Java from 0 to architect Directory: [Java from 0 to architect] learning record
Link tracking component
Why link tracking?
There are many service units in the microservice architecture. If there are errors and exceptions, it is difficult to locate (a request may need to call multiple services, and the call complexity between internal services determines that the problem is difficult to locate). Therefore, the microservice architecture must implement link tracking to follow up which services participate in a request and the order of participation.
In a microservice system, a request from a user,
- Request to reach front end a first
- Then, the middleware B and C (load balancing, gateway, etc.) of the system are reached through remote call
- Finally, back-end services D and E are achieved
- The back end returns the data to the user after a series of business logic operations
Embedding point: it is to collect some information in the specific process of the application to track the use of the application, and then use it to further optimize the product or provide data support for operation, including visits, visitors, time on site, page views, bounce rate, etc.
Such information collection can be roughly divided into two types:
- Track this virtual page view
- Track this button by an event
Sleuth
Sleuth Is an open source component dedicated to recording link data
Use steps:
- Import dependency:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
- Write @ Slf4j on the class that needs to be logged, and then print the log in the method
Explanation of log parameters:
# Log format [order-server,c323c72e7009c077,fba72d9c65745e60,false] -[order-server]: spring.application.name Value of -[c323c72e7009c077]: sleuth Generated TraceID,Used to identify a link request, A request link clock contains a TraceID,Multiple SpanID -[fba72d9c65745e60]: spanID,Basic work unit,Acquiring Metadata ,If sending a http -[false]Do you want to output this information to zipkin Service to collect and display
Zipkin
Zipkin It is the development source and implementation of Twitter's Google based distributed monitoring system Dapper (paper). Zipkin is used to track the application data link between distributed services, analyze and process latency, and help us improve the performance of the system and locate faults
Some similar products: reference resources
- CAT: a real-time application monitoring platform developed based on Java and open source by public comments, including real-time application monitoring and business monitoring
The coupling is relatively high, and the embedded point information needs to be customized - Pinpoint: the South Korean Naver team is open source and written in Java. It is a link tool for large-scale distributed systems
- SkyWalking: it was opened by individual developer Wu Sheng (Huawei developer) in 2015 and joined the Apache incubator in 2017. Especially for microservices, cloud native and containerized (Docker, Kubernetes, Mesos) architectures, its core is a distributed tracking system
Zipkin + Sleuth integration steps:
- Import Zipkin dependencies (Zipkin already contains Sluth, so there is no need to import Sluth)
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
- Start Zipkin service and use jar
# download curl -sSL https://zipkin.io/quickstart.sh | bash -s # function java -jar zipkin.jar
- Add Zipkin address to configuration file
spring:
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
probability: 1
Distributed configuration center - Config
The configuration center can be used to uniformly manage the configuration and quickly switch the configuration of each environment. In the microservice system, with the increasing number of services and configuration information (server parameter configuration, database access parameter configuration, configuration information in different environments, real-time effectiveness after modification of configuration information, etc.), the traditional configuration file method or storing the configuration file in the database can no longer meet the requirements of developers for configuration Management:
- Security: the configuration follows the source code and is saved in the code base, which is easy to cause disclosure
- Timeliness: modifying the configuration requires restarting the service to take effect
- Limitations: it cannot support dynamic adjustment, such as log switch and function switch
Related products:
- Baidu Disconf: https://github.com/knightliao/disconf
- Ali's diamand: https://github.com/takeseem/diamond
- Ctrip Apollo: https://github.com/ctripcorp/apollo
Application scenarios of the configuration center:
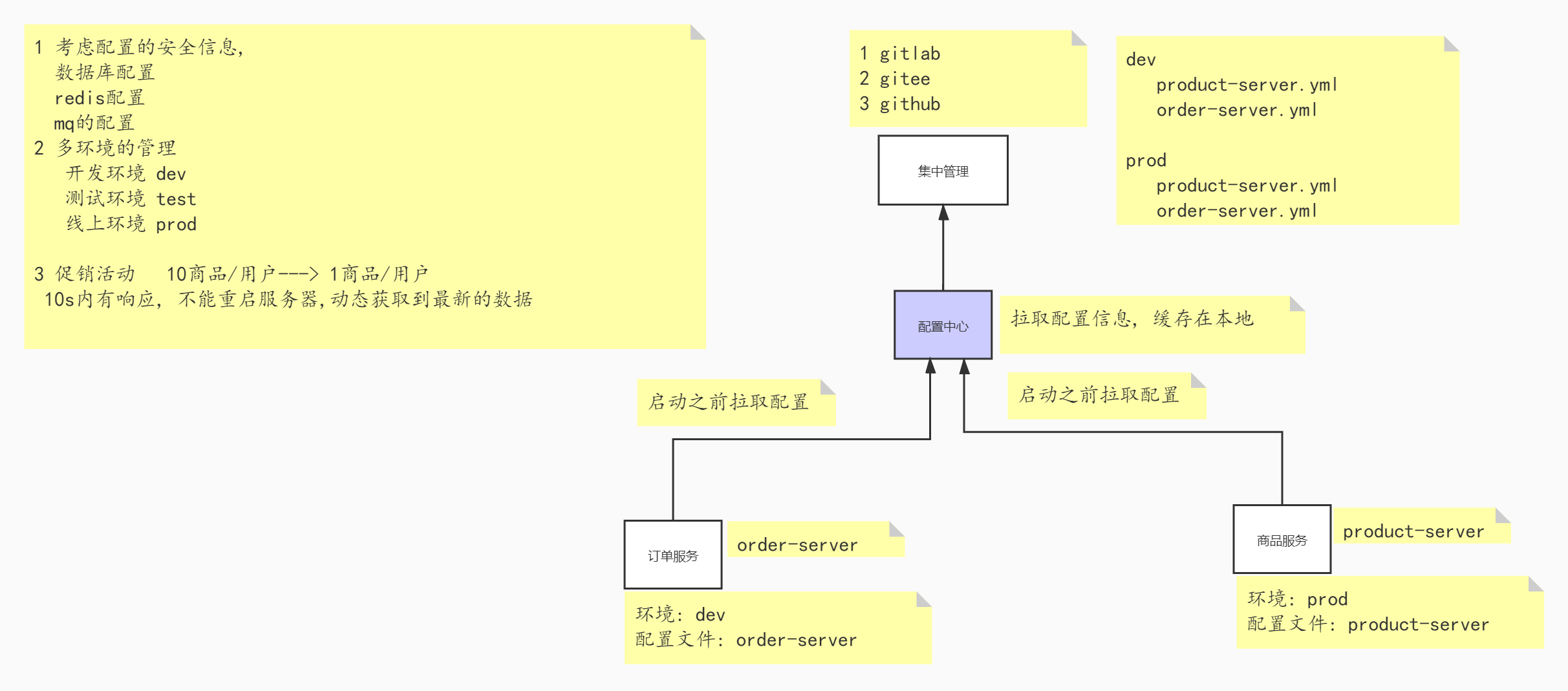
Git + Config distributed configuration center
Build config server project:
- Import dependency:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
- Use @ EnableConfigServer on startup class
- Add application.yml related configuration
Set up Git + Config distributed configuration center: file
- Register an account in the code cloud and create your own project
- Add the address of Gitee server in the configuration file
server:
port: 9100
spring:
application:
name: config-server
cloud:
config:
server:
git:
uri: https://gitee.com/xxxx/cloud-config
username: xxxx
password: xxxx
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
- Start test
# Name service name
# profile environment name, development, test and production
# lable warehouse branch, default master branch
/{name}-{profiles}.properties
/{name}-{profiles}.yml
/{name}-{profiles}.json
/{label}/{name}-{profiles}.yml
Distributed configuration center client: file
- Add the dependency of config client in order server
- Modify the configuration file to bootstrap.yml
- Put some configurations into Git server for management