Or that sentence, I always feel tired when I read what others have written. Once I paste the code, pack it up, throw it on Hadoop and run it all over???? Writing a test sample program (Hello World in MapReduce) is so troublesome!!!? I also typed the Jar package locally and passed it to Linux. Finally, I ran the jar package with the jar command and typed in and out parameters. I can't stand it. I'm in a hurry. .
.
I just want to know how MapReduce works, and when I know it, I want to run the whole MapReduce calculation process in Java program locally. Is that difficult? Searching the whole network, I found that a few of them are what I want (or may be missing), which can be referred to, but they are scattered and not suitable for entry-level "players" like me. Finally, I made up my mind to watch videos to collect information, poke the principle of MapReduce from beginning to end, and how to write map and reduce functions for a text locally. The number of occurrences of words in the file is counted and the results are output to the HDFS file system.
Note: At the end of this article, a self-written set will be attached. HDFS file manipulation Java API API is still improving.
Effect:
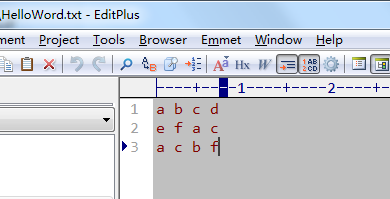
1. HelloWorld text
a b c d e f a c a c b f
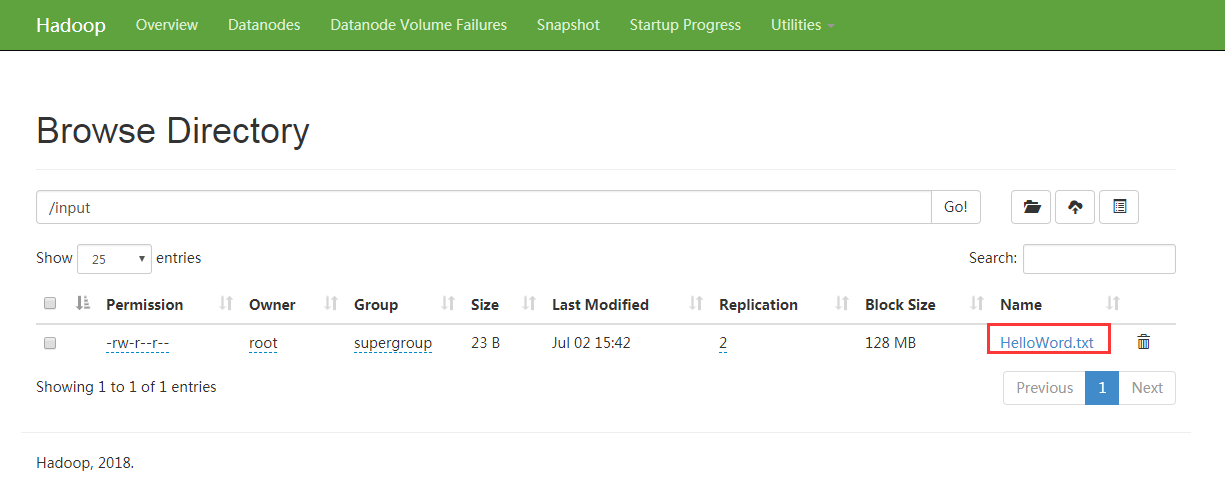
2. Upload to the intput directory of HDFS
3. Client submits Job and executes MapReduce
Output results of A and map
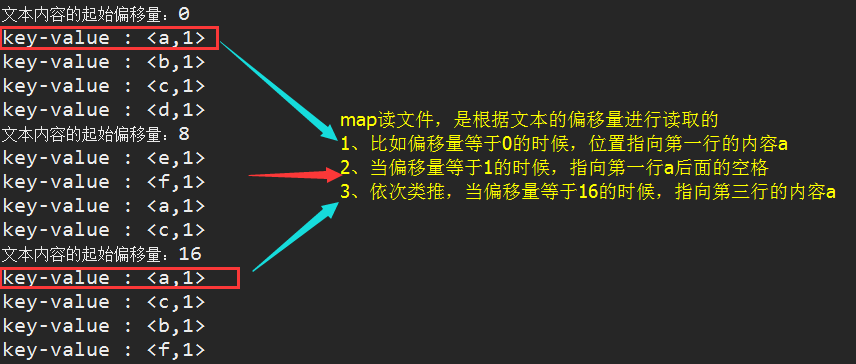
B. Input results of reduce (output of previous map)

C, reduce calculation results (code implementation details are ignored for the time being, as will be mentioned in the article)

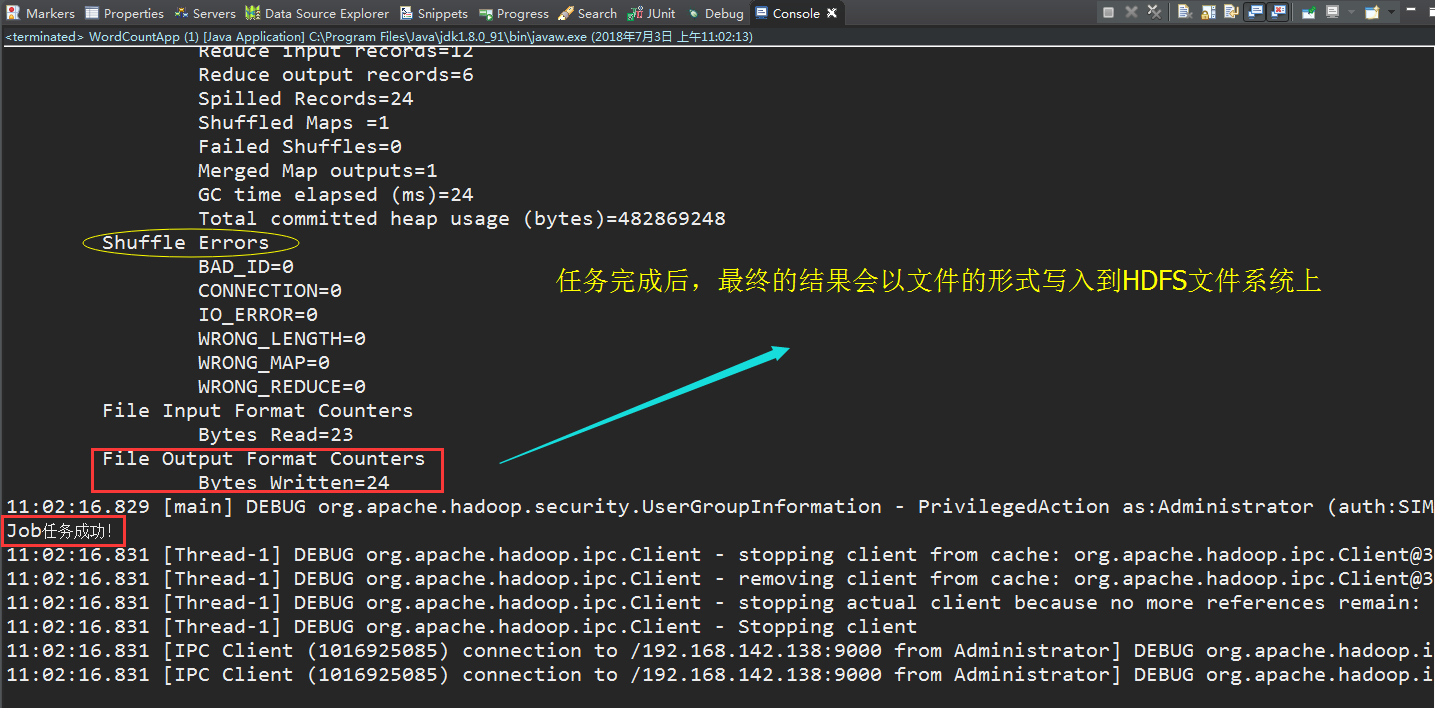
D. Finally, the task is completed and the result file is written by HDFS.

Partitions in MapReduce default to hash partitions, but we can also write demo ourselves to override the getPartiton method of the Partitioner class, as follows:
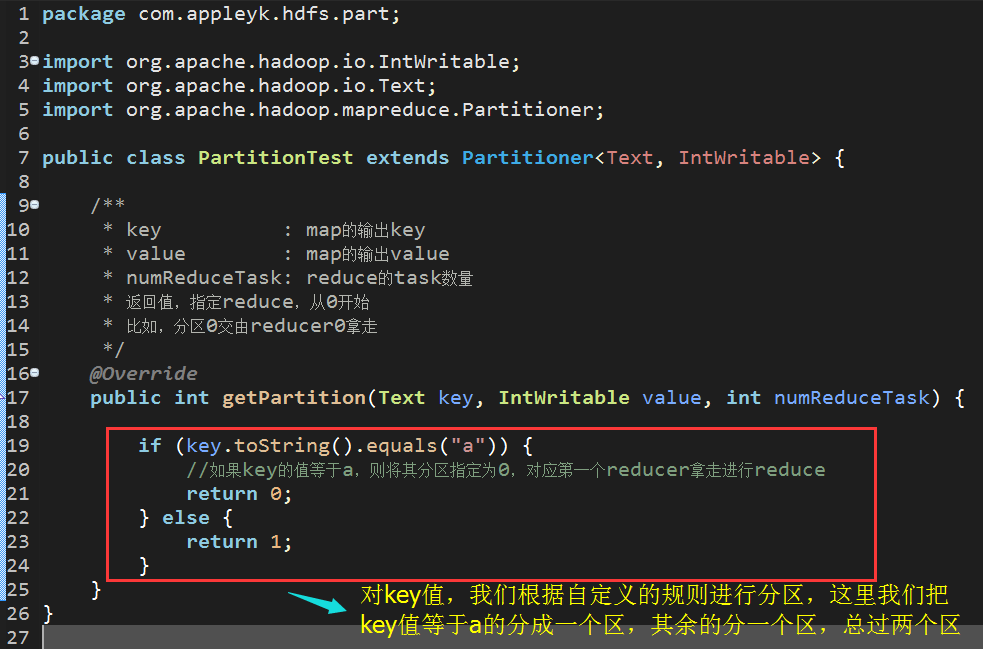
After the partition rule is determined, we need to specify the partition class of map task of client Job and set the number of reducer s as follows

Finally, submitting Job to run MapReduce once has the following effect:
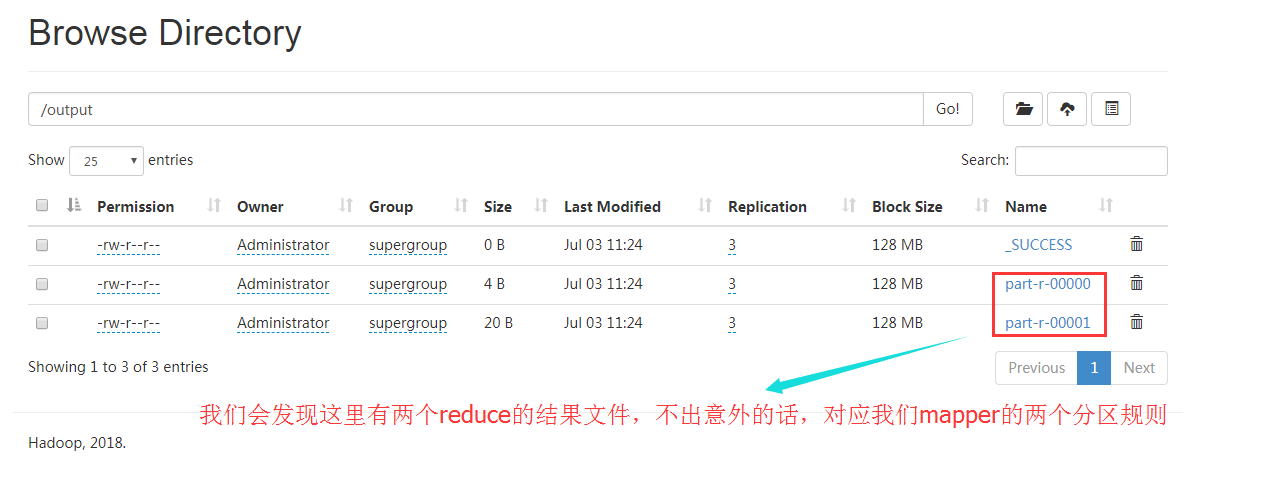
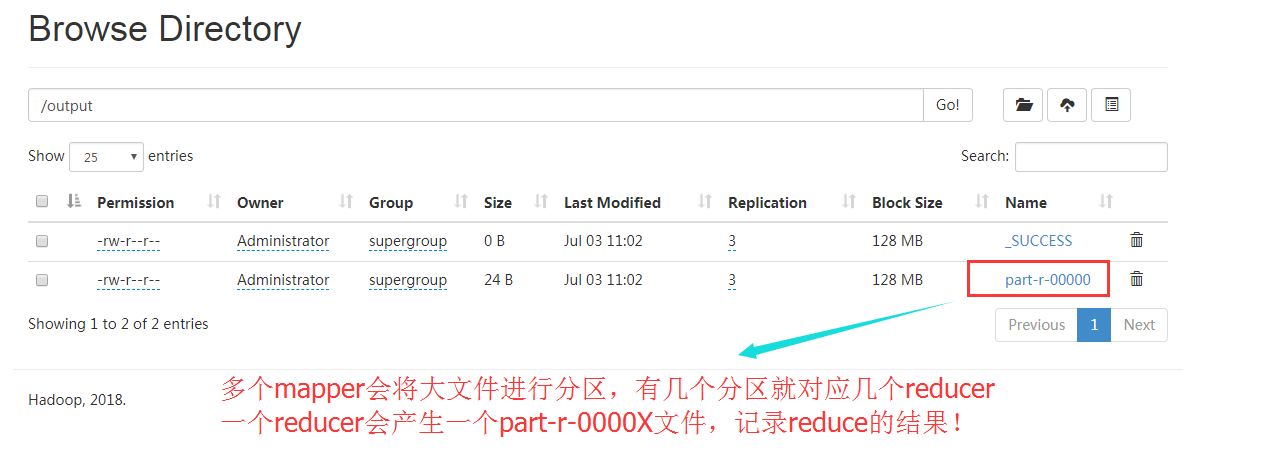
We download the files *. * - 00000 and *. * - 00001 to the local area respectively, and verify the results. The results are as follows:
The reduce result file corresponding to partition 0 is as follows:
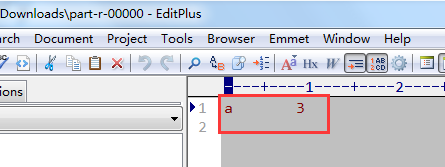
The reduce result file corresponding to partition 1 is as follows:
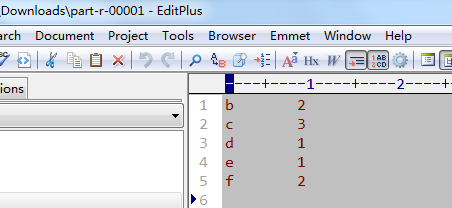
So far, I've shown you how MapReduce works before and after MapReduce, what happened in MapReduce, and what happened in the end. It's very intuitive, but notice that MapReduce can only help you understand what MapReduce can do in the end. How does MapReduce work? I'll continue to talk about it in the next section. Besides, Expo. At the end of this article, I will attach the full demo used in this blog demo.
I. What is MapReduce
We're going to count all the books in the library. You count shelves 1, I count shelves 2, and he counts shelves 3. That's called Map.
Now let's add all the books we've counted together. It's called Reduce.
Together, it's MapReduce!!!
For more details, please check: MapReduce is a programming model for parallel operations on large data sets (larger than 1TB)
MapReduce execution process
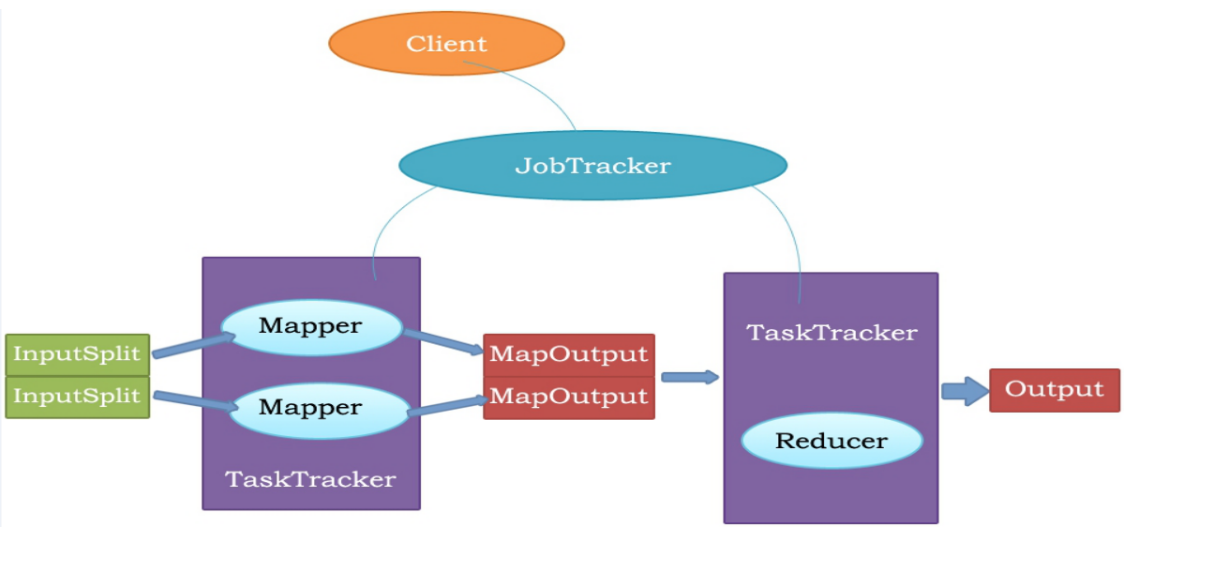
Supplement:
1. JobTracker corresponds to NameNode and TaskTracker corresponds to DataNode.
2. JobTracker is a master service. After the software starts, JobTracker receives Job and is responsible for scheduling each sub-task task task of Job to run on TaskTracker and monitoring them. If a failed task is found, JobTracker will run it again. In general, JobTracker should be deployed on a separate machine.
Client: The client submits a Job to JobTracker
JobTracker: Schedule each mapper and reducer of Job, run on TaskTracker, and monitor them
Mapper: Get your own InputSplit (input content), map, output MapOutPut (map output content)
Reducer: Get MapOutPut as your own ReduceInput, reduce the calculation, and finally output the OutPut results
3. The Working Principle of MapReduce
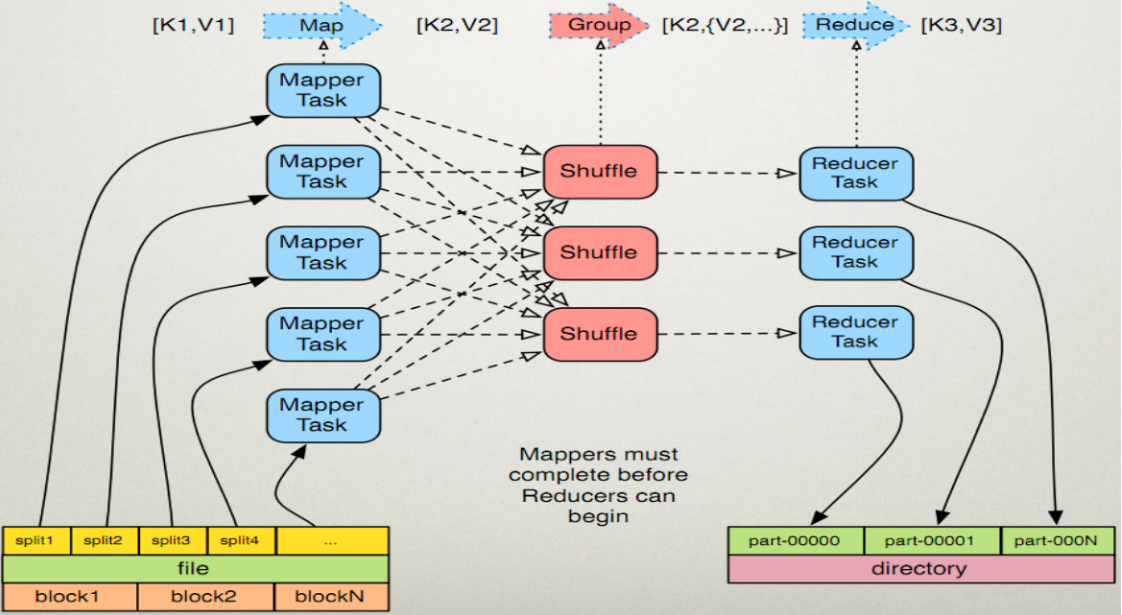
Note: Before reduce r starts reducing, you must wait for mapper to complete the map before you can start
Step 1: Job reads files that exist on the HDFS file system as Mapper's input (key, value) and handles them to Mapper Task after special processing (map programming implementation).
Step 2: Mapper Task shuffle s the map data, including partitioning, sorting or combining.
Step 3: Mapper provides the shuffle output (key, values) to the corresponding Reducer Task, which is removed by Reducer.
Step 4: Reducer takes the output of Mapper from the previous step and reduce s it (client programming implementation)
Step 5: Reducer completes reduce calculation and writes the results to HDFS file system. Different reducers correspond to different result files.
The rough drawings (drawn by myself) are as follows
Introduction of Shuffle Process
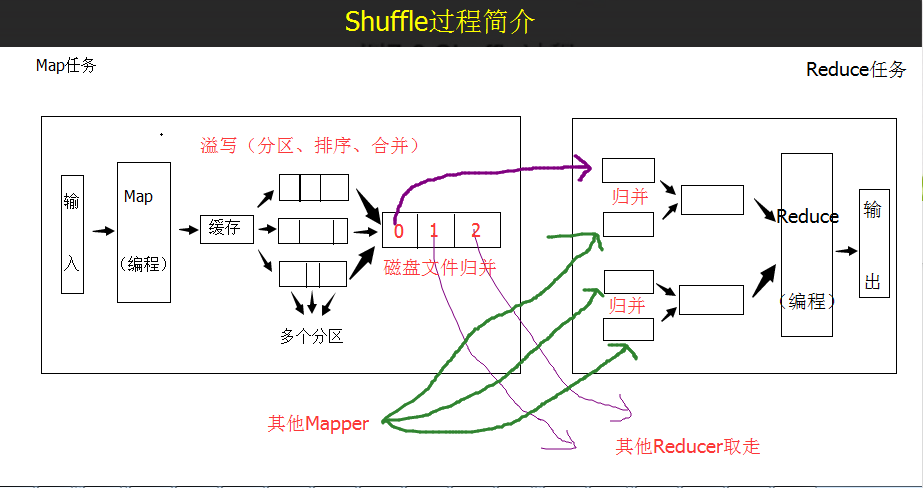
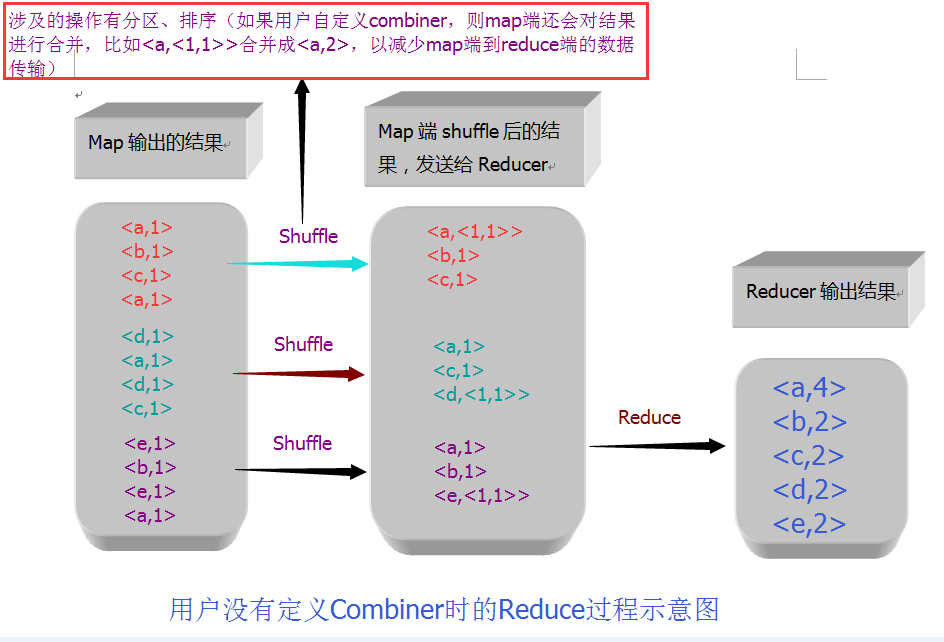
The partition in the shuffle process should be noticed in the figure above. It is intuitively illustrated in the figure that Mapper will eventually take the key-value key values out of the cache (the input data overflows) and write the disk files according to the partition rules (note: the disk files here are not files on the HDFS file system, and the contents of the written files are already there). After sorting, the key-value data files of different partitions will be merged. Finally, different Reduce tasks will be assigned to reduce. If there are multiple Mappers, the content acquired by Reducer from the Map side will need to be merged again (merging the output of different Mappers but belonging to the same partition, and shuffle the output of the same partition at the reduce side, Write to the disk file, and finally reduce the calculation. The result of reduce calculation is finally output to the HDFS file system in the form of a file.
5. Shuffle process on Map side
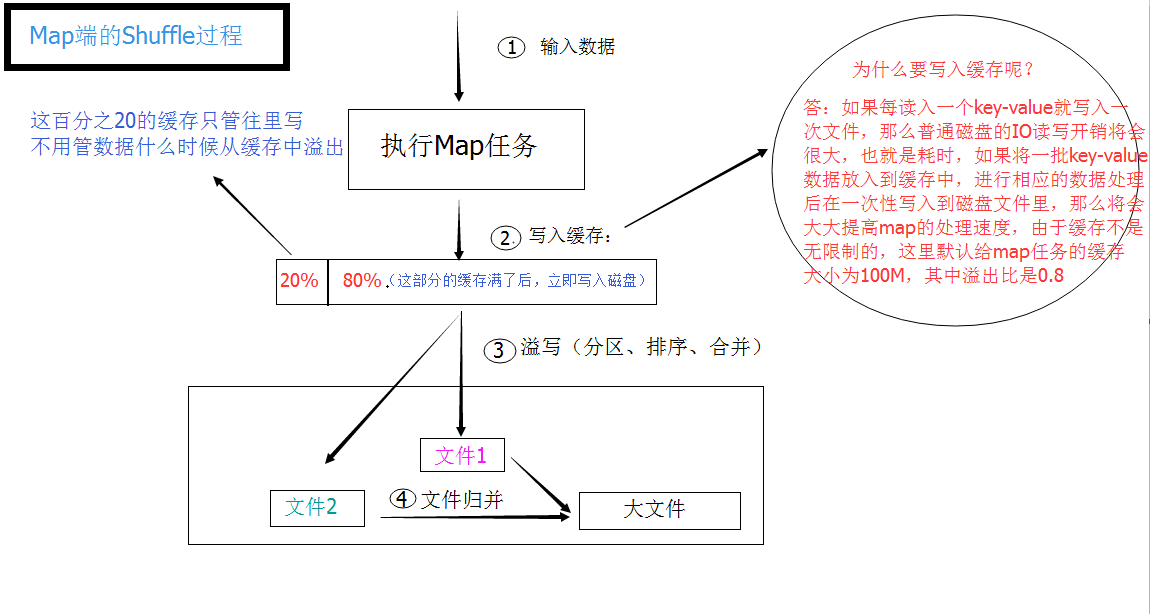
What we need to know is:
1. The size of the cache can be set (mapreduce.task.io.sort.mb, default 100M)
2. Overflow ratio (cache utilization has a soft threshold== mapreduce.map.sort.spill.percent, default 0.80). When the threshold is exceeded, the overflow behavior will be executed by a thread in the background so that the Map task will not be blocked by the overflow of the cache. However, if the hard limit is reached, the Map task will be blocked until the overflow behavior ends.
6. How to write map and reduce functions
At this point, if you have mastered the working principle of MapReduce, then it will be easy to write a client program and use MapReduce's computing function to realize the statistics of the number of words in text files.
First, we need a mapper (task), then a reducer (task). After two tasks, we need to create a Job (job), associate the mapper and reducer, and submit them to the Hadoop cluster. JobTracker in the cluster schedules the mapper and reducer tasks, and finally completes the data calculation.
Therefore, it is not difficult to find that MapReduce (Distributed Big Data Computing) cannot be implemented with mapper and reducer tasks alone. Here we need to write three classes: one is to implement Map, one is to implement Reduce, and the other is to submit the main class of jobs (Client Main Class).
Since the blogger's version of Hadoop is 3.1.0, in order to take into account that the Hadoop cluster environment below 3.X can run in the demo provided below, the Hadoop dependency involved in this article is replaced by the version of 2.7.X, as follows:
Note: Do not use outdated hadoop-core (1.2.1) dependencies, otherwise unexpected problems will arise.
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.1</version> </dependency> <!-- common rely on tools.jar package --> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.8</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency>
(1) Writing Mapper
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * Mapper Prototype: Mapper < KEYIN, VALUEIN, KEYOUT, VALUEOUT > * * KEYIN : By default, the starting offset of a line of text read by the mr framework, Long, * But in hadoop there is a more streamlined serialization interface, so instead of using Long directly, you use Long Writable. * VALUEIN : By default, it is the content of a line of text read by the mr framework (Java String corresponds to Text in Hadoop) * KEYOUT : After the user-defined logic processing is completed, the key in the output data is the word (String), which is the same as Text. * VALUEOUT : After the user-defined logical processing is completed, the value of the output data, in this case the number of words: Integer, corresponding to IntWritable in Hadoop * * mapper The input and output parameters must be of the same type as reducer, and the output of mapper is the input of reducer. * * @blob http://blog.csdn.net/appleyk * @date 2018 15:41:13, July 3, 2000 */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ /** * map Implementation of data splitting operation * This operation mainly deals with the data of Map. * The following is accepted in the Mapper parent class: * LongWritable: Initial offset of text content * Text:Text data per line (line content) * Text:Statistical results after decomposition of each word * IntWritable: Output of recorded results */ @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { System.out.println("Initial offset of text content:"+key); String line = value.toString() ;//Take out the data for each row String[] result = line.split(" ");//Data splitting by spaces //Cycle words for (int i = 0 ;i <result.length ; i++){ //For each word, construct a key-value System.out.println("key-value : <"+new Text(result[i])+","+new IntWritable(1)+">"); /** * Write the key-value of each word into the input-output context object * And pass it to mapper for shuffle process. After all mapper task s are completed, it is left to reducer to sign off. */ context.write(new Text(result[i]), new IntWritable(1)); } /** map End-to-end shuffle process (briefly described) * | * | Place the cache (default 100M, overflow ratio is 0.8, that is 80M full disk write and empty, * | The remaining 20M continues to write to the cache. The combination of the two perfectly implements overwriting while writing to the cache (writing to disk). * V * <b,1>,<c,1>,<a,1>,<a,1> * * | * | When the cache is full, start shuffle (shuffle, reorganization) ==== including partitions, sorting, and self-defined merges. * V * Write to disk files (not hdfs) and merge them into large files <a,<1,1>, <b,1>, <c,1>. * * | * | * V * Each large file has its own partition, several partitions correspond to several reducers, and then the files are taken away by their respective reducers. * * !!! This is the so-called mapper input is the output of reducer!!! */ } }
(2) Writing Reducer
import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /** * Final statistics of merged data * The type information to be used for this time is as follows: * Text:Map Output text content * IntWritable:Map Number of processes * Text:Reduce Output text * IntWritable:Reduce Number of outputs */ public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { //mapper The output is reducer Input, so please type here. reducer Received content List<Integer> list = new ArrayList<>(); int sum = 0;//Record each word ( key)Number of occurrences for (IntWritable value : values) { //from values Take it out of the collection key The number of individual frequencies (actually 1) is superimposed. int num = value.get(); sum += num; list.add(num); } /** * mapper A bunch of key-value s are shuffle d, which involves partitioning, sorting, and combining. * Note: The merge in shuffle is different from the merge in map. * For example, there are three key pairs: <a, 1>, <b, 1>, <a, 1>. * combine RESULTS: <a,2>, <b,1>=== was taken away by reducer, and the data was small. * merage Result: <a, <1,1>, <b,1>== was taken away by reducer, and the data was larger (compared with the combine mentioned above). * Note: The default combiner is user-defined, so the final output of mapper is actually the result of merge. * * So, the following print is actually to see the merge results (a bunch of key-values) of mapper after the shuffle process. */ System.out.println("key-values :<"+key+","+list.toString().replace("[", "<") .replace("]", ">")+">"); //Print it. reduce Result System.out.println("reduce Calculation results == key-value :<"+key+","+new IntWritable(sum)+">"); //Finally, it is written into the input and output context object and passed to the reducer Conduct shuffle,To be all reducer task Delivery upon completion HDFS Write files context.write(key, new IntWritable(sum)); } }
(3) Write Partition partition classes (if you need to modify Map's default hash partition rules)

1 import org.apache.hadoop.io.IntWritable; 2 import org.apache.hadoop.io.Text; 3 import org.apache.hadoop.mapreduce.Partitioner; 4 5 public class PartitionTest extends Partitioner<Text, IntWritable> { 6 7 /** 8 * key : map Output key 9 * value : map Output value of 10 * numReduceTask: reduce Number of task s 11 * Return value, specify reduce, starting at 0 12 * For example, partition 0 is taken away by reducer 0 13 */ 14 @Override 15 public int getPartition(Text key, IntWritable value, int numReduceTask) { 16 17 if (key.toString().equals("a")) { 18 //If key The value is equal to a,Specify its partition as 0, corresponding to the first reducer Take away reduce 19 return 0; 20 } else { 21 return 1; 22 } 23 } 24 }
(4) Writing Job Class
1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.fs.Path; 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Job; 6 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 7 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 8 9 import com.appleyk.hdfs.mapper.WordCountMapper; 10 import com.appleyk.hdfs.part.PartitionTest; 11 import com.appleyk.hdfs.reducer.WordCountReducer; 12 13 /** 14 * Client End, submit job 15 * @author yukun24@126.com 16 * @blob http://blog.csdn.net/appleyk 17 * @date 2018 July 3-9:51:49 a.m. 18 */ 19 public class WordCountApp { 20 21 public static void main(String[] args) throws Exception{ 22 23 Configuration conf = new Configuration(); 24 //To configure uri 25 conf.set("fs.defaultFS", "hdfs://192.168.142.138:9000"); 26 27 //Create a job, job name"wordCount",Role in Hadoop Cluster ( remote) 28 Job job = Job.getInstance(conf, "wordCount"); 29 30 /** 31 * Set the main class of the jar package (if the sample demo is typed as a Jar package and thrown under Linux to run the task, 32 * You need to specify the Main Class of the jar package, which is the main entry function that specifies the jar package to run. 33 */ 34 job.setJarByClass(WordCountApp.class); 35 36 //Set up Mapper Task classes (self-written) demo Realization map) 37 job.setMapperClass(WordCountMapper.class); 38 //Set up Reducer Task classes (self-written) demo Realization reduce) 39 job.setReducerClass(WordCountReducer.class); 40 41 //Appoint mapper Partition class 42 //job.setPartitionerClass(PartitionTest.class); 43 44 //Set up reducer(reduce task)Number (starting from 0) 45 //job.setNumReduceTasks(2); 46 47 48 //Set the key that maps the output data ( key) Class (type) 49 job.setMapOutputKeyClass(Text.class); 50 //Set the value of the mapped output data ( value)Class (type) 51 job.setMapOutputValueClass(IntWritable.class); 52 53 //Setting up jobs ( Job)The key to output data ( key) Class (type) == Finally, it's written to the output file. 54 job.setOutputKeyClass(Text.class); 55 //Setting up jobs ( Job)The value of the output data ( value)Class (type) == Finally, it's written to the output file. 56 job.setOutputValueClass(IntWritable.class); 57 58 //Setting input Path List (can be a single file or multiple files (directory representation can be used) 59 FileInputFormat.setInputPaths (job, new Path("hdfs://192.168.142.138:9000/input" )); 60 //Set the output directory Path(Confirm output Path No, if it exists, please delete the directory first. 61 FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.142.138:9000/output")); 62 63 //Submit the job to the cluster and wait for it to complete. 64 boolean bb =job.waitForCompletion(true); 65 66 if (!bb) { 67 System.out.println("Job Job execution failed!"); 68 } else { 69 System.out.println("Job Successful job execution!"); 70 } 71 } 72 73 }
(5) Run the main method and submit jobs
Abnormal:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
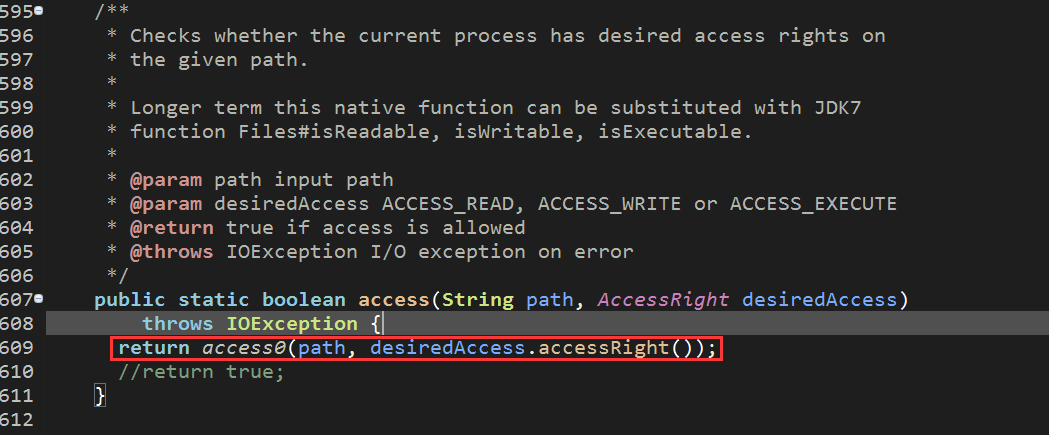
Copy out the source code and create a new file with the same package name and the same name under the project as follows:
After opening, modify the code as follows (remove validation):

(6) Run the main method again and submit the job
Again, there was an anomaly:
org.apache.hadoop.security.AccessControlException:
Permission denied: user=Administrator, access=WRITE,inode="/":root:supergroup:drwxr-xr-x
Besides, the user I currently use is Administrator under Windows, but in Hadoop's HDFS filesystem, there is no such user. Therefore, I want to use Administrator as a user to Write HDFS filesystem when there is an exception of inadequate privileges, because the files under HDFS filesystem root directory do not have the privileges of w and r for other users.
I didn't need to worry about the user's HDFS privileges when I packaged the mapreduce program in the cluster, but I said at the beginning that I didn't want to be so troublesome, but Hadoop turned on the HDFS file system's privilege verification function. I just turned it off (open) and couldn't do it, so I decided to fix the privilege verification directly in the hdfs-site.xml configuration file. Instead, add the following:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
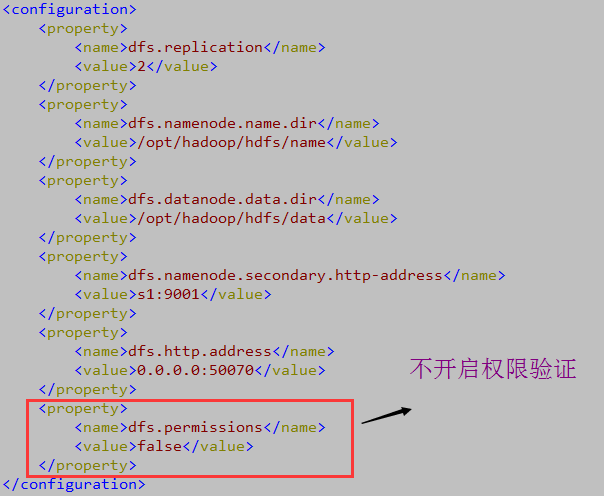
After saving, restart the Hadoop cluster
First stop, then start
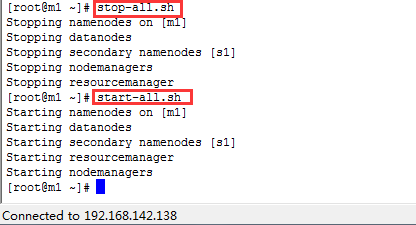
(7) Run the main method again and submit the job
16:55:44.385 [main] INFO org.apache.hadoop.mapreduce.Job - map 100% reduce 100% 16:55:44.385 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.getTaskCompletionEvents(Job.java:670) 16:55:44.385 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:320) 16:55:44.386 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:320) 16:55:44.386 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.getTaskCompletionEvents(Job.java:670) 16:55:44.386 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:320) 16:55:44.386 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:320) 16:55:44.387 [main] INFO org.apache.hadoop.mapreduce.Job - Job job_local539916280_0001 completed successfully 16:55:44.388 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.getCounters(Job.java:758) 16:55:44.407 [main] INFO org.apache.hadoop.mapreduce.Job - Counters: 35 File System Counters FILE: Number of bytes read=560 FILE: Number of bytes written=573902 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=46 HDFS: Number of bytes written=24 HDFS: Number of read operations=13 HDFS: Number of large read operations=0 HDFS: Number of write operations=4 Map-Reduce Framework Map input records=3 Map output records=12 Map output bytes=72 Map output materialized bytes=102 Input split bytes=112 Combine input records=0 Combine output records=0 Reduce input groups=6 Reduce shuffle bytes=102 Reduce input records=12 Reduce output records=6 Spilled Records=24 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=3 Total committed heap usage (bytes)=605028352 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=23 File Output Format Counters Bytes Written=24 16:55:44.407 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:320) Job Successful job execution!
ok, so far, the local mapreduce job has been completed, and then we'll look at the results we want.
(8) Using Java HDFS API, open / output/part-r-00000 file content and output it to the console
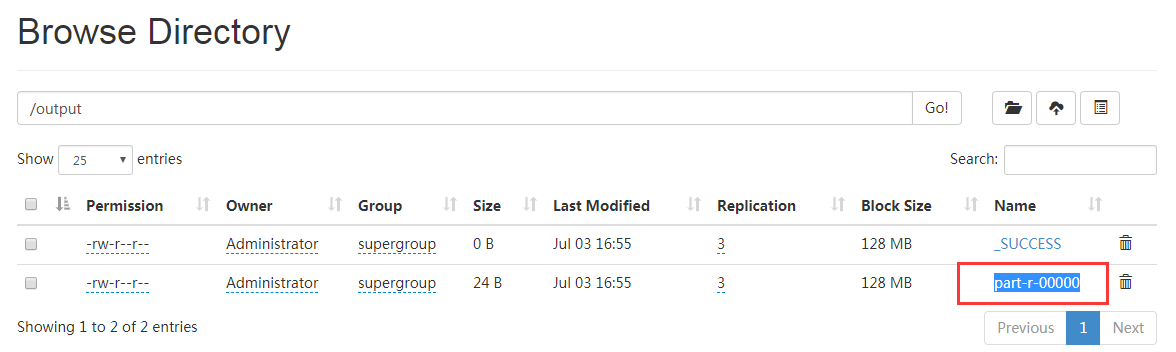
a b c d e f a c a c b f
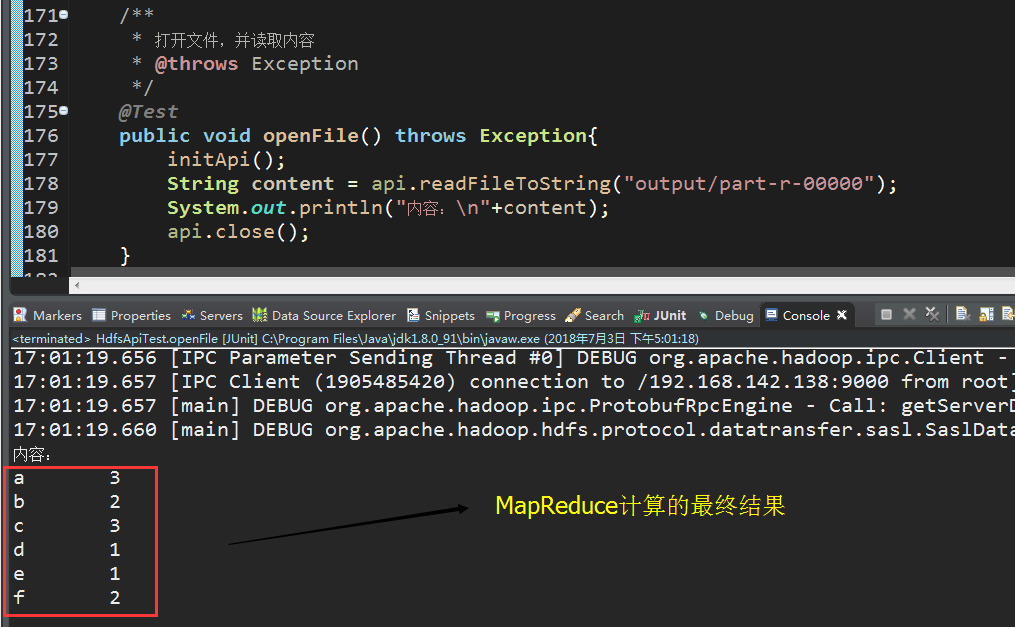
GitHub project address