aggregate
Java has many collection classes, which are divided into two main categories


- Sets are mainly two groups (single-column set, double-column set)
- The Collection interface has two important subinterfaces, List and Set, whose implementation subclasses are single-column collections
- The implementation subclass of the Map interface is a two-column collection that stores K-V
Collection Overall Structure
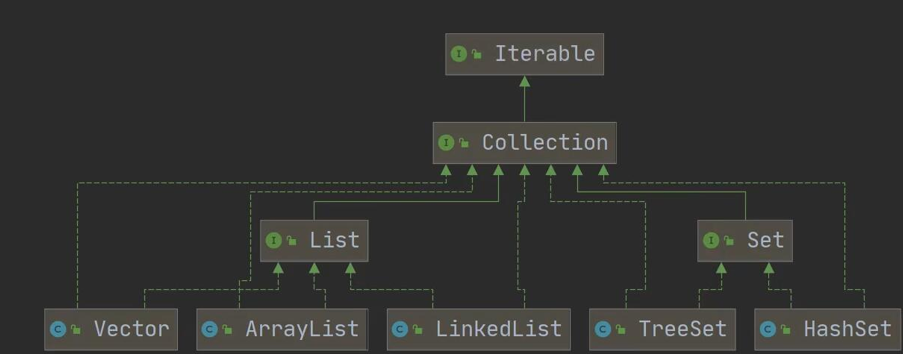

Collection interface and common methods
Collection Interface Implements Class Features
- Collection implementation subclasses can hold multiple elements, each of which can be Object
- Some Collection implementation classes can hold duplicate elements, some cannot
- Collection's implementation classes, some ordered (List) and some unordered (Set)
- The Collection interface does not directly implement subclasses, but through its subinterfaces Set and List.
Collection Common Methods
- add: add a single element
- remove: delete the specified element
- contains: Finds if an element exists and returns a boolean value
- size: Get the number of elements
- isEmpty: Determine if empty
- clear:Empty
- addAll: Add multiple elements
- containsAll: Find out if multiple elements exist
- removeAll: Delete multiple elements
To implement the subclass ArrayList for demonstration
@SuppressWarnings({"all"})
public class Test {
public static void main(String[] args) {
Collection col = new ArrayList<>();
col.add("week") ;
col.add("Liu") ;
col.add(100) ;
col.add(new Integer(3)) ;
System.out.println(col); //[Zhou, Liu, 100, 3]
col.remove(3) ;
System.out.println(col); //[Zhou, Liu, 100]
boolean b = col.contains("week");
System.out.println(b); //true
System.out.println(col.size()); //3
System.out.println(col.isEmpty()); //false
col.clear();
System.out.println(col.size()); // 0
Collection c = new ArrayList() ;
c.add("AA");
c.add("CC");
c.add("BB");
col.addAll(c) ;
System.out.println(col);
Collection c2 = new ArrayList() ;
c2.add("CC");
c2.add("AA");
boolean b1 = col.containsAll(c2);
System.out.println(b1); //true
col.removeAll(c2) ;
System.out.println(col);
}
}
Collection interface traversal element mode 1 - Iterator iterator
- The Iterator object is called an iterator and is primarily used to traverse elements in a Collection collection.
- All collection classes that implement the Collection interface have an iterator() method that returns an object that implements the Iterator interface, that is, an iterator
- Iterator is only used to traverse collections, and Iterator itself does not store objects.
Iterator Execution Principle
Iterator to get a set
Iterator iterator = col.iterator() ;
-
iterator.hasNext(): Determine if there is another element
-
iterator.next(): Role
- Move Down
- Return elements at collection location after moving down

Tips
iterator.hasNext() must be called to detect before calling the iterator.next() method. If it is not called and the next record is invalid, calling it.next() directly throws a NoSuchElementException exception
@SuppressWarnings({"all"})
public class iterator {
public static void main(String[] args) {
Collection col = new ArrayList() ;
col.add("week") ;
col.add("Liu") ;
col.add("rise") ;
col.add("stay") ;
//To traverse col, get the corresponding iterator first
Iterator iterator = col.iterator();
//Shortcut Quick Generate itit
//Shortcut key ctrl + j to display all shortcuts
while (iterator.hasNext()) {
String next = (String)iterator.next();
System.out.println(next);
}
System.out.println("=========================");
//If you want to traverse again, you need to reset the iterator
iterator = col.iterator() ;
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
}
}
Collection Interface Traverse Objects Mode 2 - Enhance for Loop
Enhanced for loops can replace iterator iterators, which are characterized by the fact that enhanced for is a simplified version of iteartor and is essentially the same. Can only be used to traverse collections or arrays
Basic Grammar
for( Element Type Element Name : Collection name or array name ){
Access Elements
}
List interface and common methods
Introduction to List interface
List interface is a subinterface of Collection interface
-
The elements in a List collection class are ordered (that is, the order in which they are added is the same as the order in which they are removed), and repeatable
-
Each element in a List collection has its own sequential index, that is, supporting an index
-
Elements in a List container correspond to an integer number that records their position in the container and allows access to the elements in the container based on the number
-
The implementation classes of the List interface in the JDK API are commonly used:
- ArrayList
- LinkedList
- Vector
@SuppressWarnings({"all"})
public class List common method {
public static void main(String[] args) {
List list = new ArrayList() ;
list.add("jack") ;
list.add("tom") ;
list.add("mary") ;
//Each element in the List interface has its own sequential index, that is, the List interface supports indexes
//Index starts at 0
System.out.println(list.get(1));
}
}
Common methods of the List interface
List collection has some methods for manipulating collection elements based on Indexes
-
void add(int index , Object ele)
- Insert ele element at index position
-
boolean addAll(int index , Collection eles)
- Add all elements in eles from index position
-
Object get(int index)
- Get the element that sets the index position
-
int indexOf(Object obj)
- Returns the first occurrence of obj in the current collection
-
int lastIndexOf(Object obj)
- Returns the last occurrence of obj in the current collection
-
Object remove(int index)
- Removes the element at the specified index position and returns this element (deleted by index by default, when deleted by the specified element, incoming objects are required)
-
Object set(int index , Object ele)
- Setting the element at the specified index position to ele is equivalent to replacing
-
List subList(int fromIndex , int toIndex)
- Returns a subset from fromIndex to toIndex
List interface exercise
Use List's implementation class to add several books and iterate through them. Requires sorting by price, from low to high (using bubbles), and using three collections of ArrayList, LinkedList, Vector
@SuppressWarnings({"all"})
public class z1_test {
public static void main(String[] args) {
List list = new ArrayList();
list.add(new Book("Ford" , 10 , "Arthur Conan Doyle")) ;
list.add(new Book("Moses" , 80 , "Arthur Conan Doyle")) ;
list.add(new Book("wahson" , 20 , "Arthur Conan Doyle")) ;
list.add(new Book("Jones" , 15 , "Arthur Conan Doyle")) ;
sort(list) ;
for (Object o : list) {
System.out.println(o);
}
}
//Bubble sort
public static List sort(List list){
int size = list.size();
for( int i = 0 ; i < size-1 ; i ++ ){
for( int j = 0 ; j < size-1-i ; j++ ){
Book book = (Book) list.get(j);
Book book1 = (Book) list.get(j + 1);
if( book.getPrice() > book1.getPrice() ){
list.set(j , book1) ;
list.set(j+1 , book) ;
}
}
}
return list ;
}
}
class Book{
private String name ;
private double price ;
private String author ;
public Book(String name, double price, String author) {
this.name = name;
this.price = price;
this.author = author;
}
@Override
public String toString() {
return "Name: " + name +"\t\t Price: " + price + "\t\t author: " + author ;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
}
ArrayList underlying structure
- ArrayList can add null s and can have multiple
- ArrayList is an array for data storage
- ArrayList is basically the same as Vector, except that ArrayList is thread insecure (efficient) and is not recommended for multi-threaded situations
ArrayList Source Analysis
-
ArrayList maintains an array of elementData of type Object
- Transient Object[] elementData; // Transients represent transient, transient, and indicate that the property cannot be serialized
-
When an ArrayList object is created, if a parameterless constructor is used, the initial elementData capacity is 0, and when added for the first time, the expanded elementData capacity is 10. If it needs to be expanded again, the expanded elementData capacity is 1.5 times
-
If a constructor of a specified size is used, the initial elementData capacity is specified, and if expansion is required, the elemetData capacity is directly expanded by 1.5 times
Vector Bottom Structure
- At the bottom of the vector s is also an array of objects, protected Object[] elementData;
- Vectors are thread-synchronized, that is, thread-safe, and the Vector class operates with the synchronized keyword
- Consider using Vector when thread synchronization security is required in development
Comparison of Vector and Array List
| Underlying structure | Edition | Thread Safety, Efficiency | Expansion multiple | |
|---|---|---|---|---|
| ArrayList | Variable Array | jdk1.2 | Insecure and efficient | If there are parameters constructed 1.5 times. If there is no parameter, 10 for the first time, 1.5 times capacity expansion from the second time |
| Vector | Variable Array | jdk1.0 | Safe and inefficient | If there is no parameter, default 10, when full, it will expand by 2 times. If size is specified, capacity will be expanded by 2 times at a time |
LinkedList underlying structure
LinkedList full description
- The bottom level of LinkedList implements the characteristics of two-way chain table and two-end queue
- Any element can be added (elements can be repeated), including null
- Thread is not secure and synchronization is not implemented
The underlying operating mechanism of LinkedList
- LinkedList maintains a two-way linked list at the bottom
- LinkedList maintains two attributes, first and last, pointing to the first and last node, respectively
- Each node (Node object) maintains three attributes: prev, next, and item, with prev pointing to the previous node and next pointing to the latter node. Finally, the two-way chain table is implemented.
- Therefore, the addition and deletion of LinkedList elements are not done through arrays, which is relatively efficient.
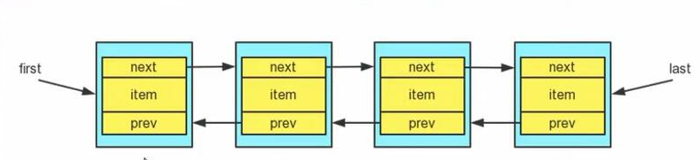
Comparison of ArrayList and LinkedList
| Underlying structure | Efficiency of addition and deletion | Efficiency of the review | |
|---|---|---|---|
| ArrayList | Variable Array | Lower, Array Expansion | higher |
| LinkedList | Bidirectional Chain List | Higher, appended through a list of chains | Lower |
How to select ArrayList and LinkedList
- If we check more, choose ArrayList
- If we add or delete more, choose LinkedList
- In general, 80-90% of programs are queries, so in most cases ArrayList is chosen
- Within a project, you have flexibility to choose based on your business, and it is possible that one module uses an ArrayList and the other is a LinkedList
Set interfaces and common methods
Introduction to Set interface
- Out of order (inconsistent order of addition and removal), no index
- Although the order of removal is different from that of addition, he is fixed
- Duplicate elements are not allowed, so contain at most one null
- The implementation classes of the Set interface in the JDK API are:
- HashSet
- TreeSet
Common methods for Set interfaces
Like the List interface, the Set interface is also a subinterface of Collection, so common methods are the same as the Collection interface.
Set interface traversal
As with Collection traversal, because the Set interface is a subinterface of the Collection interface
- You can use iterators
- Enhance for
- Cannot be retrieved by indexing
HashSet - Set interface implementation class
-
HashSet implements Set interface
-
HashSet is actually HashMap, look at the source code
-
Null values can be stored, but there can only be one null
-
HashSet does not guarantee that elements are ordered, depending on the result of the index after hash
-
There must be no duplicate elements/objects.

@SuppressWarnings({"all"})
public class Ask questions {
public static void main(String[] args) {
Set hashSet = new HashSet<>();
hashSet.add(new Dog("Bangbang")) ; //Ability to add
hashSet.add(new Dog("Bangbang")) ; //Ability to add
System.out.println(hashSet); //Output [Dog{name='state'}, Dog{name='state'}]
hashSet.clear();
hashSet.add(new String("zf")); //Add to
hashSet.add(new String("zf")); //Not added
//Why is that? Look at the source code and what happened when add() was called?
System.out.println(hashSet); //Output [zf]
}
}
class Dog{
String name ;
public Dog(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
'}';
}
}
HashSet underlying mechanism description
The bottom of the HashSet is HashMap, and the bottom of the HashMap is (array + list + red-black tree).
HashSet stores data in a table array at the bottom
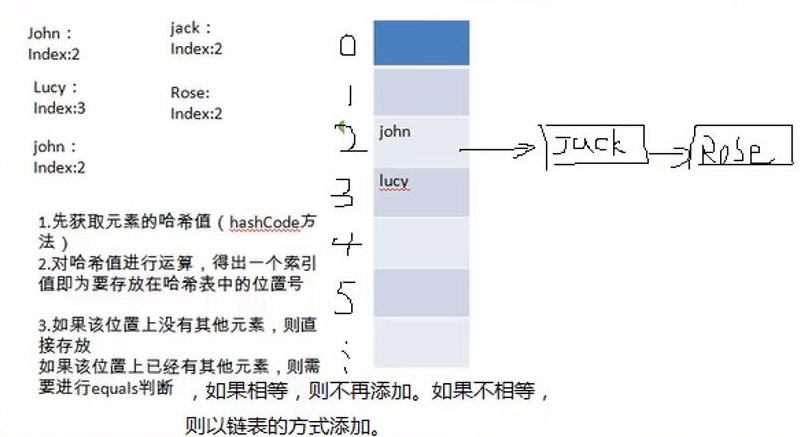
HashSet Expansion and Red-Black Treeing Mechanism
-
The bottom of the HashSet is HashMap
-
When you add an element, you first get its hash value, then convert it to an index value
-
Find the table where the data table is stored to see if the element is already stored in this index location
- If not stored, join directly
- If the element is already stored, the bars are compared with equals, and if they are the same, the addition is discarded. If not, it is added to the end of the linked list joined by the index.
-
At the bottom of the HashSet is HashMap. When first added, the table array expands to 16, and the threshold is 16*Loading Factor is 0.75 = 12
-
If the number of elements (including those on the list) stored in the table array reaches a critical value of 12 or if more than TREEIFY_is mounted on a single list YHRESHOLD (default is 8) elements, will expand to 16*2=32, the new threshold is 32*0.75=24, and so on
-
In Java8, if the number of elements in a chain table reaches TREEIFY_ YHRESHOLD (default is 8) and the size of the table (including elements on the chain table) >= MIN_ TREEIFY_ CAPACITY (default 64) will be dendrified (red-black tree), otherwise the array expansion mechanism will still be used.
-
After dendrification, the expansion mechanism is still observed, that is, if the number of elements in the table (including those in the chain table) is > the critical value, the table will expand by two times

LinkedHashSet--Set interface implementation class
- LinkedHashSet is a subclass of HashSet
- LinkedHashSet is ordered, that is, the order of additions and outputs are the same.
- LinkedHashSet has a LinkedHashMap at the bottom, which maintains an array + two-way chain table
- LinkedHashSet determines where elements are stored based on their HashCode values, while using a chain table to maintain the order of elements, making elements appear to be saved in insertion order.
- LinkedHashSet does not allow duplicate elements to be added

TreeSet
- When we create a TreeSet using the parameterless constructor, the default is ascending
- TreeSet provides a constructor to pass in a comparator when you want to add elements that are sorted according to the rules of the feature
- TreeSet also does not store duplicate elements
@SuppressWarnings({"all"})
public class TreeSet_ {
public static void main(String[] args) {
TreeSet<String> treeSet = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1); //String Descending
}
});
treeSet.add("zf");
treeSet.add("lx");
treeSet.add("lf");
treeSet.add("zx");
System.out.println(treeSet);
}
}
Map interfaces and common methods
Features of Map interface implementation classes
Note: This is about the Map interface features of jdk8
- Map exists side by side with Collection. Used to save data with mapping relationships: Key-Value
- The key s and value s in the Map can be any reference type of data and are encapsulated in the HashMap$Node object
- key in Map does not allow duplication for the same reason as HashSet
- value in Map can be repeated
- Map keys can be null or value can be null, note that keys are null and there can only be one. Value is null and can have multiple
- Common String classes as key s to Map s
- There is a one-to-one relationship between key and value, that is, the value is always found by the key specified
- Map stores key-value diagrams of data, a bunch of k-v's in a Node, because Node implements the Entry interface, and in some books a pair of k-v's is an Entry

Important details
-
For easy traversal, K-V also creates an Entry collection, which stores elements of type Entry, and an Entry object has k-v, Set <Map.Entry<K, V> EnySet
-
In entrySet, the type defined is Map.Entry, but actually points to HashMap$Node
-
Storing the HashMap$Node object in the entrySet is easy to traverse because Map.Entry provides an important method
- K getKey()
- V getValue()

Common methods for Map interfaces
- put:Add
- remove: Delete mapping relationship based on key
- Get: get a value based on a key
- size: Get the number of elements
- isEmpty: Determine if the number is zero
- clear:Empty
- containsKet: Find if the key exists
- KeySet: Get a collection of all keys
- Values:Get all values
- entrySet: Get all relationships k-v

HashMap - Map interface implementation class
- Common implementation classes for the Map interface: HashMap, Hashtable, and Proerties
- HashMap is the most frequently used implementation class for Map interfaces
- HashMap stores data as key-value pairs (HashMap$Node type)
- key cannot be duplicated, but values can be duplicated, allowing null keys and null values
- If the same key is added, it will overwrite the original k-v, which is equivalent to the modification (key will not be replaced, value will be replaced)
- As with HashSet, the order of mappings is not guaranteed because the underlying layer is stored as a hash table. (HashMap Bottom Array + Chain List + Red-Black Tree for JDK8)
- HashMap does not synchronize, so it is thread insecure, method does not do synchronization mutually exclusive operation, no syschronized
HashMap Bottom Diagram:

HashMap underlying parsing
The expansion mechanism is the same as HashSet
- HashMap maintains an array table of type Node at the bottom, defaulting to null
- When an object is created, the loadFactor is initialized to 0.75
- When key-value is added, the index on the table is derived from the hash value of the key. Then determine if the element is stored at the index, or if it is not, add it directly. If the index already has elements, continue to determine if the keys of the existing elements are equal to the keys that you are ready to add, and if they are equal, replace val directly. If they are not equal, it is necessary to decide whether they are tree or chain table structures and make appropriate processing. If not enough capacity is found when adding, expansion is required
- For the first addition, the table capacity needs to be expanded to 16 with a threshold of 12 (16*0.75).
- If the capacity of tables is expanded later, it is necessary to expand the capacity of tables twice as much as the original capacity, and the zero bound value is twice as much as the original capacity, and so on.
- In Java8, if the number of elements in a chain table exceeds TREEIFY_THRESHOLD (default 8), and table size >= MIN_ TREEIFY_ CAPACITY (default 64), then tree (red-black tree)
HashMap Source Interpretation
public class HashMap Source Code Interpretation {
public static void main(String[] args) {
HashMap<Object, Object> map = new HashMap<>();
for (int i = 0; i < 10000; i++) {
map.put(new Cat() , null) ;
}
}
}
class Cat{
@Override
public int hashCode() {
return 100 ;
}
}
Underlying Execution Interpretation
/*
1.Execute the constructor new HashMap()
Initial Load Factor Load Factor = 0.75
HashMap$Node[] table = null
2. Executing put calls the hash method and calculates the hash value of the key (h=key.hashCode()^ (h >>> 16)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//2.1 putVal (hash(key) source code in), calculates the index based on the hash value of the key
//>> means unsigned right shift, also known as logical right shift, that is, if the number is positive, the high-bit complement 0, and if the number is negative, the high-bit complement 0 after the right shift
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//3. Execute the putVal method, following is my understanding of the putVal source code
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; //Auxiliary variable
//If the underlying table array is null, or length=0, expand to 16
if ((tab = table) == null || (n = tab.length) == 0)
//resize() method is the expansion method
n = (tab = resize()).length;
//Remove the index position Node of the table corresponding to the hash value, and if null, add k-v directly
if ((p = tab[i = (n - 1) & hash]) == null)
//Create a new Node and join the location
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//If the hash value of the key at the index position of the table is the same as the hash value of the key to be added
//And satisfies (the key of the existing table node and the key to be added are the same object ||equals returns true)
//Consider it impossible to add a new k-v
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//If the existing ode of the current table is a red-black tree, add it as a red-black tree
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//If a node is found followed by a list of chains, a circular comparison is made
for (int binCount = 0; ; ++binCount) { //Dead cycle
//If the entire list is not the same as the key to be added, it is added to the end of the list
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//After joining, determine if the number of the current list of chains has reached 8, and after 8, call treeifyBin method to convert the red-black tree
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//If the same is found during a circular comparison, break is simply a replacement of value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//size++ without adding a Node
++modCount;
//If size > critical value, expand capacity
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
Hashtable - Map interface implementation class
- Key-value pairs for stored elements: key-value
- Neither keys nor values of hashtable can be null
- hashtable works basically like HashMap
- hashtable is thread-safe, hashMap is thread-insecure
hashtable underlying mechanism
- At the bottom is the array Hashtable$Entry[], with an initialization size of 11
- Threshold value threshold8 = 11 * 0.75
- Capacity expansion: Just follow your own capacity expansion mechanism
- Execute method addEntry (hash, key, value, index); Add k-v encapsulation to Entry````
- Expansion occurs when if (count >= threshold) is satisfied
- Expand as ```int newCapacity = (oldCapacity << 1) + 1, that is, double + 1.
Hashtable versus HashMap
| column1 | Edition | Thread Security (Synchronization) | efficiency | Allow null key null values |
|---|---|---|---|---|
| HashMap | 1.2 | Unsafe | high | Yes? |
| Hashtable | 1.0 | security | low | May not |
Properties - Map interface implementation class
- The Properties class inherits from the Hashtable class and implements the Map interface, which also uses a key-value pair to store data
- His usage features are similar to Hashtable
- Properties can also be used to load data from an xxx.properties file into a Properties class object and read and modify it
- Description: The xxx.properties file is usually used as a configuration file after work.
Basic Use
public class z1 {
public static void main(String[] args) throws IOException {
Properties properties = new Properties();
//Load properties file
properties.load(new FileReader("src\\mysql.properties"));
//Get K-V
String user = properties.getProperty("user");
String pwd = properties.getProperty("pwd");
System.out.println(user + " " + pwd);
//Modify K-V to add if K does not exist
properties.setProperty("user" , "xiaomi") ;
properties.setProperty("max" , "200") ;
System.out.println(properties.getProperty("user") + " " + properties.getProperty("max"));
}
}
Summary - How to Select Collection Implementation Classes in Development
In development, what collection implementation class to choose depends primarily on the business operation characteristics, and then on the collection implementation class characteristics
-
First determine the type of storage (a set of objects [single column] | a set of key-value pairs [double columns])
-
A set of objects [single column]: Collection
-
Allow duplication: List
- Add or delete: linkedList [bottom two-way chain]
- Checklist: ArrayList [bottom is Object type variable array]
-
No duplication allowed: Set
- Unordered: HashSet [HashMap at the bottom, maintaining a hash table (i.e., array + chain list + red-black tree)]
- Sort: TreeSet
- Insert and remove in the same order: LinkedHashSe
-
-
A set of key-value pairs [double columns]: Map
- Key out of order: HashMap [bottom: hash table jdk7 is array + Chain table, jdk8 is array + Chain Table + red-black tree]
- Key sorting: TreeMap
- Keys are inserted and removed in the same order: LinkedHashMap
- Read file: Properties
Collections Tool Class
- Collections is a tool class that manipulates sets, lists, Map s, and so on
- Collections provides a series of static methods for sorting, querying, and modifying collection elements
Sort operation (both static methods)
- reverse(List): Reverses the order of elements in a List
- shuffle(List): Randomly sort the elements of a List collection
- sort(List): Sorts the specified List collection elements in ascending order based on their natural order
- sort(List,Comparator): Sorts List collection elements according to the order in which they are generated by the specified Comparator, usually using anonymous internal classes
- swap(List,int,int): Exchanges elements at i and j in a specified list collection
Find, Replace
- Object max(Collection): Returns the largest element in a given set based on the natural order of the elements
- Object Max (Collection, Comparator): Returns the largest element in a given set in the order specified by the comparator
- Object min(Collection)
- Object min(Collection , Comparator)
- Int frequency (Colleciton, Object): Returns the number of occurrences of a specified element in a specified collection
- Void copy (List dest, List src): Copy the contents of SRC into dest
- Boolean replaceAll (List list, Object oldVal, Object newVal): Replace all old values of the List object with new values