Basic concepts
Hash Table: Hash Table, also known as Hash Table. Define a keyword k in the data to be stored. Map k to an address through a mapping relationship f. This address is called hash address. Then when searching for the record, it is no longer necessary to search through data comparison, but directly use the keyword k mapping of the record to obtain the data storage address and extract the address data. The address set that stores data in this way is called a Hash Table. An array is maintained under the Hash Table, and the index of the array is the address we want to map to.
Hash function: The key k of data is mapped to the corresponding relation f of address, which is called hash function.
Conflict: Different keywords map to the same hash function f with the same result, that is, f(k1)=f(k2). This phenomenon is called conflict, and K1 and K2 are called synonyms.
Load factor: Load factor = the number of data in the table / the total capacity of the array, the hash table maintains the array, so we need to expand the table at the appropriate time, this load factor is to measure whether the expansion is needed, that is, when we specify the load factor is 0.75, then every time we insert data, Whether the load factor is greater than 0.75 can be calculated, and if it is greater than 0.75, the capacity will be expanded.
Designing hash function
1. Direct Addressing Method
For example, if we want to store employee information in the hash table, we can use the age of the employee as the hash address directly, that is, f(key)=key; or we know that the year of birth of the employee is 1980, we can use 2019-1980 as the hash address, that is, f(key)=2019-key. That is to say, we can take a linear function value of the keyword as hash address: f(key)=a. key+b, where a and B are constants.
2. Digital Analysis
For example, we want to store employee information in the hash table. We find that the last few of the employee numbers are not duplicated. We can use the last few of the employee numbers as hash addresses and the employee numbers as keywords. This method of analyzing a part of a keyword as a hash address is called digital analysis.
3. Square Midway Method
When it is not possible to determine which bits of the keyword are evenly distributed, the square value of the keyword can be calculated first, and then the middle bits of the square value can be taken as hash addresses as needed. This is because: after the square, the middle bits are related to each of the keywords, so different keywords will produce different hash addresses with a higher probability. For example, we use the date of birth as the keyword, 19800315, but we don't know which part of the date of birth is more uniform step by step. We can square it to 364058420499225, and then take the middle as a hash address.
4. fold method
For example, we want to store employee information in the hash table. Now we take the date of birth of the employee as the keyword 19800315. We can calculate 19+80+03+15 as the hash address.
5. Random Number Method
Choose a random function and take the random value of keywords as hash address. It is usually used in the case of different keyword lengths.
6. The method of dividing residue For example, we use the employee number 20154511 as the keyword, although this keyword is unique among all employees, but the number is too large, so we can model it 20154511% 17 = 8, and we use result 8 as the hash address, that is, f(key)=key MOD p. In addition to the residue method, we can use the above 1-5 methods before taking the model, and finally take the model of the result.
Conflict handling
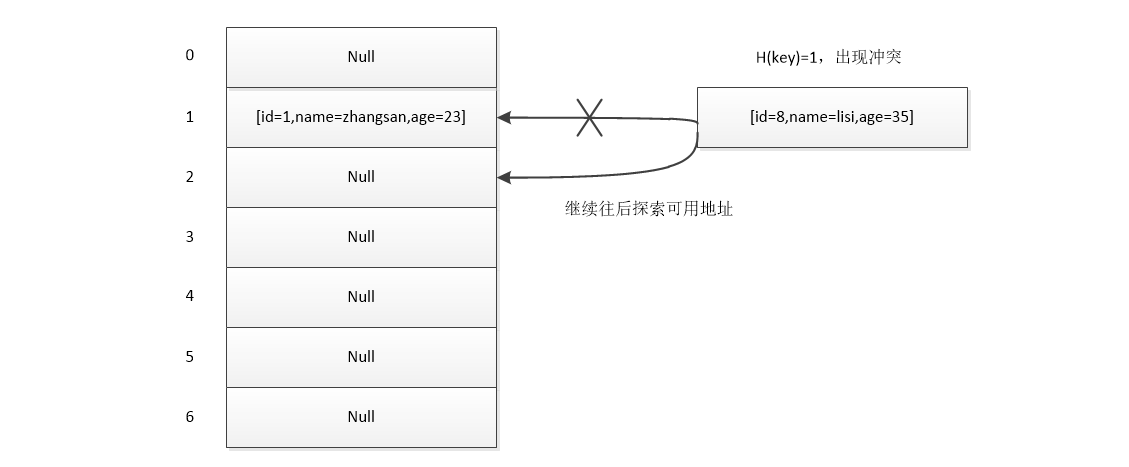
1. Open Addressing Method
Hash function H i= (H (key) + di) MODm, I = 1,2,... K(k<=m-1), where H(key) is a hash function, m is a long hash table and Di is an incremental sequence. If the hash address acquired by H (key) conflicts, the following three methods can be used to deal with conflicts:
Linear detection: di=1,2,3,... m-1, i.e. adding step size after the hash address is obtained to continue detecting whether there is conflict.
Square detection: di=1^2,-1^2,2^2,-2^2,3^2,... The (+(k)^2, (k<=m/2) is to continue to detect collisions with a certain step before and after the hash address is obtained.
Double hash detection: di=H2(key),2H2(key),3H2(key),... kH2(key),H2(key)!=0, where H2(key) is another hash function, we can make H2(key)=m - (key MOD m), m is long hash table.
2. Rehashing
H (key) = H3 (H2 (H (key)) MODm, where Hi(key) is a hash function and m is a long hash table. That is, when a hash address conflict is obtained by a hash function, it is calculated by another hash function again until the conflict no longer occurs.
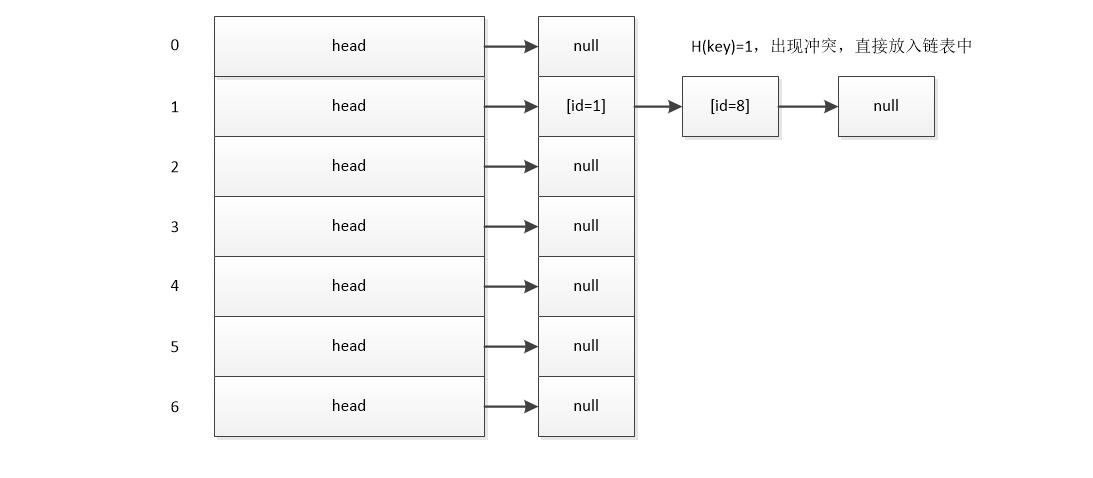
3. Chain Address Method (Zipper Method)
In the hash table maintenance array, each address stores no more data, but a linked list. When conflict occurs, the data can be directly put into the linked list where the conflict address is located.
4. Establish a public spillover zone
In addition to the arrays that must be maintained to create hash tables, an array is being developed to store conflicting data.
Optimization of Hash Table
Optimizing hash table is mainly to optimize hash function and conflict results, so as to access the corresponding data faster with a keyword.
- The more homogeneous the hash address calculated by the hash function, the less likely it is to collide. For example, if we use the age of employees to address directly, there are fewer employees aged 0 to 20 and more than 60, and most of the data are gathered between 21 and 59. Such hash functions may conflict greatly and affect the addressing time.
- When using the method of dividing residue, we use H(key) MOD p. The selection of p is very important. If p is chosen well, it can minimize conflicts. p is usually the largest prime number not larger than the size of the array.
- When using chain address method (zipper method) to deal with conflicts, if the hash address calculated by hash function is not uniform, some chain lists will be too long. We know that the query speed of chain list is very slow, and we can only compare the queries one by one, so we need to optimize the hash function first, and then, even if the hash address calculated by hash function is not uniform. Distribution is very uniform, when there is a lot of data, the list will be too long, then we can transform the list into a tree to maintain, which is also the practice of HashMap. When the length of the list reaches 8, the list will be converted to a red-black tree, and when the node of the tree is less than 6, it will be converted to a list.
- No matter how uniform the hash address calculated by the hash function is, when the length of the array is fixed, but the data in the hash table is more and more, the probability of conflict will increase. Resolving the conflict will affect the efficiency, and when the chain address method (zipper method) is used, the same list will be too long. Therefore, it is necessary to use load factor to expand the array in time.
Implementation of Simple Hash Table by Open Addressing Method
public class HashTable1 { private final int DEFAULT_TABLE_SIZE = 23; //Default array size, no expansion here private int size; //Number of data in the table private Employee[] array = null; //Array for storing data /** * constructor */ public HashTable1(){ this.size = 0; this.array = new Employee[DEFAULT_TABLE_SIZE]; } /** * Hash function, use id as key directly, take module * @param key Employee id * @return */ private int hash(int key){ int address = key%DEFAULT_TABLE_SIZE; return address; } /** * insert data * @param employee */ public void put(Employee employee){ int address = hash(employee.geteId()); //Get the hash address if(array[address]!=null){ //If the hash address data is not empty, then there is a conflict. Linear detection processing is used here. int stepSize =1; while (array[address]!=null){ address = (address+stepSize)%DEFAULT_TABLE_SIZE; } } array[address] = employee; this.size++; System.out.println("key by"+employee.geteId()+"The address where the data is put is"+address); } /** * Get the data corresponding to the key * @param key Employee id * @return */ public Employee get(int key){ int address = hash(key); //Get the hash address if(array[address]==null){ //If the corresponding data is empty, it means that there is no such data and returns empty. return null; } if(array[address].geteId()!=key){ //If the data of the current hash address is not the data to be looked for, then the data to be looked for is detected int stepSize =1; while (array[address].geteId()!=key){ address = (address+stepSize)%DEFAULT_TABLE_SIZE; } } return array[address]; } @Override public String toString() { if(this.size==0){ return "Hash table is empty"; } String str = ""; for(int i = 0;i<this.DEFAULT_TABLE_SIZE;i++){ if(array[i]!=null){ str += array[i].toString()+"\n"; } } return str; } public int getSize(){ return this.size; } }
Chain Address Method to Realize Simple Hash Table
public class HashTable2 { private final int DEFAULT_TABLE_SIZE = 23; //Default array size, no expansion here private int size; //Number of data in the table private Node[] array = null; //Array for storing data /** * constructor */ public HashTable2(){ this.size = 0; this.array = new Node[DEFAULT_TABLE_SIZE]; for (int i = 0;i<DEFAULT_TABLE_SIZE;i++){ //Initialize the header node for each address array[i] = new Node(); } } /** * Hash function, use id as key directly, take module * @param key Employee id * @return */ private int hash(int key){ int address = key%DEFAULT_TABLE_SIZE; return address; } /** * insert data * @param employee */ public void put(Employee employee){ Node node = new Node(); //Create nodes and save data node.data = employee; int address = hash(employee.geteId()); //Get the hash address Node temp = array[address]; //Auxiliary node, pointing to the last node in the list where the address is located while (temp.next!=null){ temp = temp.next; } temp.next = node; //Add new nodes this.size++; //Increased number of data } /** * Get the data corresponding to the key * @param key Employee id * @return */ public Employee get(int key){ int address = hash(key); //Get the hash address Node temp = array[address].next; //The assistant node searches the linked list of the address and queries the key. while (temp!=null&&temp.data.geteId()!=key){ temp = temp.next; } if(temp==null){ //If no data is queried, return empty return null; } return temp.data; } @Override public String toString() { if(this.size==0){ return "Hash table is empty"; } String str = ""; for (int i = 0;i<DEFAULT_TABLE_SIZE;i++){ str += "address"+i+": "+"\n"; Node temp = array[i].next; while (temp!=null){ str += "\t"+temp.data.toString()+"\n"; temp = temp.next; } } return str; } public int getSize(){ return this.size; } class Node{ Employee data; Node next; } }
attach
Source code: GitHub