Preface
- Because I have been engaged in Java research and development, especially love Java, ES Official provides two ways to access Java API as follows, of course, I chose Java API, so I also started the path of API trampling (because this SDK document seems to be headache, but when I step by step understand in depth, it is also very simple):
- Java API [5.5] — other versions
- Java REST Client [5.5] — other versions
Note (es official api document): https://www.elastic.co/guide/en/elasticsearch/client/index.html
- Related articles:
Introduction to Elastic search 5.5 (I)
I. Java Project Construction
- Client calls Maven dependency, client I configure is slf4j+log4j2, too much configuration will not paste up
<dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>5.5.1</version> </dependency> <!-- This must be introduced. This is used. transport Of jar --> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>transport</artifactId> <version>5.5.1</version> </dependency> <!-- es Of jar Yes guava Depend on --> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>18.0</version> </dependency> - The Java connection ES node code is as follows
Settings settings = Settings.builder() //Cluster name .put("cluster.name", "onesearch") //Automatic sniffing .put("client.transport.sniff", true) .put("discovery.type", "zen") .put("discovery.zen.minimum_master_nodes", 1) .put("discovery.zen.ping_timeout", "500ms") .put("discovery.initial_state_timeout", "500ms") .build(); Client client = new PreBuiltTransportClient(settings) .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(ip), 9300));Startup error-free means that you have successfully established a connection with ES.
2. Java Client Operates Index Data
- When you look at the official documents at the beginning, you will see the words "Mamaipi" in your mind, because the official documents sometimes give you a cold example. Sometimes they simply paste the JSON code of Rest mode. Tens of thousands of grass mud horses are not running and grazing crazily. Java API mode is actually the assembly of JSON strings, and then through netty to communicate with ES, compared with http mode to access. It's good that SDK can sniff nodes automatically. One node hangs up and another can be used. http has no advantage because it has a single IP.
Example 1: How do I write data into ES?
/** * ES The basic types can be viewed on the official website. * If you use map to write data and create an index, es automatically converts according to the value data type of map * For example, age is int, and integer is used in es. * There's a big flaw in using map (unless you encapsulate object preservation by yourself). When you save the java.util.Date type in, ES will all be converted to UTC for preservation. * This can only be specified by defining some attributes of the index field in the following api way **/ @Test public void createData() { Map<String, Object> map = new HashMap<String, Object>(); // map.put("name", "Smith Wang"); map.put("name", "Smith Chen"); // map.put("age", 20); map.put("age", 5); // map.put("interests", new String[]{"sports","film"}); map.put("interests", new String[] { "reading", "film" }); // map.put("about", "I love to go rock music"); map.put("about", "I love to go rock climbing"); IndexResponse response = client.prepareIndex("megacorp", "employee", UUID.randomUUID().toString()) .setSource(map).get(); System.out.println("Write data results=" + response.status().getStatus() + "!id=" + response.getId()); }
- Note: The first parameter of prepareIndex is index, the second is type, and the third is record ID (UUID is not recommended, I will say later).
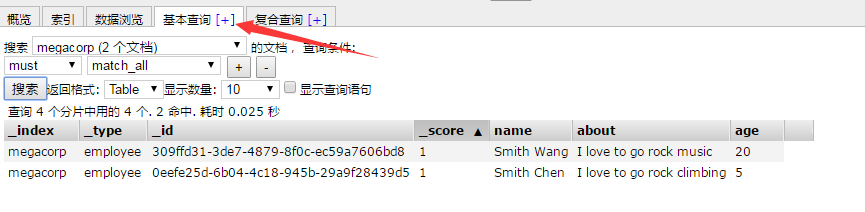
Then you can find the data you just inserted in the basic query.
---------------------------------------------------------------------------------------------------
Example 2: How do I query data from ES according to fields (in fact, my examples are translated according to the Elastic search authoritative guide, because all of the books are rest ed, not Java api)
/** * match Used, will be queried by participle */ @Test public void match() { SearchRequestBuilder requestBuilder = client.prepareSearch("megacorp").setTypes("employee") .setQuery(QueryBuilders.matchQuery("about", "rock climbing")); System.out.println(requestBuilder.toString()); SearchResponse response = requestBuilder.execute().actionGet(); System.out.println(response.status()); if (response.status().getStatus() == 200) { for (SearchHit hits : response.getHits().getHits()) { System.out.println(hits.getSourceAsString()); } } }
OK, these are the most basic operations! Seemingly no difficulty
3. Writing Complex Query Statements through Java API
- Precise matching of match phrase phrases
/** * matchphrase Use, phrase matching * Not using matchPhraseQuery results in rock climbing being split into queries */ @Test public void matchPhrase() { SearchRequestBuilder requestBuilder = client.prepareSearch("megacorp").setTypes("employee") .setQuery(QueryBuilders.matchPhraseQuery("about", "rock climbing")); System.out.println(requestBuilder.toString()); SearchResponse response = requestBuilder.execute().actionGet(); System.out.println(response.status()); if (response.status().getStatus() == 200) { for (SearchHit hits : response.getHits().getHits()) { System.out.println(hits.getSourceAsString()); } } }
- Highlight
@Test public void highlight() { HighlightBuilder highlightBuilder = new HighlightBuilder(); // highlightBuilder.preTags(FragmentSettings.prefix);//Set prefix // highlightBuilder.postTags(FragmentSettings.subfix); // Setting Suffixes highlightBuilder.field("about"); // highlightBuilder.fragmenter(FragmentSettings.SPAN) // .fragmentSize(FragmentSettings.HIGHLIGHT_MAX_WORDS).numOfFragments(5); SearchRequestBuilder requestBuilder = client.prepareSearch("megacorp").setTypes("employee") .setQuery(QueryBuilders.matchPhraseQuery("about", "rock climbing")).highlighter(highlightBuilder); System.out.println(requestBuilder.toString()); SearchResponse response = requestBuilder.execute().actionGet(); System.out.println(response.status()); if (response.status().getStatus() == 200) { for (SearchHit hits : response.getHits().getHits()) { System.out.println(hits.getSourceAsString()); // Here, you can use hight field to cover the fields in source. System.out.println(hits.getHighlightFields()); } } }
- GROUP BY query of relational data
@Test public void aggregation() { SearchRequestBuilder searchBuilder = client.prepareSearch("megacorp").setTypes("employee") .addAggregation(AggregationBuilders.terms("by_interests").field("interests") .subAggregation(AggregationBuilders.terms("by_age").field("age")).size(10)); System.out.println(searchBuilder.toString()); SearchResponse response = searchBuilder.execute().actionGet(); if (response.status().getStatus() == 200) { for (SearchHit hits : response.getHits().getHits()) { System.out.println(hits.getSourceAsString()); } } StringTerms terms = response.getAggregations().get("by_interests"); for (StringTerms.Bucket bucket : terms.getBuckets()) { System.out.println("-interest:" + bucket.getKey() + "," + bucket.getDocCount()); if (bucket.getAggregations() != null && bucket.getAggregations().get("by_age") != null) { LongTerms ageTerms = bucket.getAggregations().get("by_age"); for (LongTerms.Bucket bucket2 : ageTerms.getBuckets()) { System.out.println("--------by age:" + bucket2.getKey() + "," + bucket2.getDocCount()); } } } }
- Simultaneous Average of GROUP BY (Sum, etc.)
/** * Aggregation + Average Age * Sum and use AggregationBuilders.sum * Note that AggregationBuilders.terms("by_interests") by_interests is a key of a group, and when you return the result, you reverse it according to the key. * Come and get the value. */ @Test public void aggregationAvg() { SearchRequestBuilder searchBuilder = client.prepareSearch("megacorp").setTypes("employee") .addAggregation(AggregationBuilders.terms("by_interests").field("interests") .subAggregation(AggregationBuilders.avg("avg_age").field("age")).size(10)); System.out.println(searchBuilder.toString()); SearchResponse response = searchBuilder.execute().actionGet(); if (response.status().getStatus() == 200) { for (SearchHit hits : response.getHits().getHits()) { System.out.println(hits.getSourceAsString()); } } StringTerms terms = response.getAggregations().get("by_interests"); for (StringTerms.Bucket bucket : terms.getBuckets()) { System.out.println("-interest:" + bucket.getKey() + "," + bucket.getDocCount() + ","); InternalAvg agg = bucket.getAggregations().get("avg_age"); System.out.println("---------avg age:" + agg.value() + ",count=" + agg.getValueAsString()); } }
IV. Indexing through Java API
- Following is the official operation of creating an index and specifying the type of field. It's very "Maybaipi" here.
@Test public void createIndexInfo() { client.admin().indices().prepareCreate("megacorp") .setSettings(Settings.builder().put("index.number_of_shards", 4).put("index.number_of_replicas", 1)) .addMapping("employee", "{\n" + " \"properties\": {\n" + " \"age\": {\n" + " \"type\": \"integer\"\n" + " },\n" + " \"name\": {\n" + " \"type\": \"text\"\n" + " },\n" + " \"interests\": {\n" + " \"type\": \"text\",\n" + " \"fielddata\": true\n" + " },\n" + " \"about\": {\n" + " \"type\": \"text\"\n" + " }\n" + " }\n" + "}", XContentType.JSON) .get(); }
- Of course, the official also gave a more elegant solution (XContentBuilder), as follows
XContentBuilder mapping = JsonXContent.contentBuilder() .startObject() .startObject("productIndex") .startObject("properties") .startObject("title").field("type", "string").field("store", "yes").endObject() .startObject("description").field("type", "string").field("index", "not_analyzed").endObject() .startObject("price").field("type", "double").endObject() .startObject("onSale").field("type", "boolean").endObject() .startObject("type").field("type", "integer").endObject() .startObject("createDate").field("type", "date").endObject() .endObject() .endObject() .endObject(); //Amount to: { { "productIndex":{ "properties": { "title":{ "type":"string", "store":"yes" } }, .. } } }
Overall, this solution would be a little better than splicing strings, and would not feel very low.
- Complete API way to create an index (here is the trouble to make up for it, because I did a complete operation of extracting data from relational database and writing to ES). Just look at the lines of code. In fact, I did some XML-related modifications to map database fields to ES field operations. First, you pay attention to the simple creation process.
@Test public void createIndexWithXML() throws Exception { //Focus on lines of code IndicesExistsRequestBuilder indices = client.admin().indices().prepareExists("test"); List<SqlMappingConfig> mappingList = ElasticXMLReader.getSearchInfoList(); //Focus on lines of code if(!indices.execute().actionGet().isExists()) { //Focus on lines of code XContentBuilder builder = JsonXContent.contentBuilder(); builder.startObject().startObject("properties"); SqlMappingConfig mapping = mappingList.get(0); for(Column column : mapping.getSearchInfo().getColumns()) { builder.startObject(column.getAttriMap().get("index-column")); for(Entry<String, String> entry : column.getAttriMap().entrySet()) { if(!entry.getKey().equals("index-column") && !entry.getKey().equals("sql-column")) { builder.field(entry.getKey().equals("data-type")?"type":entry.getKey(), entry.getValue()); } } builder.endObject(); } builder.endObject().endObject(); //Focus on lines of code PutMappingRequest mappingRequest = Requests.putMappingRequest(mapping.getSearchInfo().getIndex()).type(mapping.getSearchInfo().getType()); mappingRequest.source(builder); //Focus on lines of code CreateIndexResponse response = client.admin().indices().prepareCreate(mapping.getSearchInfo().getIndex()) .setSettings(Settings.builder().put("index.number_of_shards", 8).put("index.number_of_replicas", 1)) .addMapping(mapping.getSearchInfo().getType(), mappingRequest.source(),XContentType.JSON).execute().actionGet(); System.out.println(response.isAcknowledged()); } }
Last
Many people have cleanliness, like to use pure SDK code to operate the API, I also stepped on numerous pits, the above code is I try out step by step, before adding an es learning group, but I do not know if the question I asked is too simple, there is no guidance in asking questions, and later regrettably quit that group. But thanks to that group, I learned one thing, that is Elasticsearch-sql Tool, this tool supports relational database statement to es query parameters, very convenient! Through the generated json parameters, you can copy to write Java code (although very awkward, but already good)
Later, I will write a sample of how query statements in relational databases become ES Java code. Please also pay attention to this.