For reprint, please indicate the source: http://blog.csdn.net/lmj623565791/article/details/23272657
Today, the company has a need to do some data grabbing after the specified website query, so it took some time to write a demo for demonstration.
The idea is simple: you access links through Java, get html strings, and then parse links and other data you need.
Technical use of Jsoup to facilitate page analysis, of course, Jsoup is very convenient and simple, a line of code can know how to use:
The whole implementation process is described below:
- Document doc = Jsoup.connect("http://www.oschina.net/")
- .data("query", "Java") //Request parameters
- .userAgent("I ' m jsoup") //Setting up User-Agent
- .cookie("auth", "token") //Setting cookie s
- .timeout(3000) //Setting connection timeout
- .post(); //Accessing URL s using the POST method
1. Analyzing pages that need to be parsed:
Website: http://www1.sxcredit.gov.cn/public/infocomquery.do?method=publicIndexQuery
Page: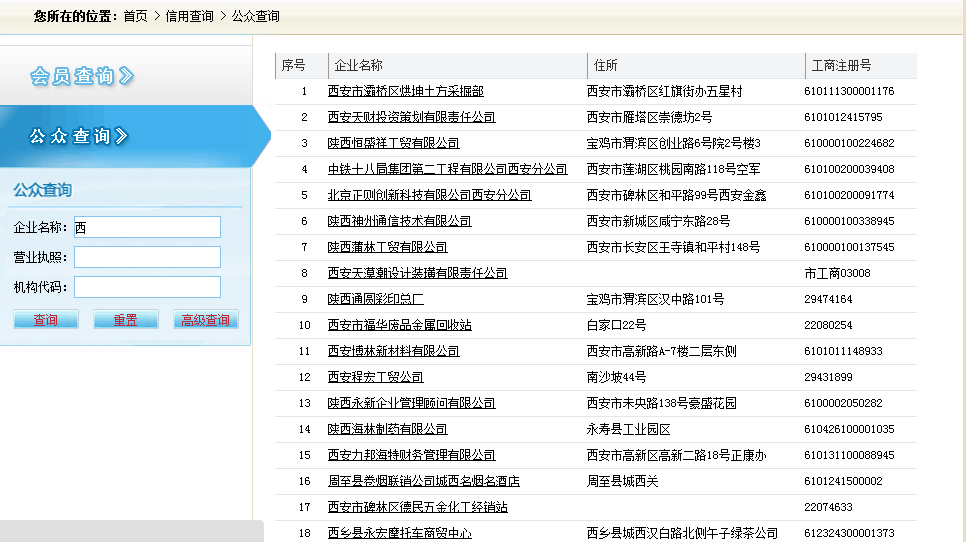
First, make a query on this page: observe the url, parameters, method, etc. of the request.
Here we use chrome's built-in developer tool (shortcut F12). Here's the result of the query:
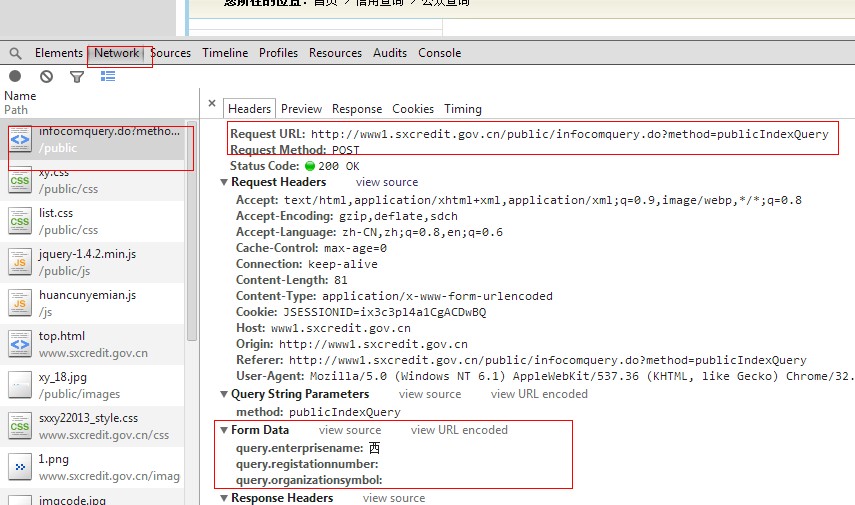
We can see url, method, and parameters. Knowing how to query or the URL, I'll start the code below. To reuse and expand, I define several classes:
1. Rule.java is used to specify query url,method,params, etc.
- package com.zhy.spider.rule;
- /**
- * Rule class
- *
- * @author zhy
- *
- */
- public class Rule
- {
- /**
- * link
- */
- private String url;
- /**
- * Parameter set
- */
- private String[] params;
- /**
- * Values corresponding to parameters
- */
- private String[] values;
- /**
- * For the returned HTML, the label used for the first filtering, set the type first
- */
- private String resultTagName;
- /**
- * CLASS / ID / SELECTION
- * Set the type of resultTagName by default to ID
- */
- private int type = ID ;
- /**
- *GET / POST
- * Type of request, default GET
- */
- private int requestMoethod = GET ;
- public final static int GET = 0 ;
- public final static int POST = 1 ;
- public final static int CLASS = 0;
- public final static int ID = 1;
- public final static int SELECTION = 2;
- public Rule()
- {
- }
- public Rule(String url, String[] params, String[] values,
- String resultTagName, int type, int requestMoethod)
- {
- super();
- this.url = url;
- this.params = params;
- this.values = values;
- this.resultTagName = resultTagName;
- this.type = type;
- this.requestMoethod = requestMoethod;
- }
- public String getUrl()
- {
- return url;
- }
- public void setUrl(String url)
- {
- this.url = url;
- }
- public String[] getParams()
- {
- return params;
- }
- public void setParams(String[] params)
- {
- this.params = params;
- }
- public String[] getValues()
- {
- return values;
- }
- public void setValues(String[] values)
- {
- this.values = values;
- }
- public String getResultTagName()
- {
- return resultTagName;
- }
- public void setResultTagName(String resultTagName)
- {
- this.resultTagName = resultTagName;
- }
- public int getType()
- {
- return type;
- }
- public void setType(int type)
- {
- this.type = type;
- }
- public int getRequestMoethod()
- {
- return requestMoethod;
- }
- public void setRequestMoethod(int requestMoethod)
- {
- this.requestMoethod = requestMoethod;
- }
- }
To put it simply: This rule class defines all the information we need in our query process, facilitates our expansion, and reuses the code. We can't write a set of code for every website we need to crawl.
2. The data object needed only needs links at present, LinkTypeData.java
- package com.zhy.spider.bean;
- public class LinkTypeData
- {
- private int id;
- /**
- * Link Address
- */
- private String linkHref;
- /**
- * Title of the link
- */
- private String linkText;
- /**
- * abstract
- */
- private String summary;
- /**
- * content
- */
- private String content;
- public int getId()
- {
- return id;
- }
- public void setId(int id)
- {
- this.id = id;
- }
- public String getLinkHref()
- {
- return linkHref;
- }
- public void setLinkHref(String linkHref)
- {
- this.linkHref = linkHref;
- }
- public String getLinkText()
- {
- return linkText;
- }
- public void setLinkText(String linkText)
- {
- this.linkText = linkText;
- }
- public String getSummary()
- {
- return summary;
- }
- public void setSummary(String summary)
- {
- this.summary = summary;
- }
- public String getContent()
- {
- return content;
- }
- public void setContent(String content)
- {
- this.content = content;
- }
- }
3. Core query class: ExtractService.java
- package com.zhy.spider.core;
- import java.io.IOException;
- import java.util.ArrayList;
- import java.util.List;
- import java.util.Map;
- import javax.swing.plaf.TextUI;
- import org.jsoup.Connection;
- import org.jsoup.Jsoup;
- import org.jsoup.nodes.Document;
- import org.jsoup.nodes.Element;
- import org.jsoup.select.Elements;
- import com.zhy.spider.bean.LinkTypeData;
- import com.zhy.spider.rule.Rule;
- import com.zhy.spider.rule.RuleException;
- import com.zhy.spider.util.TextUtil;
- /**
- *
- * @author zhy
- *
- */
- public class ExtractService
- {
- /**
- * @param rule
- * @return
- */
- public static List<LinkTypeData> extract(Rule rule)
- {
- //Necessary validation of rule
- validateRule(rule);
- List<LinkTypeData> datas = new ArrayList<LinkTypeData>();
- LinkTypeData data = null;
- try
- {
- /**
- * Parsing rule
- */
- String url = rule.getUrl();
- String[] params = rule.getParams();
- String[] values = rule.getValues();
- String resultTagName = rule.getResultTagName();
- int type = rule.getType();
- int requestType = rule.getRequestMoethod();
- Connection conn = Jsoup.connect(url);
- //Setting query parameters
- if (params != null)
- {
- for (int i = 0; i < params.length; i++)
- {
- conn.data(params[i], values[i]);
- }
- }
- //Setting the request type
- Document doc = null;
- switch (requestType)
- {
- case Rule.GET:
- doc = conn.timeout(100000).get();
- break;
- case Rule.POST:
- doc = conn.timeout(100000).post();
- break;
- }
- //Processing returned data
- Elements results = new Elements();
- switch (type)
- {
- case Rule.CLASS:
- results = doc.getElementsByClass(resultTagName);
- break;
- case Rule.ID:
- Element result = doc.getElementById(resultTagName);
- results.add(result);
- break;
- case Rule.SELECTION:
- results = doc.select(resultTagName);
- break;
- default:
- //Default the body tag when resultTagName is empty
- if (TextUtil.isEmpty(resultTagName))
- {
- results = doc.getElementsByTag("body");
- }
- }
- for (Element result : results)
- {
- Elements links = result.getElementsByTag("a");
- for (Element link : links)
- {
- //Necessary screening
- String linkHref = link.attr("href");
- String linkText = link.text();
- data = new LinkTypeData();
- data.setLinkHref(linkHref);
- data.setLinkText(linkText);
- datas.add(data);
- }
- }
- } catch (IOException e)
- {
- e.printStackTrace();
- }
- return datas;
- }
- /**
- * Necessary validation of incoming parameters
- */
- private static void validateRule(Rule rule)
- {
- String url = rule.getUrl();
- if (TextUtil.isEmpty(url))
- {
- throw new RuleException("url Can't be empty!");
- }
- if (!url.startsWith("http://"))
- {
- throw new RuleException("url The format is incorrect!");
- }
- if (rule.getParams() != null && rule.getValues() != null)
- {
- if (rule.getParams().length != rule.getValues().length)
- {
- throw new RuleException("The key value of the parameter does not match the number!");
- }
- }
- }
- }
4. It uses an exception class: RuleException.java
- package com.zhy.spider.rule;
- public class RuleException extends RuntimeException
- {
- public RuleException()
- {
- super();
- // TODO Auto-generated constructor stub
- }
- public RuleException(String message, Throwable cause)
- {
- super(message, cause);
- // TODO Auto-generated constructor stub
- }
- public RuleException(String message)
- {
- super(message);
- // TODO Auto-generated constructor stub
- }
- public RuleException(Throwable cause)
- {
- super(cause);
- // TODO Auto-generated constructor stub
- }
- }
5. Finally, the test: Here we use two websites to test, using different rules, see the code specifically.
- package com.zhy.spider.test;
- import java.util.List;
- import com.zhy.spider.bean.LinkTypeData;
- import com.zhy.spider.core.ExtractService;
- import com.zhy.spider.rule.Rule;
- public class Test
- {
- @org.junit.Test
- public void getDatasByClass()
- {
- Rule rule = new Rule(
- "http://www1.sxcredit.gov.cn/public/infocomquery.do?method=publicIndexQuery",
- new String[] { "query.enterprisename","query.registationnumber" }, new String[] { "Xing Wan","" },
- "cont_right", Rule.CLASS, Rule.POST);
- List<LinkTypeData> extracts = ExtractService.extract(rule);
- printf(extracts);
- }
- @org.junit.Test
- public void getDatasByCssQuery()
- {
- Rule rule = new Rule("http://www.11315.com/search",
- new String[] { "name" }, new String[] { "Xing Wan" },
- "div.g-mn div.con-model", Rule.SELECTION, Rule.GET);
- List<LinkTypeData> extracts = ExtractService.extract(rule);
- printf(extracts);
- }
- public void printf(List<LinkTypeData> datas)
- {
- for (LinkTypeData data : datas)
- {
- System.out.println(data.getLinkText());
- System.out.println(data.getLinkHref());
- System.out.println("***********************************");
- }
- }
- }
Output results:
- Shenzhen Netxing Technology Co., Ltd.
- http://14603257.11315.com
- ***********************************
- Jingzhou Xingnet Highway Material Co., Ltd.
- http://05155980.11315.com
- ***********************************
- Quanxing Internet Bar in Xi'an City
- #
- ***********************************
- Zichang County New Network City
- #
- ***********************************
- Shaanxi Tongxing Network Information Co., Ltd. Third Branch
- #
- ***********************************
- Xi'an Happy Network Technology Co., Ltd.
- #
- ***********************************
- Shaanxi Tongxing Network Information Co., Ltd. Xi'an Branch
- #
- ***********************************
Finally, we use a Baidu news to test our code: to show that our code is generic.
We only set links, keywords, and request types, without setting specific filter conditions.
- /**
- * Using Baidu News, only set url and keyword and return type
- */
- @org.junit.Test
- public void getDatasByCssQueryUserBaidu()
- {
- Rule rule = new Rule("http://news.baidu.com/ns",
- new String[] { "word" }, new String[] { "Alipay" },
- null, -1, Rule.GET);
- List<LinkTypeData> extracts = ExtractService.extract(rule);
- printf(extracts);
- }
Result: Some garbage data is positive, but the data needed must also be captured. We can set Rule.SECTION and further restrictions on screening conditions.
- Sort by time
- /ns?word=Alipay&ie=utf-8&bs=Alipay&sr=0&cl=2&rn=20&tn=news&ct=0&clk=sortbytime
- ***********************************
- x
- javascript:void(0)
- ***********************************
- Alipay will work together to build safety fund The first batch invested 40 million yuan
- http://finance.ifeng.com/a/20140409/12081871_0.shtml
- ***********************************
- 7 A piece of the same news
- /ns?word=%E6%94%AF%E4%BB%98%E5%AE%9D+cont:2465146414%7C697779368%7C3832159921&same=7&cl=1&tn=news&rn=30&fm=sd
- ***********************************
- Baidu snapshot
- http://cache.baidu.com/c?m=9d78d513d9d437ab4f9e91697d1cc0161d4381132ba7d3020cd0870fd33a541b0120a1ac26510d19879e20345dfe1e4bea876d26605f75a09bbfd91782a6c1352f8a2432721a844a0fd019adc1452fc423875d9dad0ee7cdb168d5f18c&p=c96ec64ad48b2def49bd9b780b64&newp=c4769a4790934ea95ea28e281c4092695912c10e3dd796&user=baidu&fm=sc&query=%D6%A7%B8%B6%B1%A6&qid=a400f3660007a6c5&p1=1
- ***********************************
- OpenSSL Vulnerabilities involve many websites Alipay says there is no data leakage
- http://tech.ifeng.com/internet/detail_2014_04/09/35590390_0.shtml
- ***********************************
- 26 A piece of the same news
- /ns?word=%E6%94%AF%E4%BB%98%E5%AE%9D+cont:3869124100&same=26&cl=1&tn=news&rn=30&fm=sd
- ***********************************
- Baidu snapshot
- http://cache.baidu.com/c?m=9f65cb4a8c8507ed4fece7631050803743438014678387492ac3933fc239045c1c3aa5ec677e4742ce932b2152f4174bed843670340537b0efca8e57dfb08f29288f2c367117845615a71bb8cb31649b66cf04fdea44a7ecff25e5aac5a0da4323c044757e97f1fb4d7017dd1cf4&p=8b2a970d95df11a05aa4c32013&newp=9e39c64ad4dd50fa40bd9b7c5253d8304503c52251d5ce042acc&user=baidu&fm=sc&query=%D6%A7%B8%B6%B1%A6&qid=a400f3660007a6c5&p1=2
- ***********************************
- YAHOO Japan began supporting Alipay payment in June.
- http://www.techweb.com.cn/ucweb/news/id/2025843
- ***********************************