange between cache and main memory. The size of cache line is generally 2 power bytes.
When the CPU accesses a variable, it will first check whether the variable exists in the CPU Cache. If so, it will be obtained directly from it. Otherwise, it will obtain the variable from the main memory, and then copy the memory of a Cache line size in the memory area where the variable is located to the Cache.
Since memory blocks rather than single variables are stored in the Cache line, multiple variables may be stored in one Cache line. When multiple threads modify multiple variables in a Cache line at the same time, since only one thread can operate the Cache line at the same time, the performance will be reduced compared with putting each variable in one Cache line, which is pseudo sharing
As shown below.
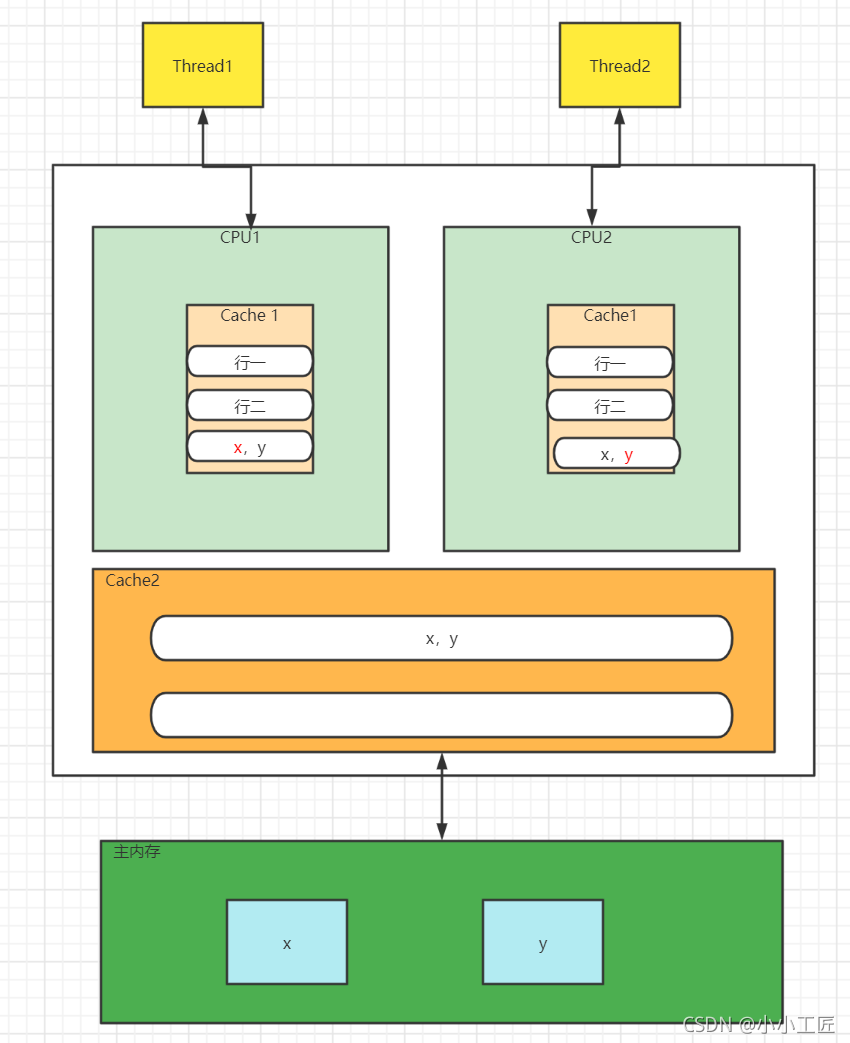
Variables X and y are put into the primary and secondary caches of the CPU at the same time. When thread 1 uses CPU1 to update variable x, it will first modify the cache line of the primary cache variable X of CPU1. At this time, under the cache consistency protocol, the cache line corresponding to variable x in CPU2 will become invalid.
When thread 2 writes to variable x, it can only look in the L2 cache, which destroys the L1 cache. The L1 cache is faster than the L2 cache, which also shows that multiple threads cannot modify the variables in the same cache line in their CPU at the same time. Worse, if the CPU has only L1 cache, it will cause frequent access to main memory.
Why does pseudo sharing occur
Pseudo sharing occurs because multiple variables are put into a cache line, and multiple threads write different variables in the cache line at the same time.
So why are multiple variables put into one cache line? In fact, the unit of data exchange between cache and memory is cache line. When the variable to be accessed by CPU is not found in the cache, the memory with the size of cache line in the memory where the variable is located will be put into the cache line according to the locality principle of program operation.
long a ; long b ; long c ; long d ;
The above code declares four long variables. Assuming that the size of the cache line is 32 bytes, when the CPU accesses variable a and finds that the variable is not in the cache, it will go to the main memory and put variable a and b, c and d near the memory address into the cache line. That is, multiple variables with consecutive addresses may be put into one cache line.
When an array is created, multiple elements in the array will be placed in the same cache line. So, in a single thread, does multiple variables being put into the same cache line have an impact on performance? In fact, it is beneficial for code execution to put array elements into one or more cache lines during single thread access, because the data is in the cache, and the code execution will be faster.
Let's look at a code
[Code1]
/**
* @author Small craftsman
* @version 1.0
* @description: TODO
* @date 2021/11/28 21:44
* @mark: show me the code , change the world
*/
public class TestWGX {
static final int LINE_NUM = 1024;
static final int COLUM_NUM = 1024;
public static void main(String[] args) {
long[][] array = new long[LINE_NUM][COLUM_NUM];
long startTime = System.currentTimeMillis();
for (int i = 0; i < LINE_NUM; ++i) {
for (int j = 0; j < COLUM_NUM; ++j) {
array[i][j] = i * 2 + j;
}
}
long endTime = System.currentTimeMillis();
long cacheTime = endTime - startTime;
System.out.println("cache time:" + cacheTime);
}
}[Code2]
/**
* @author Small craftsman
* @version 1.0
* @description: TODO
* @date 2021/11/28 22:05
* @mark: show me the code , change the world
*/
public class TestWGX2 {
static final int LINE_NUM = 1024;
static final int COLUM_NUM = 1024;
public static void main(String[] args) {
long[][] array = new long[LINE_NUM][COLUM_NUM];
long startTime = System.currentTimeMillis();
for (int i = 0; i < COLUM_NUM; ++i) {
for (int j = 0; j < LINE_NUM; ++j) {
array[j][i] = i * 2 + j;
}
}
long endTime = System.currentTimeMillis();
System.out.println("no cache time:" + (endTime - startTime));
}
}Code1 within 5ms
Code2 above 5ms
Code (1) executes faster than code (2) because the memory addresses of the array elements in the array are continuous. When accessing the first element of the array, several elements after the first element will be put into the cache line. In this way, when accessing the array elements in sequence, they will be hit directly in the cache, so they will not be read from the main memory, and the same is true for subsequent accesses.
In other words, when sequentially accessing the elements in the array, if the current element does not hit in the cache, several subsequent elements will be read from the main memory to the cache at once, that is, one memory access can make subsequent accesses hit directly in the cache. The code (2) accesses the array elements in a skip manner, not in order, which destroys the locality principle of program access, and the cache is capacity controlled. When the cache is full, the cache line will be replaced according to a certain elimination algorithm, which will cause the elements of the cache line replaced from the memory to be replaced before they are read.
Therefore, the sequential modification of multiple variables in a cache line under a single thread will make full use of the locality principle of program operation, so as to speed up the operation of the program. When multiple variables in a cache line are modified concurrently under multithreading, the cache line will compete, which will reduce the performance of the program.
How to avoid pseudo sharing
Before JDK 8, this problem was generally avoided by byte filling, that is, when creating a variable, the filling field is used to fill the cache line where the variable is located, so as to avoid storing multiple variables in the same cache line.
public final static class FilledLong {
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6;
}If the cache behavior is 64 bytes, we fill the FilledLong class with 6 long variables. Each long variable occupies 8 bytes, plus 8 bytes of value variable, a total of 56 bytes. In addition, FilledLong here is a class object, and the object header of the bytecode of the class object occupies 8 bytes, so a FilledLong object will actually occupy 64 bytes of memory, which can be put into a cache line.
JDK 8 provides a sun.misc.contented annotation to solve the problem of pseudo sharing. Modify the above code as follows.
@sun.misc.Contended
public final static class FilledLong {
public volatile long value = 0L;
}Here, annotations are used to modify classes. Of course, they can also modify variables, such as in the Thread class.
/** The current seed for a ThreadLocalRandom */
@sun.misc.Contended("tlr")
long threadLocalRandomSeed;
/** Probe hash value; nonzero if threadLocalRandomSeed initialized */
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
/** Secondary seed isolated from public ThreadLocalRandom sequence */
@sun.misc.Contended("tlr")
int threadLocalRandomSecondarySeed;These three variables in the Thread class are initialized to 0 by default. These three variables will be used in the ThreadLocalRandom class. Later chapters will specifically explain the implementation principle of ThreadLocalRandom.
By default, the @ contained annotation is only used for Java core classes, such as those under rt package. If the class under the user class path needs to use this annotation, you need to add the JVM parameter: - XX: - restrictcontained. The filling width is 128 by default. To customize the width, you can set the - XX: contentedpaddingwidth parameter.
Summary
Here we mainly describe how pseudo sharing is generated and how to avoid it. We prove that pseudo sharing occurs only when multiple variables in the same cache line are accessed in multiple threads. Accessing multiple variables in a cache line in a single thread will accelerate the operation of the program. Understanding this knowledge is helpful to understand the implementation principle of LongAdder.