Principle of optimization
Code optimization refers to the equivalent transformation of program code (i.e. the result of running a program without changing it). Program code can be either intermediate code or object code. Equivalence means that the result of code running after transformation is the same as that of code running before transformation. The meaning of optimization is that the final generated object code can work more easily and freely (with shorter running time and less space occupied), and optimize the space-time efficiency.
Code tuning belongs to the category of performance optimization. What is the goal of code optimization that does not deviate from the essence of optimization? When you start coding, you spend most of your time optimizing your code, and it pays to forget the original purpose of software development (helping users solve problems). If the optimization part of the program has little impact on the performance of the program, then we need to consider whether it is necessary to optimize, if we want to optimize when to optimize, this need to be clear. Optimized code will more or less have some impact on system performance, and is one of the most direct, fast and effective ways.Excessive optimization will reduce the readability of the program and increase the difficulty factor for later maintenance personnel. Writing beautiful and efficient code programs is a code solution that every programmer should devote himself to. Programmers can write readable, concise and efficient code to improve the overall performance of the system. I believe that writing programs that meet the above coding standards is the basic quality of efficient programmers.
The program is optimized based on API. For example, write a Java Programs, programmers need to understand Java API provides a trade-off between the use of methods and objects and familiarity with the application scenarios of objects and methods (generally) java The API provides different implementations of an interface. Programmers need to be flexible in using common data types and tools provided by the Java API, and to write efficient programs, they need to understand the corresponding use. data structure Or the working mechanism of the tool method, knowing the advantages and disadvantages of each data structure can make a reasonable choice. Writing programs that conform to Java API application specifications is the basis of code specifications and the prerequisite for code optimization.
Cognitive optimization
The following is from Baidu Encyclopedia: http://baike.baidu.com/link?url=D84XufyCzBwe2HTLBclo6HgZX7wAt9wHVT67TqyYtdnEFeZH4X5xpo_9oGK50LeUOEPL–NsuD9LtEs9fp4H8q
1. Clear optimization objectives
At the beginning of optimization, you haven't defined the content and purpose of optimization yet, so you can easily fall into a misunderstanding. At the outset, you should have a clear understanding of the results you want to achieve, as well as other optimization related issues. These goals need to be clearly stated (at least the technically savvy project manager can understand and express them), and then, throughout the optimization process, you need to adhere to these goals.
Various variables often exist in actual project development. You may want to optimize this aspect at first, and then you may find that you need to optimize the other aspect. In this case, you need to understand these changes clearly and make sure that everyone on the team understands that the goals have changed.
2. Choosing the right optimization index
Choosing the right indicators is an important part of optimization, and you need to measure the progress of optimization according to these indicators. If the indicators are inappropriately chosen or completely wrong, your efforts may be in vain. Even if the indicators are correct, there must be some discrimination. In some cases, it's a practical strategy to put the most effort into the part of the code that consumes the most time to run. But remember, Unix/ Linux Most of the time in the kernel is spent on empty loops. It's important to note that if you choose an easily achievable target easily, it doesn't help much because there's no real problem solving. You need to choose a more complex indicator that is closer to your goal.
3. Finding the Key Points of Optimization
This is the key to effective optimization. Find areas of the project that are contrary to your goals (performance, resources, or other) and use your efforts and time there. For a typical example, a Web project is slow, and developers focus most of their optimization efforts on it. data base In terms of optimization, the real problem is that the network connection is slow. Also, don't be distracted by easy-to-implement problems. Although these problems are easy to solve, they may not be necessary or inconsistent with your goals. Easy optimization doesn't mean it's worth the effort.
4. The higher the optimization level, the better
In general, the higher the level of optimization, the more effective it will be. According to this criterion, the best optimization is to find a more effective one. algorithm . For example, in a software development project, there is an important application performance is poor, so the development team began to optimize, but the performance did not improve too much. Later, the project staff alternated, new developers found that the core of the performance problem is the use of bubble sorting algorithm in the table, resulting in thousands of increases.
Nevertheless, high-level optimization is not a silver bullet. Some basic techniques, such as moving everything out of circular statements, can also produce some optimization effects. Usually, a large number of low-level optimization can produce the same effect as a high-level optimization. It should also be noted that high-level optimization will reduce some code blocks, so the optimization of these blocks before you will have no meaning, so high-level optimization should be considered at the beginning.
5. Don't optimize prematurely
Optimizing early on in a project can make your code difficult to read or affect your performance. On the other hand, in the later part of the project, you may find that the previous optimization did not work and wasted time and energy. The right way is to treat project development and optimization as two separate steps.
6. Performance Analysis Guides Optimization
You tend to think that you already know where to optimize, which is undesirable, especially in complex software systems, performance analysis data should be the first and last intuition. An effective strategy for optimization is to rank according to the impact of the work done on the optimization results. Find the most influential "roadblock" before starting work, and then deal with the small "roadblock".
7. Optimizing is not omnipotent
One of the most important rules of optimization is that you cannot optimize everything, or even two problems at the same time. For example, optimizing speed may increase resource utilization; optimizing storage utilization may slow down other places. You need to weigh which is more in line with your optimization goals.
Optimizing Practice
1. try{}catch() {} Use
Generally, especially important data operations need to catch exceptions so that programmers can know where the error occurred in time, but frequent try {catch(){} will degrade the performance of the system.
[Scenario 1] Do not use try{}catch(){} statements in queries
The best way to remove try{}catch() {} from a general query is to use the try{}catch() {} statement. In CRUD(create, read, update, delete) operations, reading data (R{read}) is a very common mode of operation, which does not have any impact on the data itself, so it is not necessary to use try {catch(){} statement. The use of a single try{}catch(){} statement has little effect on the program, but it is better not to use it, which has no practical significance.
Assuming that the time of a query is 3s, the program simulation is implemented:
Javatest Code
Print results:
- public void tryCatch()
- {
- long before = System.currentTimeMillis();
- try
- {
- new Thread().sleep(3000);
- } catch (Exception e)
- {
- e.printStackTrace();
- }
- long after = System.currentTimeMillis();
- System.out.println("single try catch time consuming:" + (after - before) + "ms");
- }
Single try catch time: 3000ms
[Scenario 2] Do not use try {catch(){} statements in loops
The try{}catch(){} statement is a time-consuming process, and the longer the loop length in the for loop, the more times try{}catch(){}.
Java test code
Test results:
- public void tryCatchOperateInLoop(long times)
- {
- long before = System.currentTimeMillis();
- for (int i = 0; i < times; i++)
- {
- try
- {
- new Thread();
- } catch (Exception e)
- {
- e.printStackTrace();
- }
- }
- long after = System.currentTimeMillis();
- System.out.println("implement try catch Cyclic time-consuming:" + (after - before) + "ms");
- }
- public void noTryCatchOperateInLoop(long times)
- {
- long before = System.currentTimeMillis();
- for (int i = 0; i < times; i++)
- {
- new Thread();
- }
- long after = System.currentTimeMillis();
- System.out.println("wrong try catch Cyclic time-consuming:" + (after - before) + "ms");
- }
Cycle 10000 times, execution of try catch cycle time: 32 ms; non-try catch cycle time: 15 ms.
[Scenario 3] try{}catch(){} exception handling
The try{}catch(){} statement is used to capture possible exceptions. Instead of using Exception for all exceptions, it is better to capture the corresponding exception type. When an exception is caught, it needs to be handled accordingly, but most people don't. They print an e.printStackTrace(); that's all. That's not good.
The function of exception capture is to do some remedial measures after the exception occurs, so that the program can continue to run. The simple sentence e.printStackTrace(); is not to deal with exceptions, but more of the consequences of the program can no longer be executed.
Processing logs:
1. Print error log
2. Calling error business logic processing function
3. Jump error prompt page
Scenario 4 Destroy objects or release resources in final try{}catch(){}
The final block code will be accessed regardless of whether try {catch(){} has an exception or not, so we can do some resource release and object destruction work here to reduce unnecessary resource occupation.
Java code example:
The above code is part of the file writing.
- try
- {
- os.write(byteBuffer);
- } catch (Exception e)
- {
- e.printStackTrace();
- } finally
- {
- os.close();//Releasing resources
- os = null;
- destfile = null;
- }
Scenario 5 If there is an exception to the interface provided to the outside world, it will be thrown.
In interface invocation, if there may be exceptions in the implementation that need to be handled or thrown, it will be convenient for developers to debug the positioning problem; if the interface implementer is hidden, the positioning problem will be a troublesome thing.
Java code:
- package com.boonya.test;
- public interface IObjectService {
- public void printFiles() throws Exception;
- }
2. Reduce the use of new keywords to create objects
In Java programs, object creation and destruction is a heavyweight operation, which increases system performance overhead and reduces system performance, and it does not guarantee that objects will perform GC operations immediately when they are not in use. In addition, initializing an object by default steals its parametric constructor. In most cases, we don't want to call its constructor when initializing an object.
[Scenario 1] Avoid using new keywords to create objects in loops
The following is illustrated by an example:
Java test code
Test results:
- public void noTryCatchOperateInLoop(long times)
- {
- long before = System.currentTimeMillis();
- for (int i = 0; i < times; i++)
- {
- new Object();
- }
- long after = System.currentTimeMillis();
- System.out.println("Cyclic time-consuming:" + (after - before) + "ms");
- }
Taking 10,000 times as the test standard, the result is: cycle time: 16 ms; if new Object(); comment out, print result is: cycle time: 0 ms; from this we can see that object creation is a big expense.
Scenario 2 Create objects only when they are necessary
In some cases, we don't need to create extra variables or objects at all, but we can't help doing so sometimes or inadvertently.
Java test code
In fact, s here does not need to be created, because developers are accustomed to using data types to return objects or values. The above code can be written as follows:
- public String judgeStatus(int flag)
- {
- String s = new String("Success");
- if (flag == 0)
- {
- s = "Failure";
- }
- return s;
- }
In addition, declare the object in the scope of the object:
- public String judgeStatus(int flag)
- {
- if (flag == 0)
- {
- return "Failure";
- }
- return "Success";
- }
- public Object test(int flag)
- {
- if (flag == 1)
- {
- return new Object();
- }
- return null;
- }
3. Can Multiplication and Division Use Shift Operations
Scenario 1: Is the multiplier or divisor the square root of 2?
Java test code
Many algorithms in Java use shift operation in multiplication and division calculation, which greatly reduces the calculation time and improves the efficiency of the algorithm.
- //Left shift operation time is a power of 2
- public long numberLeftCalculate(long number, int times)
- {
- return number << times;
- }
- //Right shift operation times is a power of 2
- public long numberRightCalculate(long number, int times)
- {
- return number >> times;
- }
Scenario 2 Multiplication and division arithmetic occurs repeatedly in a loop
As we all know, shift operation is the fastest way to operate binary data, and what computer can recognize is binary data 0 and 1. Its calculation only adds or subtracts a number of zeros to the left or right after the binary number without calculation, so the efficiency of reading operation is very high. In decimal data operations, the computer converts decimal numbers (at least twice) into recognizable binary numbers, and then multiplies or divides the binary numbers.
Java test code
- public void perplexingLoop(int j)
- {
- int s = 0;
- for (int i = 0; i <= j; i++)
- {
- int a = i * 8;
- int b = a / 4;
- //Computation of complex a-b multiplication-Division relations
- // .................
- s += a + b;
- }
- System.out.println("s1=" + s);
- }
- public void perplexingLoop2(int j)
- {
- int s = 0;
- for (int i = 0; i <= j; i++)
- {
- int a = i << 3;
- int b = a >> 2;
- //Computation of complex a-b multiplication-Division relations
- // .................
- s += a + b;
- }
- System.out.println("s2=" + s);
- }
Execute 1000000 cycles, respectively
Test results: s1=663067456, s2=663067456, there may be no difference here, but more multiplication and division operations in for loop can be reflected.
4. Writing of Attention Cycle
Scenario 1 Reduces the number of loops read by variables
To determine the number of cycles in advance, it is no longer necessary to calculate the number of cycles in the future.
Java test code
Instead of calculating the boundary size every time, it's better to write it as follows:
- for (int i = 0; i < list.size(); i++)
- {
- //Every time i'm going to decide if i's on the list.size() boundary.
- }
Scenario 2 Nested loops in loops write small loops out
- for (int i = 0,j=list.size(); i < j; i++)
- {
- //j is a local variable initialized only once
- }
Large loops nest small loops, and too many outer loops cause continuous switching between loops, which also increases system overhead.
Java test code
The test results showed that the time consumed for small-scale and large-scale loops was 266 MS and 312 MS respectively.
- public void complexLoop()
- {
- long before = System.currentTimeMillis();
- for (int i = 0; i < 10; i++)
- {
- for (int j = 0; j < 1000000; j++)
- {
- new String();
- }
- }
- long after = System.currentTimeMillis();
- System.out.println("Small inlay large cycle time-consuming:" + (after - before) + "ms");
- long before2 = System.currentTimeMillis();
- for (int i = 0; i < 1000000; i++)
- {
- for (int j = 0; j < 10; j++)
- {
- new String();
- }
- }
- long after2 = System.currentTimeMillis();
- System.out.println("Large embedded small cycle time-consuming:" + (after2 - before2) + "ms");
- }
Scenario 3 Don't declare objects frequently in loops
As mentioned in [2], [Scenario 2], don't create objects arbitrarily, which will reduce the efficiency of program execution, as well as in loops.
Test for length 1 million times:
- //Mode 1
- public List<Map<String, Object>> createMapList()
- {
- List<Map<String, Object>> maplist = new ArrayList<Map<String, Object>>();
- for (int i = 0, j = 1000000; i < j; i++)
- {
- Map<String, Object> map = new HashMap<String, Object>();//Create a heap space to store the object once per loop and create a reference to the object in the stack
- map.put("ms" + 1, "hello_" + i);
- maplist.add(map);
- }
- return maplist;
- }
- //Mode 2
- public List<Map<String, Object>> createMapList2()
- {
- List<Map<String, Object>> maplist = new ArrayList<Map<String, Object>>();
- Map<String, Object> map;
- for (int i = 0, j = 1000000; i < j; i++)
- {
- map = new HashMap<String, Object>();//No more declarations every time
- map.put("ms" + 1, "hello_" + i);
- maplist.add(map);
- }
- return maplist;
- }
Method 1: 4141ms
Method 1: 4078ms
Conclusion: Mode 2 is more efficient than mode 1.
[Scenario 4] Don't call synchronization methods in loops
As long as hooking up with synchronization is a time-consuming operation, if the time complexity of synchronization method execution is 1, then the time complexity of calling synchronization method in a loop is n, so it is recommended not to do so.
Java code:
This is inefficient unless the method requires synchronization.
- private static boolean isUsingLock = false;
- public synchronized void operate()
- {
- isUsingLock = true;
- // do somthing
- isUsingLock = false;
- }
- public void dowork(int n)
- {
- for (int i = 0; i < n; i++)
- {
- this.operate();
- }
- }
[Scenario 5] Avoid query operations in loops as much as possible
Queries are also a cause of system performance degradation, especially frequent access to database operations. Similarly, if the time complexity of synchronization method execution is 1, then the time complexity of calling synchronization method in a loop is n, which is basically consistent with the effect of applying a loop in a loop.
Java code:
- public void queryData(int n)
- {
- for (int i = 0; i < n; i++)
- {
- // database query
- }
- }
Except for cross-table queries, this approach is generally not used.
5. Realizing String Splicing
[Scenario 1] String
The stitching of immutable character data classes is equivalent to introducing an intermediate temporary variable every time the "+=" is used, so this method is the most worthy of criticism.
Java code
Adding more than once declares a temporary hidden variable.
- public void exampleString(int arg1, int arg2, int arg3)
- {
- String sb = new String("Name of parameter: ");
- if (arg1 == 0)
- {
- sb += " arg1xxxxx0";
- } else
- {
- sb += " arg1xxxxx-1";
- }
- if (arg2 == 0)
- {
- sb += " arg2xxxxx0";
- } else
- {
- sb += " arg2xxxxx-1";
- }
- if (arg3 == 0)
- {
- sb += " arg3xxxxx0";
- } else
- {
- sb += " arg3xxxxx-1";
- }
- System.out.println(sb);
- }
[Scenario 2] String Builder
Variable string objects can ensure that only one StringBuffer object in the current thread is changing the length of the string, but this object is not thread-safe.
It is more efficient than StringBuffer because synchronization is not required.
- public void exampleStringBuilder(int arg1, int arg2, int arg3)
- {
- StringBuilder sb = new StringBuilder("Name of parameter: ");
- if (arg1 == 0)
- {
- sb.append(" arg1xxxxx0");
- } else
- {
- sb.append(" arg1xxxxx-1");
- }
- if (arg2 == 0)
- {
- sb.append(" arg2xxxxx0");
- } else
- {
- sb.append(" arg2xxxxx-1");
- }
- if (arg3 == 0)
- {
- sb.append(" arg3xxxxx0");
- } else
- {
- sb.append(" arg3xxxxx-1");
- }
- System.out.println(sb.toString());
- }
[Scenario 3] String Buffer
Variable string object, which is thread-safe, ensures that only one StringBuffer object in the current thread is changing the length of the string.
Java code
String Buffer is often used in database SQL statement splicing, so String Buffer is usually used in string splicing.
- public void exampleStringBuffer(int arg1, int arg2, int arg3)
- {
- StringBuffer sb = new StringBuffer("Name of parameter: ");
- if (arg1 == 0)
- {
- sb.append(" arg1xxxxx0");
- } else
- {
- sb.append(" arg1xxxxx-1");
- }
- if (arg2 == 0)
- {
- sb.append(" arg2xxxxx0");
- } else
- {
- sb.append(" arg2xxxxx-1");
- }
- if (arg3 == 0)
- {
- sb.append(" arg3xxxxx0");
- } else
- {
- sb.append(" arg3xxxxx-1");
- }
- System.out.println(sb.toString());
- }
[Scenario 4] Single characters are added in place of''
String string addition is not a wise choice. Here we talk about single character splicing. Because''works on char data, it's better than String. Obviously, using String Buffer here is a waste.
Java code
- //Examples:
- public void method(String s)
- {
- String string = s + "d";
- string = "abc" + "d";
- System.out.println(string);
- }
- //Correction: Replace the string of a character with''
- public void method2(String s)
- {
- String string = s + 'd';
- string = "abc" + 'd';
- System.out.println(string);
- }
6. Improving the traversal efficiency of HashMap
Hashmap implements the Map interface, the bottom of which is to use Entry object to operate key and value. The traversal of Map is to use Hash value to extract the corresponding Entry to compare the results.
Java test code
- public void foreachHashMap()
- {
- Map<String, String[]> paraMap = new HashMap<String, String[]>();
- for (int i = 0; i < 1000000; i++)
- {
- paraMap.put("test" + i, new String[]
- { "s" + i });
- }
- String[] values;
- //The first cycle
- long before = System.currentTimeMillis();
- Set<String> appFieldDefIds = paraMap.keySet();
- for (String appFieldDefId : appFieldDefIds)
- {
- values = paraMap.get(appFieldDefId);
- // System.out.println(values[0]);
- }
- long after = System.currentTimeMillis();
- System.out.println("HashMap ergodic:" + (after - before) + "ms");
- //Second cycle
- long before2 = System.currentTimeMillis();
- for (Entry<String, String[]> entry : paraMap.entrySet())
- {
- values = entry.getValue();
- // System.out.println(values[0]);
- }
- long after2 = System.currentTimeMillis();
- System.out.println("HashMap ergodic:" + (after2 - before2) + "ms");
- }
Test results: HashMap traversal: 93ms, HashMap traversal: 63ms
When the number of cycles is 10000, print:
HashMap traversal: 15ms
HashMap traversal: 0ms
As far as the method itself is concerned, using the first loop is equivalent to entering the Entry of HashMap twice.
The second loop takes value directly after it gets the value of Entry, which is more efficient than the first one.
7. Use local variables as much as possible
Use local variables as much as possible. The parameters passed when calling methods and the temporary variables created in the calls are saved in the Stack, which is faster. Other variables, such as static variables, instance variables, etc., are created in Heap, which is slower.
Java test code
- public static int increment_no;
- public void forLoop()
- {
- long before = System.currentTimeMillis();
- for (int i = 0; i < 10000000; i++)
- {
- increment_no += i;
- }
- long after = System.currentTimeMillis();
- System.out.println("Variable Testing:" + increment_no + " " + (after - before) + "ms");
- }
- public void forLoop2()
- {
- int no = 0;
- long before = System.currentTimeMillis();
- for (int i = 0; i < 10000000; i++)
- {
- no += i;
- }
- long after = System.currentTimeMillis();
- System.out.println("Variable Testing:" + no + " " + (after - before) + "ms");
- }
Test results:
Variable test: - 201426003231ms
Variable test: - 20142600320ms
8. Realize object reuse as much as possible
The system takes time to generate objects, and then it takes time to recycle and dispose of these objects. Therefore, generating too many objects will have a great impact on the performance of the program.
Scenario 1 String object reuse
The reuse of string objects is to reduce the declaration of string variables, while some declarations are invisible and need to be noted.
Java code
The String class "+=" operation is implemented by declaring intermediate variables, while String Buffer is equivalent to a container. String Buffer is added to the container continuously without the need for other containers to assist in the implementation. As you can see, String Buffer can also be used for string object reuse.
- //String is an immutable character, str "+=" corresponds to String temp=array[0];str=str+temp;
- public String getString(String array[])
- {
- String str = "";
- for (int i = 0; i < array.length; i++)
- {
- str += array[i];
- }
- return str;
- }
- //StringBuffer is a variable character, and strings are stitched together to operate on an object
- public String getString2(String array[])
- {
- StringBuffer sb = new StringBuffer();
- for (int i = 0; i < array.length; i++)
- {
- sb.append(array[i]);
- }
- return sb.toString();
- }
Scenario 2: Reuse of declared objects
Object creation and destruction (garbage collection mechanism GC) are at the expense of system performance.
Java code
The creation of an Object for getObjectList() in the above code is an unwise practice.
- public List<Object> getObjectList()
- {
- List<Object> list = new ArrayList<Object>();
- for (int i = 0; i < 100; i++)
- {
- Object obj = new Object();
- list.add(obj);
- }
- return list;
- }
- public List<Object> getObjectList2()
- {
- List<Object> list = new ArrayList<Object>();
- Object obj;
- for (int i = 0; i < 100; i++)
- {
- obj = new Object();
- list.add(obj);
- }
- return list;
- }
Scenario 3 Reduces Object Initialization
By default, when calling the constructor of a class, Java initializes the variable to a fixed value: all string variables are set to null, integer variables (byte, short, int, long) to 0, float and double variables to 0.0, and logical values to false.
Take the singleton pattern as an example to reduce the system performance consumption caused by frequent object creation.
Java code
If it's not a singleton pattern, but frequent initialization using inherited subclasses, then it will frequently call the constructor of the parent class, which is also not recommended.
- public class PlusSingleton
- {
- /**
- * Ensure that externalities cannot be instantiated, even if the new keyword is invalid
- */
- private PlusSingleton()
- {
- System.out.println("singleton constructor");
- }
- /**
- * Initial swap call of internal class JVM
- */
- private static class SingletonObject
- {
- private static PlusSingleton singleton = new PlusSingleton();
- }
- /**
- * No need to consider multithreading
- */
- public static PlusSingleton getInstance()
- {
- return SingletonObject.singleton;
- }
- }
[Scenario 4] Rational Use of Inheritance and Abstraction
If a class is an extension or extension of another class, then we can consider whether inheritance can be used, and we need to weigh whether the object is subject to the parent class after using inheritance and whether it reduces flexibility. Inheritance only inherits the characteristics of the parent class, but it can not understand everything of the parent class, such as private functions, attributes and so on.
Java code:
- public class Father
- {
- private String name;
- private int age;
- public String getName()
- {
- return name;
- }
- public void setName(String name)
- {
- this.name = name;
- }
- public int getAge()
- {
- return age;
- }
- public void setAge(int age)
- {
- this.age = age;
- }
- @SuppressWarnings("unused")
- private void playCard()
- {
- System.out.println("Playing cards");
- }
- }
- public class Son extends Father
- {
- public void work()
- {
- System.out.println("Work");
- }
- }
Although both sons and fathers have names and ages, sons do not know that fathers can play cards and fathers do not know that sons can work. If the father's private method is changed carelessly, the son will learn to play cards. If the son enjoys playing cards, will he forget his work? So, inheritance is not everything. The subclass will be influenced by the father, so it's better to use inheritance carefully. Obviously, sons can refuse to play cards at work, but they need to increase the logic of not playing cards at work. At this point, you can consider using abstract classes to achieve, not the need to use inheritance affected by the parent class.
Java code:
- public abstract class AbstractClass
- {
- private String name;
- private int age;
- public String getName()
- {
- return name;
- }
- public void setName(String name)
- {
- this.name = name;
- }
- public int getAge()
- {
- return age;
- }
- public void setAge(int age)
- {
- this.age = age;
- }
- public abstract void playCard();
- }
Now Father and Son inherit this abstract class to implement their own playing rules:
In the past, my son was not accustomed to his father playing cards, so he was ashamed of setting rules for himself to play cards. From this, we can see that Father and Son have broken off the relationship between father and son.
- public class Father extends AbstractClass
- {
- public void playCard()
- {
- System.out.println("Play cards,Endless fighting");
- }
- }
- public class Son extends AbstractClass
- {
- public void work()
- {
- System.out.println("Work");
- }
- public void playCard()
- {
- System.out.println("Playing rules: you can't play cards during working hours, you can only work");
- }
- }
9. Release of idle resources
In the process of Java programming, you must be careful in database connection and I/O flow operation, even when closed to release resources after use. Because the operation of these large objects will cause large overhead of the system, slightly inadvertent, will lead to serious consequences.
[Scenario 1] Remember to disconnect the database access link
Database operation is a heavyweight operation. Although database connection pool can be established, if the established connection is not released after use, there will soon be no idle connection in the database connection pool for use, so timely recovery of database resources is the best way to avoid the thread pool being left unavailable. Over-occupied system resources will lead to slow programs, resulting in false deaths. Therefore, a strict coding habit is needed to avoid these problems.
Java code:
- /**
- * Release resource occupancy
- *
- * @param con
- * Database Links
- * @param stmt
- * Database declaration operation
- * @param res
- * data set
- */
- public static void setItFree(Connection con, Statement stmt, ResultSet res)
- {
- try
- {
- if (res != null)
- {
- res.close();
- }
- res = null;
- } catch (Exception e)
- {
- e.printStackTrace();
- }
- try
- {
- if (stmt != null)
- {
- stmt.close();
- }
- stmt = null;
- } catch (Exception e)
- {
- e.printStackTrace();
- }
- try
- {
- if (con != null)
- {
- con.close();
- }
- con = null;
- } catch (Exception e)
- {
- e.printStackTrace();
- }
- }
The above is the release of JDBC database access resources. hibernate There's no need to do that, because Hibernate has already done this for us.
[Scenario 2] Remember to turn off I/O input and output streams
File input and output operations need to close the flow of input and output, if not, it will occupy CPU resources and reduce system performance.
Java code:
It is recommended that the resources be released together after the output of the document is completed.
- public void fileOperate() throws IOException
- {
- //Getting input stream
- File srcfile = new File("D:\\myfiles\\my.txt");
- InputStream is = new FileInputStream(srcfile);
- //Obtain the output stream
- File destfile = new File("D:\\myfiles\\test.txt");
- OutputStream os = new FileOutputStream(destfile);
- byte[] byteBuffer = null;
- try
- {
- byteBuffer = new byte[1024];
- while (is.read(byteBuffer) != -1)
- {
- System.out.println(byteBuffer.length);
- }
- } catch (Exception e)
- {
- e.printStackTrace();
- } finally
- {
- is.close();//Releasing resources
- is = null;
- srcfile = null;
- }
- try
- {
- os.write(byteBuffer);
- } catch (Exception e)
- {
- e.printStackTrace();
- } finally
- {
- os.close();//Releasing resources
- os = null;
- destfile = null;
- }
- }
[Scenario 3] Empty the object after it has been used
Because JVM has its own GC mechanism, it does not need too much consideration of programmers, which reduces the burden of developers to a certain extent, but also omits hidden dangers. Excessive creation of objects will consume a large amount of memory of the system, which will lead to memory leaks in serious cases. Therefore, it is of great significance to ensure timely recovery of expired objects. JVM garbage collection conditions are: objects are not referenced; however, the GC of JVM is not very clever, even if the object meets the garbage collection conditions, it will not necessarily be immediately recycled. Therefore, it is suggested that we should manually set null after using the object.
Java code:
This clears the memory that the list occupies.
- public Map<String, Object> getObjects()
- {
- Map<String, Object> map = new HashMap<String, Object>();
- List<Object> list = new ArrayList<Object>();
- Object obj;
- for (int i = 0; i < 100; i++)
- {
- obj = new Object();
- list.add(obj);
- }
- map.put("objects", list);
- list = null;
- return map;
- }
10. Use of ArrayList, Vector and LinkedList
The List interface has three implementation classes: ArrayList, Vector and LinkedList. List is used to store multiple elements, to maintain the order of elements, and to allow repetition of elements.
[Scenario 1] ArrayList implements random search and traversal
ArrayList is the most commonly used List implementation class, which is implemented internally through arrays, allowing quick random access to elements. The disadvantage of arrays is that there can be no interval between each element. When the size of arrays is not enough, storage capacity needs to be increased. It is necessary to say that the data of the existing arrays are copied into the new storage space. When inserting or deleting elements from the middle of an ArrayList, the array needs to be copied, moved, and expensive. Therefore, it is suitable for random search and traversal, not for insertion and deletion.
Java code:
[Scenario 2] Vector implements array synchronization
- public void myArrayList(ArrayList<String> list)
- {
- for (int i = 0, j = list.size(); i < j; i++)
- {
- System.out.println(list.get(i));
- }
- }
Vector, like ArrayList, is also implemented through arrays. The difference is that it supports thread synchronization, i.e. only one thread can write Vector at a certain time to avoid inconsistencies caused by multi-threaded simultaneous writing, but synchronization requires a high cost, so accessing it is slower than accessing ArrayList.
Java code:
- public void myVectorList(Vector<String> list, String s)
- {
- for (int i = 0, j = list.size(); i < j; i++)
- {
- if (list.get(i).equals(s))
- {
- //Modified values
- list.add(i, i + "update");
- }
- }
- }
[Scenario 3] Dynamic insertion and deletion of LinkedList data
LinkedList uses linked list structure to store data. It is very suitable for dynamic insertion and deletion of data. Random access and traversal speed are relatively slow. In addition, he provides methods that are not defined in the List interface for manipulating table header and tail elements, which can be used as stacks, queues, and bidirectional queues.
Java code:
- public void myLinkedList(LinkedList<String> list, String s)
- {
- for (int i = 0, j = list.size() - 10; i < j; i++)
- {
- list.pop();
- }
- if (list.size() == 0)
- {
- list.add(0, "ss");
- } else
- {
- list.removeAll(list);
- }
- }
11. Use of synchronized
Synchronization of [Scenario 1] Methods
Method synchronization: Once a thread accesses the method, the method will fall into waiting or blocking. Only when the user thread method is unlocked, it can be invoked by other threads.
Java code:
It is necessary to operate serial process processing.
- private static boolean isUsingLock = false;
- public synchronized void operate()
- {
- isUsingLock = true;
- // do somthing
- isUsingLock = false;
- }
Scenario 2 Synchronization of Code Blocks
This synchronization exists to ensure a special object operation in a thread, for example, when multiple users have the right to operate on the same common resource, they need to use this method to achieve the synchronization of resources.
- private static String name = "";
- public void operate2()
- {
- synchronized (name)
- {
- if (name.equals(""))
- {
- name = "boonya";
- }
- }
- }
12. Ternary expressions instead of if else
Simplifying logical judgment is to make the code clearer and clearer at a glance.
- public String express(boolean flag)
- {
- return flag ? "Success" : "Failure";
- }
13. String Tokenizer instead of substring() and indexOf()
StringTokenizer is a subclass of object class in java. It inherits from the object of Enumeration (public interface Enumeration < E > which implements the Enumeration interface. It generates a series of elements, one at a time). Interface.
String Tokenizer can be understood as String's character marker object, which can implement string interception operation, avoiding the problem that strings easily lead to String Indexed OfBoundsException. Its constructor has the following three forms:
·public StringTokenizer(String str,String delim,boolean returnTokens);
·public StringTokenizer(String str,String delim);
· Public String Tokenizer (String str); where STR is the string to be analyzed and delim is the delimiter, Tokens describes whether to treat the delimiter as a token.
Java code example:
The results are printed as boonya
- public void stringTokenizerSubstring()
- {
- String str = "boonya@sina.com";
- String s1 = new StringTokenizer(str).nextToken("@");
- System.out.println(s1);
- }
- public void stringTokenizerIndexof()
- {
- String str = "boonya@sina.com";
- String s1 = new StringTokenizer(str, "@", true).nextToken();
- System.out.println(s1);
- }
14. System.arraycopy() implements a copy of the array value
Replication between two arrays is recommended not to use loops. Java provides a way to copy arrays.
Java code:
Print results: 0,1,2,3,4,5,6,7,8,9,
- public void arrayCopy()
- {
- int[] array1 = new int[10];
- for (int i = 0; i < array1.length; i++)
- {
- array1[i] = i;
- }
- int[] array2 = new int[10];
- System.arraycopy(array1, 0, array2, 0, 10);
- for (int i = 0; i < array2.length; i++)
- {
- System.out.print(array2[i] + ",");
- }
- }
Note: Although the List is based on the implementation of arrays, System.arraycopy(list1, 0, list2, 0, n) cannot be used here for fetching; although the code was compiled, runtime exceptions will be thrown.
15. instanceof determines the interface rather than the implementation class of the interface
Interface-based design is usually a good thing because it allows for different implementations while remaining flexible. Whenever possible, instanceof operations are performed on an object to determine whether an interface is faster than a class.
Java code:
So, we judge interfaces, not ordinary classes or implementation classes of interfaces.
- public interface IObject
- {
- }
- public class ObjectImpl implements IObject
- {
- }
- public void instanceOf(Object obj)
- {
- // better
- if (obj instanceof IObject)
- {
- }
- // worse
- if (obj instanceof ObjectImpl)
- {
- }
- }
16. Static invariant instances in classes
If a variable in a class does not change with its instance, it can be defined as a static variable so that all its instances share the variable.
Java code:
- public class AlarmDao extends BaseDao<Alarm>
- {
- private static SortUtil<Alarm> sortUtil = new SortUtil<Alarm>();
- }
17. Reduce unnecessary database query operations
If there are two or more identical query operations in a query, you can consider caching the results of the first query. In this query, subsequent queries can read the cached object.
See the sketch below before optimizing:
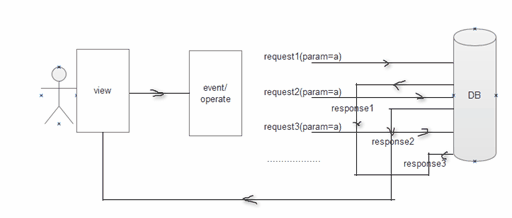
After optimization:
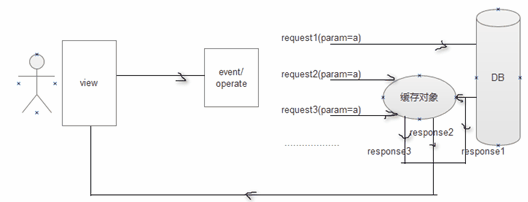
There are many caching solutions, such as Cache, Cache4j, Memcached, and Hcache provided by Hibernate.
18. Specify final modifiers for classes whenever possible
Classes with final modifiers are not derived. In the Java core API, there are many examples of applying final, such as java.lang.String. Specifying final for the String class prevents people from overwriting the length() method. In addition, if you specify a class as final, all methods of that class are final. Java compiler will look for opportunity inline. [Inline function means that the function expands directly where it is called. When the compiler calls, it does not need to be like ordinary function, parameter stack, parameter stack and resource release when it returns, which improves the speed of program execution. ] All final methods (this is related to specific compiler implementations). This can increase performance by an average of 50%.
Java code:
// Indicates that this behavior is unchangeable
public final void doWork(){
//doSomething
}
It is feasible for the getter/setter method of the attribute field of a general entity object to become "final" because basically no one has modified these methods.
19. Find only a single character and replace startsWith() with charAt()
Calling startsWith() with a character as a parameter would also work well, but from a performance point of view, calling String API is undoubtedly inappropriate!
Java code:
- public void findCharExists()
- {
- String str = "boonya@sina.com";
- // startsWith
- if (str.startsWith("b"))
- {
- System.out.println("existence b");
- }
- // charAt
- if ('b' == str.charAt(0))
- {
- System.out.println("existence b");
- }
- // charAt
- if ('@' == str.charAt(6))
- {
- System.out.println("existence@");
- }
- }
20. transient Modified Fields Avoid Serialized Persistence Operations
Adding transients to field descriptions indicates that an attribute is temporary, not serialized or persistent. Java serialization provides a mechanism for persistent object instances. When persisting an object, there may be a special object data member, and we don't want to use serialization mechanism to save it. In order to close serialization on a domain of a particular object, you can add the keyword transient before that domain. Transient is the keyword of the Java language to indicate that a domain is not part of the serialization of the object. When an object is serialized, the value of transients is not included in the serialized representation, whereas non-transients are included.
Java code:
This feature is also supported in Hibernate. If there is a field in the entity class of Hibernate annotation that does not exist in the database, you need to add the @Transient annotation to the field, which will not be mapped and will not be persisted.
- import java.io.Serializable;
- public class Person implements Serializable
- {
- private static final long serialVersionUID = -36370127660133224L;
- //Name
- private String name;
- //Mailbox
- private String email;
- //Identity card (temporary field, this information is from exclusive files, no serial operation is required)
- private transient String idCard;
- public String getName()
- {
- return name;
- }
- public void setName(String name)
- {
- this.name = name;
- }
- public String getEmail()
- {
- return email;
- }
- public void setEmail(String email)
- {
- this.email = email;
- }
- public String getIdCard()
- {
- return idCard;
- }
- public void setIdCard(String idCard)
- {
- this.idCard = idCard;
- }
- }
Java code:
- @Transient
- private String factoryDeviceId;//Non-database Field > Device Number
21. Clean up the redundant code in the program
Scenario 1 Delete unnecessary test code
Delete the test method in the code, and the code is no longer used for users after the project is deployed, so there is no need to retain it.
Java code:
This method belongs to the static method of class, which is loaded into memory when class loading is initialized. For this kind of method, the main function is visible elsewhere, so it should be removed.
- public static void main(String[] args) throws IOException
- {
- ObjectReuse or = new ObjectReuse();
- or.arrayCopy();
- }
Java code:
- try
- {
- ObjectReuse.main(new String[]
- { "a", "b", "c" });
- } catch (IOException e)
- {
- e.printStackTrace();
- }
Scenario 2 Delete invalid lines
Invalid lines of code can also bring workload to the compiler, so it is recommended to remove them.
Java code:
The compiler will determine whether the line for "//" ends or not, and the "/*/" comment is the same.
- private double toPercent(int y, int z)
- {
- //String result = ";// Acceptance Percentage Value
- double baiy = y * 1.0;
- double baiz = z * 1.0;
- double fen = (baiy / baiz) * 100;
- //NumberFormat nf = NumberFormat.getPercentInstance(); // Annotated is another method
- //Nf.setMinimum FractionDigits (2); //Reserved to decimal places
- // DecimalFormat df1 = new DecimalFormat("##.00%"); // ##.00%
- //// Percentage format, followed by less than 2 bits with 0
- // result = nf.format(fen);
- return fen;
- }
- //Cleaned Java code:
- private double toPercent(int y, int z)
- {
- double baiy = y * 1.0;
- double baiz = z * 1.0;
- double fen = (baiy / baiz) * 100;
- return fen;
- }
[Scenario 3] Delete irregular comments
Some comments have no practical meaning at all, so delete them decisively.
It's really a headache to see such bad comments flooding everywhere and to omit even the basic parameter descriptions. Either delete it directly or fill in the comments completely. Deleting is simple and won't take much time, but it's illustrated here with a complete comment.
- /*
- * (Non-Javadoc)
- * <p>Title:Query DeviceMember based on parameters</p>
- * <p>Description: </p>
- * @param dm
- * @param page
- * @param rows
- * @return
- * @see
- * com.kvt.lbs.system.service.IDeviceService#getDeviceMemberList(com.kvt
- * .lbs.system.entity.DeviceMember, int, int)
- */
- @Override
- public Map<String, Object> getDeviceMemberList(DeviceMember dm, int page, int rows, String sortName, String sortOrder)
- {
- return deviceMemberDao.getDeviceMember(dm, page, rows, sortName, sortOrder);
- }
Java code:
If you want to write comments, write them clearly. Don't let people who read code or use this method guess the meaning of parameters.
- /**
- * Query DeviceMember data based on incoming parameters
- *
- * @param dm
- * Device Object
- * @param page
- * Paging Index
- * @param rows
- * Number of entries per page
- * @param sortName
- * sort field
- * @param sortOrder
- * Sort type
- * @return Map<String, Object> Device Paging Data Attribute Object
- */
- public Map<String, Object> getDeviceMemberList(DeviceMember dm, int page, int rows, String sortName, String sortOrder);
22. Session Management
[Scenario 1] Avoid frequent creation of Session on JSP pages
A common misconception is that sessions are created when there is client access, but the fact is that they are not created until a server-side program calls statements such as HttpServletRequest.getSession(true). Note that if the session is not closed using <%@page session="false"%> as shown by JSP, the JSP file will automatically add such a phrase when compiled into a Servlet Sentence HttpSession session = HttpServletRequest.getSession(true); this is also the origin of the session object implied in JSP. Because session consumes memory resources, if session is not intended to be used, it should be closed in all JSPs.
For pages that do not need to track session status, closing automatically created sessions can save some resources. Use the following page instructions:
example: <%@ page session="false"%>
Setting false does not disable session tracking, it just prevents jsp pages from creating new sessions for users who do not have sessions.
For pages that do not require session tracking, set it to false; session objects are inaccessible when set to false.
Scenario 2: Clean up unwanted Session in time
In order to clear inactive sessions, many application servers have default session timeouts, usually 30 minutes. When the application server needs to save more sessions, if the memory capacity is insufficient, operating system Some of the memory data will be transferred to disk, and the application server may dump some inactive sessions to disk according to the Most Recently Used algorithm, or even throw out the "insufficient memory" exception. Serialized sessions are expensive in large-scale systems. When the session is no longer needed, the HttpSession.invalidate() method should be called in time to clear the session. The HttpSession.invalidate() method is usually invoked on the exit page of the application.
Java code:
- @RequestMapping("/out")
- public String out(HttpServletRequest req, HttpServletResponse resp)
- {
- isystemLogService.saveLog(req, "User logout exit", "User logout exit", "User logout exit");
- req.getSession().removeAttribute("user");
- req.getSession().invalidate();
- Log.getLogger(this.getClass()).info("User logout is successful! ___________.);
- return "redirect:../";
- }
23. Use unit testing instead of main method
Adding unit tests to the key details of the program, which can be retained in the system and provided for testers to use, to facilitate the statistical coverage of unit tests and so on; to reduce the frequency of errors in the program before testers test; for example, using Junit and other testing tools to achieve.
Java code:
- public class UserTest
- {
- private IUserService userService;
- @Before
- public void initInterface()
- {
- userService = new UserService();
- }
- @After
- public void freeSources()
- {
- userService = null;
- }
- @Test
- public void add()
- {
- User user = new User("boonya", "male", 23, "Java programmer");
- boolean success = userService.add(user);
- System.out.println(success ? "Add Success" : "Add Failure");
- }
- }
Note: Some places may not be considered. I hope you can point out the inappropriate points.
Original address: http://blog.csdn.net/boonya/article/details/13622169