I. Preface
Using Jsoup + HttpClient (combination I) can basically crawl a lot of information we need. The combination of Xpath + HtmlUnit (combination II) is even more powerful, and it can be competent for combination I no matter in terms of selection or analysis. Here is a simple example to show the main technologies: ① simulate browser, ② use proxy IP, ③ cancel CSS, JS parsing, ④ simple use of Xpath
I. other foundations:
① An example of using Xpath: Using xml to save address book information and realize adding, deleting, modifying and checking
② Xpath Basics: XPath syntax
II. Before contact:
①Jsoup+HttpClient: [Java crawler] use Jsoup + HttpClient to crawl web page pictures
Two, demand
Now we need to crawl the title of CSDN's "today's recommendation" (in practice, we should crawl the whole article, which is how many IT communities are built) 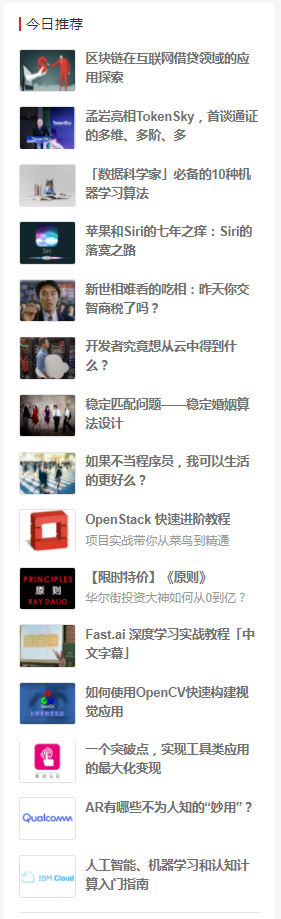
Three, code
package com.cun.test;
import java.io.IOException;
import java.net.MalformedURLException;
import java.util.List;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
/**
* Core technology:
* 1,HtmlUnit Basic usage architecture
* 2,HtmlUnit Simulation browser
* 3,Use proxy IP
* 4,Static web page crawling, cancel CSS and JS support, improve speed
* @author linhongcun
*
*/
public class JsoupHttpClient {
public static void main(String[] args) {
// Instantiate Web client, ① simulate Chrome browser A kind of ② use proxy IP A kind of
WebClient webClient = new WebClient(BrowserVersion.CHROME, "118.114.77.47", 8080);
webClient.getOptions().setCssEnabled(false); // Cancel CSS support A kind of
webClient.getOptions().setJavaScriptEnabled(false); // Cancel JavaScript support A kind of
try {
HtmlPage page = webClient.getPage("https://www.csdn.net/"); // Get page by parsing
/**
* Xpath:Cascade selection A kind of
* ① //: Select nodes in the document from the current nodes that match the selection, regardless of their location
* ② h3: Match < H3 > label
* ③ [@class='company_name']: The value of property name class is company name
* ④ a: Match < a > label
*/
List<HtmlElement> spanList=page.getByXPath("//h3[@class='company_name']/a");
for(int i=0;i<spanList.size();i++) {
//asText ==> innerHTML ✔
System.out.println(i+1+","+spanList.get(i).asText());
}
} catch (FailingHttpStatusCodeException e) {
e.printStackTrace();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
webClient.close(); // Close the client and free the memory
}
}
}
Four, effect

How do you think it's easy?